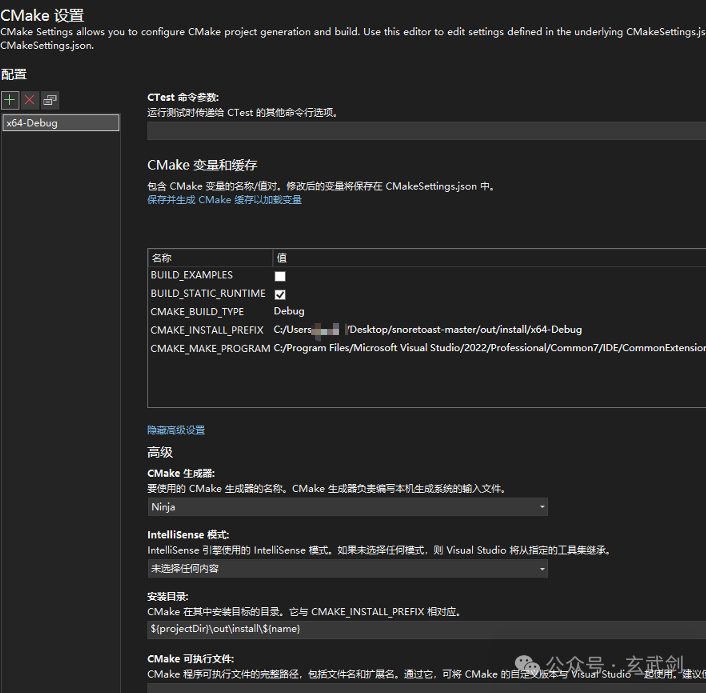
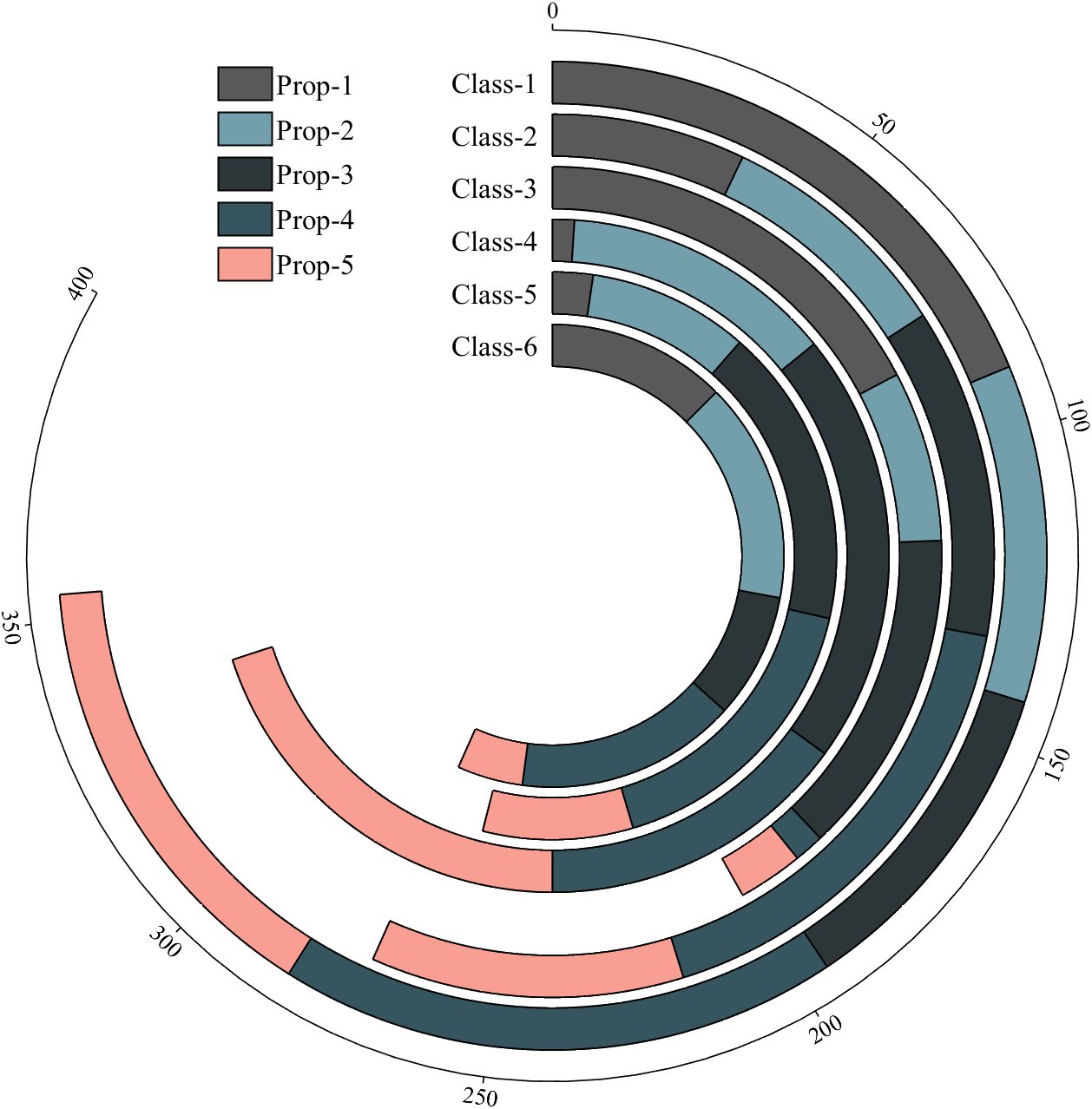
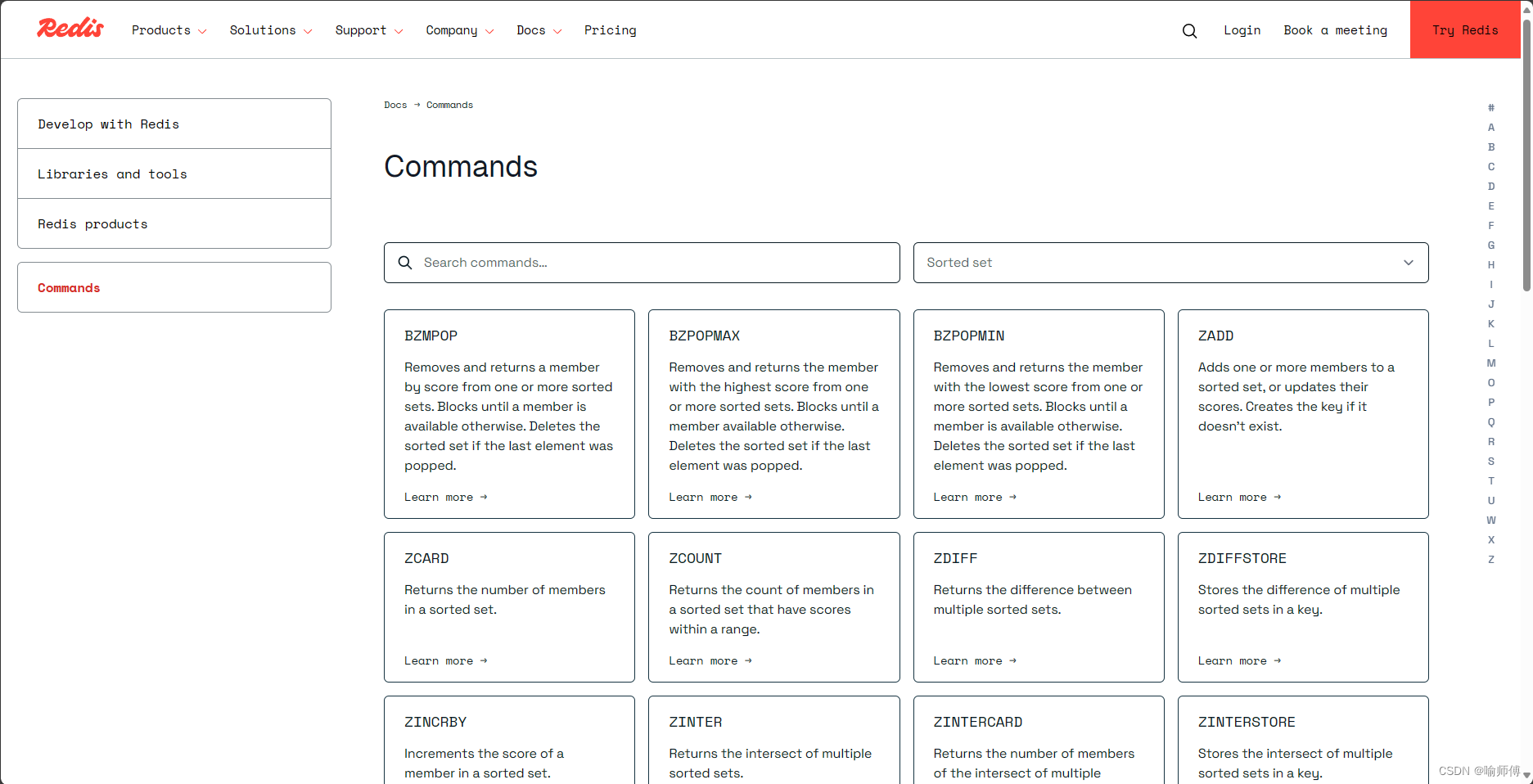
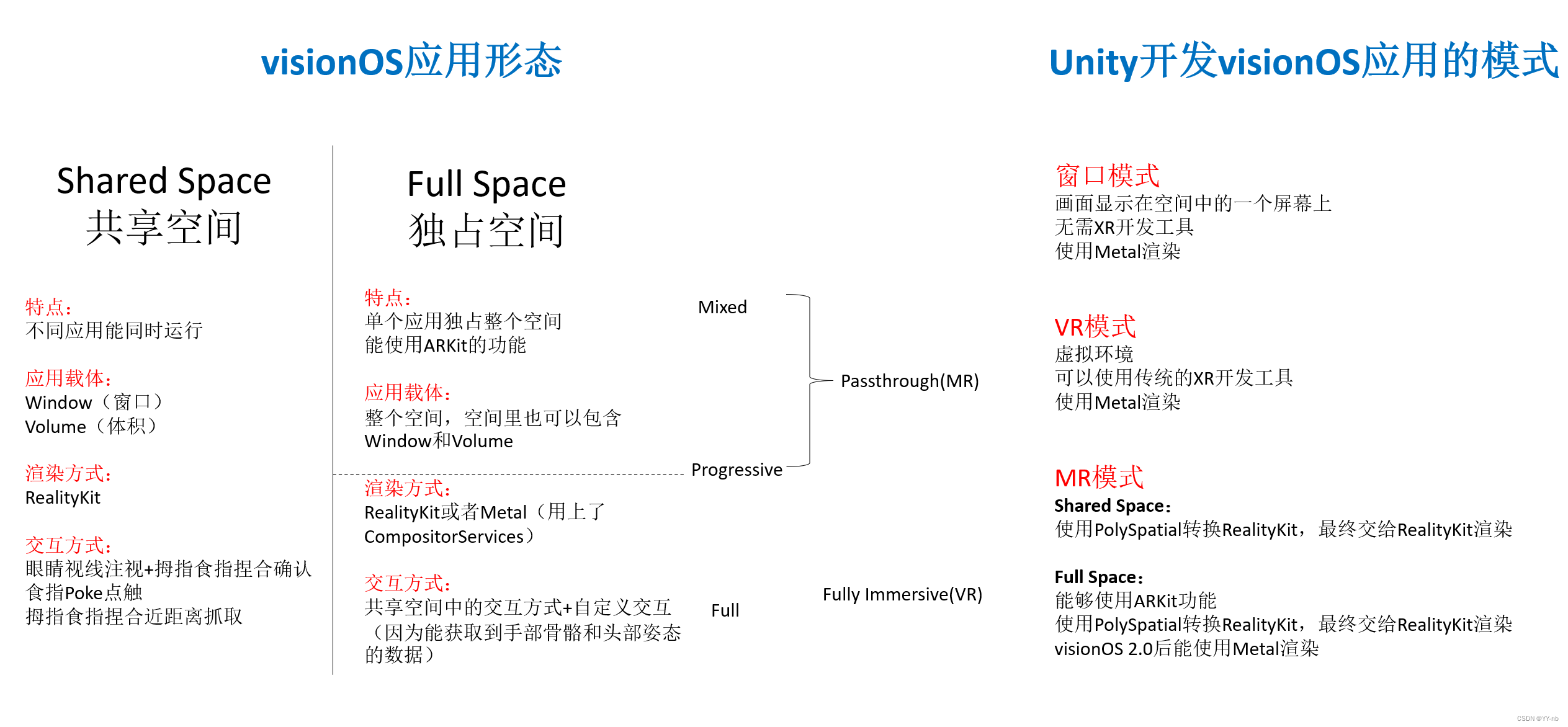
数据集 Dataset
MindSpore提供了基于Pipeline的数据引擎,通过Dataset和Transforms实现高效的数据预处理。它提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。此外,MindSpore的领域开发库也提供了大量的预加载数据集,可以使用API一键下载使用。本教程将详细介绍不同的数据集加载方式、数据集常见操作和自定义数据集方法。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14导入包
import numpy as np
from mindspore.dataset import vision
from mindspore.dataset import MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt数据集加载
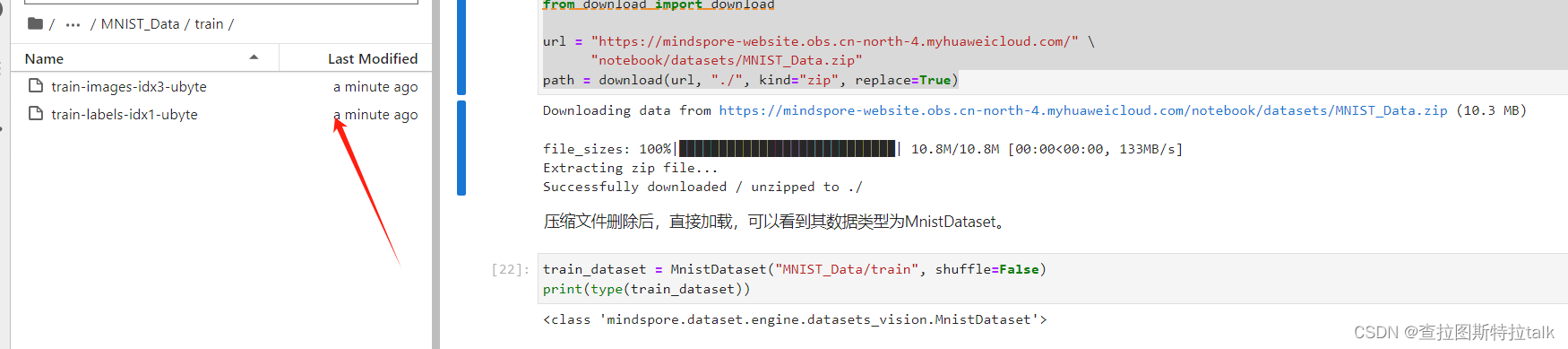
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)下载完成
数据集迭代
加载数据集后,通常以迭代方式获取数据,然后将数据送入神经网络进行训练。可以使用 create_tuple_iterator 或 create_dict_iterator 接口创建数据迭代器,以便迭代访问数据。默认情况下,访问的数据类型为Tensor;如果设置 output_numpy=True,则访问的数据类型为Numpy。
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()
visualize(train_dataset)迭代9张图片进行展示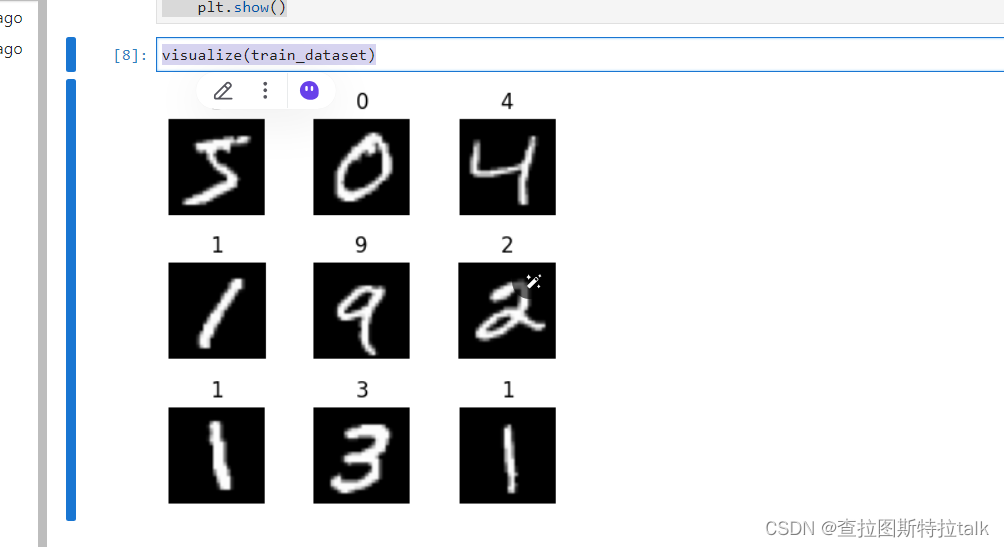
数据集常用操作
Pipeline的设计理念是采用异步执行方式来处理数据集的常用操作,通过在Pipeline中加入节点,最终进行迭代时并行执行整个Pipeline。
数据集随机shuffle可以消除数据排列造成的分布不均问题。
map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。

自定义数据集
mindspore.dataset模块提供了加载常用公开数据集和标准格式数据集的API。对于MindSpore暂不支持直接加载的数据集,可以通过构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。GeneratorDataset支持通过可随机访问数据集对象、可迭代数据集对象和生成器构造自定义数据集。
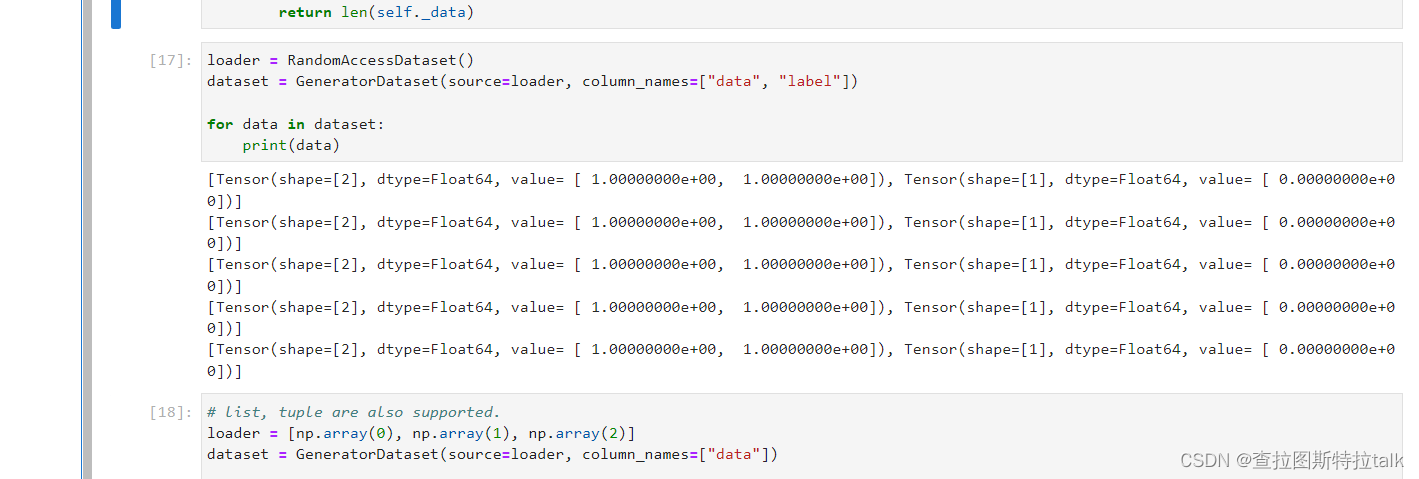
可随机访问数据集
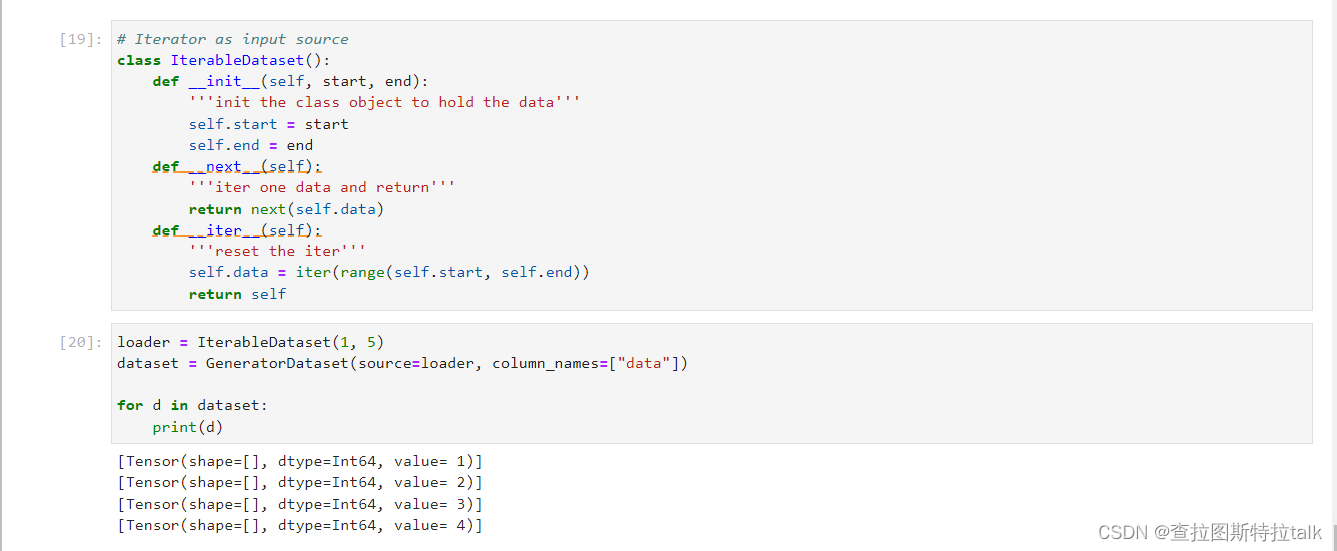
可迭代数据集
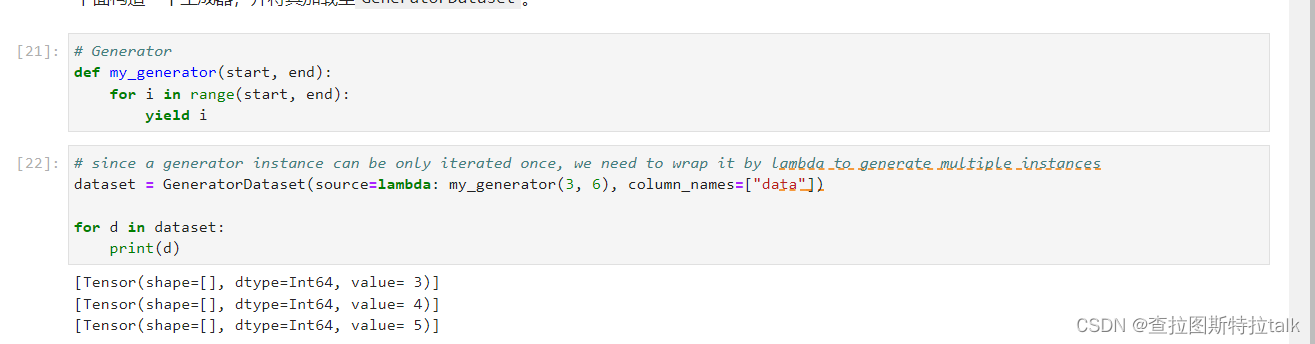
生成器
总结
这一节主要是针对数据集的一个处理。先对数据集进行一个加载迭代,进行一些常规的一些操作。最后自定义一些相关的数据集。