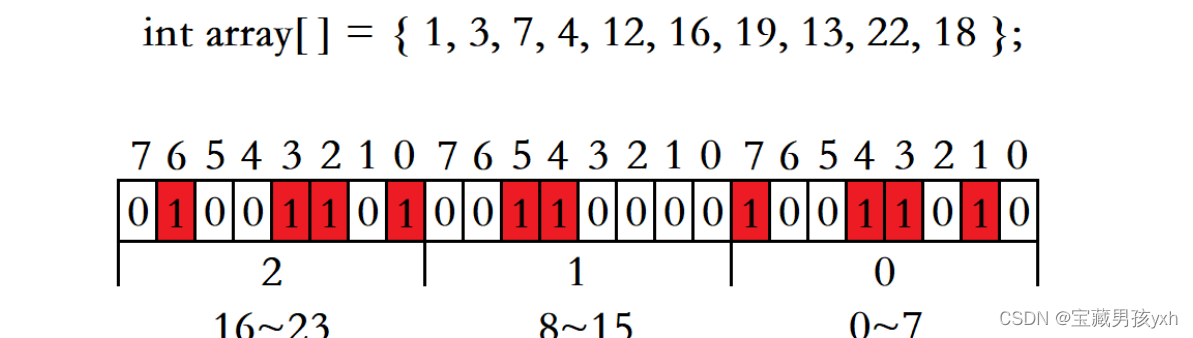
学习资料:尚硅谷_爬虫
学习环境: pycharm
一.爬虫基本概念
爬虫定义
> 解释1:通过程序,根据URL进行爬取网页,获取有用信息
> 解释2:使用程序模拟浏览器,向服务器发送请求,获取相应信息爬虫核心
> 1.爬取整个网页
> 2.解析数据,获取关心的数据
> 3.难点:爬虫VS非爬虫爬虫设计思路
> 1.确定爬取的url
> 2.模拟浏览器通过http协议访问url,获取服务器返回的html代码
> 3.解析html代码
二、urllib库基础
1.任务一:下载想要的网页、图片、视频、音频
(1)确定下载文件的url
(2)urllib.request.urlretrieve(url,文件名) 注意文件的格式(网页:html,图片:jpg、png...,视频:mp4...,音频:mp3...)
import urllib.request
#下载网页
url_page="http://www.baidu.com"
#url:下载路径,filename:文件名字
#在python中 可以变量的名字 也可以直接写值
urllib.request.urlretrieve(url_page,'baidu.html')
#下载图片
url_img="https://img2.baidu.com/it/u=1239151102,985906506&fm=253&fmt=auto&app=120&f=JPEG?w=500&h=756"
urllib.request.urlretrieve(url_img,'SunNan.jpg')
#下载视频
url_video="https://vdept3.bdstatic.com/mda-qfki2ugsvapzwmi5/360p/h264/1718974059553088160/mda-qfki2ugsvapzwmi5.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1718992706-0-0-ec02705d0acdbcc898d46a43306803c0&bcevod_channel=searchbox_feed&pd=1&cr=0&cd=0&pt=3&logid=3506132986&vid=18030693424817568764&klogid=3506132986&abtest=101830_1-102148_2-17451_1"
urllib.request.urlretrieve(url_video,'Kind Of Sadness By Sun Nan.mp4')
#下载音频
url_audio="https://ws6.stream.qqmusic.qq.com/C4000044M6Un0RXph2.m4a?guid=3844259990&vkey=FE194254F48E7427320B0F215EDE6F31C0FE911757B199D0332896D1D5E837402D5BFFD5FADE06533C81288B334789E9411E173F9FED349F&uin=2131640053&fromtag=120032"
urllib.request.urlretrieve(url_audio,"Maple.mp3")2.任务二:获取百度首页(http协议)的源码
(1)确定url:“http://www.baidu.com”
(2)模拟浏览器向服务器发送请求 response=urllib.request.urlopen(url) HTTPResponse
(3)获取页面源码 content=response.read().decode('UTF-8') 解码:二进制->字符串
#使用urllib来获取百度首页的源码
#一个类型 response:HTTPResponse
#六个方法 read、readline、readlines、getcode、geturl、getheaders
import urllib.request
#(1)定义url 就是要访问的地址
url='http://www.baidu.com'
#(2)模拟浏览器向服务器发送请求 response 是 HTTPResponse的类型
response=urllib.request.urlopen(url)
#(3)获取相应中页面源码 content 内容
#read方法 返回的是字节形式的二进制数据 需要转化为字符串
#二进制->字符串 解码 decode('编码的格式')
#read() 按照一个一个字节的去读
#read(n) 返回n个字节
#readline() 读取一行
#readlines() 一行一行读
#response.getcode() 返回状态码 如果是200了 证明逻辑没有错
#response.geturl() 返回url地址
#response.getheaders() 获取状态信息
content=response.read().decode('UTF-8')
#(4) 打印数据
print(content)3.任务三:获取百度首页(https协议)的源码(请求对象的定制)
url的组成:
例如
#https://www.baidu.com/sf/vsearch?pd=video&tn=vsearch
#url的组成
#http/https www.baidu.com 80/443 sf/vsearch pd=xxx&... #
#协议 主机 端口号 路径 参数 锚点
#协议默认端口号:http 80 https 443 mysql 3306 oracle 1521 mongodb 27017 redis 6379
UA介绍:User Agent中文名为用户代理,简称UA,它是一个特殊字符串头,是的服务器识别客户是用的操作系统及
#版本、CPU类型、浏览器及版本等等,例如Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36#UA反爬:网站通过检查请求中的User-Agent字段来判断请求是否来自正常的浏览器。如果一个请求的User-Agent字段看起来像是一个爬虫程序(例如,没有包含常见的浏览器信息或者包含明显的爬虫标识),
# 网站可能会拒绝响应这个请求,或者返回错误信息、验证码等,以此来阻止爬虫的访问。
遇到UA反爬解决策略:请求对象的定制
(1)确定url
(2)将UA字段以字典形式保存在headers中
[网页右键检查->network->刷新网页点击name栏第一行->在headers中的request Headers中查看UA]
headers={'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111'}
(3)定制请求对象request=urllib.request.Request(url=url,headers=headers)
(4)模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
(5)获取数据
content=response.read().decode('utf-8')

import urllib.request
url='https://www.baidu.com' #这里使用https协议,按之前的方法爬取,得到的只是有限数据,因为遇到了UA反爬
#headers:以字典形式保存UA字段
headers={'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111'}
#因为urlopen中不能存储字典,headers不能传递进去
#urlopen:Open the URL url, which can be either a string or a Request object.
#因为参数顺序问题,需要关键字传参
#用url和UA创建Request对象
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('UTF-8')
print(content)
4.任务四:获取百度周杰伦界面的源码(掌握urllib.parse.quote/urlencode使用)
GET和POST是HTTP协议中两种常用的请求方法,它们在数据传输和使用场景上有一些区别
GET:数据通过URL的查询字符串(query string)发送,即附加在URL后面,以
?开始,参数之间用&分隔。例如:上面的百度首页案例均是get请求
POST:数据通过请求体(request body)发送,不直接显示在URL中。例如:百度翻译首页
可以看到对于post请求类型,参数被放在请求体payload中,在form Data中可以看到各个参数

确定url: https://www.baidu.com/s?wd=周杰伦
请求方式:get请求
编码:将url中参数'周杰伦'转化为url编码,使用urllib.parse.quote(name),quote针对一个参数的转化
#https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6 wd=后面的是周杰伦的url编码
#我的需求:获取 https://www.baidu.com/s?wd=周杰伦的网页源码
import urllib.request
import urllib.parse
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111'}
url="https://www.baidu.com/s?wd="
#将周杰伦三个字变成url编码的格式,否则引发UnicodeEncodeError: 'ascii' codec can't encode characters
#需要 urllib.parse.quote()
name=urllib.parse.quote('周杰伦')
# print(name) %E5%91%A8%E6%9D%B0%E4%BC%A6
url=url+name
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('UTF-8')
print(content)
当额外增加几个参数时,如何编解码?这时候使用parse中的urlencode方法,将参数及其值表示为字典形式,作为urlencode的参数周杰伦_百度搜索
http://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&location=%E4%B8%AD%E5%9B%BD%E5%8F%B0%E6%B9%BE%E7%9C%81
#urlencode应用场景:多个参数的时候
#http://www.baidu.com/s?wd=周杰伦&sex=男&location=中国台湾省
#urllib.parse.urlencode(dict) 把字典中键值对&拼接,并转化为url码
import urllib.parse
import urllib.request
#获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&location=%E4%B8%AD%E5%9B%BD%E5%8F%B0%E6%B9%BE%E7%9C%81
base_url='https://www.baidu.com/s?'
data={
'wd':'周杰伦',
'sex':'男',
'location':'中国台湾省'
}
new_data=urllib.parse.urlencode(data)
url=base_url+new_data
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111'}
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('UTF-8')
print(content)5.任务五:获取百度翻译中输入spider翻译的信息(post请求)
post请求要点(与前面的get请求的区别)
①url中不包含参数信息
②post请求的参数必须进行被编码为二进制形式
data=urllib.parse.urlencode(data).encode('UTF-8')
③定制请求参数时除了传入url、headers,还需传入data
import urllib.request
import urllib.parse
#在百度翻译中以英文输入法模式下输入spider,在network-Name栏中找到最后一个sug,在payload中显示
#kw=spider,点击preview可以看到翻译信息,这就是我们这次任务中想要获取的数据
url="https://fanyi.baidu.com/sug"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111"}
data={
'kw':'spider'
}
#post请求的参数 必须要进行编码
# #TypeError: POST data should be bytes
data=urllib.parse.urlencode(data).encode('utf-8')
#post的请求的参数,是不会拼接在url后面的 而是放在请求对象定制的参数中
#post的请求参数
request=urllib.request.Request(url=url,data=data,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
#content是字符串形式,将其转化为json形式后查看
import json
object=json.loads(content)
print(object)
#{'errno': 0, 'data': [{'k': 'spider', 'v': 'n. 蜘蛛; 星形轮,十字叉; 带柄三脚平底锅; 三脚架'}, {'k': 'Spider', 'v': '[电影]蜘蛛'}, {'k': 'SPIDER', 'v': 'abbr. SEMATECH process induced damage effect revea'}, {'k': 'spiders', 'v': 'n. 蜘蛛( spider的名词复数 )'}, {'k': 'spidery', 'v': 'adj. 像蜘蛛腿一般细长的; 象蜘蛛网的,十分精致的'}], 'logid': 669976824}JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript编程语言的一个子集,但已经成为一种独立于语言的数据格式,广泛用于网络数据传输。
JSON数据结构以键值对的形式存在,类似于编程语言中的字典或哈希表。它支持两种结构:对象和数组。
JSON的设计目标是易于理解,同时也便于机器处理。它广泛用于Web服务中,作为客户端和服务器之间数据交换的格式。由于JSON的简洁性和通用性,它也被许多编程语言支持,如JavaScript、Python、Java、C#等,这些语言都有内置的或第三方库来解析和生成JSON数据。
6.任务六:获取百度翻译中输入love的详细翻译(面对cookie反爬)
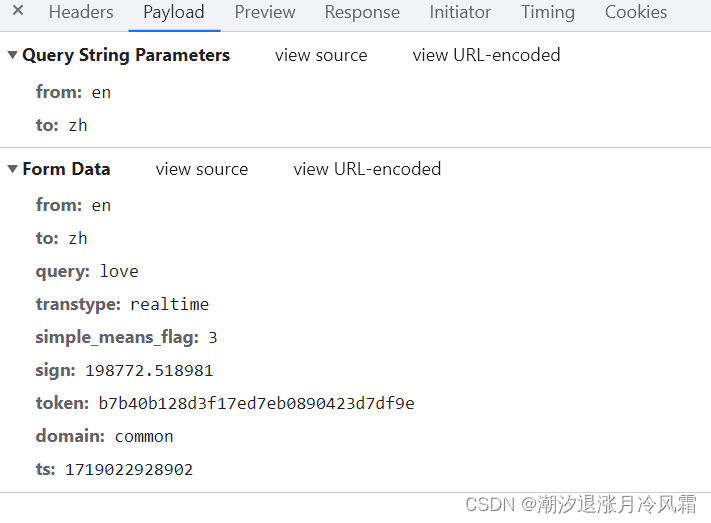
同样是post请求,首先从网页中sug中复制相关的多个参数(可以让AI帮忙转化为字典形式),使用urlencode转化为url编码拼接后进行二进制编码得到data。然后同之前的步骤处理,运行后报错。
解决策略:将包括UA内的所有的headers信息都复制到程序中,成功解决问题得到love的想详细翻译。那么这么多参数哪一个是核心的呢?逐一排除后发现只有Cookie是必须的!!!
import urllib.request
import urllib.parse
url="https://fanyi.baidu.com/v2transapi?from=en&to=zh"
#UA->完整请求头->'cookie'
headers={
#"Accept": "*/*",
#"Accept-Encoding": "gzip, deflate, br", 不接受“utf-8”编码,必须注释掉
#"Accept-Language": "zh-CN,zh;q=0.9",
#"Acs-Token": "1718971209892_1719022928933_8nzwX5twPOKQPPQ3Gs5LZGYbAri59V00Ta4ke2H7AvNlBKzPK6FHgYroNKt9mYJcsG01nwmwi39IozLVmaEF0pdbMC0UEXUrB0O8hB6lTNcvgd5HWEdhaRREE16dqgb/x2+yDM2yiqufJp0xOZ18PhxWK6vHB1c67+WwejkTJax3ZJ/2JgVvW/O6NbTYXh94IrKqykNcvhTx2IOKaNdbGgsKMaUMN2NCOPPxFFtCFLbHTdTuP+H6qls2nSqOxD95oUOkUkwP5EWPO6Z97YwL+37cvQ9CSKNl3rUlOw+X3QyyylvZd3i+vr1XyzX5VzCkD5Y/JV0QTGm/x0ApxGltv6/0Z39TKvJ8Qdi31qwcMmPdaD4PcLGYfbjGFhwQfSFTq2f1pwJwgVevqFijvhOCdO0YfoFQi8fNrOJYMM8f5YJ7j+7b72H7UdpQ7FygCvCkgsMP22O6tIpeMQyeoR/rFuiH/j/VI2q0aJss/mCpEGdDYR33bfW17uco7EKH6dPsASzMjy9JznU6X0WPB6ft7EtsHTM4xWWTMN/JyDwmkhk=",
#"Connection": "keep-alive",
#"Content-Length": "152",
#"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "PSTM=1706692650; BIDUPSID=9EC23CDD0A68506C733194BAC20084DC; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BAIDUID=038EB8BBA6B3B98D0F3CD34454C2B3D0:SL=0:NR=10:FG=1; APPGUIDE_10_7_2=1; smallFlowVersion=old; BDUSS=ZuSE54fmRta2JxcDJqaHNDZTl1dWt4alVTTkZZekNyMVNDb0JWazVQTGxYb2xtSVFBQUFBJCQAAAAAAAAAAAEAAADgYXqpxKfBpsH6zf4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOXRYWbl0WFmM0; BDUSS_BFESS=ZuSE54fmRta2JxcDJqaHNDZTl1dWt4alVTTkZZekNyMVNDb0JWazVQTGxYb2xtSVFBQUFBJCQAAAAAAAAAAAEAAADgYXqpxKfBpsH6zf4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOXRYWbl0WFmM0; APPGUIDE_10_7_6=1; MCITY=-%3A; H_PS_PSSID=60325_60338_60346_60375; H_WISE_SIDS=60325_60338_60346_60375; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_WISE_SIDS_BFESS=60325_60338_60346_60375; delPer=0; PSINO=1; BAIDUID_BFESS=038EB8BBA6B3B98D0F3CD34454C2B3D0:SL=0:NR=10:FG=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1716720771,1716993063,1718525943,1719019024; APPGUIDE_10_7_1=1; BA_HECTOR=208ka025052lag0504a001ah1rpknh1j7ca2b1u; ZFY=qJR93VzT2VCx9I9zcuFIZz:A2i9qHFnc7vfUK5FlgszQ:C; ZD_ENTRY=baidu; __bid_n=19039d5e2da491256372a5; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1719022909; ab_sr=1.0.1_MGU3OTVlZDgwMzZlYjQxZTc4YTRkMTE1NmZhM2U5NWI0YTgzMjMyMWEyMDFkMTQyZjY4YTg4Y2IxM2NhOTEwYjYzMGI3ZDgzYmQ1YmYxYWJhMzkyODk2YmQ4OTJmZWEzNjI1MTE3YWMxNzgzNDRiMjA2MzY3MWRjMjI1YmVlYzEwYjQ2M2YwN2NhNGU3MDViZWZmMzYyY2Y0NDBkZTBhODNkMGVlZTJmZTFiNzQ1MTIwY2JmMjY0ODM1ZDA5NDk0",
#"Host": "fanyi.baidu.com",
#"Origin": "https://fanyi.baidu.com",
#"Referer": "https://fanyi.baidu.com/?aldtype=16047&ext_channel=Aldtype",
#"sec-ch-ua": "\"Chromium\";v=\"9\", \"Not?A_Brand\";v=\"8\"",
#"sec-ch-ua-mobile": "?0",
#"sec-ch-ua-platform": "\"Windows\"",
#"Sec-Fetch-Dest": "empty",
#"Sec-Fetch-Mode": "cors",
#"Sec-Fetch-Site": "same-origin",
#"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111",
#"X-Requested-With": "XMLHttpRequest"
}
data={
"from": "en",
"to": "zh",
"query": "love",
"transtype": "realtime",
"simple_means_flag": "3",
"sign": "198772.518981",
"token": "b7b40b128d3f17ed7eb0890423d7df9e",
"domain": "common",
"ts": "1719022928902"
}
#post请求 参数必须进行编码
data=urllib.parse.urlencode(data).encode('UTF-8')
#请求对象定制
request=urllib.request.Request(url=url,data=data,headers=headers)
#模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
#获取响应数据
content=response.read().decode('utf-8')
import json
obj=json.loads(content)
print(obj)7.任务七:获取豆瓣电影第一页的数据(ajax中的get请求)
前端中的AJAX(Asynchronous JavaScript and XML)是一种在无需重新加载整个页面的情况下,能够更新部分网页的技术。它通过在后台与服务器进行少量数据交换,使得网页可以异步地更新内容,从而提供更流畅的用户体验。
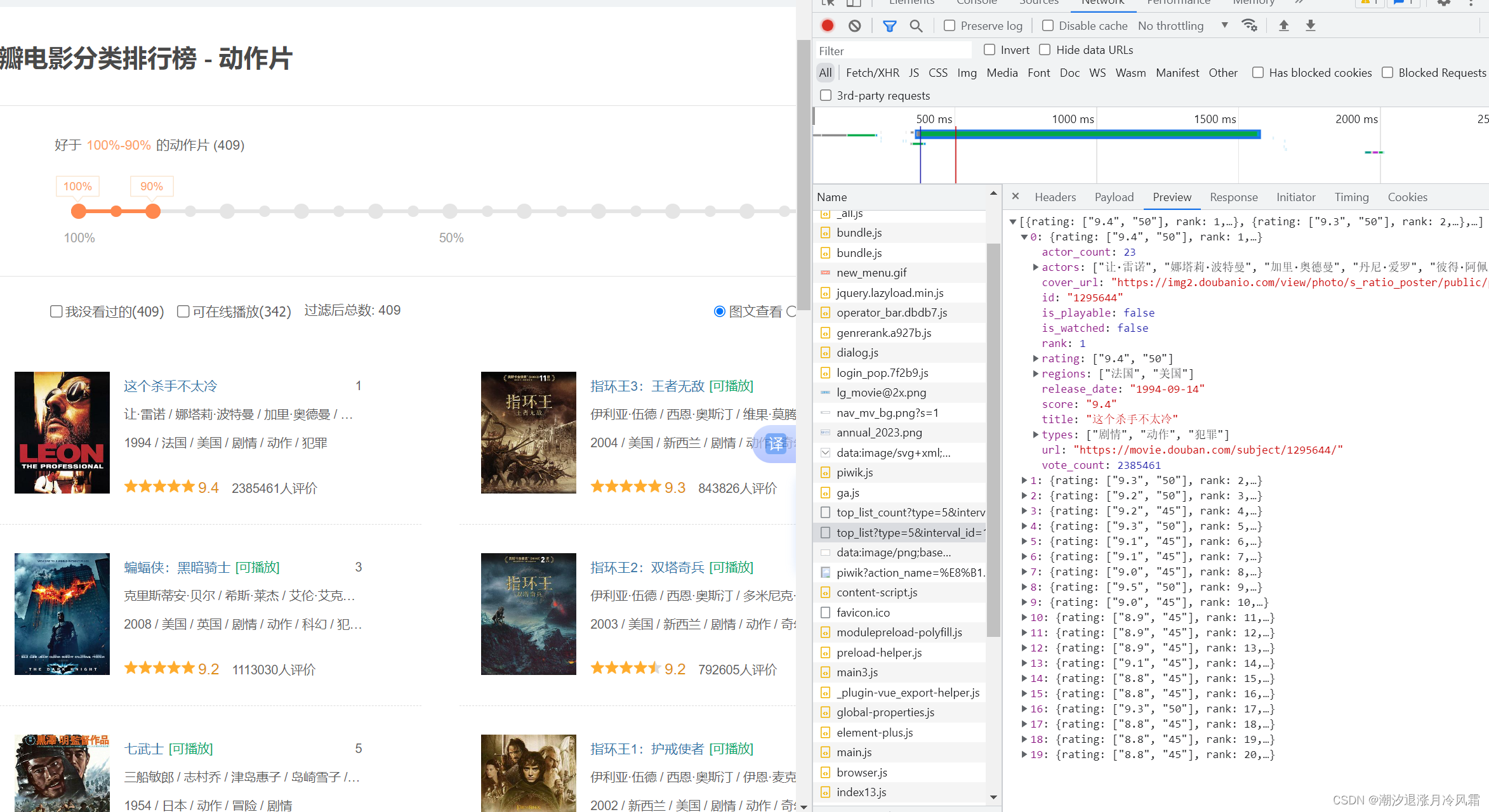
用这个例子熟悉get请求时的步骤:
(1)确定url (2)确定UA (3)定制请求对象 (4)模拟浏览器向服务器发出请求
(5)获得数据并解码为字符串形式
这里最后利用文件操作的知识,把数据保存在douban.jason中
import urllib.request
import urllib.parse
url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111"}
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
#数据下载到本地,写入jason类型文件
#open方法默认情况下使用的是gbk的编码,想要保存汉字,需要在open方法中指定编码格式为utf-8,encoding='utf-8'
# fp=open('douban.jason','w',encoding='utf-8')
# fp.write(content)
with open('double1.jason','w',encoding='utf-8') as fp:
fp.write(content)8.任务八:获取豆瓣电影前十页的数据(ajax中的get请求)
在任务七的基础上任务升级。首先通过向下移动界面记录不同page对应的url寻找规律。
很容易发现不同点在于参数中start的值,并且有规律:start=20(page-1)
对每一页我们的核心步骤是:
(1)定制请求对象,封装函数create_request;要点是通过字符串拼接得到不同page对应的url,使用urlencode方法将start和limit组合
(2)获取响应的数据,封装函数get_content;
(3)下载数据,封装函数down_load.
import urllib.request
import urllib.parse
#找前十页url规律
# page1:https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
# page2:https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
# page3:https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=30&limit=20
#pagen->start=20(page-1)
#下载豆瓣电影前十页的数据
#(1)请求对象的定制
#(2)获取响应的数据
#(3)下载数据
def create_request(page):
base_url="https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&"
data={
'start':20*(page-1),
'limit':20
}
url=base_url+urllib.parse.urlencode(data)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111"
}
request=urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('UTF-8')
return content
def down_load(page,content):
with open('douban'+str(page)+'.json','w', encoding='utf-8') as fp:
fp.write(content)
#程序的入口
if __name__=='__main__':
start_page=int(input('请输入起始的页码:'))
end_page=int(input('请输入结束的页码:'))
for page in range(start_page,end_page+1):
#每一页都有自己请求对象的定制
request=create_request(page)
#每一页获取响应的数据
content=get_content(request)
#下载每一页数据
down_load(page,content)9.任务九:获取KFC官网广州餐厅十页信息
import urllib.request
import urllib.parse
#1页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
#cname: 广州
#pid:
#pageIndex: 1
# pageSize: 10
#2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
#cname: 广州
#pid:
#pageIndex: 2
# pageSize: 10
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/111"
}
def create_request(page):
data={
'cname':'广州',
'pid':'',
'pageIndex':page,
'pagesize':10
}
data=urllib.parse.urlencode(data).encode('UTF-8')
request=urllib.request.Request(url=url,data=data,headers=headers)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def down_load(page,content):
with open('KFC'+str(page)+'.json','w',encoding='UTF-8') as fp:
fp.write(content)
if __name__=='__main__':
start_page=int(input('输入起始的页码:'))
end_page = int(input('输入最后的页码:'))
for page in range(start_page,end_page+1):
request=create_request(page)
content=get_content(request)
down_load(page,content)累了o(╥﹏╥)o,这个任务的要点是进一步熟练掌握post请求的处理方法,然后同任务八,面对多页面时,先找页之间的url规律,然后使用循环、函数、文件等基础知识,下载所需的数据。
10.异常处理
简介:1.HTTPError类是URLError类的子类
2.导入的包urllib.error.HTTPError urllib.error.URLErron
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出了问题。
4.通过ur11ib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try-except进行捕获异常,异常有两类,URLError\HTTPError
**HTTPError**: `HTTPError`是一个特定于HTTP协议的异常,它是`URLError`的子类。当使用`urllib`库发送HTTP请求时,如果服务器返回了一个HTTP错误状态码(如404 Not Found、500 Internal Server Error等),就会抛出`HTTPError`。这个异常包含了HTTP响应的详细信息,如状态码、原因短语和响应头。
**URLError**: `URLError`表示更一般的网络错误,它通常发生在网络请求无法完成的情况下,比如网络不可达、DNS解析失败、服务器不存在等。`URLError`通常由`urlopen`函数抛出,当它无法建立到服务器的连接时。