0.引言
近年来,人工智能领域取得了令人瞩目的进步,其核心是图形处理单元(GPU)和并行计算平台的强大组合。
大模型如 GPT、BER能够理解和生成具有前所未有的流畅性和连贯性的类人文本。然而,训练这些模型需要大量的数据和计算资源,因此 GPU 和 CUDA 是这一努力中不可或缺的工具。
这个博客演示了在 Ubuntu 上设置 NVIDIA GPU 的过程,涵盖 NVIDIA 驱动程序、CUDA 工具包、cuDNN、PyTorch 等基本软件组件的安装。

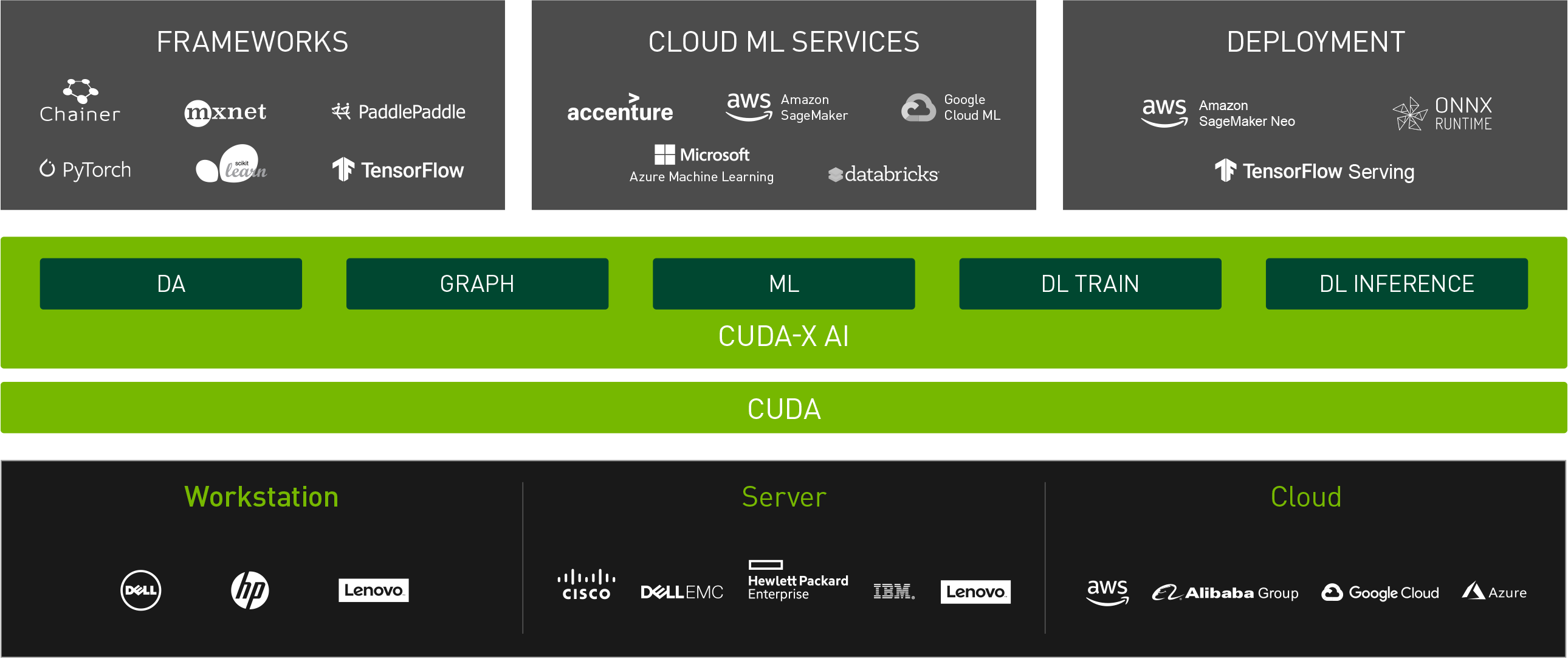
1.CUDA 加速 AI 框架的兴起
GPU 加速的深度学习得益于流行的 AI 框架的发展,这些框架利用 CUDA 实现高效计算。常用的深度学习框架如 TensorFlow, PyTorch及 MX网 都内置对 CUDA 的支持,可将 GPU 加速无缝集成到深度学习管道中。
据 NVIDIA 数据中心深度学习产品性能研究,CUDA加速的深度学习模型与基于CPU的实现相比可以实现高达数百倍的性能提升。
NVIDIA 的多实例 GPU (MIG) 技术是随 Ampere 架构引入的,该技术允许将单个 GPU 划分为多个安全实例,每个实例都有自己的专用资源。此功能可在多个用户或工作负载之间高效共享 GPU 资源,从而最大限度地提高利用率并降低总体成本。
2. 使用 NVIDIA TensorRT 加速 LLM 推理
虽然 GPU 在训练 LLM 方面发挥了重要作用,但高效的推理对于在生产环境中部署这些模型也同样重要。 英伟达 TensorRT,一种高性能深度学习推理优化器和运行时,在加速支持 CUDA 的 GPU 上的 LLM 推理方面发挥着至关重要的作用。
根据 NVIDIA 的基准测试与基于 CPU 的 GPT等大型语言模型推理相比,TensorRT 可以提供高达 5 倍的推理性能和 3 倍的总体拥有成本。
NVIDIA 对开源计划的承诺一直是 AI 研究界广泛采用 CUDA 的推动力。以下项目 神经网络, 立方玻璃及 国家控制中心 以开源库的形式提供,使研究人员和开发人员能够充分利用 CUDA 的潜力进行深度学习。
3.配置
在进行 AI 开发时,使用最新的驱动程序和库可能并不总是最好的选择。例如,虽然最新的 NVIDIA 驱动程序 (545.xx) 支持 CUDA 12.3,但 PyTorch 和其他库可能尚不支持此版本。因此,一般情况下都是使用 驱动程序版本 535.146.02,带有 CUDA 12.2 以确保兼容性。
安装步骤
3.1.安装NVIDIA驱动程序
首先,要确定的 GPU 型号。在这个演示博客中所使用是NVIDIA GPU,(NVIDIA GPU,俗称N卡,是于A卡,则别外找相关的指导文档)。关于NVIDIA GPU驱动请访问 NVIDIA 驱动程序下载页面,选择适合当前的 GPU的驱动程序,并记下驱动程序版本。
(1)在 Ubuntu 上检查预构建的 GPU 包,在命令行终端请输入:
sudo ubuntu-drivers list --gpgpu
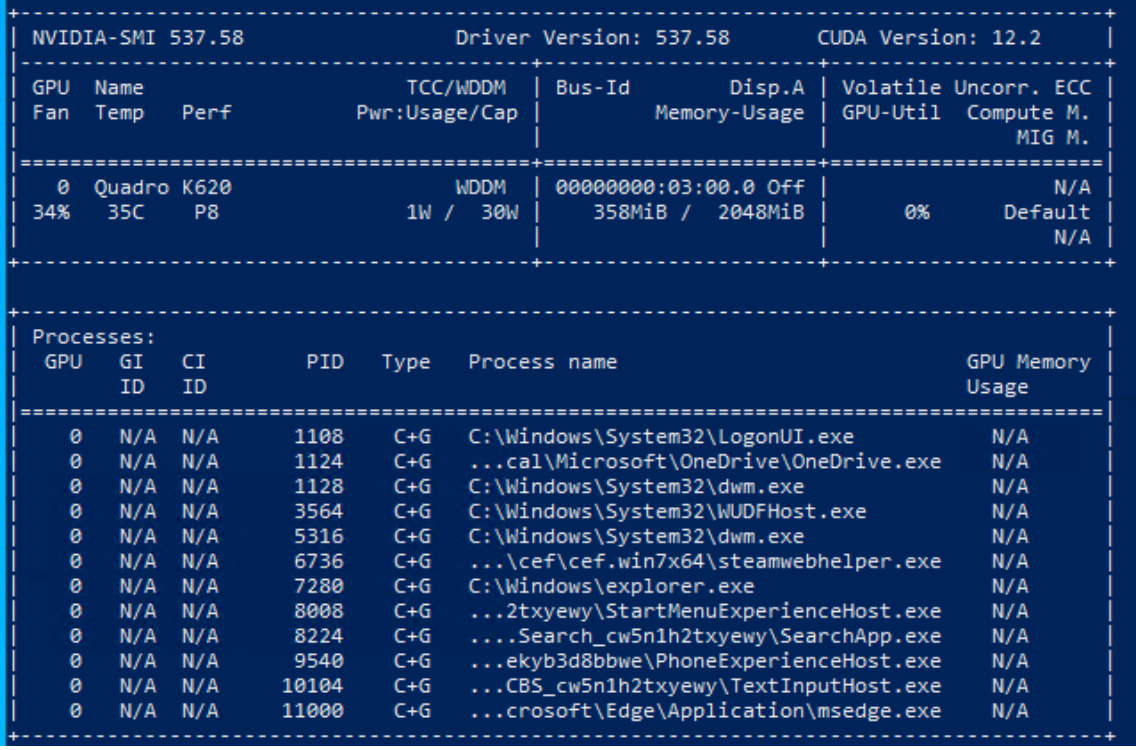
(2)然后重新启动计算机并验证安装:
nvidia-smi
3.2.安装 CUDA 工具包
CUDA 工具包提供了创建高性能 GPU 加速应用程序的开发环境。
对于非 LLM/深度学习设置,您可以使用:
sudo apt install nvidia-cuda-toolkit
However, to ensure compatibility with BitsAndBytes, we will follow these steps:
[code language="BASH"]
git clone https://github.com/TimDettmers/bitsandbytes.git
cd bitsandbytes/
bash install_cuda.sh 122 ~/local 1
验证安装:
~/local/cuda-12.2/bin/nvcc --version
设置环境变量:
export CUDA_HOME=/home/roguser/local/cuda-12.2/
export LD_LIBRARY_PATH=/home/roguser/local/cuda-12.2/lib64
export BNB_CUDA_VERSION=122
export CUDA_VERSION=122
3.3. 安装 cuDNN
下载 cuDNN 包 来自 NVIDIA 开发者网站. 使用以下命令安装:
sudo apt install ./cudnn-local-repo-ubuntu2204-8.9.7.29_1.0-1_amd64.deb
按照说明添加密钥环:
sudo cp /var/cudnn-local-repo-ubuntu2204-8.9.7.29/cudnn-local-08A7D361-keyring.gpg /usr/share/keyrings/
安装 cuDNN 库:
sudo apt update
sudo apt install libcudnn8 libcudnn8-dev libcudnn8-samples
3.4.设置Python虚拟环境
Ubuntu 22.04 自带 Python 3.10。安装 venv:
sudo apt-get install python3-pip
sudo apt install python3.10-venv
创建并激活虚拟环境:
cd
mkdir test-gpu
cd test-gpu
python3 -m venv venv
source venv/bin/activate
3.5.从源代码安装BitsAndBytes
导航到 BitsAndBytes 目录并从源代码构建:
cd ~/bitsandbytes
CUDA_HOME=/home/roguser/local/cuda-12.2/
LD_LIBRARY_PATH=/home/roguser/local/cuda-12.2/lib64
BNB_CUDA_VERSION=122
CUDA_VERSION=122
make cuda12x
CUDA_HOME=/home/roguser/local/cuda-12.2/
LD_LIBRARY_PATH=/home/roguser/local/cuda-12.2/lib64
BNB_CUDA_VERSION=122
CUDA_VERSION=122
python setup.py install
3.6.安装PyTorch
使用以下命令安装 PyTorch:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
3.7.安装 Hugging Face 和 Transformers
安装变压器和加速库:
pip install transformers
pip install accelerate
4. 并行处理的威力
从本质上讲,GPU 是高度并行的处理器,旨在高效处理数千个并发线程。这种架构使其非常适合训练深度学习模型(包括 LLM)所涉及的计算密集型任务。NVIDIA 开发的 CUDA 平台提供了一个软件环境,使开发人员能够充分利用这些 GPU 的潜力,使他们能够编写能够利用硬件并行处理功能的代码。
训练大型语言模型是一项计算要求很高的任务,需要处理大量文本数据并执行大量矩阵运算。GPU 拥有数千个核心和高内存带宽,非常适合执行这些任务。通过利用 CUDA,开发人员可以优化代码以利用 GPU 的并行处理能力,从而显著减少训练 LLM 所需的时间。
例如,要训练 GPT-3 是迄今为止最大的语言模型之一,它通过使用数千个运行 CUDA 优化代码的 NVIDIA GPU 实现。这使得该模型能够在前所未有的数据量上进行训练,从而在自然语言任务中表现出色。
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load pre-trained GPT-2 model and tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Move model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# Define training data and hyperparameters
train_data = [...] # Your training data
batch_size = 32
num_epochs = 10
learning_rate = 5e-5
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
for i in range(0, len(train_data), batch_size):
# Prepare input and target sequences
inputs, targets = train_data[i:i+batch_size]
inputs = tokenizer(inputs, return_tensors="pt", padding=True)
inputs = inputs.to(device)
targets = targets.to(device)
# Forward pass
outputs = model(**inputs, labels=targets)
loss = outputs.loss
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}')
在此示例代码片段中,演示了 GPT-2使用 PyTorch 和支持 CUDA 的 GPU 构建语言模型。该模型被加载到 GPU 上(如果可用),训练循环利用 GPU 的并行性执行高效的前向和后向传递,从而加速训练过程。
5.用于深度学习的 CUDA 加速库
除了 CUDA 平台本身,NVIDIA 和开源社区还开发了一系列 CUDA 加速库,可高效实现深度学习模型,包括 LLM。这些库提供了常见运算(例如矩阵乘法、卷积和激活函数)的优化实现,使开发人员能够专注于模型架构和训练过程,而不是低级优化。
其中一个库是 cuDNN(CUDA 深度神经网络库),它提供了深度神经网络中使用的标准例程的高度优化实现。通过利用 cuDNN,开发人员可以显著加快其模型的训练和推理速度,与基于 CPU 的实现相比,性能可提高几个数量级。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.cuda.amp import autocast
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels))
def forward(self, x):
with autocast():
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
在此代码片段中,我们使用 PyTorch 为卷积神经网络 (CNN) 定义残差块。PyTorch 的自动混合精度 (AMP) 中的 autocast 上下文管理器用于实现混合精度训练,这可以在支持 CUDA 的 GPU 上显著提高性能,同时保持高精度。F.relu 函数由 cuDNN 优化,确保在 GPU 上高效执行。
6.多 GPU 和分布式训练以实现可扩展性
随着 LLM 和深度学习模型的规模和复杂性不断增长,训练这些模型的计算要求也随之增加。为了应对这一挑战,研究人员和开发人员已转向多 GPU 和分布式训练技术,这使他们能够利用多台机器上多个 GPU 的综合处理能力。
CUDA 和相关库(例如 NCCL(NVIDIA 集体通信库))提供了高效的通信原语,可实现跨多个 GPU 的无缝数据传输和同步,从而实现前所未有的规模的分布式训练。
</pre>
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# Initialize distributed training
dist.init_process_group(backend='nccl', init_method='...')
local_rank = dist.get_rank()
torch.cuda.set_device(local_rank)
# Create model and move to GPU
model = MyModel().cuda()
# Wrap model with DDP
model = DDP(model, device_ids=[local_rank])
# Training loop (distributed)
for epoch in range(num_epochs):
for data in train_loader:
inputs, targets = data
inputs = inputs.cuda(non_blocking=True)
targets = targets.cuda(non_blocking=True)
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
在此示例中,我们使用 PyTorch 的 DistributedDataParallel (DDP) 模块演示了分布式训练。该模型封装在 DDP 中,它使用 NCCL 自动处理数据并行、梯度同步和跨多个 GPU 的通信。这种方法可以高效地在多台机器上扩展训练过程,使研究人员和开发人员能够在合理的时间内训练更大、更复杂的模型。
使用 CUDA 部署深度学习模型
虽然 GPU 和 CUDA 主要用于训练深度学习模型,但它们对于高效部署和推理也至关重要。随着深度学习模型变得越来越复杂和资源密集,GPU 加速对于 在生产环境中实现实时性能.
NVIDIA 的 TensorRT 是一款高性能深度学习推理优化器和运行时,可提供 低延迟和高吞吐量 在支持 CUDA 的 GPU 上进行推理。TensorRT 可以优化和加速在 TensorFlow、PyTorch 和 MXNet 等框架中训练的模型,从而实现在从嵌入式系统到数据中心的各种平台上的高效部署。
import tensorrt as trt
# Load pre-trained model
model = load_model(...)
# Create TensorRT engine
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
network = builder.create_network()
parser = trt.OnnxParser(network, logger)
# Parse and optimize model
success = parser.parse_from_file(model_path)
engine = builder.build_cuda_engine(network)
# Run inference on GPU
context = engine.create_execution_context()
inputs, outputs, bindings, stream = allocate_buffers(engine)
# Set input data and run inference
set_input_data(inputs, input_data)
context.execute_async_v2(bindings=bindings, stream_handle=stream.ptr)
# Process output
# ...
在此示例中,我们演示了如何使用 TensorRT 在支持 CUDA 的 GPU 上部署预训练的深度学习模型。首先由 TensorRT 解析和优化模型,生成针对特定模型和硬件定制的高度优化推理引擎。然后可以使用该引擎在 GPU 上执行高效推理,利用 CUDA 加速计算。
7. 结论
GPU 与 CUDA 的结合在推动大型语言模型、计算机视觉、语音识别和其他各种深度学习领域的进步方面发挥了重要作用。通过利用 GPU 的并行处理能力和 CUDA 提供的优化库,研究人员和开发人员可以高效地训练和部署日益复杂的模型。
随着人工智能领域的不断发展,GPU 和 CUDA 的重要性将日益凸显。借助更强大的硬件和软件优化,我们可以期待看到人工智能系统的开发和部署取得进一步突破,突破可能的界限。