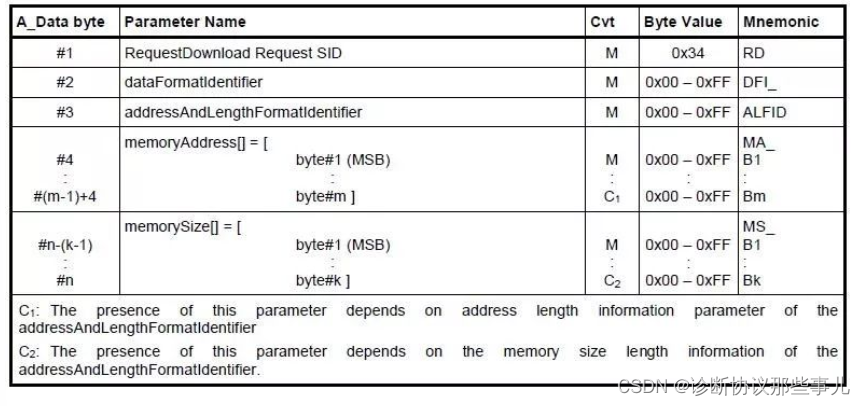
基于R 4.2.2版本演示
一、写在前面
有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。
答曰:可!用GPT或者Kimi转一下就得了呗。
加上最近也没啥内容写了,就帮各位搬运一下吧。
二、R代码实现KNN分类
(1)导入数据
我习惯用RStudio自带的导入功能:
(2)建立KNN模型
# Load necessary libraries
library(caret)
library(pROC)
library(ggplot2)
# Assume 'data' is your dataframe containing the data
# Set seed to ensure reproducibility
set.seed(123)
# Split data into training and validation sets (80% training, 20% validation)
trainIndex <- createDataPartition(data$X, p = 0.8, list = FALSE)
trainData <- data[trainIndex, ]
validData <- data[-trainIndex, ]
# Convert the target variable to a factor for classification
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)
# Define control method for training with cross-validation
trainControl <- trainControl(method = "cv", number = 10)
# Fit KNN model on the training set
model <- train(X ~ ., data = trainData, method = "knn", trControl = trainControl, preProcess = "scale")
# Predict on the training and validation sets
trainPredict <- predict(model, trainData, type = "prob")[,2]
validPredict <- predict(model, validData, type = "prob")[,2]
# Convert true values to factor for ROC analysis
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)
# Calculate ROC curves and AUC values
trainRoc <- roc(response = trainData$X, predictor = trainPredict)
validRoc <- roc(response = validData$X, predictor = validPredict)
# Plot ROC curves with AUC values
ggplot(data = data.frame(fpr = trainRoc$specificities, tpr = trainRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +
geom_line(color = "blue") +
geom_area(alpha = 0.2, fill = "blue") +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +
ggtitle("Training ROC Curve") +
xlab("False Positive Rate") +
ylab("True Positive Rate") +
annotate("text", x = 0.5, y = 0.1, label = paste("Training AUC =", round(auc(trainRoc), 2)), hjust = 0.5, color = "blue")
ggplot(data = data.frame(fpr = validRoc$specificities, tpr = validRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +
geom_line(color = "red") +
geom_area(alpha = 0.2, fill = "red") +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +
ggtitle("Validation ROC Curve") +
xlab("False Positive Rate") +
ylab("True Positive Rate") +
annotate("text", x = 0.5, y = 0.2, label = paste("Validation AUC =", round(auc(validRoc), 2)), hjust = 0.5, color = "red")
# Calculate confusion matrices based on 0.5 cutoff for probability
confMatTrain <- table(trainData$X, trainPredict >= 0.5)
confMatValid <- table(validData$X, validPredict >= 0.5)
# Function to plot confusion matrix using ggplot2
plot_confusion_matrix <- function(conf_mat, dataset_name) {
conf_mat_df <- as.data.frame(as.table(conf_mat))
colnames(conf_mat_df) <- c("Actual", "Predicted", "Freq")
p <- ggplot(data = conf_mat_df, aes(x = Predicted, y = Actual, fill = Freq)) +
geom_tile(color = "white") +
geom_text(aes(label = Freq), vjust = 1.5, color = "black", size = 5) +
scale_fill_gradient(low = "white", high = "steelblue") +
labs(title = paste("Confusion Matrix -", dataset_name, "Set"), x = "Predicted Class", y = "Actual Class") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1), plot.title = element_text(hjust = 0.5))
print(p)
}
# Now call the function to plot and display the confusion matrices
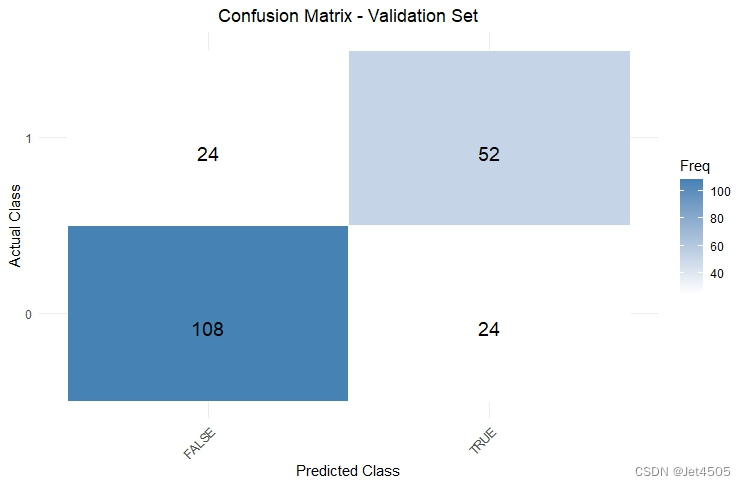
plot_confusion_matrix(confMatTrain, "Training")
plot_confusion_matrix(confMatValid, "Validation")
# Extract values for calculations
a_train <- confMatTrain[1, 1]
b_train <- confMatTrain[1, 2]
c_train <- confMatTrain[2, 1]
d_train <- confMatTrain[2, 2]
a_valid <- confMatValid[1, 1]
b_valid <- confMatValid[1, 2]
c_valid <- confMatValid[2, 1]
d_valid <- confMatValid[2, 2]
# Training Set Metrics
acc_train <- (a_train + d_train) / sum(confMatTrain)
error_rate_train <- 1 - acc_train
sen_train <- d_train / (d_train + c_train)
sep_train <- a_train / (a_train + b_train)
precision_train <- d_train / (b_train + d_train)
F1_train <- (2 * precision_train * sen_train) / (precision_train + sen_train)
MCC_train <- (d_train * a_train - b_train * c_train) / sqrt((d_train + b_train) * (d_train + c_train) * (a_train + b_train) * (a_train + c_train))
auc_train <- roc(response = trainData$X, predictor = trainPredict)$auc
# Validation Set Metrics
acc_valid <- (a_valid + d_valid) / sum(confMatValid)
error_rate_valid <- 1 - acc_valid
sen_valid <- d_valid / (d_valid + c_valid)
sep_valid <- a_valid / (a_valid + b_valid)
precision_valid <- d_valid / (b_valid + d_valid)
F1_valid <- (2 * precision_valid * sen_valid) / (precision_valid + sen_valid)
MCC_valid <- (d_valid * a_valid - b_valid * c_valid) / sqrt((d_valid + b_valid) * (d_valid + c_valid) * (a_valid + b_valid) * (a_valid + c_valid))
auc_valid <- roc(response = validData$X, predictor = validPredict)$auc
# Print Metrics
cat("Training Metrics\n")
cat("Accuracy:", acc_train, "\n")
cat("Error Rate:", error_rate_train, "\n")
cat("Sensitivity:", sen_train, "\n")
cat("Specificity:", sep_train, "\n")
cat("Precision:", precision_train, "\n")
cat("F1 Score:", F1_train, "\n")
cat("MCC:", MCC_train, "\n")
cat("AUC:", auc_train, "\n\n")
cat("Validation Metrics\n")
cat("Accuracy:", acc_valid, "\n")
cat("Error Rate:", error_rate_valid, "\n")
cat("Sensitivity:", sen_valid, "\n")
cat("Specificity:", sep_valid, "\n")
cat("Precision:", precision_valid, "\n")
cat("F1 Score:", F1_valid, "\n")
cat("MCC:", MCC_valid, "\n")
cat("AUC:", auc_valid, "\n")在R语言中,caret包提供了一个通用的接口来训练KNN模型。使用caret的train函数来训练KNN模型时,可以调整多种参数来优化模型的性能:
基本参数:
①formula: 指定模型的公式,如Y ~ .,表示使用数据框中的所有其他变量来预测Y。
②data: 提供包含训练数据的数据框。
③method: 对于KNN模型,这个参数应设置为"knn"。
④preProcess: 预处理步骤,常用的包括标准化("scale")和中心化("center"),对于KNN这一步非常重要因为KNN依赖于变量的距离度量。
⑤trControl: 一个trainControl对象,定义了模型训练的各种控制策略,如交叉验证的类型和重复次数。
trainControl 函数的参数:
①method: 训练的方法,如交叉验证("cv"),重复交叉验证("repeatedcv"),留一交叉验证("LOOCV")等。
②number: 对于"cv"和"repeatedcv",这个参数定义了折数。
③repeats: 当使用"repeatedcv"时,定义重复的次数。
④search: 参数搜索方法,默认为"grid"。也可以设置为"random"进行随机搜索。
⑤savePredictions: 是否保存预测结果,通常用于后续分析。
模型性能调整参数:
使用KNN时,最关键的参数之一是邻居的数量(K值)。这可以通过train函数的以下参数来调整:
①tuneLength: 这个参数决定了在参数搜索中考虑多少个不同的K值。
②tuneGrid: 这是一个数据框,可以自定义K值的具体范围,例如expand.grid(k = c(1, 5, 10))
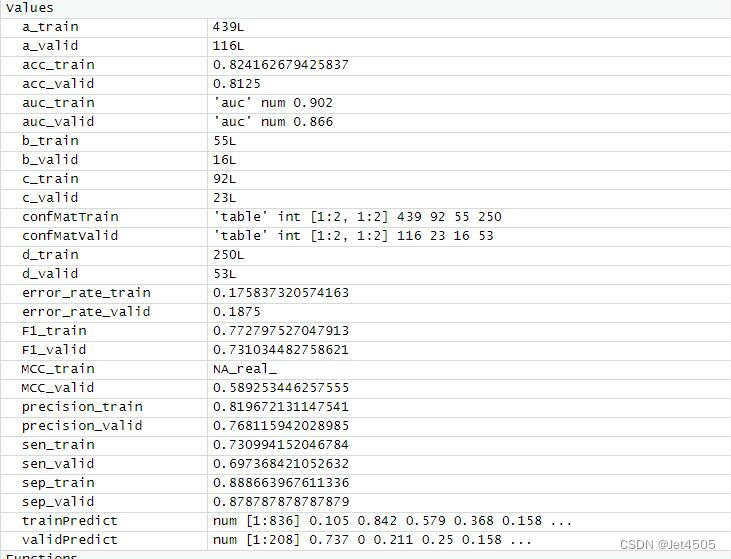
结果输出(默认参数):



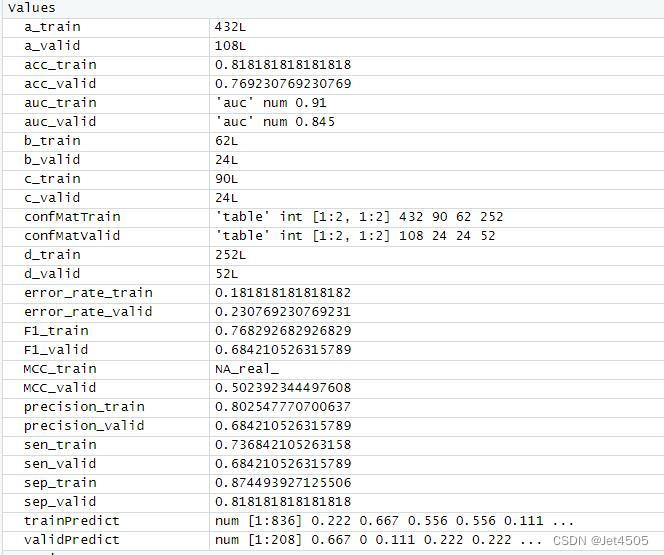
三、KNN调参方法
如前所述,KNN的关键参数就是K值,所以可以对其进行一个暴力测试,比如取值1到10:
# 定义交叉验证的控制方法,启用网格搜索
trainControl <- trainControl(method = "cv", number = 10)
# 定义K值的网格搜索范围
tuneGrid <- expand.grid(k = 1:10)
# 在训练集上拟合KNN模型,指定网格搜索的K值
model <- train(X ~ ., data = trainData, method = "knn", trControl = trainControl,
tuneGrid = tuneGrid, preProcess = "scale")
# 查看模型结果,找出最优的K值
print(model)解读:
①定义交叉验证的控制方法:使用trainControl函数设定交叉验证的详细参数。
②定义K值的网格:使用tuneGrid参数在train函数中指定K值的范围。
③拟合模型:使用train函数训练模型,同时应用预处理步骤(比如标准化数据),以确保每个特征在距离计算中具有等同的权重。
结果输出:
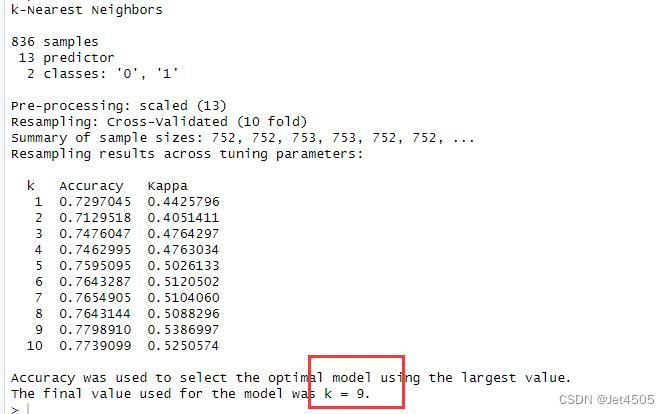
注意:用了caret包的train函数,并且通过网格搜索指定了一系列的参数(如K值的范围),那么这个函数会自动选择表现最好的参数配置来训练最终的模型。train函数的输出即是基于你提供的训练数据和参数搜索范围内表现最优的模型。因此,当你调用predict函数进行预测时,使用的就是这个最优化的模型。所以,下面的代码不变。
结果吧,跟之前的完全一样:
因为caret包对于KNN模型默认进行一系列的K值尝试,通常这个范围是1到最多的邻居数,但具体的最大K值依赖于caret的内部设置。在大多数情况下,它会尝试如1, 5, 7, 9等常用的K值。所以,我们默认参数的时候,其实软件自动给我们寻找最优K值了。可以用这个代码输出最有K值:
# Print the best K value used by the model
best_k <- model$bestTune$k
cat("The best K value found is:", best_k, "\n")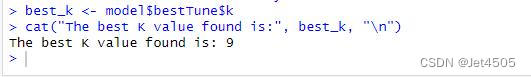
K值就是9,跟我们自行调参的一致。
那我们猛点,把K的范围设置的宽一些:
# 定义交叉验证的控制方法,启用网格搜索
trainControl <- trainControl(method = "cv", number = 10)
# 定义K值的网格搜索范围
tuneGrid <- expand.grid(k = 1:20)
# 在训练集上拟合KNN模型,指定网格搜索的K值
model <- train(X ~ ., data = trainData, method = "knn", trControl = trainControl,
tuneGrid = tuneGrid, preProcess = "scale")
# 查看模型结果,找出最优的K值
print(model)结果:
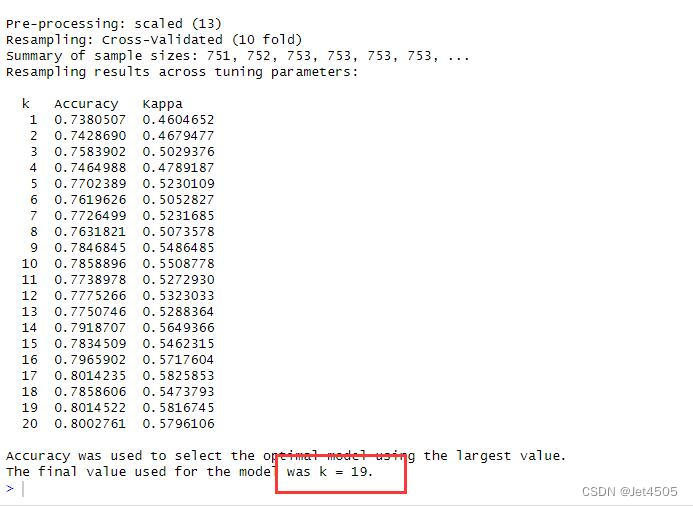
K=19,性能指标如下,似乎大同小异:
四、最后
数据嘛:
链接:https://pan.baidu.com/s/1rEf6JZyzA1ia5exoq5OF7g?pwd=x8xm
提取码:x8xm