内表是在程序中定义,仅在程序运行时间内,存在于内存中的表格,用于暂时存储数据库表中的数据,实现复杂的数据操作
内表中存放的数据是临时的,当程序执行时才会占用内存,关闭程序时会释放内存
内表的种类
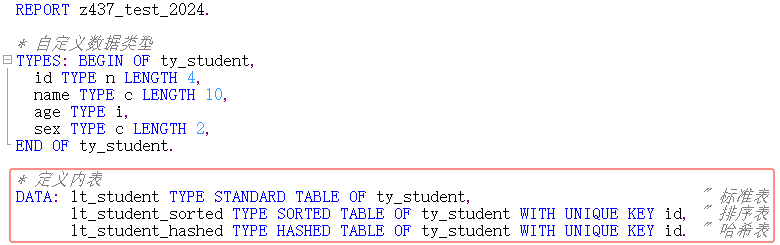
① 标准表
关键字为STANDARD TABLE,系统为该表的每一行数据生成一个逻辑索引,对标准表的寻址可以通过关键字或索引进行
标准表中不能使用WITH UNIQUE语句,只能使用WITH NON-UNIQUE语句
② 排序表
关键字为SORTED TABLE,也具有一个逻辑索引,不同之处是排序表总是按其表关键字升序排序后再进行存储,其访问方式与标准表相同
与标准表不同,排序表可使用WITH UNIQUE语句且自带BINARY SEARCH(二分查找)功能
因为排序表已经排序,所以使用SORT语句会报错
③ 哈希表
关键字为HASHED TABLE,只能通过关键字来访问(没有索引),其寻址一个数据行的时间与表的行数无关
哈希表一定要使用WITH UNIQUE语句指定关键字
1.创建内表
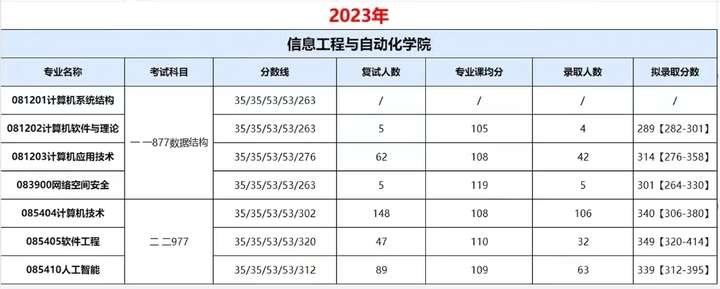
示例1

WITH HEADER LINE表示定义内表的时候,同时定义了同名称的工作区,为了明确区分使用的是内表还是工作区,我们可以使用[]加以区分
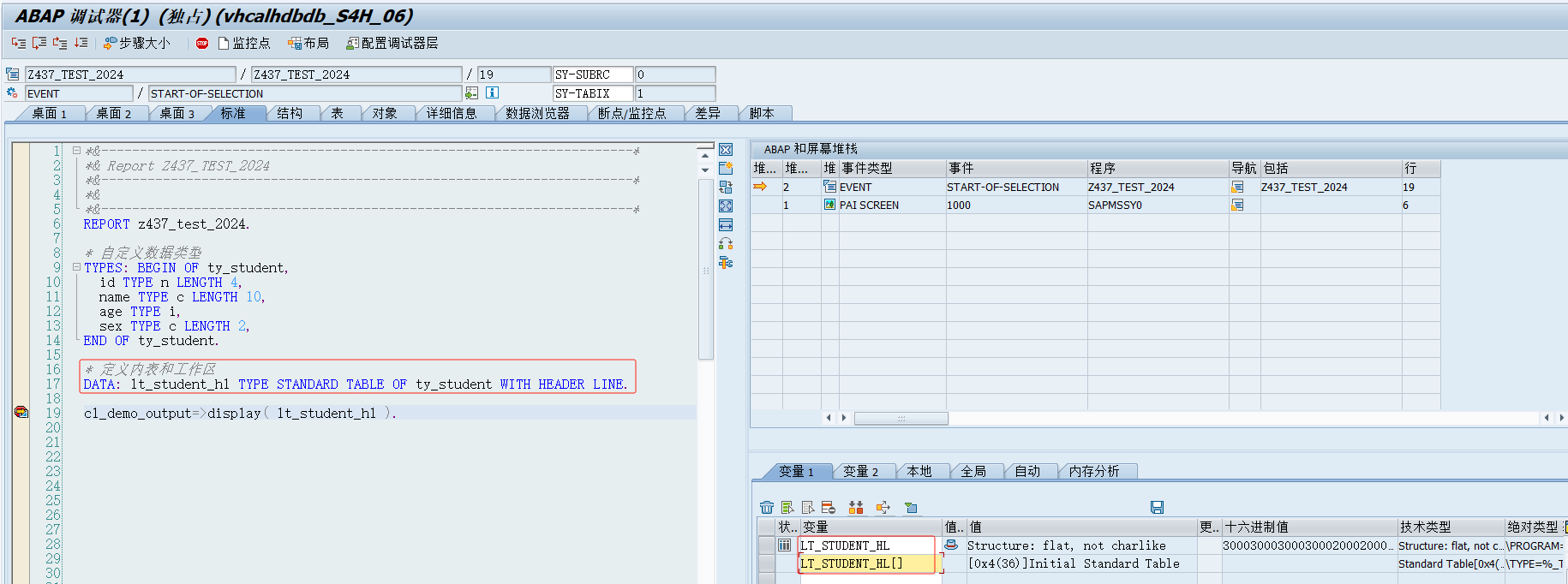
例如,LT_STUDENT_HL表示工作区,LT_STUDENT_HL[]表示内表
提示Tips:WITH HEADER LINE不建议使用,可读性较差
示例2:定义标准表、排序表和哈希表
2.内表初始化
。。。
3.内表操作
① 追加内表数据
追加内表数据![]() https://blog.csdn.net/Hudas/article/details/139899438?spm=1001.2014.3001.5501② 插入内表数据
https://blog.csdn.net/Hudas/article/details/139899438?spm=1001.2014.3001.5501② 插入内表数据
插入内表数据![]() https://blog.csdn.net/Hudas/article/details/139900682?spm=1001.2014.3001.5501③ 删除内表数据
https://blog.csdn.net/Hudas/article/details/139900682?spm=1001.2014.3001.5501③ 删除内表数据
删除内表数据![]() https://blog.csdn.net/Hudas/article/details/139905340?spm=1001.2014.3001.5501④ 读取内表数据
https://blog.csdn.net/Hudas/article/details/139905340?spm=1001.2014.3001.5501④ 读取内表数据
读取内表数据![]() https://blog.csdn.net/Hudas/article/details/139904778?spm=1001.2014.3001.5501⑤ 排序内表数据
https://blog.csdn.net/Hudas/article/details/139904778?spm=1001.2014.3001.5501⑤ 排序内表数据
排序内表数据![]() https://blog.csdn.net/Hudas/article/details/139908124?spm=1001.2014.3001.5501
https://blog.csdn.net/Hudas/article/details/139908124?spm=1001.2014.3001.5501









![[spring] Spring MVC Thymeleaf(下)](https://img-blog.csdnimg.cn/direct/8165dc29c60f44ed8f80c7ddabed6b6f.png)