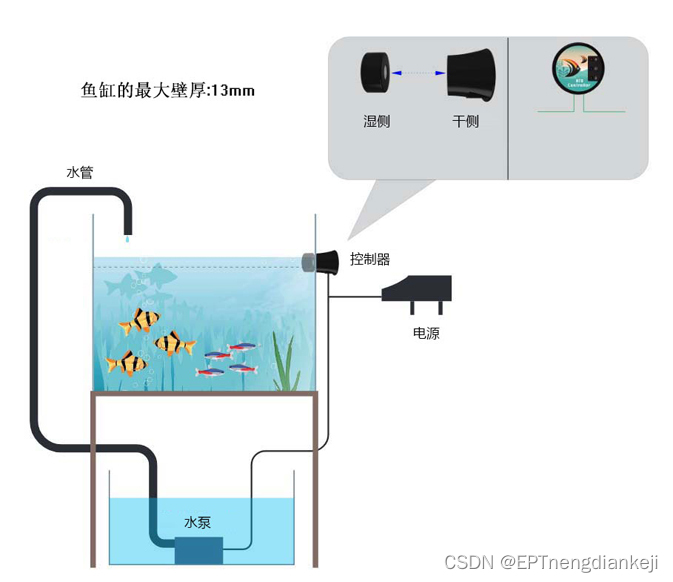
用自己的数据集训练TimeSformer并转ONNX用c++推理
文章目录
- 用自己的数据集训练TimeSformer并转ONNX用c++推理
-
- 下载安装TimeSformer
- 创建分类文件夹
- 创建数据集
- 修改训练配置
- 运行脚本开始训练
- 测试模型
- 模型转为onnx
- 测试一下生成的onnx模型
- 转为用c++推理
下载安装TimeSformer
TimeSformer开源地址
按照官方教程安装好环境。
如果报下面这个错误,是因为新版的pytorch已经不支持那种写法了,需要修改一下。
ImportError: cannot import name '_LinearWithBias' from 'torch.nn.modules.linear'
可以参考这个人的fork修改
创建分类文件夹
我这里有61个动作分类,每个分类创建一个文件夹

将视频文件分割成 每个视频大概10s左右;
然后将视频文件按照分类放到每个文件夹里。
创建数据集
写一个脚本分割数据集,并生成标签文件
import os
import csv
import shutil
from tqdm import tqdm
from sklearn.model_selection import train_test_split
out_dir = "/home/disk/liangbaikai/TimeSformer/mydata/mydatasets" # 输出路径
video_path = "/home/disk/liangbaikai/TimeSformer/mydata/myvideos" # 数据集路径
file_name = ".csv"
name_list = ["train","test","val"]
if not os.path.exists(out_dir):
os.mkdir(out_dir)
if not os.path.exists(os.path.join(out_dir, 'train')):
os.mkdir(os.path.join(out_dir, 'train'))
if not os.path.exists(os.path.join(out_dir, 'val')):
os.mkdir(os.path.join(out_dir, 'val'))
if not os.path.exists(os.path.join(out_dir, 'test')):
os.mkdir(os.path.join(out_dir, 'test'))
for file in os.listdir(video_path):
file_path = os.path.join(video_path, file)
video_files = [name for name in os.listdir(file_path)]
#将20%的数据分配给test
train_and_valid, test = train_test_split(video_files, test_size=0.2, random_state=42)
#将80%的数据再分配20%出来给val,剩下的给train
train, val = train_test_split(train_and_valid, test_size=0.2, random_state=42)
train_dir = os.path.join(out_dir, 'train', file)
val_dir = os.path.join(out_dir, 'val', file)
test_dir = os.path.join(out_dir, 'test', file)
if not os.path.exists(train_dir):
os.mkdir(train_dir)
if not os.path.exists(val_dir):
os.mkdir(val_dir)
if not os.path.exists(test_dir):
os.mkdir(test_dir)
for video in tqdm(train):
shutil.copy(os.path.join(video_path,file,video),os.path.join(train_dir,video))
for video in tqdm(test):
shutil.copy(os.path.join(video_path,file,video),os.path.join(test_dir,video))
for video in tqdm(val):
shutil.copy(os.path.join(video_path,file,video),os.path.join(val_dir,video))
#输出路径下创建csv文件夹,并在文件夹下创建train.csv val.csv test.csv
csv_path = os.path.join(out_dir,"csv")
if not os.path.exists(csv_path):
os.mkdir(csv_path)
for name in name_list:
with open(os.path.join(csv_path,name+file_name),'wb') as f:
print("创建"+os.path.join(csv_path,name+file_name))
for ii in os.listdir(csv_path):
if ii.split(".")[0] in name_list:
path1 = os.path.join(csv_path,ii)
with open(path1, 'w', newline='') as f:
for dd in os.listdir(out_dir):
if dd==ii.split(".")[0]:
for zz in os.listdir(os.path.join(out_dir,dd)):
for mm in os.listdir(os.path.join(out_dir,dd,zz)):
writer = csv.writer(f)
writer.writerow([os.path.join(out_dir,dd,zz,mm),zz])
## 创建类别label标号文件
labels= []
for label in sorted(os.listdir(video_path)):
labels.append(label)
label2index = {
label: index for index, label in enumerate(sorted(set(labels)))}
label_file = os.path.join(out_dir, str(len(os.listdir(video_path))) + 'class_labels.txt')
with open(label_file, 'w') as f:
for id, label in enumerate(sorted(label2index)):
f.writelines(str(id) + ' ' + label +'\n')
#替换csv文件中类别名为数字
csv_file = os.path.join(out_dir,"csv")
def txt_read(files):
txt_dict = {
}
fopen = open(files)
for line in fopen.readlines():
line = str(line).replace('\n','')
txt_dict[line.split(' ',1)[1]] = line.split(' ',1)[0]
fopen.close()
return txt_dict
txt_dict = txt_read(label_file)
print(txt_dict)
for ii in os.listdir(csv_file):
path1 = os.path.join(csv_file,ii)
r = csv.reader(open(path1))
lines = [l for l in r]
for i in range(







![[C++ STL] list 详解](https://img-blog.csdnimg.cn/direct/0825024dcc1f453b963c03491a097877.png)