文章目录
- 1.概述
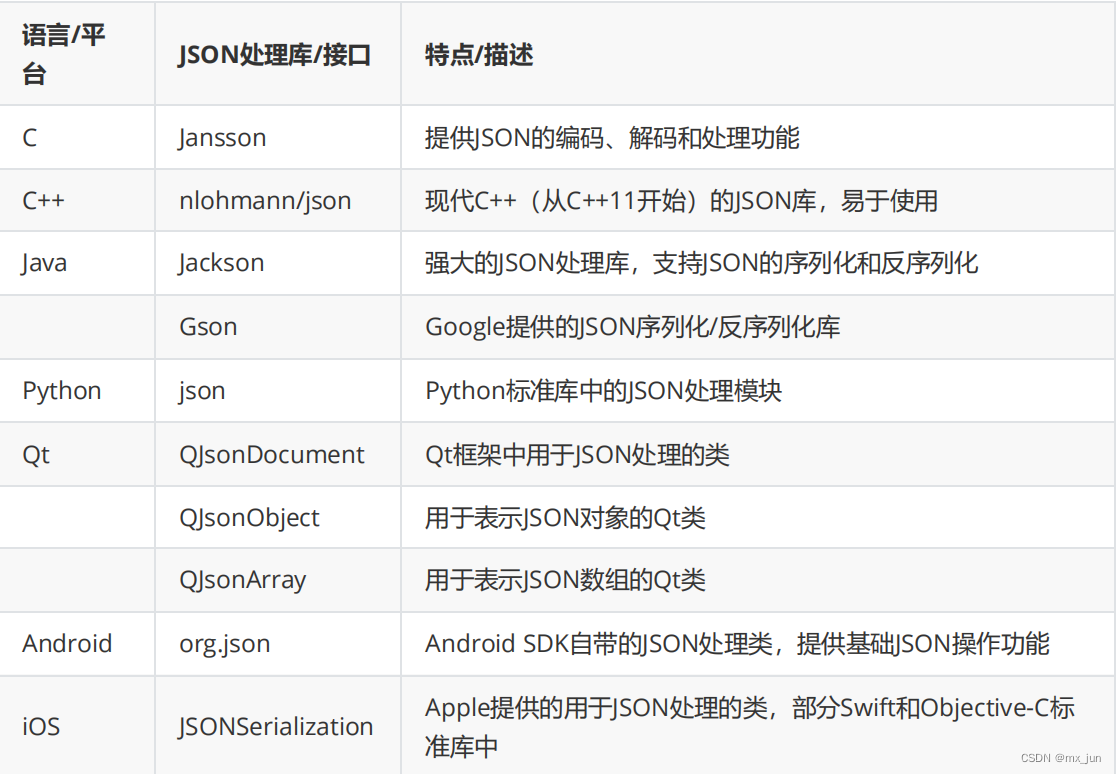
- 2. ByteBuf 分类
- 3. 代码实例
- 3.1 常用方法
- 3.1.1 创建ByteBuf
- 3.1.2 写入字节
- 3.1.3 扩容
- 3.1.2.1 扩容实例
- 3.1.2.2 扩容计算新容量代码
- 3.1.4 读取字节
- 3.1.5 标记回退
- 3.1.6 slice
- 3.1.7 duplicate
- 3.1.8 CompositeByteBuf
- 3.1.9 retain & release
- 3.1.9.1 retain & release
- 3.1.9.2 Netty TailContext release
- 3.2 完整实例
- 4. 参考文献
1.概述
ByteBuf 对字节进行操作
ByteBuf 四个基本属性:
- readerIndex: 读指针,字节数组,读到哪了
- writerIndex: 写指针,字节数组,写到哪了
- maxCapacity:最大容量,字节数组最大容量
- markedReaderIndex:标记读指针,
resetReaderIndex方法可以把readerIndex修改为markedReaderIndex,回退重新读数据 - markedWriterIndex: 标记写指针,
resetReaderIndex方法可以把writerIndex修改为markedWriterIndex,回退重新写数据
public abstract class AbstractByteBuf extends ByteBuf {
int readerIndex;
int writerIndex;
private int markedReaderIndex;
private int markedWriterIndex;
private int maxCapacity;
}
2. ByteBuf 分类
ByteBuf 分为
- 直接内存或堆内存(Heap/Direct)
- 池化 和 非池化(Pooled/Unpooled)和 操作方式是否安全 (Unsafe/非 Unsafe)
ByteBuf 创建可以基于直接内存或堆内存
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
ByteBuf 池化 和 非池化
- 没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
ByteBuf 操作方式是否安全 (Unsafe/非 Unsafe)
- Unsafe:表示每次调用 JDK 的 Unsafe 对象操作物理内存,依赖 offset + index 的方式操作数据
- 非 Unsafe:则不需要依赖 JDK 的 Unsafe 对象,直接通过数组下标的方式操作数据
3. 代码实例
3.1 常用方法
3.1.1 创建ByteBuf
创建ByteBuf , 默认都是池化的
// 堆内存的ByteBuf
ByteBuf bufferHeap = ByteBufAllocator.DEFAULT.heapBuffer();
// 直接内存的ByteBuf
ByteBuf bufferDirect = ByteBufAllocator.DEFAULT.directBuffer();
System.out.println(bufferHeap);
System.out.println(bufferDirect);

3.1.2 写入字节
bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});
bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});
print("第一次写入", bufferHeap);
print("第一次写入", bufferDirect);

3.1.3 扩容
3.1.2.1 扩容实例
- 默认 256
- 扩容加一倍
- 到了4194304,每次+4194304
for (int i = 0; i < 100; i++) {
bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});
bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});
}
print("批量写入&扩容", bufferHeap);
print("批量写入&扩容", bufferDirect);

3.1.2.2 扩容计算新容量代码
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
ObjectUtil.checkPositiveOrZero(minNewCapacity, "minNewCapacity");
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format("minNewCapacity: %d (expected: not greater than maxCapacity(%d)", minNewCapacity, maxCapacity));
} else {
int threshold = 4194304;
if (minNewCapacity == 4194304) {
return 4194304;
} else {
int newCapacity;
if (minNewCapacity > 4194304) {
newCapacity = minNewCapacity / 4194304 * 4194304;
if (newCapacity > maxCapacity - 4194304) {
newCapacity = maxCapacity;
} else {
newCapacity += 4194304;
}
return newCapacity;
} else {
for(newCapacity = 64; newCapacity < minNewCapacity; newCapacity <<= 1) {
}
return Math.min(newCapacity, maxCapacity);
}
}
}
}
3.1.4 读取字节
readByte(bufferHeap);
readByte(bufferDirect);
print("读取一个字节", bufferHeap);
print("读取一个字节", bufferDirect);

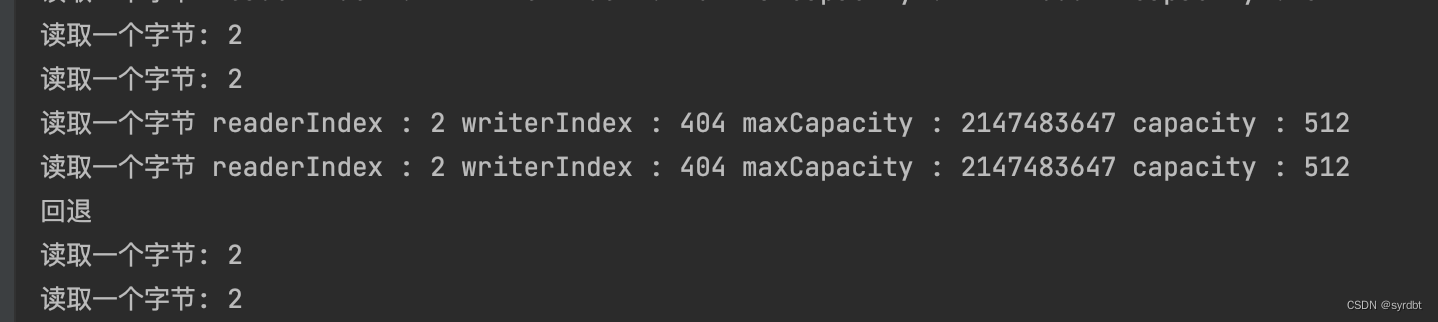
3.1.5 标记回退
bufferHeap.markReaderIndex();
bufferDirect.markReaderIndex();
readByte(bufferHeap);
readByte(bufferDirect);
print("读取一个字节", bufferHeap);
print("读取一个字节", bufferDirect);
System.out.println("回退");
bufferHeap.resetReaderIndex();
bufferDirect.resetReaderIndex();
readByte(bufferHeap);
readByte(bufferDirect);
print("读取一个字节", bufferHeap);
print("读取一个字节", bufferDirect);
3.1.6 slice
// 无参 slice 是从原始 ByteBuf 的 read index 到 write index 之间的内容进行切片
// slice 和 bufferHeap 共享一块内存
ByteBuf slice = bufferHeap.slice();
slice.setByte(0, 9);
print("slice", slice);
readByte(bufferHeap);

3.1.7 duplicate
// 内存拷贝不共享内存
ByteBuf duplicate = bufferHeap.duplicate();
print("duplicate", duplicate);
print("bufferHeap", bufferHeap);
duplicate.writeBytes(new byte[]{5});
print("duplicate", duplicate);
print("bufferHeap", bufferHeap);

3.1.8 CompositeByteBuf
// CompositeByteBuf 是一个组合的 ByteBuf,它内部维护了一个 Component 数组,
// 每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量等信息,代表着整体中某一段的数据。
// 优点,对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制
// 缺点,复杂了很多,多次操作会带来性能的损耗
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);
buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});
CompositeByteBuf buf3 = ByteBufAllocator.DEFAULT.compositeBuffer();
// true 表示增加新的 ByteBuf 自动递增 write index, 否则 write index 会始终为 0
buf3.addComponents(true, buf1, buf2);
print("buf3", buf3);
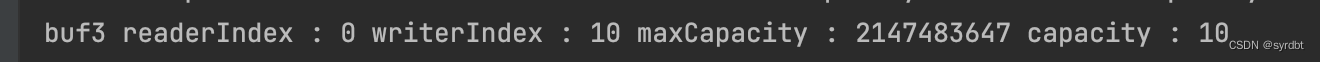
3.1.9 retain & release
3.1.9.1 retain & release
Netty 这里采用了引用计数法来控制回收内存,每个 ByteBuf 都实现了 ReferenceCounted 接口
- 每个 ByteBuf 对象的初始计数为 1
- 调用 release 方法计数减 1,如果计数为 0,ByteBuf 内存被回收
- 调用 retain 方法计数加 1,表示调用者没用完之前,其它 handler 即使调用了 release 也不会造成回收
- 当计数为 0 时,底层内存会被回收,这时即使 ByteBuf 对象还在,其各个方法均无法正常使用
bufferHeap.retain();
bufferDirect.retain();
bufferHeap.release();
bufferDirect.release();
print("release bufferHeap", bufferHeap);
print("release bufferDirect", bufferDirect);
bufferHeap.release();
bufferDirect.release();
print("release bufferHeap", bufferHeap);
print("release bufferDirect", bufferDirect);
bufferHeap.release();
bufferDirect.release();
print("release bufferHeap", bufferHeap);
print("release bufferDirect", bufferDirect);

3.1.9.2 Netty TailContext release
io.netty.channel.DefaultChannelPipeline.TailContext
io.netty.channel.DefaultChannelPipeline.TailContext#channelRead
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
onUnhandledInboundMessage(ctx, msg);
}
io.netty.channel.DefaultChannelPipeline#onUnhandledInboundMessage(ChannelHandlerContext, Object)
protected void onUnhandledInboundMessage(ChannelHandlerContext ctx, Object msg) {
onUnhandledInboundMessage(msg);
if (logger.isDebugEnabled()) {
logger.debug("Discarded message pipeline : {}. Channel : {}.",
ctx.pipeline().names(), ctx.channel());
}
}
3.2 完整实例
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.CompositeByteBuf;
public class ByteBufStudy {
public static void main(String[] args) {
// 堆内存的ByteBuf
ByteBuf bufferHeap = ByteBufAllocator.DEFAULT.heapBuffer();
// 直接内存的ByteBuf
ByteBuf bufferDirect = ByteBufAllocator.DEFAULT.directBuffer();
System.out.println(bufferHeap);
System.out.println(bufferDirect);
bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});
bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});
print("第一次写入", bufferHeap);
print("第一次写入", bufferDirect);
for (int i = 0; i < 100; i++) {
bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});
bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});
}
print("批量写入&扩容", bufferHeap);
print("批量写入&扩容", bufferDirect);
readByte(bufferHeap);
readByte(bufferDirect);
print("读取一个字节", bufferHeap);
print("读取一个字节", bufferDirect);
bufferHeap.markReaderIndex();
bufferDirect.markReaderIndex();
readByte(bufferHeap);
readByte(bufferDirect);
print("读取一个字节", bufferHeap);
print("读取一个字节", bufferDirect);
System.out.println("回退");
bufferHeap.resetReaderIndex();
bufferDirect.resetReaderIndex();
readByte(bufferHeap);
readByte(bufferDirect);
print("读取一个字节", bufferHeap);
print("读取一个字节", bufferDirect);
// 无参 slice 是从原始 ByteBuf 的 read index 到 write index 之间的内容进行切片
// slice 和 bufferHeap 共享一块内存
ByteBuf slice = bufferHeap.slice();
slice.setByte(0, 9);
print("slice", slice);
readByte(bufferHeap);
// 内存拷贝不共享内存
ByteBuf duplicate = bufferHeap.duplicate();
print("duplicate", duplicate);
print("bufferHeap", bufferHeap);
duplicate.writeBytes(new byte[]{5});
print("duplicate", duplicate);
print("bufferHeap", bufferHeap);
// CompositeByteBuf 是一个组合的 ByteBuf,它内部维护了一个 Component 数组,
// 每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量等信息,代表着整体中某一段的数据。
// 优点,对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制
// 缺点,复杂了很多,多次操作会带来性能的损耗
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);
buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});
CompositeByteBuf buf3 = ByteBufAllocator.DEFAULT.compositeBuffer();
// true 表示增加新的 ByteBuf 自动递增 write index, 否则 write index 会始终为 0
buf3.addComponents(true, buf1, buf2);
print("buf3", buf3);
bufferHeap.retain();
bufferDirect.retain();
bufferHeap.release();
bufferDirect.release();
print("release bufferHeap", bufferHeap);
print("release bufferDirect", bufferDirect);
bufferHeap.release();
bufferDirect.release();
print("release bufferHeap", bufferHeap);
print("release bufferDirect", bufferDirect);
bufferHeap.release();
bufferDirect.release();
print("release bufferHeap", bufferHeap);
print("release bufferDirect", bufferDirect);
}
public static void print(String prefix, ByteBuf buffer) {
System.out.printf("%s readerIndex : %s writerIndex : %s maxCapacity : %s capacity : %s %n",
prefix, buffer.readerIndex(), buffer.writerIndex(), buffer.maxCapacity(), buffer.capacity());
}
public static void readByte(ByteBuf buffer) {
System.out.printf("读取一个字节: %s %n", buffer.readByte());}
}
4. 参考文献
- 黑马 Netty教程
- 拉钩教育 Netty 核心原理剖析与 RPC 实践 若地老师