复制
复制的问题和解决方案
数据损坏或丢失的错误


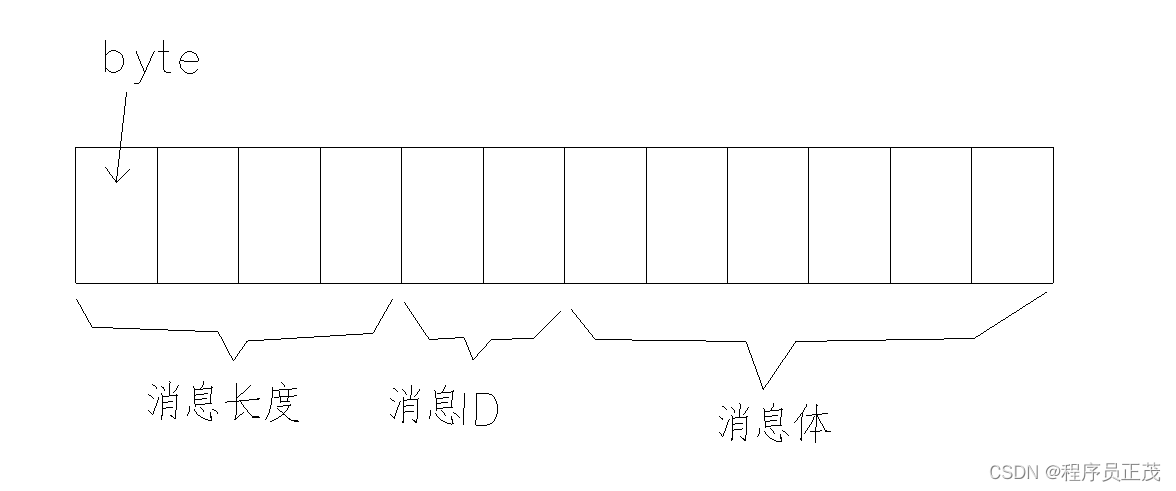
当一个二进制日志损坏时,能恢复多少数据取决于损坏的类型,有几种比较常见的类型:
- 1.数据改变,但事件仍是有效的SQL
不幸的是,MySQL甚至无法察觉这种损坏。因此最好还是经常检查备库的数据是否正确。在MySQL未来的版本中可能会被修复 - 2.数据改变并且事件是无效的SQL
这种情况可以通过mysqlbinlog提取出事件并看到一些错乱的数据,例如:
UPDATE tbl SET col ???????
可以通过增加偏移量的方式来尝试找到下一个事件,这样就可以只忽略这个损坏的事件。
- 3.数据一楼并且/或者事件的长度是错误的
这种情况下,mysqlbinlog可能会发生错误退出或者直接崩溃,因为它无法读取事件,并且找不到下一个事件的开始位置 - 4.某些事件已经损坏或被覆盖,或者偏移量已经改变并且下一个事件的起始偏移量也是错误的。
同样的,这种情况下mysqlbinlog也起不了多少作用
当损坏非常严重,通过mysqlbinlog已经无法获取日志事件时,就不得步进行一些十六进制的编辑或者通过一些繁琐的技术来找到日志事件的边界。这通常并不困难,因为有一些可辨识的标记会分割事件。如下例所示,首先使用mysqlbinlog找到样例日志的日志事件偏移量
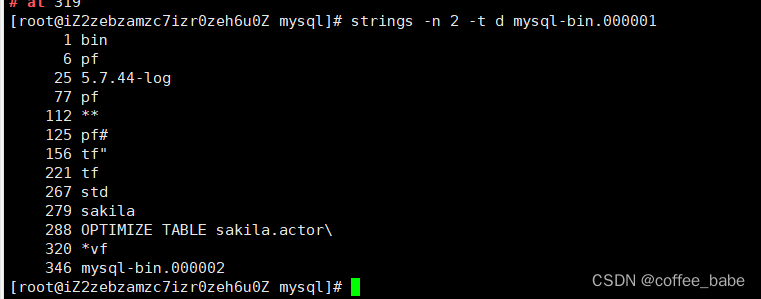
$ mysqlbinlog mysql-bin.000113 | grep '^# at'
一个找到日志偏移量的比较简单的方法是比较以下string命令输出的偏移量:
$ strings -n 2 -t d mysql-bin.000113
mysqlbinlog默认在/var/lib/mysql目录下
有一些可辩别的模式可以帮助定位事件的开头,注意以’G结尾的字符串在日志事件开头的一个字节后的位置。它们是固定长度的事件头的一部分。这些值因服务器而异,因此结果也可能取决于解析的日志所在的服务器。简单地分析后应该能够从二进制日志中找到这些模式并找到下一个完整的日志事件偏移量。然后通过mysqlbinlog的–start-position选项来跳过损坏的事件,或者使用CHANGE MASTER TO命令的MASTER_LOG_POS参数。
使用非事务型表
如果一切正常,基于语句的复制通常能够很好地处理非事务型表。但是当对非事务型表的更新发生错误时,例如查询在完成前被kill,就可能导致主库和备库的数据不一致。例如,假设更新一个MyISAM表的100行数据,若查询更新到了其中50条时有人kill该查询,会发生什么呢?一半的数据改变了,而另一半则没有,结果是复制必然不同步,因为该查询会在备库重放并更新完100行数据(MySQL随后会在主库上发现查询引起的错误,而备库上则没有报错,此后复制将会发生错误并中断)。
如果使用的是MyISAM表,在关闭MySQL之前需要确保已经运行了STOP SLAVE,否则服务器在关闭时会kill所有正在运行的查询(包括没有完成的更新)。事务型存储引擎则没有这个问题。如果使用的是事务型表,失败的更新会在主库上回滚并且不会记录到二进制日志中
混合事务型和非事务型表
如果使用的是事务型存储引擎,只有在事务提交后才会将查询记录到二进制日志中。因此如果事务回滚,MySQL就不会记录这条查询,也就不会在备库上重放。但是如果混合使用事务型和非事务型表,并且发生了一次回滚,MySQL能够回滚事务型表的更新,但非事务型表则被永久地更新了。只要不发生类似查询中途被kill这样的错误,这就不是问题:MySQL此时会记录该查询并记录一条ROLLBACK语句到日志中,结果是同样的语句也在备库中执行,所有的都很正常。这样效率会第一点,因为备库需要做一些工作并且最后再把它们丢弃掉。但理论上能够保证主备的数据一致。
目前看来一切很正常。但是如果备库发生死锁而主库没有也可能会导致问题。事务型表的更新会被回滚,而非事务型表则无法回滚,此时备库和主库的数据是不一致的。
防止该问题的唯一办法是避免混合使用事务型和非事务型表.如果遇到这个问题,唯一的解决办法是忽略错误,并重新同步相关的表。基于行的复制不会受到这个问题的影响。因为它记录的是数据的更改。而不是SQL语句。如果一条语句改变了一个MyISAM表和一个InnoDB表的某些行,然后主库发生了一次死锁,InnoDB表的更新会被回滚,而MyISAM表的更新仍会被记录到日志中并在备库重放。
不确定语句
当使用基于语句的复制模式时,如果通过不确定的方式更改数据可能会导致主备不一致。例如,一条带LIMIT的UPDATE语句更改的数据取决于查找行的顺序,除非能保证主库和备库上的顺序相同。例如,若行更具主键排序,一条查询可能在主库和备库上更新不同的行,这些问题非常微妙并且很难注意到。所以一些人进制对那些更新数据的语句使用LIMIT.另外一种不确定的行为是在一个拥有多个唯一索引的表上使用REPLACE或者INSERT IGNORE语句——MySQL在主库和备库上可能会选择不同的索引。
另外还要注意那些设计INFORMATION_SCHEMA表的语句。它们很容易在主库和备库上产生不一致,其结果也会不同。最后需要注意许多系统变量,例如@@server_id和@@hostname,在MySQL5.1之前无法正确地复制,基于行地复制则没有上述限制
主库和备库使用不同的存储引擎
在悲苦上使用不同的存储引擎,有时候可以带来好处。但是在一些场景下,当使用基于语句的复制方式时,如果备库使用了不同的存储引擎,则可能造成一条查询在主库和备库上的执行结果不同,例如不确定语句在主库使用不同的存储引擎更容易导致问题。如果发现主库和备库的某些表已经不同步,除了检查更新这些表的查询外,还需要检查两台服务器上使用的存储引擎是否相同。
备库发生数据改变
基于语句的复制方式前提时确保备库和主库相同的数据,因此不应该允许对备库数据的任何更改(比较好的办法是设置read only选项)。假设有如下语句:
mysql>INSERT INTO table1 SELECT * FROM table2;
如果备库上table2的数据和主库上不同,该语句会导致table1的数据也会不一致。换句话说,数据不一致可能会在表之间传播。不仅仅是INSERT…SELECT查询,所有类型的查询都可能发生。有两种可能的结果:备库上发生重复索引键冲突错误或者根本不提示任何错误。如果能报告错误还好,起码能够提示你主备数据已经不一致。无法察觉的不一致可能会悄无声息地导致各种严重的问题。唯一解决的办法就是重新从主库同步数据
不唯一的服务器ID
这种问题更加难以捉摸。如果不小心为两台备库设置了相同的服务器ID,看起来似乎没有什么问题,但如果查看错误日志,或者使用innotop查看主库,可能会看到一些古怪的信息。在主库上,会发现两台备库中只有一台连接到主库(通常情况下所有的备库都会建立连接以等待随时进行复制)。在备库的错误日志中,则会发现反复的重连和连接断开信息,但不会提及被错误配置的服务器ID。
MySQL可能会缓慢地进行正确的复制,也可能无法进行正确复制,这取决于MySQL的版本,给定的备库可能会丢失二进制日志事件,或者重复执行事件,导致重复键错误(或者不可见的数据损坏)。也可能因为备库的互相竞争造成主库的负载升高。如果备库竞争非常激烈,回导致错误日志在很短的时间内急剧增大。唯一的解决办法是小心设置备库的服务器ID。一个比较号的办法是创建一个主库到备库的服务器ID映射表,这样就可以跟踪到备库的ID信息(也许你想把它保存在服务器中,这 不完全是玩笑,可以给ID添加一个唯一索引)。如果备库全在一个自网络内,可以将每台机器IP的后八位作为唯一ID








![[数据集][目标检测]棉花叶子害虫检测数据集VOC+YOLO格式571张1类别](https://img-blog.csdnimg.cn/direct/02b44bb1e8cf4b6bb2cf8c5dd8f400c7.png)