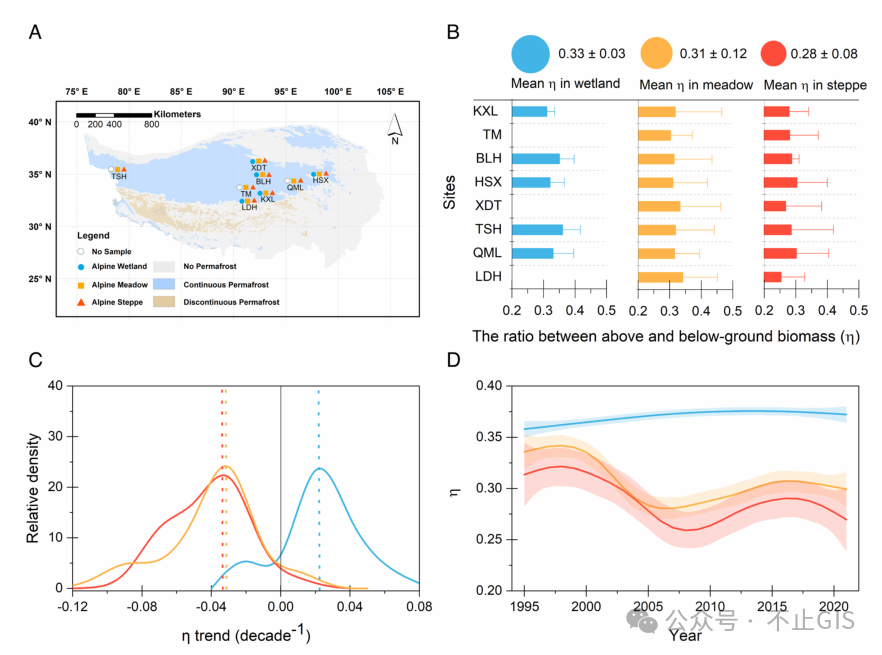
前言
🍊作者简介: 不肯过江东丶,一个来自二线城市的程序员,致力于用“猥琐”办法解决繁琐问题,让复杂的问题变得通俗易懂。
🍊支持作者: 点赞👍、关注💖、留言💌~
在之前的博客中,大聪明给各位小伙伴分享了一下如何在 Win10 环境下搭建 Kafka,相信各位小伙伴都有了属于自己的一套 Kafka 环境。今天咱们书接上文,大聪明继续和大家深入浅出的聊一聊 Kafka。
🔊 传送门:大聪明教你学kafka | Windows10系统下kafka安装及使用
假设你在工作中维护了两个服务,分别是服务A和服务B,B服务每秒只能处理100个消息,但A服务却每秒发出200个消息。在这种情况下,B服务是顶不住这么大压力的,分分钟就被堆积如山的消息给压垮了。那么问题就来了,有没有办法让B服务在不被压垮的同时还能处理掉A服务发来的消息呢?办法当然是有的,俗话说:没有什么是加一层中间层不能解决的,如果有,那就再加一层。 要引入的中间层正是我们今天要聊的消息队列Kafka。

什么是消息队列
那么什么是消息队列呢?为了保护B服务,我们很容易想到可以在B服务的内存中加入一个队列,说白了它其实是个链表,链表的每个节点就是一个消息,每个节点有一个序号,我们叫它 offset,通过这个 offset 就可以记录消息的位置。

B服务根据自己的处理能力,链表里的消息能处理多少就处理多少,并且在消费的过程中不断更新已处理消息的offset值。

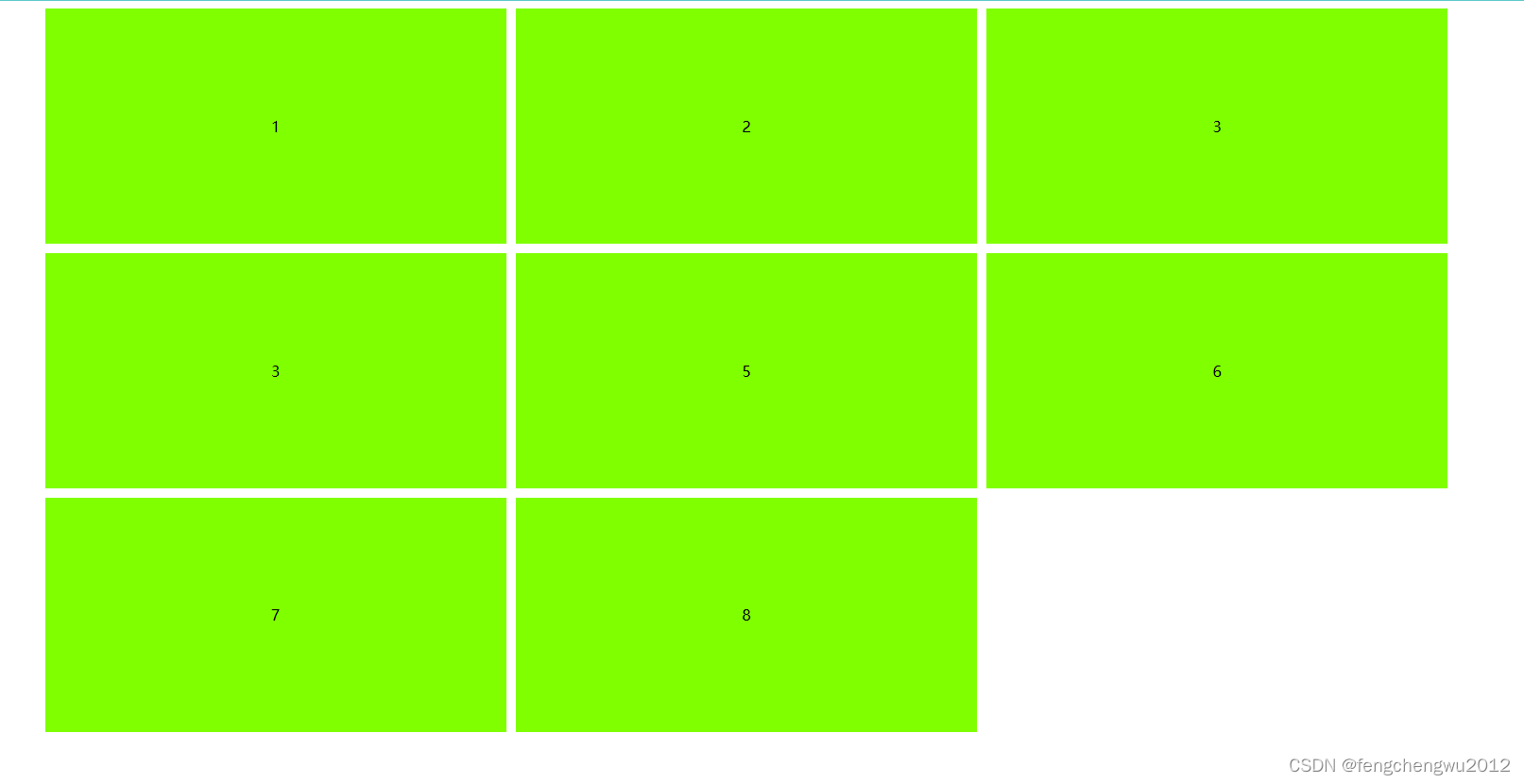
但这就引发了一个问题,B服务来不及处理的消息会堆积在内存里,如果某个时间点B服务更新重启,这些消息就都丢了。例如上图一样,如果此时B服务重启了,那么内存中的“消息3”就彻底消失不见了。为了解决这个办法,我们可以将队列挪出来变成一个单独的进程,这样就算我们重启了B服务也不会影响到了队列里的消息。也就变成了这样👇

这样一个简陋的队列进程其实就是所谓的消息队列。而像服务A这样负责发数据到消息队列的角色就是生产者Producer,像服务B这样处理消息的角色就是消费者Consumer。但这个消息队列属实过于简陋,高性能、高扩展性、高可用,它是一个都不沾边。那么我们就要对这个简陋的消息队列做一个小小的优化。
做一个小小的优化
高性能
由于服务B的性能较差,消息队列里会不断堆积数据,为了提升性能,我们可以扩展更多的消费者,这样消费速度就上去了。相对的,我们就可以增加更多生产者,提升消息队列的吞吐量。

随着生产者和消费者都变多,我们会发现他们会同时争抢同一个消息队列,抢不到的一方就得等待,这不纯纯浪费时间嘛,那么我们就要做进一步的改善了。首先是对消息进行分类,每一类是一个 topic 然后根据 topic 新增队列的数量,生产者将数据按 topic 投递到不同的队列中。消费者则根据需要订阅不同的 topic 这样就大大降低了 topic 队列的压力。

但单个 topic 的消息可能还是过多,我们可以将单个队列拆成好几段,每段就是一个 Partition 分区,每个消费者负责一个 Partition ,这样就大大降低了争抢,提升了消息队列的性能。

高扩展性
随着 Partition 多,如果 Partition 都在同一台服务器上的话,就会导致单个服务器的CPU和内存过高,影响整体系统性能。那么我们可以申请更多的服务器,将 Partition 分散部署在多台服务器上,这每一台服务器就代表一个 broker,我们可以通过增加 broker 缓解机器CPU过高带来的性能问题。

高可用
看到这,可能有些小伙伴会提出新的疑问:如果其中一个 Partition 所在的 broker 挂了,那 broker 里所有 Partition 的消息都没了,那这高可用还从何谈起 ❓❓
针对于这个问题的解决方案就更简单了。每一位女神的手机里都有那么几个被当作备胎的沸羊羊,那么我们也可以通过这样的方法来解决这个问题。我们可以给 Partition 多加几个副本,他们统称为 replicas,将他们分为 leader 和 follower。

leader 负责应付生产者和消费者的读写请求,而 follower 只管同步 leader 的消息。

将 leader 和 follower 分散到不同的 broker 上,这样 leader 所在的 broker 挂了也不会影响到 follower 所在的 broker,并且还能从 flower 中选取出一个新的 leader Partition 顶上(是不是有点像 Redis 的哨兵模式😉)。这样就保证了消息队列的高可用。
持久化和过期策略
刚刚提到的是几个 broke 挂掉的情况,那假设所有 broke 都挂了,那岂不是数据全丢了?为了解决这个问题,我们不能光把数据放内存里,还要持久化到磁盘中,这样哪怕全部 broke 都挂了,数据也不会全部丢失,在我们重启服务后也能从磁盘里读出数据继续工作。但问题又来了,磁盘总是有限的,一直往磁盘里写数据迟早有写满的一天。所以我们还可以给数据加上保留策略,也就是所谓的 Retention Policy,比如磁盘数据超过一定大小或消息放置超过一定时间就会被清理掉。
Consumer Group
到这里其实还有个问题,按现在的消费方式,每次新增的消费者只能跟着最新的offerset接着消费。如果我想让新增的消费者从某个 offerset 开始消费呢?于是引入了消费者组的概念,也就是 Consumer Group,不同消费者组维护自己的消费进度,互不打搅。

Zookeeper
相信各位聪明的小伙伴也发现了,我们刚刚讲到的组件实在是太多了,而且每个组件都有自己的数据和状态,所以还需要有个组件去统一维护这些组件的状态信息。于是我们引入了 Zookeeper 组件,他会定期和 broker 通信,获取整个 Kafka 集群的状态,以此判断某些 broker 是不是挂掉了,某些消费组消费到哪了。

什么是 Kafka
上面我们铺垫了这么多,当初那个简陋的消息队列摇身一变成了一个高性能、高扩展性、高可用、支持持久化的超强消息队列。没错,他就是我们常说的消息队列 —— Kafka。Kafka 是架构中常见的中间件之一,在博客开头讲到的场景中引入 Kafka,可以对流量削峰填谷。我们经常还能在秒杀活动、大数据和日志的异构同步中看到他的身影。
相信各位小伙伴看完以后就会对 Kafka 有了一个更深的理解,如果你觉得这篇博客对你有帮助,别忘了三连哦~
小结
本人经验有限,有些地方可能讲的没有特别到位,如果您在阅读的时候想到了什么问题,欢迎在评论区留言,我们后续再一一探讨🙇
希望各位小伙伴动动自己可爱的小手,来一波点赞+关注 (✿◡‿◡) 让更多小伙伴看到这篇文章~ 蟹蟹呦(●’◡’●)
如果文章中有错误,欢迎大家留言指正;若您有更好、更独到的理解,欢迎您在留言区留下您的宝贵想法。
你在被打击时,记起你的珍贵,抵抗恶意;
你在迷茫时,坚信你的珍贵,抛开蜚语;
爱你所爱 行你所行 听从你心 无问东西