paper:Talking-Heads Attention
在CaiT这篇文章中,作用采用了talking-heads attention,这里做一下解释。
在原始multi-head self-attention中,各个head的计算是独立进行的,多个head的输出最后concat到一起,然后再经过一个线性变换得到最终的输出。
本文提出了在softmax操作的前后引入跨注意力头维度的线性变换,从而使每个self-attention函数依赖于所有的key和query。
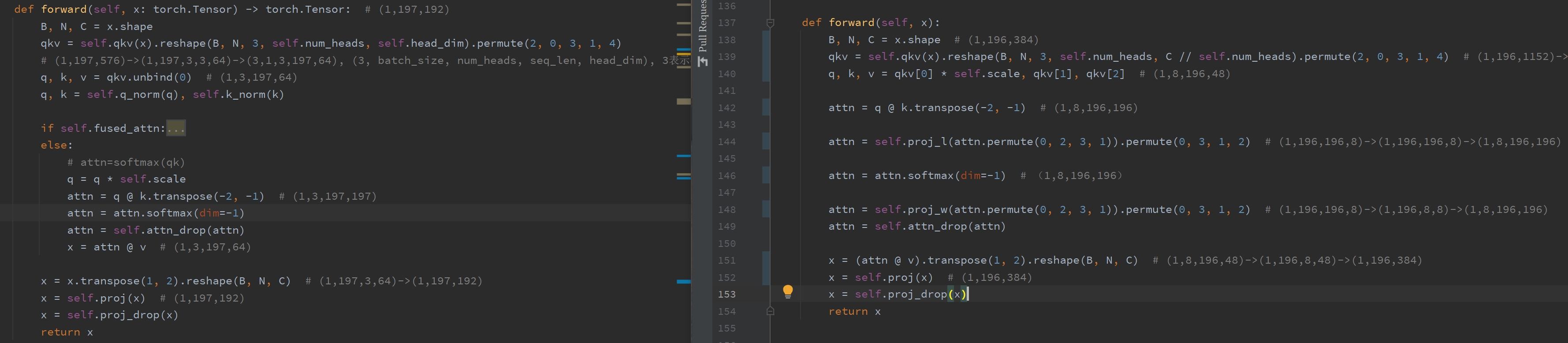
下面分别是timm中普通Attention和TalkingHeadAttention的实现
# class Attention
def forward(self, x: torch.Tensor) -> torch.Tensor: # (1,197,192)
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
# (1,197,576)->(1,197,3,3,64)->(3,1,3,197,64), (3, batch_size, num_heads, seq_len, head_dim), 3表示qkv
q, k, v = qkv.unbind(0) # (1,3,197,64)
q, k = self.q_norm(q), self.k_norm(k)
if self.fused_attn: # False
x = F.scaled_dot_product_attention(
q, k, v,
dropout_p=self.attn_drop.p if self.training else 0.,
)
else:
# attn=softmax(qk)
q = q * self.scale
attn = q @ k.transpose(-2, -1) # (1,3,197,197)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = attn @ v # (1,3,197,64)
x = x.transpose(1, 2).reshape(B, N, C) # (1,197,3,64)->(1,197,192)
x = self.proj(x) # (1,197,192)
x = self.proj_drop(x)
return x
# class TalkingHeadAttn
def forward(self, x):
B, N, C = x.shape # (1,196,384)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # (1,196,1152)->(1,196,3,8,48)->(3,1,8,196,48)
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2] # (1,8,196,48)
attn = q @ k.transpose(-2, -1) # (1,8,196,196)
attn = self.proj_l(attn.permute(0, 2, 3, 1)).permute(0, 3, 1, 2) # (1,196,196,8)->(1,196,196,8)->(1,8,196,196)
attn = attn.softmax(dim=-1) # (1,8,196,196)
attn = self.proj_w(attn.permute(0, 2, 3, 1)).permute(0, 3, 1, 2) # (1,196,196,8)->(1,196,8,8)->(1,8,196,196)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # (1,8,196,48)->(1,196,8,48)->(1,196,384)
x = self.proj(x) # (1,196,384)
x = self.proj_drop(x)
return x从下图的对比看的更加清楚,左边是普通的attention,右边是talking-heads attention。左边的输入shape为(1, 197, 192),其中197=196+1是添加了class token,192是特征维度。右边的输入shape为(1, 196, 384),特征维度为384。左边num_heads=3,右边num_heads=8。因为左边的代码来自vision transformer,右边的代码来自CaiT,选择的具体模型variant不同,所以特征维度和head数量也不一样,但不影响。
可以看到,TalkingHeadAttention在计算softmax前后分别引入了一个线性变换self.proj_l和self.proj_w,定义分别为self.proj_l = nn.Linear(num_heads, num_heads)和self.proj_w = nn.Linear(num_heads, num_heads)。在线性变换前先对输入进行维度变换通过.permute(0, 2, 3 ,1)将num_head维度放到最后,因此线性变换是针对num_head维度的,从而实现跨head的交互,最后再permute回去。