目录
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- 摘要
- Approach—方法
- Channel Shuffle for Group Convolutions—用于分组卷积的通道重排
- ShuffleNet Unit—ShuffleNet单元
- Network Architecture—网络体系结构
- 总结
- ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
- 摘要
- Introduction—简介
- 四条准则
- Practical Guidelines for Efficient Network Design—高效网络设计的实用准则
- G1) Equal channel width minimizes memory access cost (MAC) -- 相同通道宽度能够最小化MAC(内存访问成本)
- G2) Excessive group convolution increases MAC—过度的组卷积会增加 MAC
- G3) Network fragmentation reduces degree of parallelism—网络碎片化会降低并行程度
- G4) Element-wise operations are non-negligible—Element-wise操作的影响不可忽略
- ShuffleNet V2: an Efficient Architecture—一个高效的架构
- 基本单元
- ShuffleNet V2 的整体架构
- Analysis of Network Accuracy—网络精度分析
- 总结
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
论文链接:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
摘要
(1)CNN架构ShuffleNet是专门为计算能力有限的移动设备而设计
(2)ShuffleNet利用两种新的运算方法:
- 分组逐点(1 × 1)卷积(pointwise group convolution)
- 通道重排(channel shuffle)
作用:
(1)使用分组逐点卷积来降低1×1卷积的计算复杂度
(2)使用通道重排操作来帮助信息在特征通道间流动
Approach—方法
Channel Shuffle for Group Convolutions—用于分组卷积的通道重排
下图是分组卷积的图示,可以看到分组卷积参数量大大减少,计算量同样也会减少。
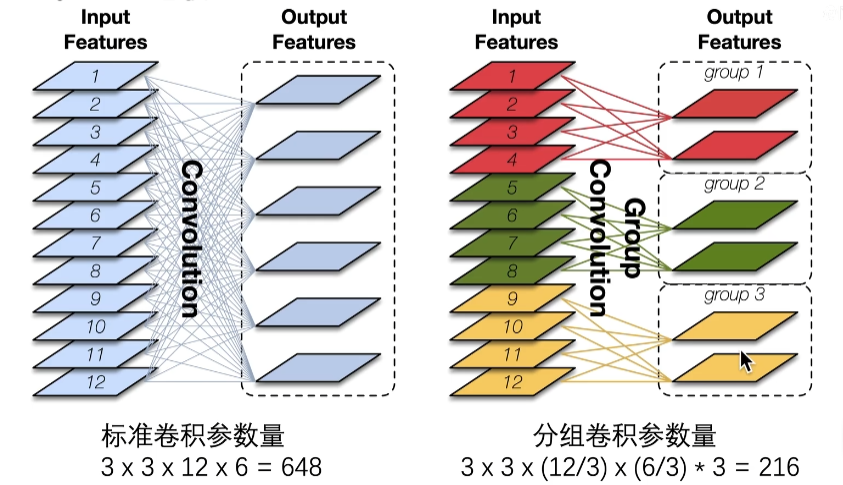
本文中的pointwise group convolution其实就是用1 × 1的卷积核进行分组卷积,进一步降低计算复杂度。
优点:通过确保每个卷积仅在相应的输入通道组上运行,组卷积降低了计算成本。
但是分组卷积的副作用:阻塞通道之间的信息并削弱表征能力。
如下图所示,沿着channel分成红、绿、蓝三组,各组之间的信息是不流通的,只能融合组内的信息。
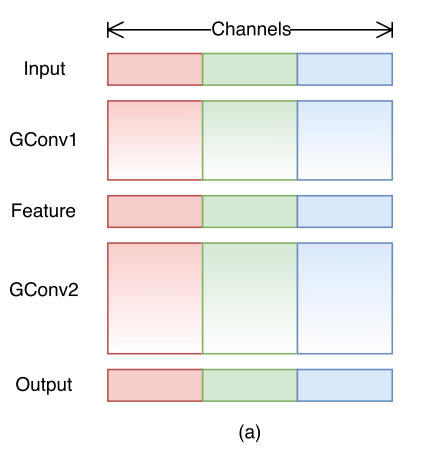
解决方法
本文采用channel shuffle操作,通过将每个分组后的通道再分成几组子通道,并将不同分组中的不同子通道进行混合(洗牌操作),那么就可以保证不同分组间的特征通道的特征信息可以共享。
channel shuffle的作用: 跨通道信息交融。
下图中,(b) 第二个分组卷积是从第一个分组卷积里不同的组里拿数据(b是一种思想);(c) 利用通道重排产生与(b) 等效的实现(c是一种实现)
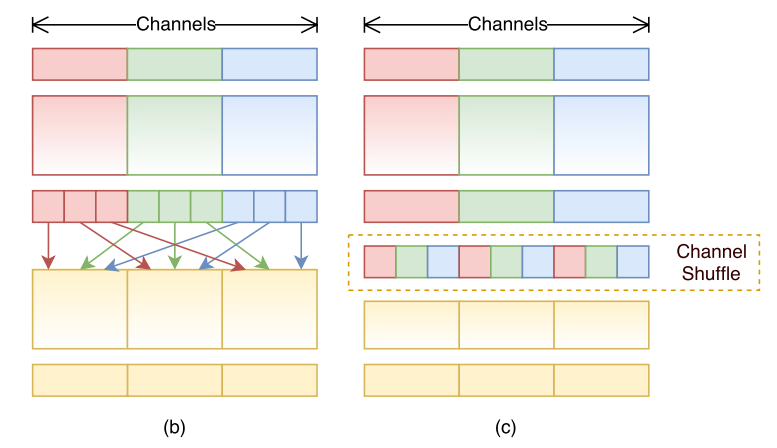
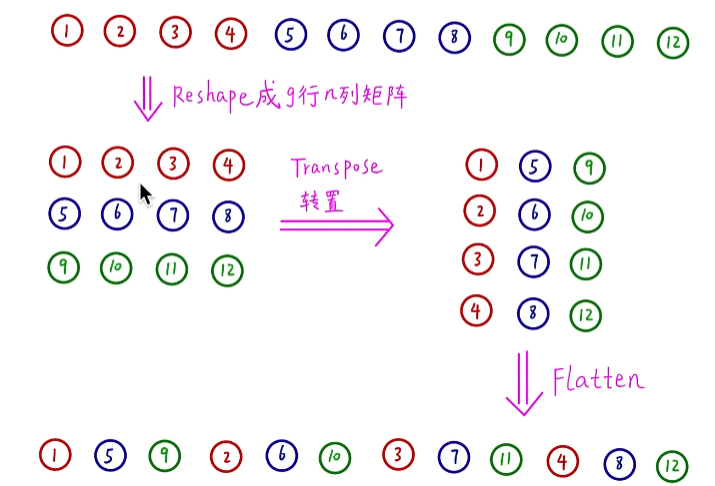
channel shuffle通道重排过程
(c)的实现: 假设卷积层有g组,输出有g × n个通道,先将输出通道维数reshape为(g,n)的矩阵,再进行转置(transpose),展平(flatten),作为下一层的输入(即使两个卷积的组数不同,操作依然有效)
该过程可以直接调用pytorch的API实现,是可微分、可导的,计算效率很高,几乎没有额外的算力消耗,可以进行端到端的训练。
ShuffleNet Unit—ShuffleNet单元
ShuffleNet Unit是基于Resdual block改进得到的
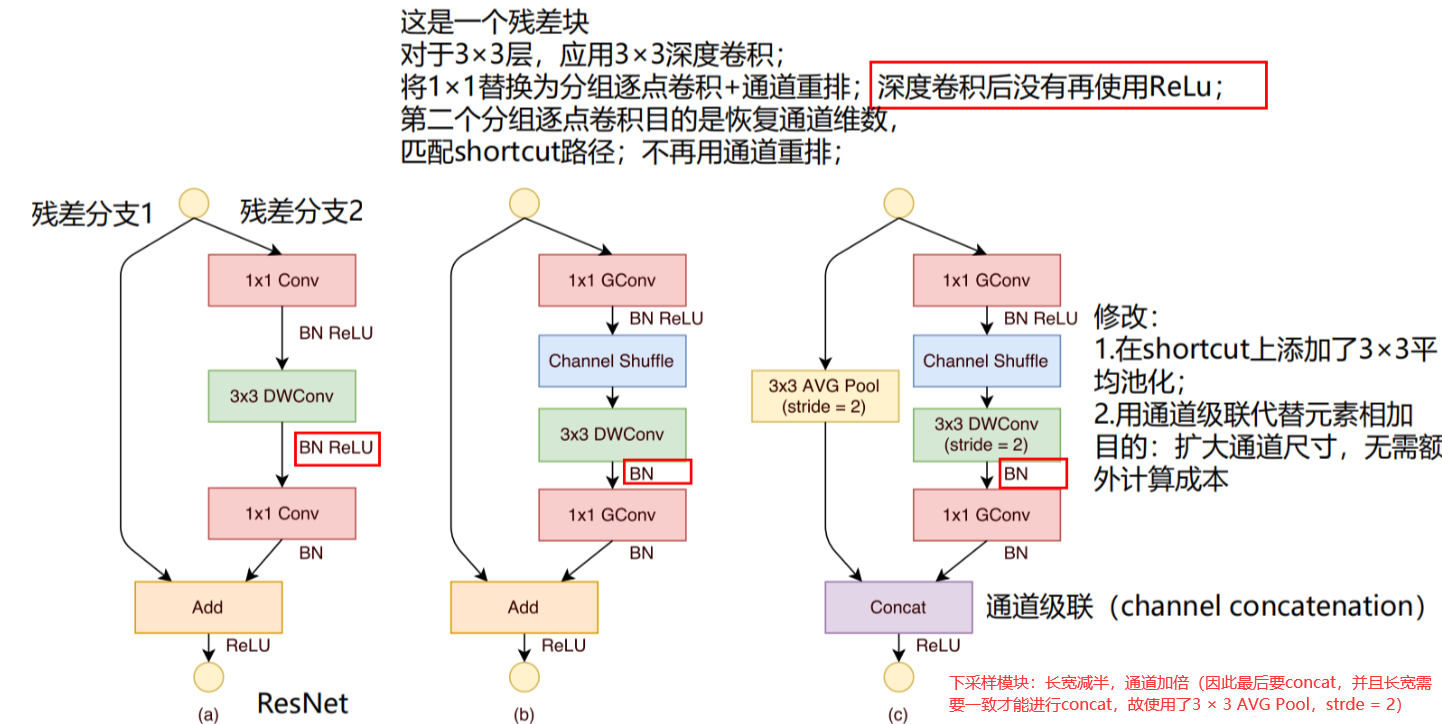
(a)为一个Resdual block
①1×1卷积(降维)+3×3深度卷积+1×1卷积(升维)
②之间有BN和ReLU
③最后通过add相加
(b)为输入输出特征图大小不变的ShuffleNet Unit
①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 + Channel Shuffle
②去掉原3×3深度卷积后的ReLU
③ 将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
(c)为输出特征图大小为输入特征图大小一半的ShuffleNet Unit(下次阿阳模块)
①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 + Channel Shuffle
②令原3×3深度卷积的步长stride=2, 并且去掉深度卷积后的ReLU
③将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
④shortcut上添加一个3×3平均池化层(stride=2)用于匹配特征图大小
⑤对于块的输出,将原来的add方式改为concat方式(通道加倍)
Q1:为什么在模块输出部分的逐点分组卷积后并没有使用channel shuffle?
因为此时得到的结果已经相当不错了,所以不需要进行通道重排了
Q2:为什么去掉第二个ReLU?
这个我们在MobileNetV2(点这里)里介绍过,作者发现训练过程中depthwise部分得到卷积核会废掉,认为造成这样的原因是由于ReLU函数造成的。
Q3:为什么用concat代替add?
扩大通道尺寸,无需额外计算成本
Network Architecture—网络体系结构
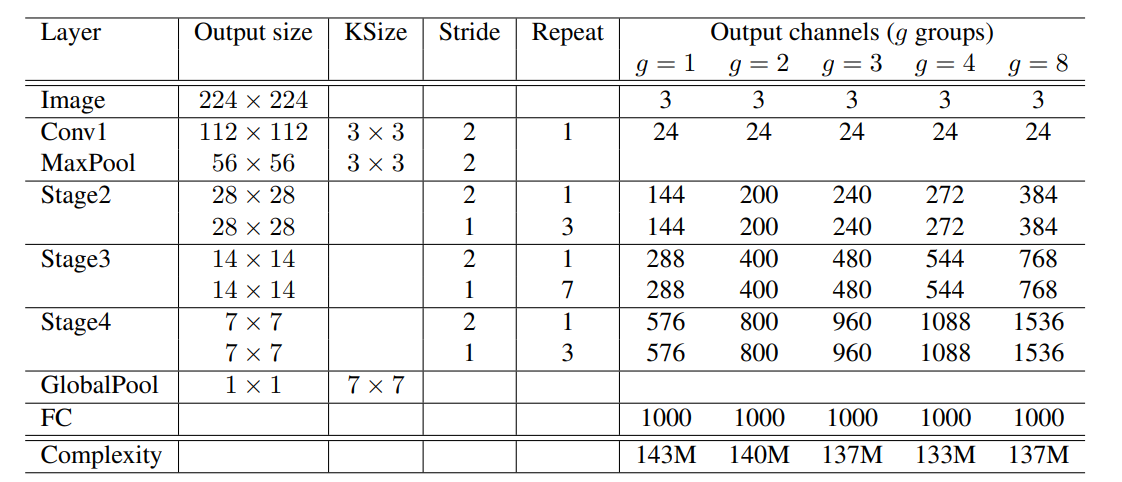
不同分组数的shuffleNet网络结构如下图:
(1)首先使用的普通的3 x 3的卷积和max pool层
(2)接着分为三个阶段:
每个stage都是重复堆叠了几个ShuffleNet unit
对于每个stage,第一个unit采用的是stride = 2,这样特征图width和height各降低一半,而通道数增加一倍
后面的都是stride=1,特征图和通道数都保持不变
(3)对于基本单元来说,其中瓶颈层,就是3 x 3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的
同时从下图可以看出,并非分组数越多,运算量越小(g = 4 ) < ( g = 8 )
总结
通过group pointwise convolution分组1 x 1卷积和channel shuffle通道重排操作,降低参数量和计算量,扩增卷积核个数。
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
论文链接:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
摘要
神经网络架构的设计目前主要由计算复杂度的间接指标(即 FLOPs)来指导。
但是,直接指标(如速度)还依赖于其他因素。
本文主要工作
(1)提出了新的网络结构ShuffleNet V2
(2)指出过去在网络架构设计上仅注重间接指标 FLOPs 的不足,并提出两个基本原则和四个实用准则来指导网络架构设计
Introduction—简介
FLOPs作为衡量指标的不足,FLOPs是一个间接的指标。
直接指标是指速度或延迟。
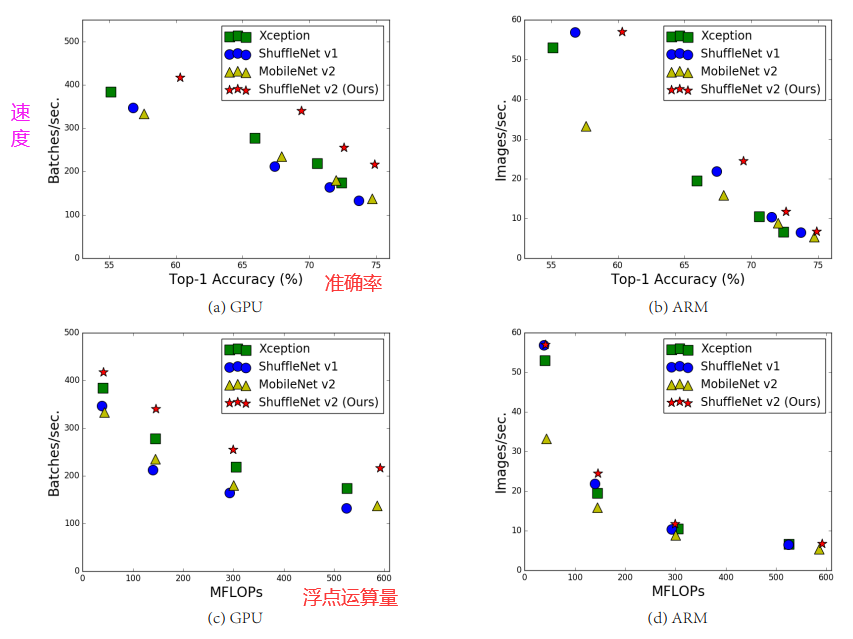
四个网络架构在两个硬件平台、四种不同计算复杂度上的(验证集 ImageNet 分类)精度、速度和 FLOPs 结果。
从©和(d)可以看出,具有相似FLOPs的网络却具有不同的速度,在GPU上相同的FLOPs速度差异很大,在CPU上却很小。因此,使用FLOPs作为计算复杂度的唯一指标是不够的,可能会导致次优化设计。
FLOPS和FLOPs:
FLOPS: 全大写,指每秒浮点运算次数,可以理解为计算的速度,是衡量硬件性能的一个指标 (硬件)
FLOPs: s小写,指浮点运算数,理解为计算量,可以用来衡量算法/模型的复杂度,(模型)在论文中常用GFLOPs(1 GFLOPs = 10^9FLOPs)
下图反映了不同的轻量化模型在不同的硬件设备上的计算开销分布
element wise(逐元素操作):relu()函数激活,残差网络的连接(add)等
Data:数据的输入输出
如果只优化FLOPs(对应加法乘法运算),相当于只优化卷积运算,从图中可以看出还有很多其他的操作的开销也很大,特别是在GPU上。
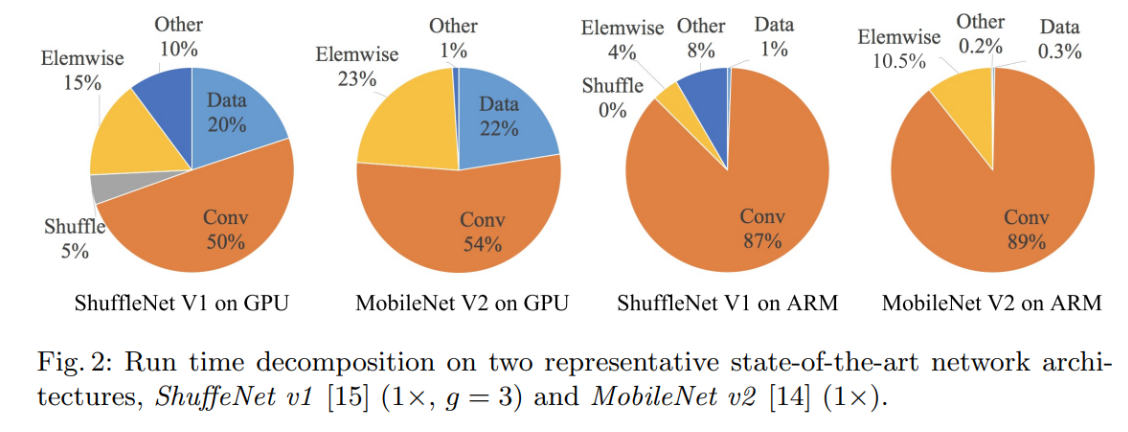
从上图可以得出以下的结论:
1.乘-加浮点运算次数FLOPs仅反映卷积层,仅为间接指标
2.不同硬件上的测试结果不同
3.数据读写的内存MAC占用影响很大
4.Element-wise逐元素操作带来的开销不可忽略
间接指标和直接指标差异的原因
(1)对速度有较大影响的几个重要因素对 FLOPs 不产生太大作用。
(2)由于平台的不同是,使用相同的FLOPs操作可能有不同的运行时间。
ShuffleNetv2提出的两个原则
第一,应该用直接指标(例如速度)替换间接指标(例如 FLOPs)。
第二,这些指标应该在目标平台上进行评估。
四条准则
准则一︰输入输出通道数相同时,内存访问量MAC最小
准则二︰分组数过大的分组卷积会增加MAC
准则三︰碎片化操作对并行加速不友好
准则四:逐元素噪作(Element-wise)带来的内存和耗时不可忽略
Practical Guidelines for Efficient Network Design—高效网络设计的实用准则
G1) Equal channel width minimizes memory access cost (MAC) – 相同通道宽度能够最小化MAC(内存访问成本)
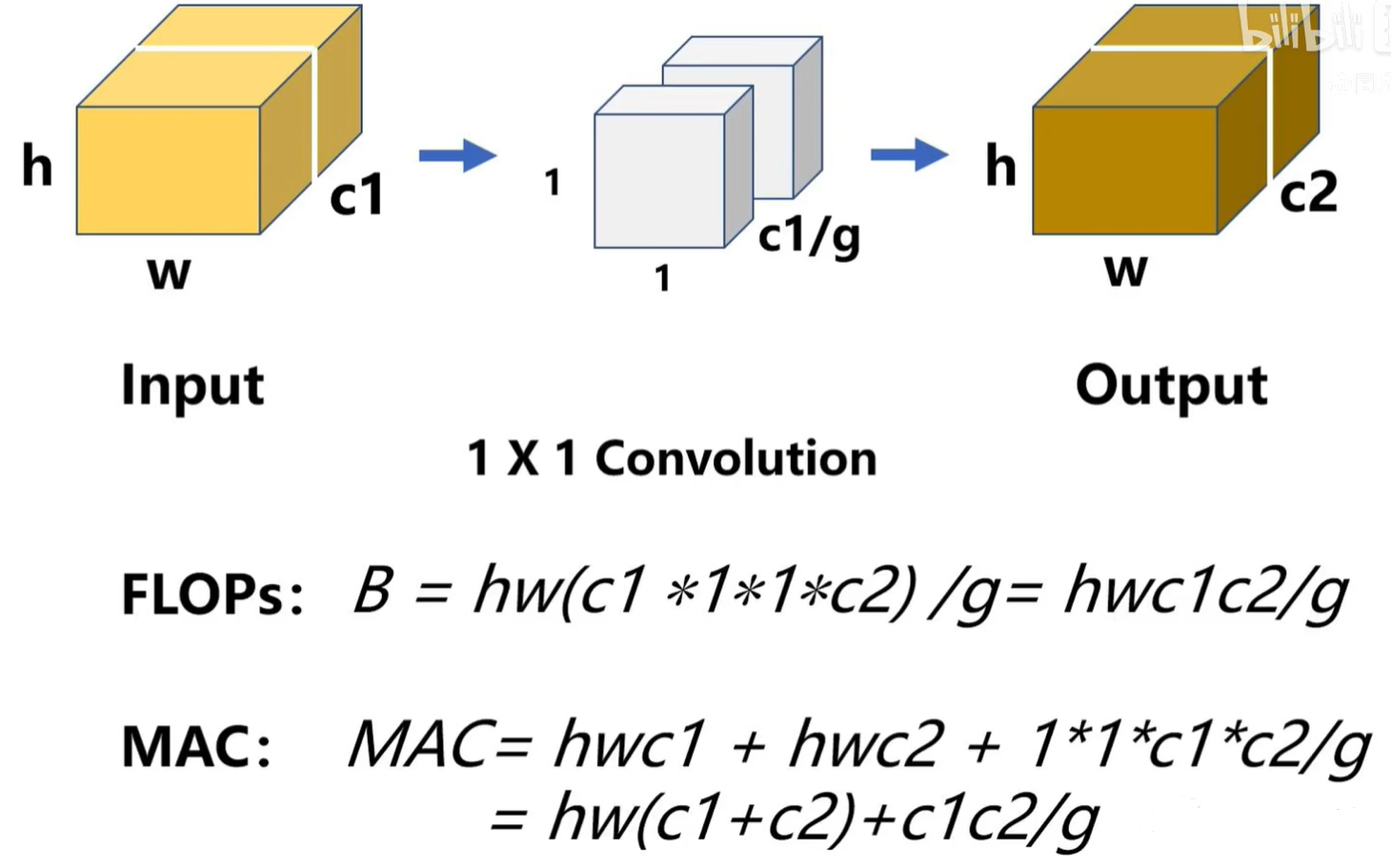
1 × 1卷积其实是轻量化网络里面计算量最大,参数量最多,计算最密集的部分,特别是使用了深度可分离卷积之后。
1×1卷积核的参数由两个量决定:
- 1.输入通道数C1
- 2.输出通道数C2
假设一个1×1卷积层的输入特征通道数是c1,输出特征尺寸是h和w,输出特征通道数是c2,那么这样一个1×1卷积层的FLOPs就是下面式子所示 :
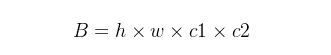
(更具体的写法是B=1×1×c1×c2×h×w,这里省略了1×1)
假设计算设备的内存足够大能够储存整个计算图和参数,那么:
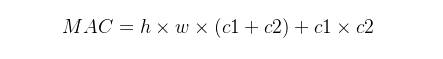
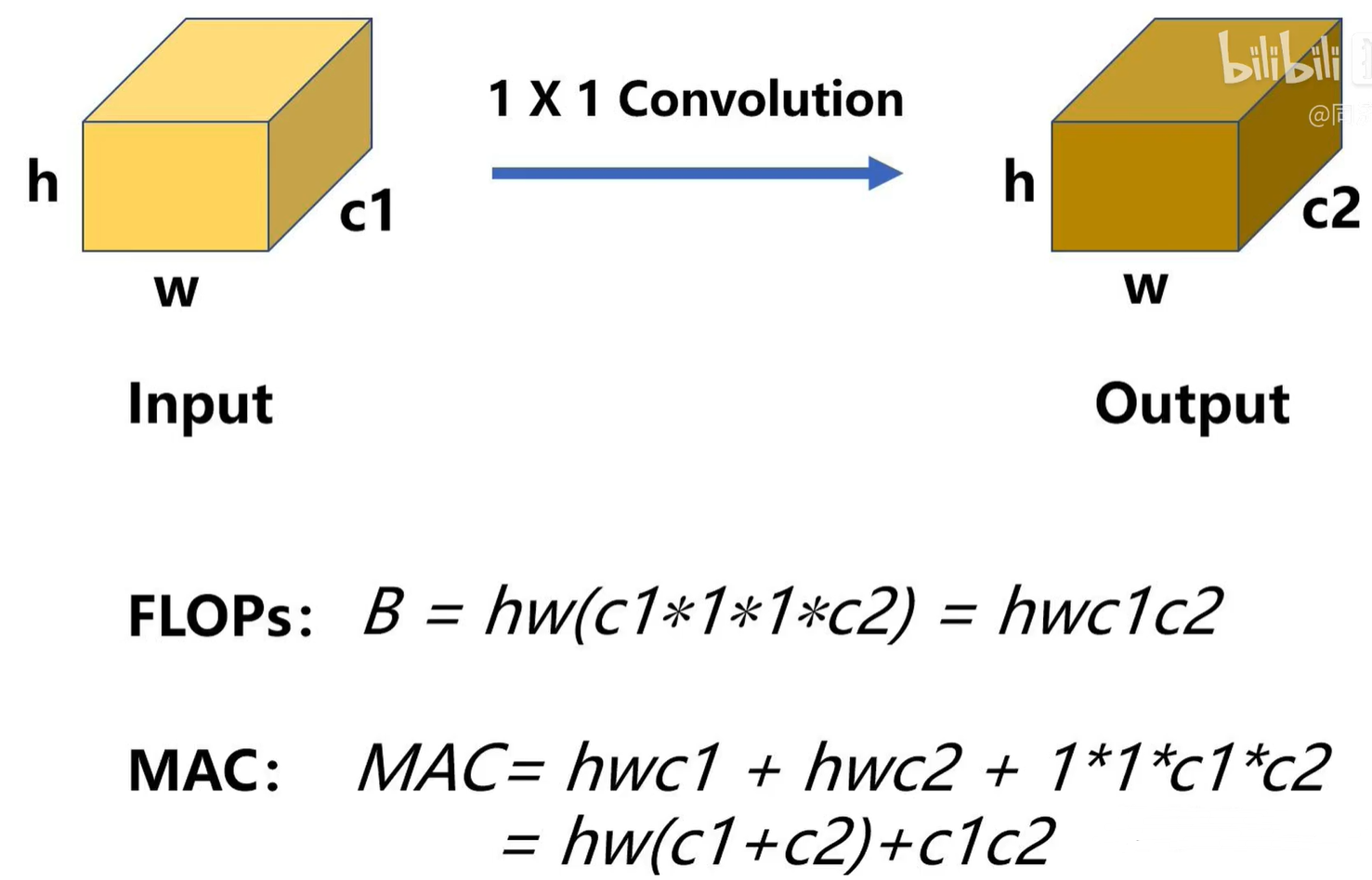
由中值不等式得:
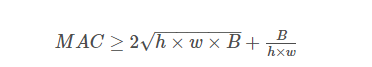
因此理论上MAC的下界由FLOPs决定,当且仅当C1 = C2 时取得最小值。
G2) Excessive group convolution increases MAC—过度的组卷积会增加 MAC
组卷积是ResNext提出的结构,使用了稀疏的平行拓扑结构来减少计算复杂度:
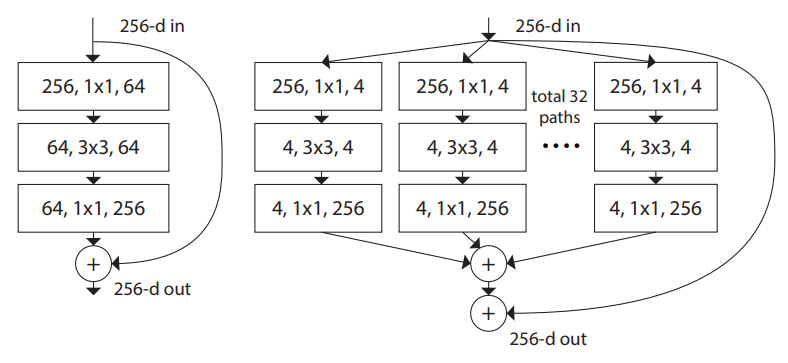
作者发现,虽然使用组卷积在相同计算复杂度的情况下拓展了通道数,但是通道数的增加也使得MAC大大增加。
假设 g 是1x1组卷积的组数,则有:
将FLOPs,也就是B代入下式中:
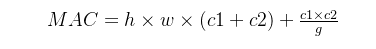
即:
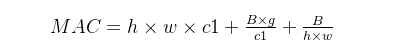
B和MAC其实是耦合的,所以在比较的情况下一般控制B不变进行比较。
可以看到,对于固定的输入大小 (h,w,ci) 和计算复杂度FLOPS (B),MAC随着 g 的增大而增加。
因此虽然提高g可以降低参数量、计算量降低,但是副作用就是MAC增大,MAC增大速度就会降低。因此要在速度和精度之间进行平衡。
下图是实验结果,g是分组数,可以看出组数越大速度越慢,特别是对于GPU而言。
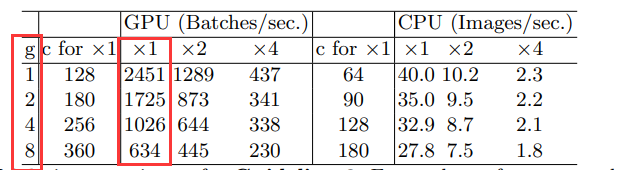
G3) Network fragmentation reduces degree of parallelism—网络碎片化会降低并行程度
碎片化操作:多分支、多通路,把网络变得很宽。
网络碎片化,减低模型的并行度,相应速度会慢。
GoogleNet系列就大量使用的Inception这样的multi-path结构(即存在一个lock中很多不同的小卷积或者pooling)增加了准确度:
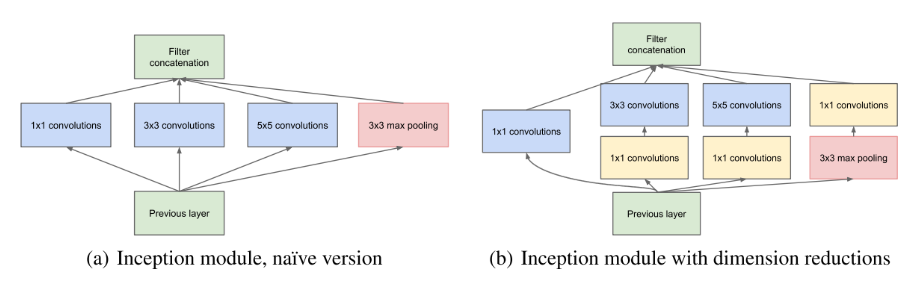
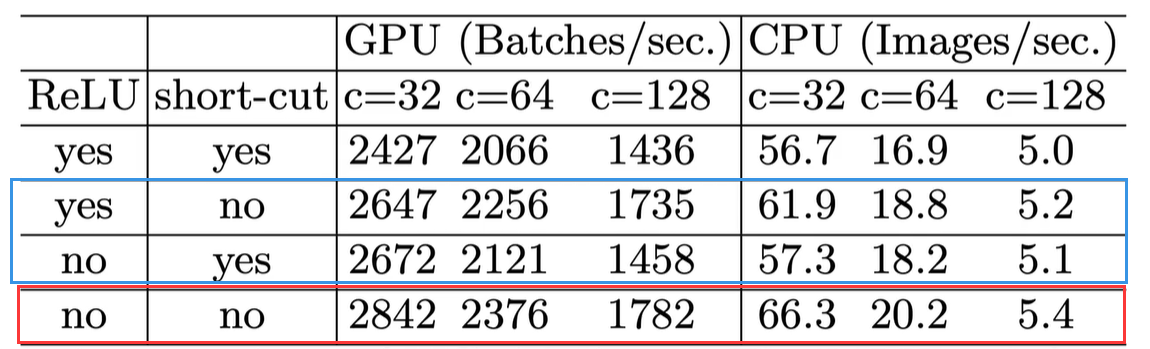
下图为实验结果FLOPs固定,网络越碎片化,推理速度越慢,特别是对GPU并行运算设备(红框和红框比,黄框和黄框比)和小型网络(蓝色框参数表示网络大小)。
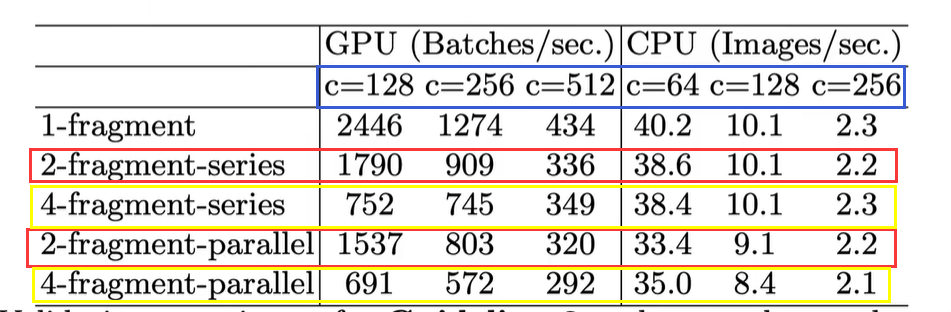
G4) Element-wise operations are non-negligible—Element-wise操作的影响不可忽略
这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话(最后一行),速度有20%的提升。单独移除也能提升速度(蓝色框内)。
ShuffleNet V2: an Efficient Architecture—一个高效的架构
基本单元
(a)和(b)ShuffleNet V1的基本单元(主要构成pointwise group convolution和channel shuffle)。
不足之处(有待商榷)
大量使用了1×1卷积,使用了分组卷积。—— 违背了 G2。
采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同(升维再降维)。—— 违背了 G1。
使用太多分组。—— 违背了 G3。
短路连接中存在大量的元素级Add运算。—— 违背了G4。
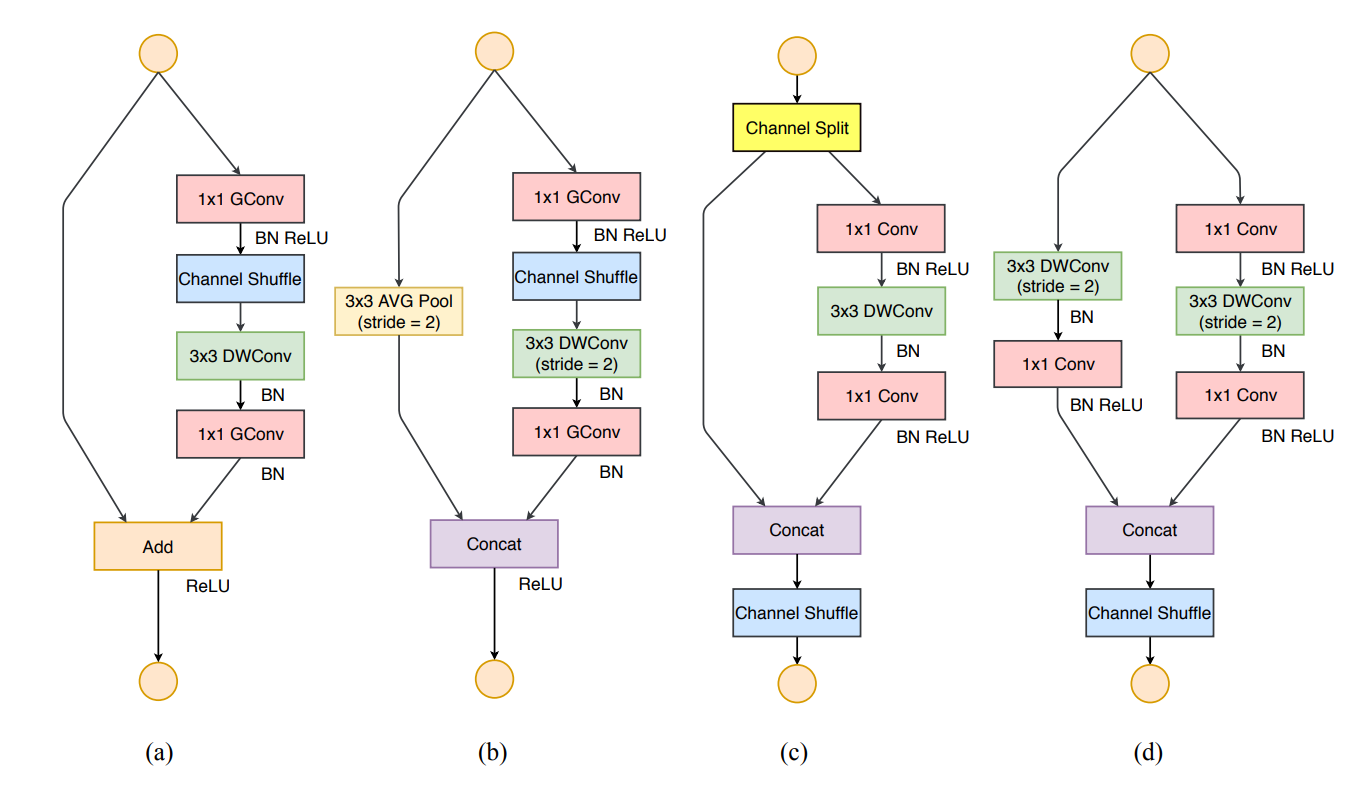
©和(d)ShuffleNet V2的基本单元
©单元:ShuffleNet V2 的基本单元
(1)增加了Channel Split操作,实际上就是把输入通道分为2个部分,一半通道走左边分支,一半通道走右边分支。
(2)根据G1: 左边分支做恒等映射,右边的分支包含3个连续的卷积(有一个深度可分离卷积),并且输入和输出通道相同,每个分支中的卷积层的输入输出通道数都一致。
(3)根据G2: 两个1x1卷积不再是组卷积。
(4)根据G3: 减少基本单元数。因此有一个分支不做任何操作,直接做恒等映射。
(5)根据G4: 两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channel shuffle,以保证两个分支信息交流。
完全满足G1和G2(恒等映射,输入输出通道一致;没用分组卷积),G3、G4(两个分支基本满足;ReLu函数的Element-wise操作不可避免)
注意: 右边分支最后那个1×1卷积后面是跟了BN以及ReLU的,这与v1先Add再ReLU不同。
(d)单元:用于空间下采样 (2×) 的 ShuffleNet V2 单元
对于下采样模块,不再有channel split,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
注意:©和(d)单元都是在concat后再进行channel shuffle,以此保证通道间的信息交融。
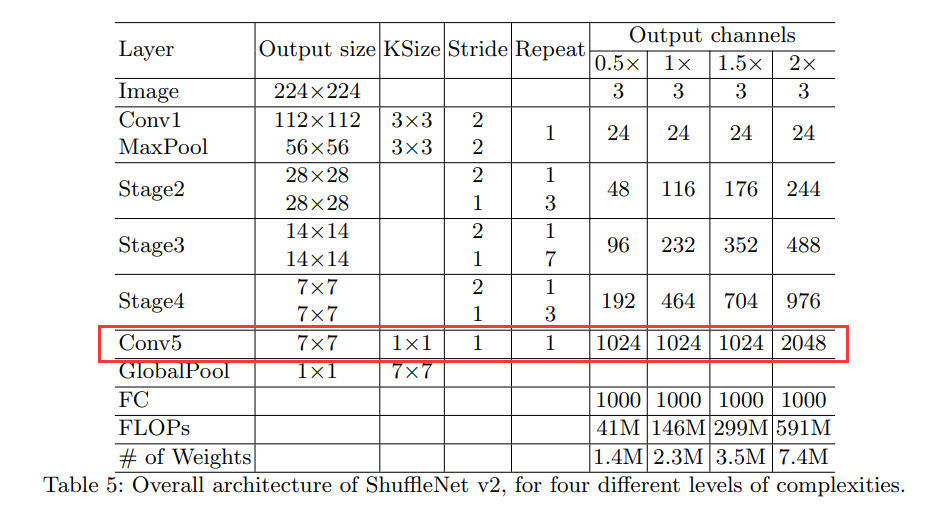
ShuffleNet V2 的整体架构
v2在全局池化层之前增加了个conv5卷积,这是与v1的一个区别。
Analysis of Network Accuracy—网络精度分析
ShuffleNet V2高效且准确率高的原因:
(1)每个构建模块非常高效,可以产生更多的通道和高强的网络;
(2)在每个模块中,一半的特征通道直接穿过该模块去了下一个模块(恒等映射),这可以被看作为某种“特征复用”,并且衰减指数为(1/2)^n。
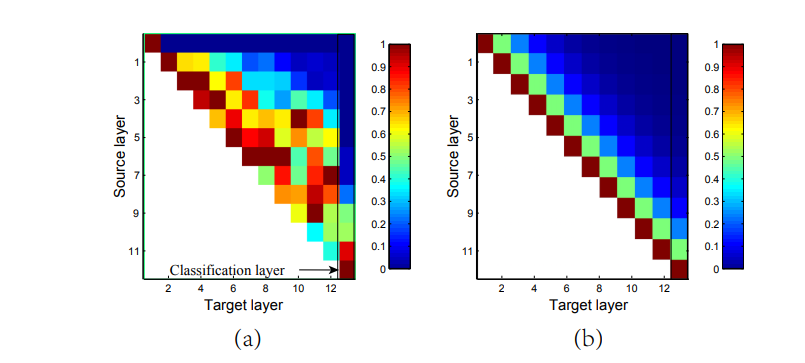
(a)是DenseNet论文中的图,表示第一个Dense Block中各个Dense Layer之间的权重绝对值。
DenseNet因为特征复用,所以性能很强大;
DenseNet训练出的特征复用模式,相邻的Dense Layer权重更大。
(b)是ShuffleNet V2各个Block之间通过channel split共享的复用通道数,相邻的block有更多的共享的复用特征,天然和DenseNet相似,因此性能也很强大。
总结
本文通过大量实验提出四条轻量化网络设计准则,对输入输出通道、分组卷积组数、网络碎片化程度、逐元素操作对不同硬件上的速度和内存访问量MAC的影响进行了详细分析。 提出ShuffleNet V2模型,通过Channel Split替代分组卷积,满足四条设计准则,达到了速度和精度的最优权衡。