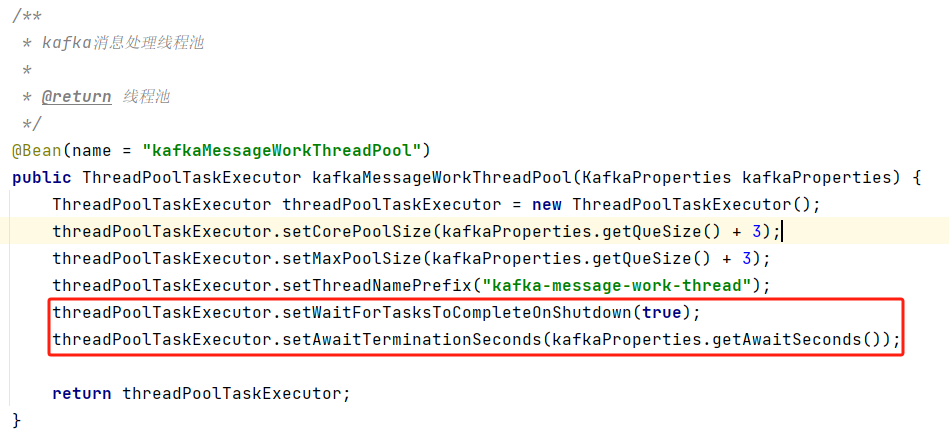
当大模型产生输出返回后,它的内容更像是一段平铺的文字没有结构。在传给下游节点处理时可能并不能符合输入要求,LangChain提供了一套机制使得模型返回的内容可以按照开发者定义的那样结构化。
在官网文档中可以看到LangChain提供了丰富的输出解析器,涵盖了常用的一些格式。比如CSV、JSON、XML和YAML,也有一些跟模型提供商相关的特定解析工具,比如OpenAI Functions和OpenAI Tools。具体内容可以快速查看这里的表中内容。
快速开始
使用输出解析器的方法很简单,只需要两步:
- 给出格式指令:给出语言模型输出应如何格式化的说明字符串。
- 进行解析:对接受的字符串进行解析,成为符合某种结构的输出。
以JSON解析器(其他解析器使用方法类似,可以参看官方文档进行)为例,示例代码如下:
from langchain.output_parsers import PydanticOutputParser
from langchain_core.output_parsers import CommaSeparatedListOutputParser, JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_community.llms import Ollama
model = Ollama(model="llama3", temperature=0.0)
# 定义输出格式的字段属性。
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# 添加自定义的格式检查。
@validator("setup")
def validate_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
# 定义需要的输出解析器。
parser = JsonOutputParser(pydantic_object=Joke)
# 通过format_instructions输入格式化的指令。
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# LCEL组装带有输出解析器的chain,当chain被调用invoke后,parser最终按照格式解析后输出结果。
prompt_and_model = prompt | model | parser
output = prompt_and_model.invoke({"query": "Tell me a joke about bear."})
print(output)
首先,Joke类定义了输出内容的格式,其中指定了"setup"和"punchline"字段,以及提问时的格式校验。
其次,实例化JSON格式的输出解析器(JsonOutputParser)对象,指定格式为前面定义的Joke。
然后,在定义prompt时候传入format_instructions,指示后续的格式化形式。
最后,定义的chain中使用该parser。
我们可以看到输出为:

自定义输出解析器
如果觉得LangChain 提供的解析器武德不够充沛,可以自己动手打造自己专属的“武器”。LangChain提供了两种方法:
- 使用
RunnableLambda或者RunnableGenerator,这种方法简洁明了,推荐使用。 从解析器基类继承编写新的类,相对比较复杂。
RunnableLambda/RunnableGenerator自定义解析
使用这个方法,我们定义自己的处理方法,接收某个输入,然后将其做对应转换后返回。以RunnableLambda为例如下:
from langchain_community.chat_models import ChatOllama
from langchain_core.messages import AIMessage
# from langchain_core.runnables import RunnableLambda
# 定义自己的解析方法
def parse(ai_message: AIMessage) -> str:
# 传入AIMessage类型的参数,这是Chat Model的输出
return ai_message.content.swapcase()
# 定义一个Chat Model
model = ChatOllama(model="llama3")
# LCEL定义一个chain
chain = model | parse
print(chain.invoke("hello"))
# output = model.invoke("hello")
#
# parse = RunnableLambda(parse)
# print(parse.invoke(output))
定义了自己的解析处理方法parse,注意它接受AIMessage类型的输入,这是Chat Model的输出类型,在model定义时我们使用了ChatOllama类型。它的输出给到parse解析得到最终输出,使用LCEL即是:
chain = model | parse这里的LCEL将parse自动封装为RunnableLambda,可以理解这个操作如下面内容(注释部分):
output = model.invoke("hello")
parse = RunnableLambda(parse)
print(parse.invoke(output))最终的输出:

将语言模型的输出结果进行了大小写调换。
继承解析基类
可以通过继承一个简单的定制化解析器类BaseOutputParser来自定义自己的解析器类。只需要重写parse方法,加入自己的解析逻辑即可。_type方法返回str类型信息,主要用于日志相关功能。使用自定义的解析器类对象,解析大模型的输出。如下代码所示:
from langchain_community.llms.ollama import Ollama
from langchain_core.output_parsers import BaseOutputParser
# 继承BaseOutputParser,定义parse和_type
class MyCustomOutputParser(BaseOutputParser[str]):
# 自定义解析方法
def parse(self, text: str) -> str:
return text.swapcase()
# 本自定义解析器类的type属性,用于Log。 可选。
@property
def _type(self) -> str:
return "my_custom_parser"
# 定义一个LLM,返回str
model = Ollama(model="llama3")
# 初始化自定义的解析器对象
parser = MyCustomOutputParser()
# 调用自定义解析器进行解析
print(parser.invoke(model.invoke("hello")))
该自定义解析子类的方法,得到跟前面的RunnableLambda方法一样的结果。

也可以通过继承BaseGenerationOutputParser类来自定义自己的解析类,这样能够更好和更多地控制解析输出结果,比如对模型输出里的metadata内容进行解析。使用方法上和继承BaseOutputParser的方法大致相当,只是重写的方法是parse_result。有兴趣可以参考这里,不再赘述。
通过Model I/O的介绍,大家基本上可以写个简单的LLM应用了。通过prompt输入用户的提示语,经过LLMs/ChatModel处理后,输出结果通过Output Parser解析后最终返回用户一个期望格式的内容。
当然,为了LLM应用更好的结果,我们可能还需要提供更多的内容给到底层的大模型来处理,这就是“Retrieval”相关的内容了。