知识点:
1.
(p->n)++ 会递增 p->n 的值,但是这个表达式的值仍然是递增之前的值
p->n 会得到 a[0].n 的值,
++p->n 也会递增 p->n 的值,但是这个表达式的值是递增后的值
p->next->n 访问 p 指向的结点的下一个结点的 n 值,这就是 a[1].n 的值
2.
*(pt+1):对 pt 指针加上 1 后再解引用==访问 pt 数组中的第二个元素
&pt[2]:这将返回 pt 数组第三个元素的地址
3.
对于插入新节点:
新节点的任何形式都不能出现在第一个等号的右边,但是需要出现在后一个式子的等号的右侧

3.指向一级指针的只能是二级指针
二级指针不能直接访问一级指针所指向的任何形式的变量,只能间接访问

4.指针中地址的引用不能加 *
指针所指向的具体值应该加 *
5.char a[]="Itismine", *p="Itismine":
p所指向的地址可以修改,如果p所指向的是常量字符串,则不能修改,常量字符串本身是不能被修改的
6.p.next = &b; 和 p->next = &b; 不等价
点运算符 (.): 这种方式直接在结构体或者类的对象上访问其成员。

箭头运算符 (->): 这种方式在通过指针间接访问结构体或类的成员时使用

7.指针指向最后一个节点的条件是p->next = NULL

8.指针对数组元素的引用问题


9.调用函数有什么要求,在书写方面?

m=f(a,n); 正确是因为它正确地传递了数组和数组长度给子函数。
而 A, B 和 C 分别存在参数类型不符、数组地址未正确传递等问题。正确的调用应该确保参数匹配函数原型。

10.宏
1 编译之前进行
2

11.char s[]="china"; char *p; p=s;
数组s的长度和p所指向的字符串长度相等—— 错误,这里需要理解数组长度和指针指向的字符串长度的区别。数组s的长度包括空终止符\0,而p指向的字符串通常指的是没有包含空终止符的字符序列的长度,除非特地去计算它。
习题易错
2-1
若有以下说明语句,struct birthday
{int year;
int month;
int day;
}day1; 则下面叙述正确的是( )。
A.day1为结构体类型名
B.struct birthday为结构体变量名
C.month为结构体变量名
D.day1为结构体变量名
2-2
下叙述中不正确的是()。
A.一个结构体类型可以由多个称为成员(或域) 的成分组成
B.在定义结构体类型时,编译程序就为它分配了内存空间
C.结构体类型中的成员可以是C语言中预先定义的基本数据类型,也可以是数组和结构。
D.结构体类型中各个成员的类型可以是不一致的
2-3
当定义一个结构变量时,系统分配给它的内存空间大小是( )。
A.各成员所需内存量的总和
B.结构中第一个成员所需内存量
C.成员中占内存量最大者所需容量
D.结构中最后一个成员所需内存量
2-4
若程序中有下面的说明和定义

A.编译出错,结构体定义完要加分号
B.程序将顺利编译连接执行
C.能顺利通过编译连接但不能执行
D.能顺利通过编译但连接出错
2-5
设有如下定义,则对data中的a成员的正确引用是()。
struct sk{ int a; float b; } data, *p=&data;A.(*p).data.a
B.(*p).a
C.p->data.a
D.p.data.a
2-6
设有以下说明语句:
struct ex
{
int x;
float y;
char z;
} example;
则下面的叙述中不正确的是______。
A.struct是结构体类型的关键字
B.example是结构体类型名
C.x,y,z都是结构体成员名
D.struct ex是结构体类型
2-7
根据下面的定义,struct worker
{char name[18];
int age;
};
struct worker w[100]={"John",16,"Paul",17,"Mary",16 }; 能输出字母’P’的语句是( )。
A.printf("%c",w[1].name);
B.printf("%c",w[2].name[0]);
C.printf("%c",w[2].name[1]);
D.printf("%c",w[1].name[0]);
2-8
有以下结构体说明、变量定义和赋值语句:
struct SID
{ char name [10];
int age;
char sex;
}s[5],stu;
则以下 scanf函数调用语句有错误的是( )。
A.scanf("%s", s[0].name);
B.scanf("%d", &s[0].age);
C.scanf("%s", &stu.name);
D.scanf("%d",& stu.sex);
2-9
有以下结构体说明、变量定义和赋值语句,则以下scanf函数调用语句有错误的是
struct STD
{ char name[10];
int age;
char sex;
} s[5],*ps;
ps=&s[0];
A.scanf("%c",&(ps->sex));
B.scanf("%d",ps->age);
C.scanf("%s",s[0].name);
D.scanf("%d",&s[0].age);
2-10
根据下面的定义,struct worker
{char name[18];
int age;
};
struct worker w[100]={"John",16,"Paul",17,"Mary",17 }; 能输出字符串’Mary’的语句是( )。
A.printf("%s",w[2].name);
B.printf("%s",w[1].name);
C.printf("%s",w[2]);
D.printf("%s",w[1]);
2-11
以下程序运行后的输出结果是
#include <stdio.h>
#include <string.h>
struct S
{
char name[10];
};
main()
{
struct S s1, s2;
strcpy(s1.name, "XXX");
strcpy(s2.name, "=");
s1 = s2;
printf("%s\n", s1.name);
}
A.XXX
B.=
C.XXX=
D.=XXX
2-12
以下程序运行后的输出结果是
#include <stdio.h>
#include <string.h>
struct S
{
char name[10];
};
main()
{
struct S s1, s2;
strcpy(s1.name, "12345");
strcpy(s2.name, "ABC");
s1 = s2;
printf("%s\n", s1.name);
}
A.12345
B.ABC
C.ABC45
D.12ABC
2-13
若有以下定义,struct data
{int x;
int y;
}data1;
int *p; 则使p指向data1中的成员x,正确的赋值语句是( )。
A.p=&a;
B.p=&data1.x
C.p=data1.x;
D.*p=data1.x;
2-19
在c语言中,不允许有常量的数据类型是( )
A.整型
B结构型
C.字符型
D.字符串
2-20
若有以下结构体类型定义,struct worker
{char name[16];
struct date
{int year;
int month;
int day;
}birthday;
}x;则赋值语句正确的是( )。
A.x.year=1999;
B.x.birthday.month=3;
C.x.name="黎明";
D.x.birthday=1999.9.9;

2-23
在单链表指针为p的结点之后插入指针为s的结点,正确的操作是()。
A.p->next=s;s->next=p->next;
B.s->next=p->next;p->next=s;
C.p->next=s;p->next=s->next;
D.p->next=s->next;p->next=s;
2-24
设curr是指向一个非循环单向链表的尾结点(该结点有data域和next域,next域为指向下一结点的指针)的指针,则curr->next的值是:( )。
A.TRUE
B.FALSE
C.NULL
D.'\0'
2-29
单链表的访问规则是( )。
A.随机访问
B.从头指针开始,顺序访问
C.从尾指针开始,逆序访问
D.可以顺序访问,也可以逆序访问
2-30
带头结点的单链表的结点结构Node包含数据域data、指针域next,当前指针为p,则使p指向下一个结点的语句是( )。
A.p->next=p->next->next;
B.p->next=p;
C.p=p->next;
D.p=p.next

2-38
如果有函数char *func(char *p, char ch),则下面说法错误的是( )
A.函数返回一个字符指针
B.可以通过语句"return NULL;"返回函数结果
C.可以通过语句"return -1;"返回函数结果
D.可以通过语句"return p;"返回函数结果
2-42
单链表的结点结构Node包含数据域data、指针域next,则next域存放的是( )。
A.下一个结点的地址
B.下一个结点的值
C.本结点的地址
D.本结点的值
2-43
下面对typedef的叙述中错误的是( )。
A.用typedef可以定义各种类型名,但不能用来定义变量
B.用typedef可以增加新类型
C用typedef只是将已存在的类型用一个新的标识符来代表
D.使用typedef有利于程序的通用和移植

1.在C/C++中,数组下标和指针算术可以相互转换,但 p[3][1] 的形式试图访问三维数组的元素,然而在本例中并没有定义这样的数组,因此 C 项不正确。此外,p[3] 将尝试访问超出数组范围之外的元素,在 C 中将引发未定义行为。
pp[0][1] :,如果 pp 指向了 p 数组的第一个元素并且我们将其视为一个指向指针数组的指针的话。但是在实际情况下,由于 pp 和 p 都是存储在栈上的局部变量,这种引用可能引发未定义行为,但至少从语法上看它是格式正确的。
a[10] :直接引用了 a 数组中的第 10 个元素,考虑到 a 数组有 12 个元素,这是一个合法的引用。
((p+2)+2) :超出了 p 数组的范围,
2-55

答案是非零值(通常是1)
表示文件结束状态。当文件到达末尾时,feof() 函数返回非零值,否则返回0。


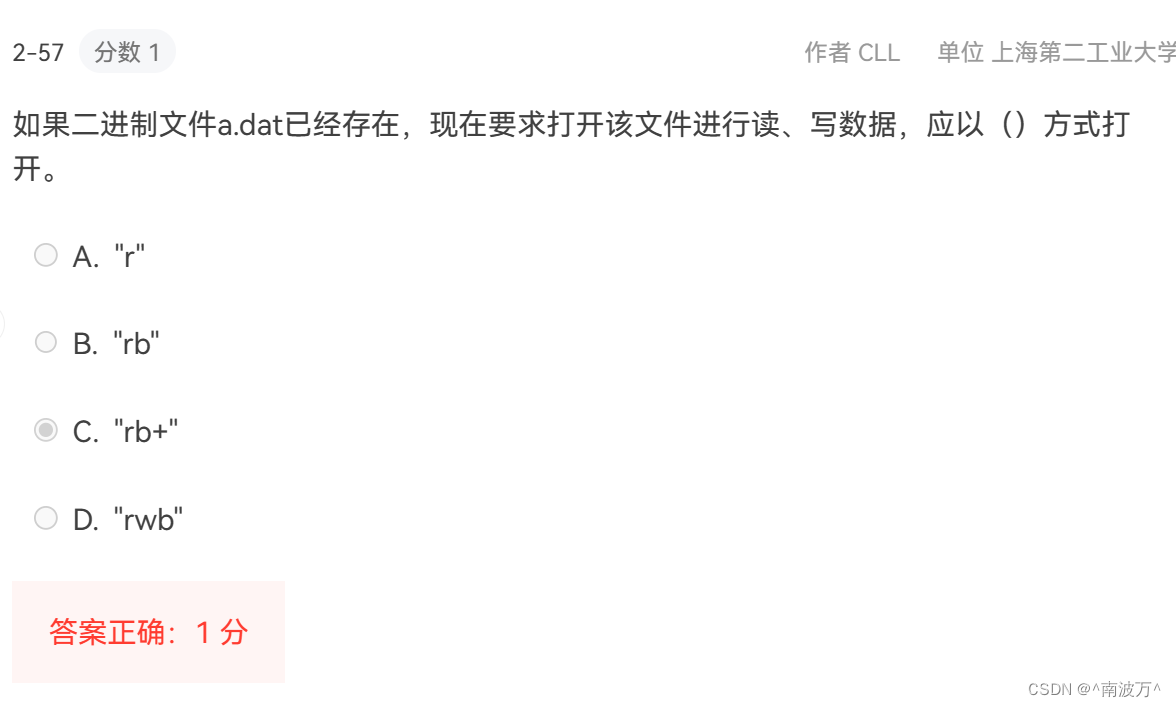
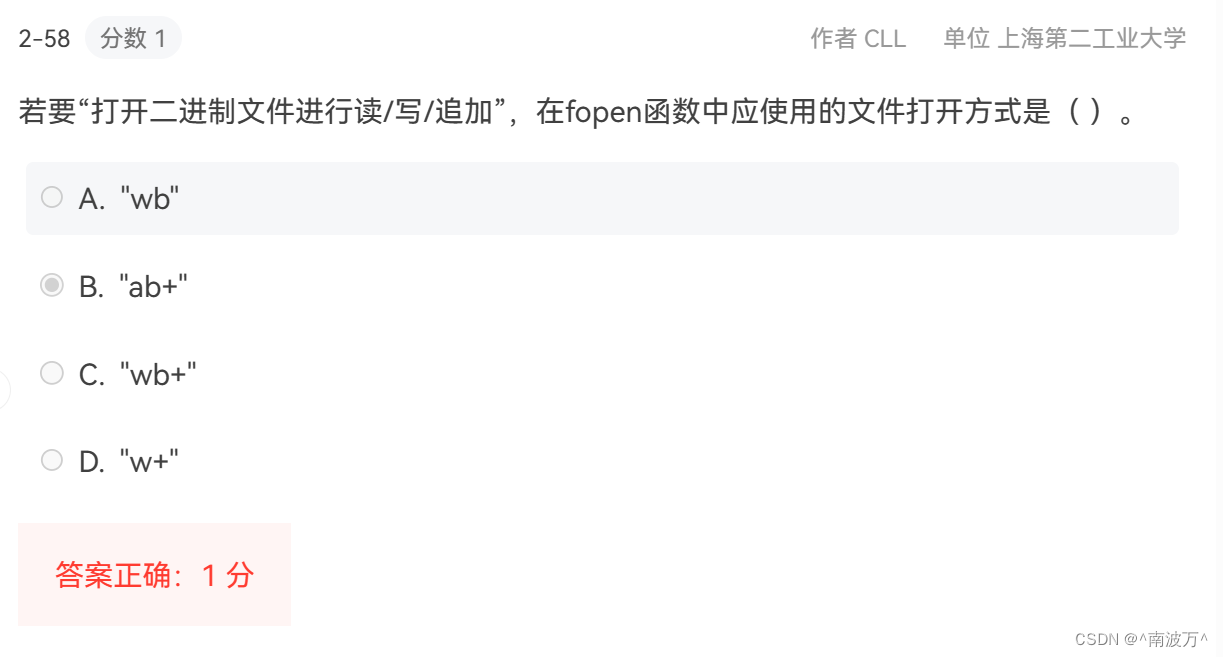



在 C 语言中,“rb”、“rb+”、“wb” 和 “wb+” 都是 fopen 函数用来打开二进制文件的模式:
- `"rb"` 表示以二进制格式打开一个文件供读取。如果文件不存在或者无法读取,函数将返回 `NULL`。
- `"rb+"` 类似于 `"rb"`,但是允许读/写。也就是说,在读模式下,你还可以写入文件。如果文件不存在或者无法读取,函数同样将返回 `NULL`。
- `"wb"` 是写模式的二进制文件打开方式。如果文件存在会被清空(即原有内容被删除),然后你可以向其中写入新的内容;如果文件不存在,则会创建一个新的文件。此模式下的文件只能写,不能读。
- `"wb+"` 在写模式的基础上增加了读的能力,所以你可以在写的同时读取文件中的信息。与 `"wb"` 类似,如果文件存在会被清空,并允许后续写入;如果文件不存在,则会创建新文件。
至于文本模式的 `"w"`、`"a+"` 等,它们的工作原理类似但适用于文本文件。例如:
- `"w"` 打开一个文本文件以写入,如果文件已经存在,其内容会被删除,就像 `"wb"` 模式。
- `"a+"` 打开一个文件用于追加和读取,如果文件不存在则创建之。初始位置是在文件的结尾,这样任何写入的内容都会添加到已有内容的后面。这种模式既支持读也支持写,读取时会从文件头部开始。
总结来说,加上 `"b"` 后缀表示二进制模式,而无 `"b"` 后缀一般默认为文本模式,主要影响换行符的处理以及缓冲区的行为。