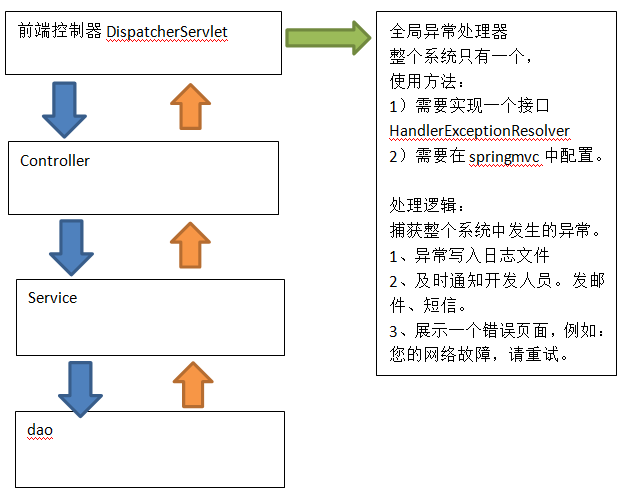
数据清洗概述
数据清洗是对一些没有用的、不合理的数据进行处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。
样本数据:
from io import StringIO
import pandas as pd
csv_data = """
PID,ST_NUM,ST_NAME,OWN_OCCUPIED,NUM_BEDROOMS,NUM_BATH,SQ_FT
100001000,104,PUTNAM,Y,3,1,1000
100002000,197,LEXINGTON,N,3,1.5,--
100003000, ,LEXINGTON,N,n/a,1,850
100004000,201,BERKELEY,12,1,NaN,700
,203,BERKELEY,Y,3,2,1600
100006000,207,BERKELEY,Y,NA,1,800
100007000,NA,WASHINGTON,'',2,HURLEY,950
100008000,213,TREMONT,Y,1,1,
100009000,215,TREMONT,Y,na,2,1800
100009000.0,215.0,TREMONT,Y,na,2,1800
100009000.0,215.0,TREMONT,Y,na,2,1800
,,,,,,
"""
# 使用StringIO来模拟文件对象
csv_file = StringIO(csv_data)
df = pd.read_csv(csv_file)
print(df)
# PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
# 0 100001000.0 104 PUTNAM Y 3 1 1000
# 1 100002000.0 197 LEXINGTON N 3 1.5 --
# 2 100003000.0 LEXINGTON N NaN 1 850
# 3 100004000.0 201 BERKELEY 12 1 NaN 700
# 4 NaN 203 BERKELEY Y 3 2 1600
# 5 100006000.0 207 BERKELEY Y NaN 1 800
# 6 100007000.0 NaN WASHINGTON '' 2 HURLEY 950
# 7 100008000.0 213 TREMONT Y 1 1 NaN
# 8 100009000.0 215 TREMONT Y na 2 1800
# 9 100009000.0 215.0 TREMONT Y na 2 1800
# 10 100009000.0 215.0 TREMONT Y na 2 1800
# 11 NaN NaN NaN NaN NaN NaN NaN空值数据,上表包含了几种空数据:
pandas 读取后当做:np.NaN:n/a、NA、两个风格符之间什么不写、
pandas 读取后当做字符串处理: --、na、空格、''
清洗空值数据
语法:DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
注意:简单粗暴,但实际可能清除掉了有效数据,常用清除空行,且修改源数据源。
df.dropna(how="all",inplace=True)
print(df)注意:后续处理可以针对整个df ,也可以是几列df["col1"]
空值处置-缺失值自定义处置[导入时]
Pandas 把 n/a、NA、两个分隔符之间什么不写的 当作np.Nan空数据,但是有很多情况如na、--、''、空格、等自定义的空数据不被处置成空数据,可以通过na_values 配置缺失值为np.NaN
csv_file = StringIO(csv_data)
df2 = pd.read_csv(csv_file, na_values=["n/a", "na", "--", "\'\'", " "])
df2.dropna(how="all", inplace=True)
print(df2)
# PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
# 0 100001000.0 104.0 PUTNAM Y 3.0 1 1000.0
# 1 100002000.0 197.0 LEXINGTON N 3.0 1.5 NaN
# 2 100003000.0 NaN LEXINGTON N NaN 1 850.0
# 3 100004000.0 201.0 BERKELEY 12 1.0 NaN 700.0
# 4 NaN 203.0 BERKELEY Y 3.0 2 1600.0
# 5 100006000.0 207.0 BERKELEY Y NaN 1 800.0
# 6 100007000.0 NaN WASHINGTON NaN 2.0 HURLEY 950.0
# 7 100008000.0 213.0 TREMONT Y 1.0 1 NaN
# 8 100009000.0 215.0 TREMONT Y NaN 2 1800.0
# 9 100009000.0 215.0 TREMONT Y NaN 2 1800.0
# 10 100009000.0 215.0 TREMONT Y NaN 2 1800.0空值处理-填充[内存df]
自定义值填充fillna
# 所有空值 0 填充,不仅仅是0 其他值也可以
df3=df2.fillna(0)
print(df3)空值后面的第一个有效值填充bfill
# 空值填充 使用 空值后面的第一个有效值填充 ,axis=0 同列下一行的值 ,axis=1 同行下一列的值 ,
df3 = df2.bfill(axis=0)
print(df3)空值前面的最后一个有效值填充ffill
# 空值填充 使用 空值前面的最后一个有效值填充 ,axis=0 同列上一行的值 ,axis=1 同行前一列的值 ,
df3 = df2.ffill(axis=0)
print(df3)数学值填充
某些特定含义的列,如果需要进行空值填充,不建议填充成0,会导致一些整列评估问题等。
针对此类列值替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
csv_file = StringIO(csv_data)
df = pd.read_csv(csv_file, na_values=["n/a", "na", "--", "\'\'", " "])
df.dropna(how="all", inplace=True)
print(df)
# x = df["ST_NUM"].mean()
# x = df["ST_NUM"].median()
x = df["ST_NUM"].mode().values[0]
df["ST_NUM"] = df["ST_NUM"].fillna(x)
print(df)自定义替换-replace
df = df.replace('', np.nan) # 所有空字符串 替换 np.nan ,
df = df[["Age", "Money"]].replace('', np.nan) # 指定列 清洗格式错误数据
可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02', '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data)
df['Date'] = pd.to_datetime(df['Date'], format='mixed')
print(df.to_string())
# Date duration
# 0 2020-12-01 50
# 1 2020-12-02 40
# 2 2020-12-26 45清洗错误数据
数据错误,可以对错误的数据进行替换或移除。
修改
person = {
"name": ['zs', 'ls', 'ww'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
# 修改数据
df.loc[2, 'age'] = 30
# 或者 条件判断修改
# for x in df.index:
# if df.loc[x, "age"] > 120:
# df.loc[x, "age"] = 120
print(df.to_string())删除
person = {
"name": ['zs', 'ls', 'ww'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace=True)
print(df.to_string())
# name age
# 0 zs 50
# 1 ls 40清洗重复数据
要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
过滤:duplicated() 会返回 True,否则返回 False 过滤去除重复的
from io import StringIO
import pandas as pd
csv_data = """
PID,ST_NUM,ST_NAME,OWN_OCCUPIED,NUM_BEDROOMS,NUM_BATH,SQ_FT
100001000,104,PUTNAM,Y,3,1,1000
100002000,197,LEXINGTON,N,3,1.5,--
100003000, ,LEXINGTON,N,n/a,1,850
100004000,201,BERKELEY,12,1,NaN,700
,203,BERKELEY,Y,3,2,1600
100006000,207,BERKELEY,Y,NA,1,800
100007000,NA,WASHINGTON,'',2,HURLEY,950
100008000,213,TREMONT,Y,1,1,
100009000,215,TREMONT,Y,na,2,1800
100009000.0,215.0,TREMONT,Y,na,2,1800
100009000.0,215.0,TREMONT,Y,na,2,1800
,,,,,,
"""
# 使用StringIO来模拟文件对象
csv_file = StringIO(csv_data)
df = pd.read_csv(csv_file, na_values=['--', '', "\'\'", "na"])
df.dropna(how='all', inplace=True)
print(df)
# PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
# 0 100001000.0 104 PUTNAM Y 3.0 1 1000.0
# 1 100002000.0 197 LEXINGTON N 3.0 1.5 NaN
# 2 100003000.0 LEXINGTON N NaN 1 850.0
# 3 100004000.0 201 BERKELEY 12 1.0 NaN 700.0
# 4 NaN 203 BERKELEY Y 3.0 2 1600.0
# 5 100006000.0 207 BERKELEY Y NaN 1 800.0
# 6 100007000.0 NaN WASHINGTON NaN 2.0 HURLEY 950.0
# 7 100008000.0 213 TREMONT Y 1.0 1 NaN
# 8 100009000.0 215 TREMONT Y NaN 2 1800.0
# 9 100009000.0 215.0 TREMONT Y NaN 2 1800.0
# 10 100009000.0 215.0 TREMONT Y NaN 2 1800.0
print(df[~df.duplicated()])
# PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
# 0 100001000.0 104 PUTNAM Y 3.0 1 1000.0
# 1 100002000.0 197 LEXINGTON N 3.0 1.5 NaN
# 2 100003000.0 LEXINGTON N NaN 1 850.0
# 3 100004000.0 201 BERKELEY 12 1.0 NaN 700.0
# 4 NaN 203 BERKELEY Y 3.0 2 1600.0
# 5 100006000.0 207 BERKELEY Y NaN 1 800.0
# 6 100007000.0 NaN WASHINGTON NaN 2.0 HURLEY 950.0
# 7 100008000.0 213 TREMONT Y 1.0 1 NaN
# 8 100009000.0 215 TREMONT Y NaN 2 1800.0
# 9 100009000.0 215.0 TREMONT Y NaN 2 1800.0删除
df.drop_duplicates(inplace = True)Pandas相关性分析
相关性计算df.corr
通过计算不同变量之间的相关系数来了解它们之间的关系
语法:df.corr(method='pearson', min_periods=1)
核心参数:
-
method (可选): 字符串类型,用于指定计算相关系数的方法。默认是 'pearson',还可以选择 'kendall'(Kendall Tau 相关系数)或 'spearman'(Spearman 秩相关系数)。
- Pearson 相关系数: 即皮尔逊相关系数,用于衡量了两个变量之间的线性关系强度和方向。它的取值范围在 -1 到 1 之间,其中 -1 表示完全负相关,1 表示完全正相关,0 表示无线性相关。可以使用 corr() 方法计算数据框中各列之间的 Pearson 相关系数。
- Spearman 相关系数:即斯皮尔曼相关系数,是一种秩相关系数。用于衡量两个变量之间的单调关系,即不一定是线性关系。它通过比较变量的秩次来计算相关性。可以使用 corr(method='spearman') 方法计算数据框中各列之间的 Spearman 相关系数。
-
min_periods (可选): 表示计算相关系数时所需的最小观测值数量。默认值是 1,即只要有至少一个非空值,就会进行计算。如果指定了
min_periods,并且在某些列中的非空值数量小于该值,则相应列的相关系数将被设为 NaN。
返回值:是一个相关系数矩阵,矩阵的行和列对应数据框的列名,矩阵的元素是对应列之间的相关系数。
示例:
import sys
import warnings
from io import StringIO
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
warnings.filterwarnings('ignore')
csv_data = """
PID,ST_NUM,ST_NAME,OWN_OCCUPIED,NUM_BEDROOMS,NUM_BATH,SQ_FT
100001000,104,PUTNAM,Y,3,1,1000
100002000,197,LEXINGTON,N,3,1.5,--
100003000, ,LEXINGTON,N,n/a,1,850
100004000,201,BERKELEY,12,1,NaN,700
,203,BERKELEY,Y,3,2,1600
100006000,207,BERKELEY,Y,NA,1,800
100007000,NA,WASHINGTON,'',2,HURLEY,950
100008000,213,TREMONT,Y,1,1,
100009000,215,TREMONT,Y,na,2,1800
100009000.0,215.0,TREMONT,Y,na,2,1800
100009000.0,215.0,TREMONT,Y,na,2,1800
,,,,,,
"""
# 使用StringIO来模拟文件对象
csv_file = StringIO(csv_data)
df = pd.read_csv(csv_file, na_values=['--', '', "\'\'", "na", ' '])
df.dropna(how='all', inplace=True)
# print(df,df.dtypes)
# 去除ID 空值 数据
df_result = df[df["PID"].notna()]
# 使用drop_duplicates()去除重复的ID
# df_result = df_result.drop_duplicates(subset='PID', keep='first')
print(df_result,df_result.dtypes)
# PID float64
# ST_NUM float64
# ST_NAME object
# OWN_OCCUPIED object
# NUM_BEDROOMS float64
# NUM_BATH object
# SQ_FT float64
# dtype: object
# 类型转换
df_result["PID"] = df_result["PID"].astype(str)
df_result["ST_NUM"] = df_result["ST_NUM"].astype(np.float16)
# 注意:np的int 没有NaN类型 ,.astype(np.int16) 报错
df_result["NUM_BEDROOMS"] = df_result["NUM_BEDROOMS"].astype(np.float16)
df_result["SQ_FT"] = df_result["SQ_FT"].astype(np.float16)
print(df_result,df_result.dtypes)
# PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
# 0 100001000.0 104.0 PUTNAM Y 3.0 1 1000.0
# 1 100002000.0 197.0 LEXINGTON N 3.0 1.5 NaN
# 2 100003000.0 NaN LEXINGTON N NaN 1 850.0
# 3 100004000.0 201.0 BERKELEY 12 1.0 NaN 700.0
# 5 100006000.0 207.0 BERKELEY Y NaN 1 800.0
# 6 100007000.0 NaN WASHINGTON NaN 2.0 HURLEY 950.0
# 7 100008000.0 213.0 TREMONT Y 1.0 1 NaN
# 8 100009000.0 215.0 TREMONT Y NaN 2 1800.0
# 9 100009000.0 215.0 TREMONT Y NaN 2 1800.0
# 10 100009000.0 215.0 TREMONT Y NaN 2 1800.0
# PID object
# ST_NUM float16
# ST_NAME object
# OWN_OCCUPIED object
# NUM_BEDROOMS float16
# NUM_BATH object
# SQ_FT float16
# dtype: object
def getAvg(row):
return (row["ST_NUM"] + row["NUM_BEDROOMS"]+ row["SQ_FT"])/3
# 计算 每人 数值列 平均值
df_result["agg"]=df_result.apply(lambda row:getAvg(row),axis=1)
# 计算 Pearson 相关系数
correlation_matrix = df_result[["ST_NUM","NUM_BEDROOMS","SQ_FT","agg"]].copy().corr()
print("*"*10)
print(correlation_matrix)
# ST_NUM NUM_BEDROOMS SQ_FT agg
# ST_NUM 1.000000 -0.648580 0.405672 -1.0
# NUM_BEDROOMS -0.648580 1.000000 0.933257 1.0
# SQ_FT 0.405672 0.933257 1.000000 1.0
# agg -1.000000 1.000000 1.000000 1.0
# 使用热图可视化 Pearson 相关系数
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.show()结果分析
ST_NUM NUM_BEDROOMS SQ_FT agg
ST_NUM 1.000000 -0.648580 0.405672 -1.0
NUM_BEDROOMS -0.648580 1.000000 0.933257 1.0
SQ_FT 0.405672 0.933257 1.000000 1.0
agg -1.000000 1.000000 1.000000 1.0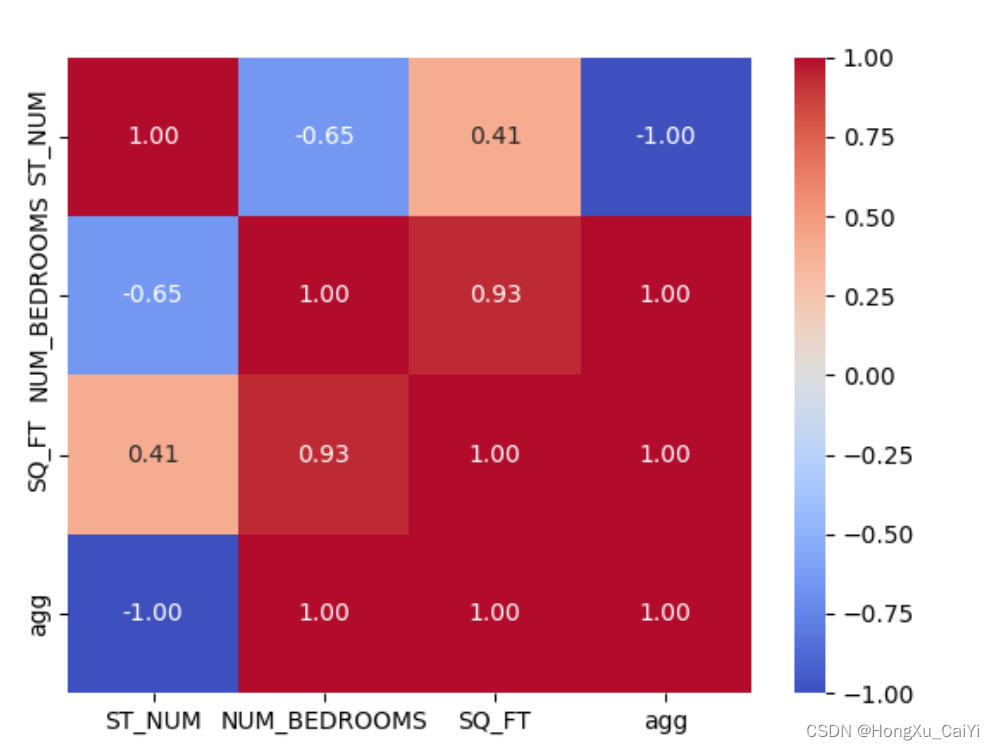
理解:如ST_NUM 与agg 列 -1 完全负相关
计算Spearman系数
# 计算 Spearman 相关系数
spearman_correlation_matrix = df_result[["ST_NUM","NUM_BEDROOMS","SQ_FT","agg"]].corr(method='spearman')
print(spearman_correlation_matrix)
# ST_NUM NUM_BEDROOMS SQ_FT agg
# ST_NUM 1.000000 -0.894427 0.806452 -1.0
# NUM_BEDROOMS -0.894427 1.000000 1.000000 1.0
# SQ_FT 0.806452 1.000000 1.000000 1.0
# agg -1.000000 1.000000 1.000000 1.0
sns.heatmap(spearman_correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.show()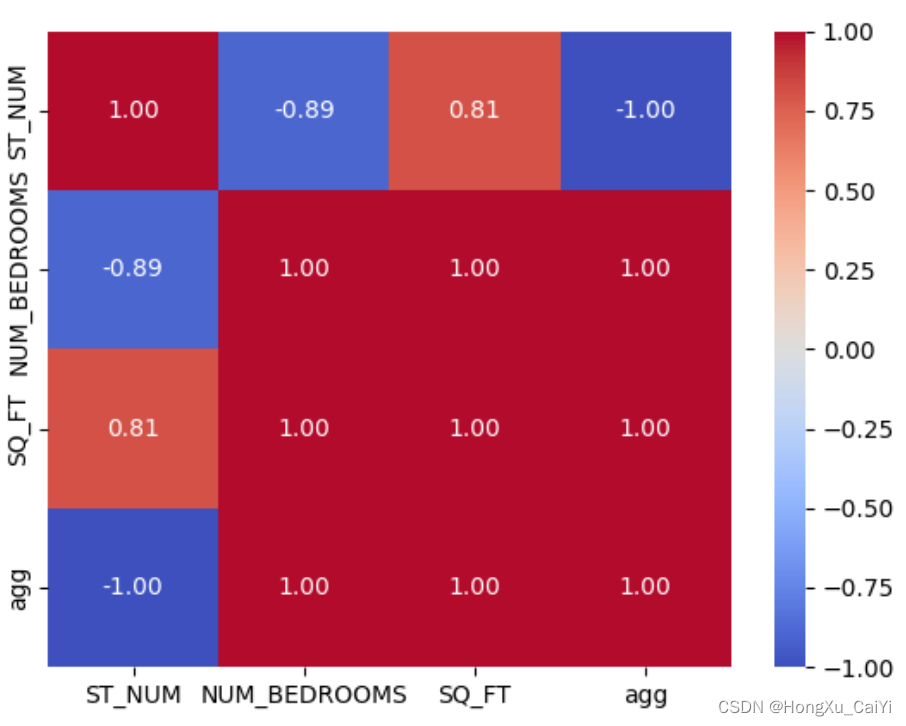
理解:如ST_NUM 与agg 列 -1 单调负相关。
相关性可视化
Seaborn 是一个基于 Matplotlib 的数据可视化库,专注于统计图形的绘制,旨在简化数据可视化的过程。在Matplotlib基础上进行了更高级的封装,使得数据可视化更加简单和美观。
Seaborn 提供了一些简单的高级接口,可以轻松地绘制各种统计图形,包括散点图、折线图、柱状图、热图等,而且具有良好的美学效果。
热力图使用
# 计算 Pearson 相关系数
correlation_matrix = df.corr()
# 使用热图可视化 Pearson 相关系数
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.show()
将生成一个热图如上,用颜色表示相关系数的强度,其中正相关用温暖色调表示,负相关用冷色调表示。annot=True 参数在热图上显示具体的数值。
更多统计图形类型:
散点图(Scatter plot):使用seaborn.scatterplot(x=[],y=[])函数可以绘制散点图,用于展示两个连续变量之间的关系。
折线图(Line plot):使用seaborn.lineplot(x=[],y=[])函数可以绘制折线图,用于展示连续变量随着另一个变量的变化而变化的趋势。
柱状图(Bar plot):使用seaborn.barplot(x=[],y=[])函数可以绘制柱状图,用于展示分类变量之间的比较。
箱线图(Box plot):使用seaborn.boxplot()函数可以绘制箱线图,用于展示一组数据的分布情况,包括中位数、四分位数和异常值等。
热力图(Heatmap):使用seaborn.heatmap()函数可以绘制热力图,用于展示两个分类变量之间的相关性。
直方图(Histogram):使用sns.histplot()函数来绘制直方图。直方图将数值范围分成多个间隔(bin),并计算每个间隔内的观测值数量。直方图的x轴表示数值范围,y轴表示观测值数量。
密度图(Density Plot):使用sns.kdeplot()函数来绘制核密度估计图。密度图通过平滑的曲线来估计数值变量的概率密度函数。密度图的x轴表示数值范围,y轴表示概率密度。
树状图: sns.clustermap():绘制树状图,用于展示数据集中观察之间的相似性,并按照相似性分组
除了以上几种常见的统计图形类型,Seaborn还提供了其他一些更高级的图形类型,如密度图(Density plot)、面积图(Area plot)和小提琴图(Violin plot)等。这些图形类型可以根据数据集的特点进行选择和定制,使得数据可视化更加直观和有趣。