elasticsearch基本操作
- 基础
- 两种模式:
- ik分词器词库拓展
- 索引库操作
- mapping映射属性
- type
- index
- analyzer
- properties
- 索引库的CRUD
- 创建
- 修改
- 查询
- 删除
- 文档操作
- 创建
- 查询
- 修改
- 删除
基础
本教程使用es8.6.0与kibana作为测试环境
打开开发工具
## 1.查看节点信息
GET /_cat/nodes?v
## 2.查看节点健康状态
GET _cluster/health
## 3.创建索引库
PUT /moon_db
## 4.查寻索引库
GET /moon_db
## 5.删除索引库
DELETE /moon_db
## 6.判断索引库是否存在
HEAD /moon_db
1.创建索引库时设置分词器、分片数和副本数
PUT /moon_db
{
"settings":{
"number_of_shards": 2,
"number_of_replicas": 2,
"index":{
"analysis.analyzer.default.type":"ik_max_word"
}
}
}
## 2.创建文档
## 如果id不存在,创建新的文档,否则先删除现有文档,再创建新的文档,版本会增加
## 如果是_create命令,id存在则会报错
## 如果用POST命令,带着ID则使用指定ID,否在由ES生成一个ID
PUT /moon_db/_doc/1
{
"name":"张三",
"sex":1,
"age":18,
"poem":"连雨不知春去,一晴方觉夏深"
}
POST /moon_db/_doc/
{
"name":"孙八",
"sex":1,
"age":30,
"poem":"清江一曲抱村流,长夏江村事事幽"
}
## 3.查寻数据
GET /moon_db/_doc/1
## 4.更新:PUT|POST ID一致相当于全量更新
## 部分更新:_update
POST /moon_db/_update/1
{
"doc": {
"name":"张三峰"
}
}
## 5.条件更新: _update_by_query
## 如果原文档,无ages属性,则会创建ages,并赋值
POST /moon_db/_update_by_query
{
"query": {
"match": {
"_id": "1"
}
},
"script": {
"source": "ctx._source.ages = 30"
}
}
## 6.并发时读后写版本控制:
## _seq_no:数据序列号,同_version,数据变更时严格递增
## _primary_term:分区版本,主分区重新分配(重启、Primary选举等),版本递增
PUT /moon_db/_doc/1?if_seq_no=11&if_primary_term=1
{
"name":"张三峰",
"age":18,
"poem":"连雨不知春去,一晴方觉夏深"
}
## 7.条件查询
GET /moon_db/_search?from=0&size=10
{
"query": {
"term": {
"age": 30
}
}
}
两种模式:
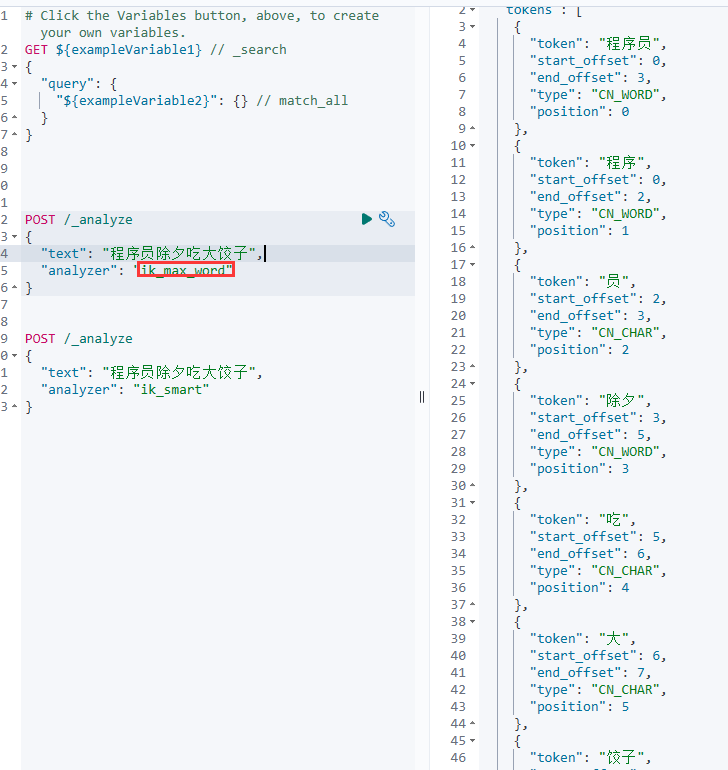
ik_smart
按照内存/计算力消耗最少来分析
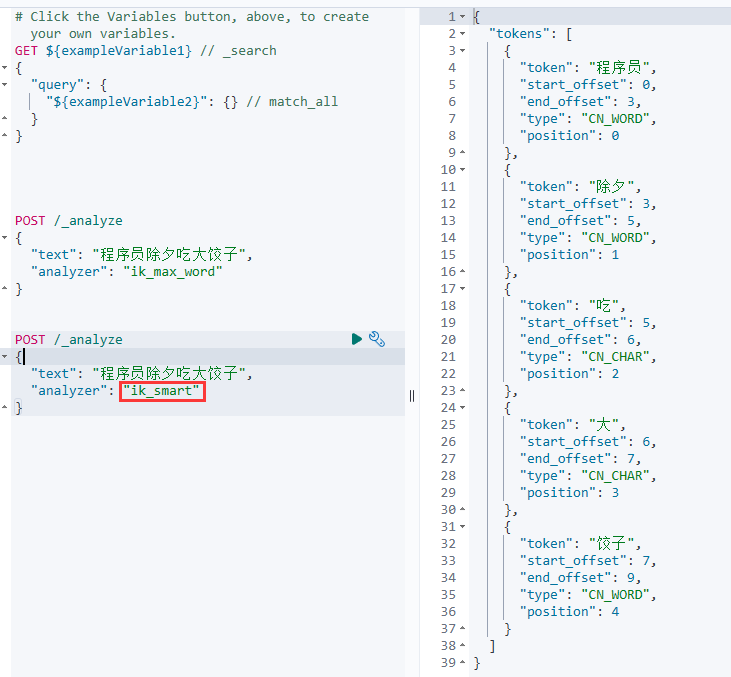
ik_max_word
按照搜索效果最大来划分
ik分词器词库拓展
字典:这里指的是ik分词器的合法词语组成的集合
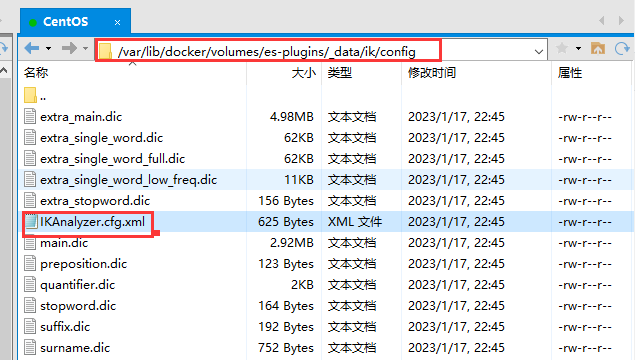
修改ik分词器的config目录的IKAnalyzer.cfg.xml文件
设置ext.dic是扩展词库,
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典-->
<!-- <entry key="remote_ext_dict" >words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
然后新建一个文件为ext.dic,在里面添加词,作为扩展词库
然后目录里有stopword.dic,在里面添加词,作为停用词库:(放不会分词的单词,比如脏话,语气词等词语)
添加个人词典:

添加停用词:
这里还有其他词库:量词后缀啥的,用的时候再看
记得保存了重启生效
docker restart es
docker restart kibana
测试:

可见停用词"希特勒",“的"都不见了,但是出现了完整的"奥力给”.
"yyds"没有分出来,可能在原本的英语分词中还是以空格分词为主,所以不会进行切分
索引库操作
mapping映射属性
mapping是对索引库中文档的约束
常见的属性:
type
字段数据类型,常见的类型:
字符串: text(可分词的文本),keyword(精确值,比如:品牌、国家、邮箱)
数值: long,integer,short,byte,double,float
布尔: boolean
日期: date
对象: object
es中没有数组类型,但是会理解成多个值分别解析,
index
是否创建索引,默认为true(是否参与搜索)
analyzer
使用哪种分词器,一般我们用ik_smart,和text结合使用
properties
该字段(属性)的子字段(属性)
索引库的CRUD
创建
PUT /syk1
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName": {
"type":"keyword"
},
"lastName":{
"type": "keyword"
}
}
}
}
}
}

修改
事实上不允许进行修改,但是可以添加新字段
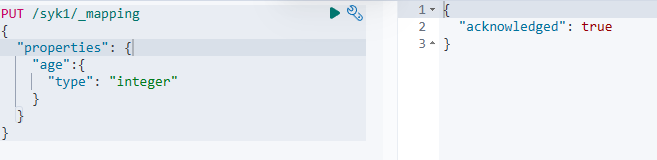
PUT /syk1/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}
添加成功:
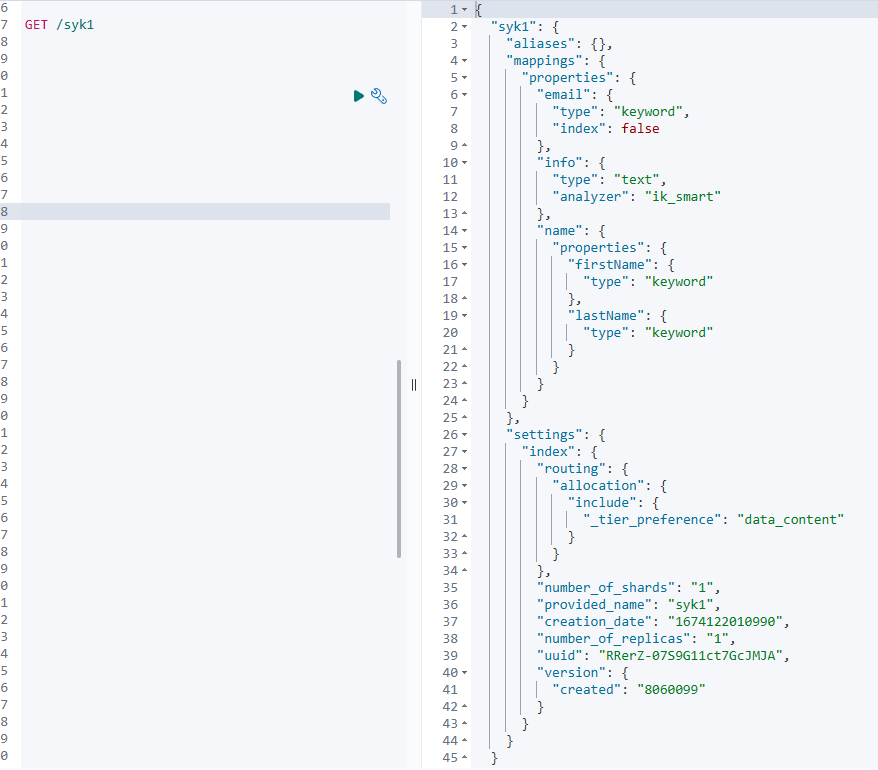
查询
GET /syk1
删除
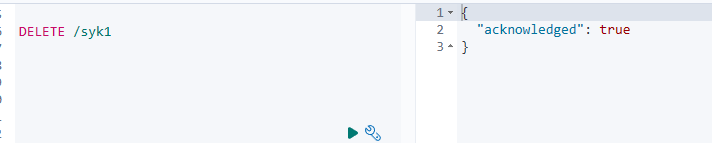
DELETE /syk1
删除成功
文档操作
都是在索引库名后面加上_doc/文档id
文档:
创建
POST /索引库名/_doc/文档id
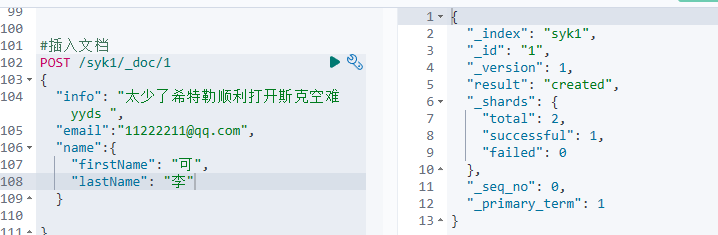
#插入文档
POST /syk1/_doc/1
{
"info": "太少了希特勒顺利打开斯克空难 yyds ",
"email":"11222211@qq.com",
"name":{
"firstName": "可",
"lastName": "李"
}
}
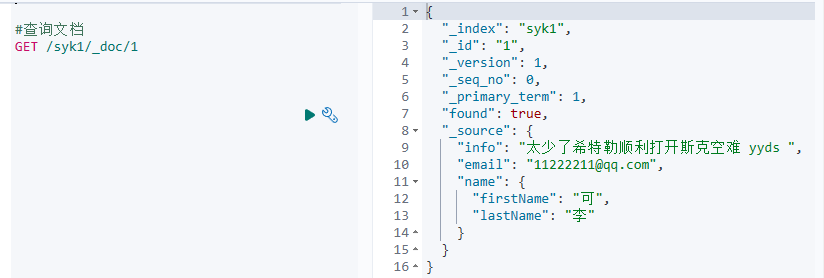
查询
GET /syk1/_doc/1
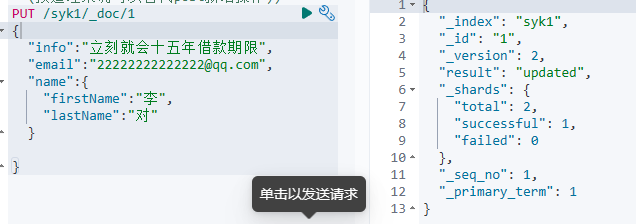
修改
全量修改
#修改文档
#全量修改(删除再添加(按道理来说可以替代post新增操作))
PUT /syk1/_doc/1
{
"info":"立刻就会十五年借款期限",
"email":"22222222222222@qq.com",
"name":{
"firstName":"李",
"lastName":"对"
}
}
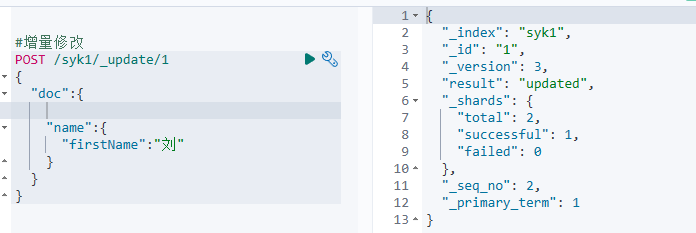
增量修改
#增量修改
POST /syk1/_update/1
{
"doc":{
"name":{
"firstName":"刘"
}
}
}
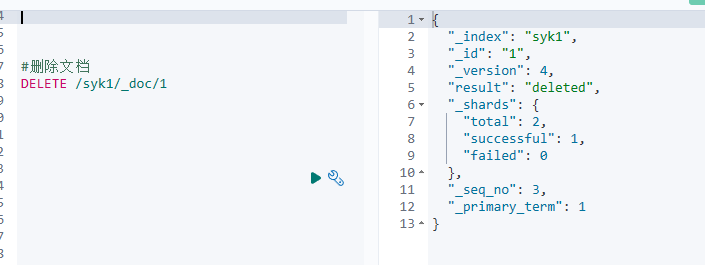
删除
使用的乐观锁思想,删除不是真删除,所以删除之后再添加会有版本迭代现象
#删除文档
DELETE /syk1/_doc/1