介绍
是 Apache 的顶级开源项目,一个分布式框架,主要功能:
- 分布式大数据存储——HDFS 组件
- 分布式大数据计算——MapReduce 组件
- 分布式资源调度——YARN 组件
学习起来相对简单,市场占有率高,为后续的其他大数据软件学习打下基础
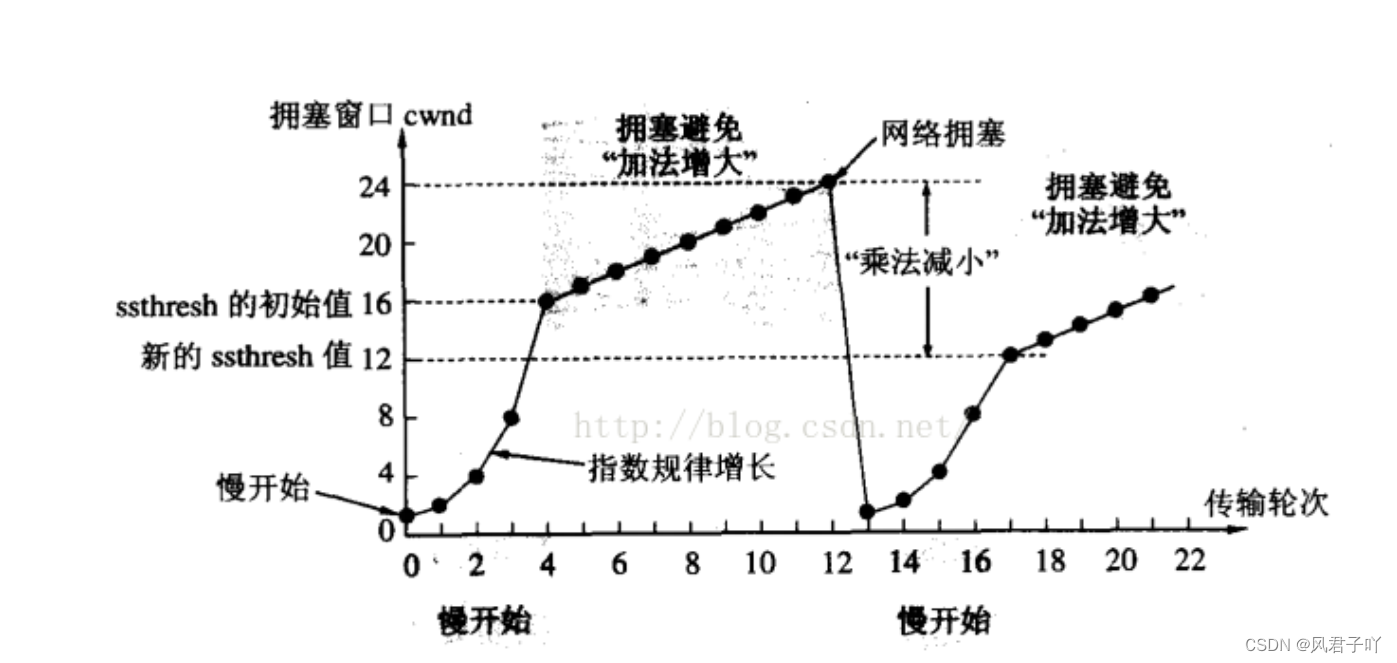
HDFS
Hadoop Distributed File System,Hadoop 分布式文件系统,是一个用来存储数据的组件
为什么需要分布式来存储
单台服务器无法存储太大的数据,那就把文件分成多个部分,用多台服务器存储多个部分
多台服务器还可以实现性能横向扩展,比如带宽、磁盘 IO 、CPU 运算速度等
如何管理多个服务器
在大数据中大部分都是主从模式,这个 Hadoop 就是主从模式
基础架构
主角色:NameNode(是一个独立的进程,负责管理整个 HDFS 和 DataNode;领导)
从角色:DataNode (是一个独立的进程,主要负责存取数据;员工)
主角色辅助角色:SecondaryNameNode (是一个独立的进程,协助主角色合并元数据,这就是它唯一的作用;老板秘书)
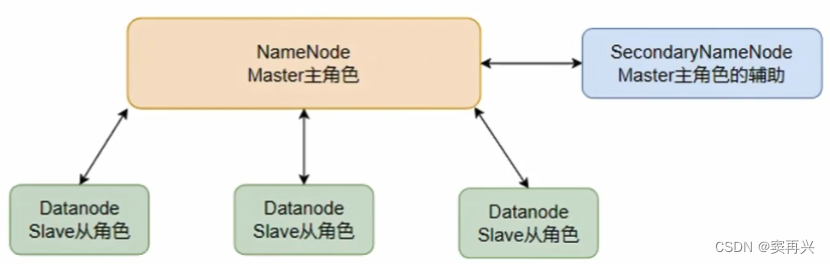
- NameNode 负责整个集群的管理,元数据的记录和权限的审核
- DataNode 负责集群中文件的存储
- SecondaryNameNode 负责合并元数据文件(edits & fsimage)
可以在 IDEA 中下载 Big Data Tools 插件,再进行一波配置就能连接上远程的 HDFS 了,可以用图形化界面进行文件的增删改查
VMware 集群部署配置
上传 & 解压
把 Hadoop 的压缩包上传到 /export/server 中,并解压
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
修改配置文件


workers

hadoop-env.sh

core-site.xml

<configuration>
<property>
<name?>fs.defaultFS</name>
<value>hdfs:node1:8020</value>
</property>
<property>
<name?>io.file.buffer.size</name>
<value>131072</value>
</property>

hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
创建数据保存的目录

把 node1 中的文件复制给另两个
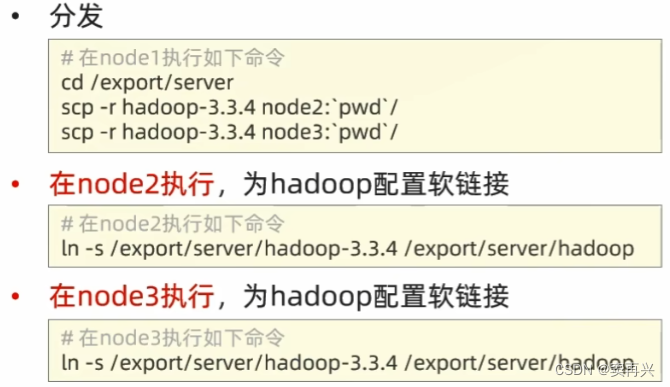
cd /export/server
scp -r hadoop-3.3.4 node2:/export/server
scp -r hadoop-3.3.4 node3:/export/server
软连接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
为授权 hadoop 用户
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
格式化 HDFS
su hadoop
# 启动HDFS集群
start-dfs.sh
# 停止HDFS集群
成功标志

启动后,输入 jps,node1 有这些,node2/3 只有 DataNode
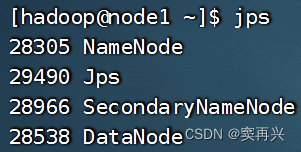
如果无法启动,说明配置文件或者权限有问题,去看日志+问AI基本都能解决
启动后,访问这个地址,可以看到 web 管理页面(Windows 的 hosts 文件有映射)
启动完毕后,关机,打快照,ssh 以后用 hadoop 用户登录
HDFS 操作
一键启动、停止
# 启动HDFS集群
start-dfs.sh
# 停止HDFS集群

单进程启停

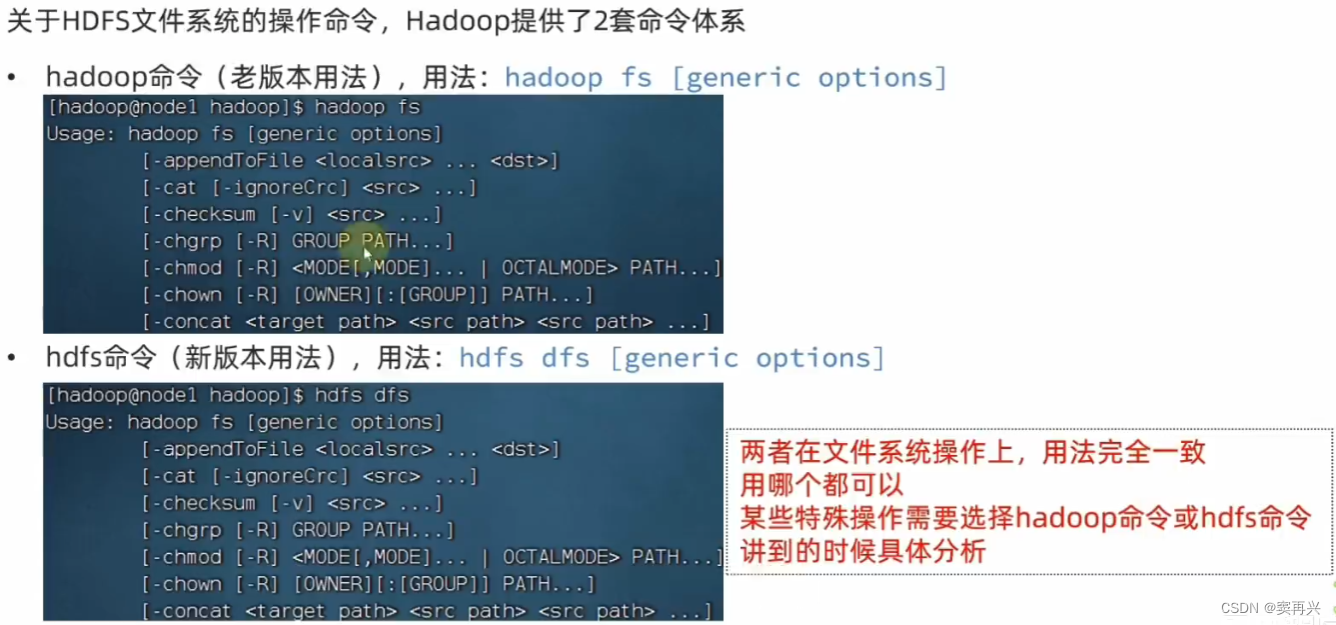
文件系统操作命令
HDFS 的目录形式和 Linux 一样,命令名称和 Linux 几乎一样,在前面加上特定的关键字即可
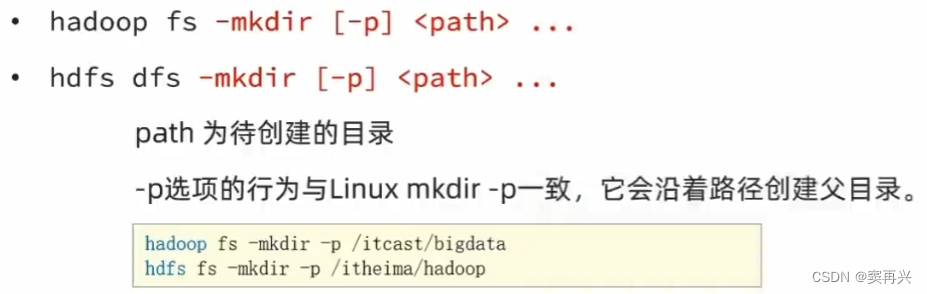
创建文件夹
hadoop 会自动识别创建的目录是 HDFS 还是 Linux 的目录的
查看目录中的内容

上传文件到 HDFS 指定目录
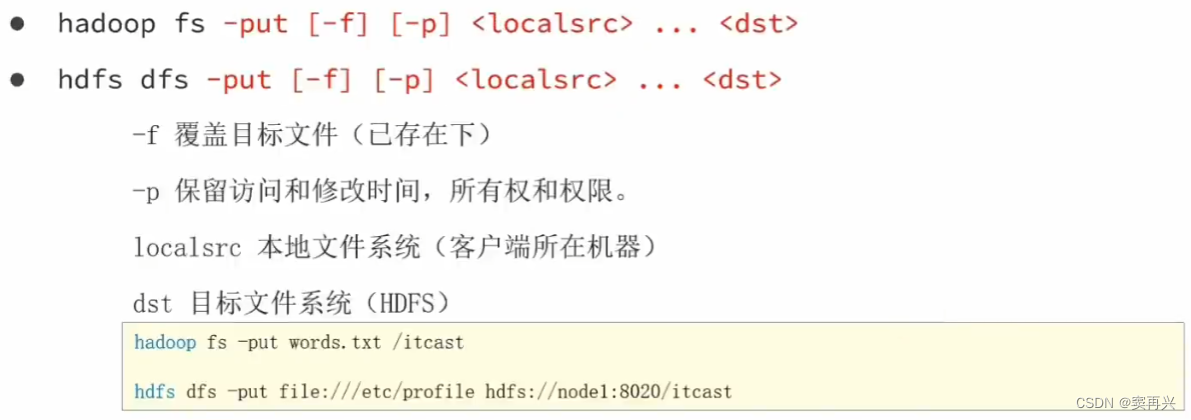

查看 HDFS 中文件内容

下载 HDFS 文件

复制 HDFS 文件

追加/删除 HDFS 文件内容

移动 HDFS 文件

删除 HDFS 文件

回收站功能

第一个的 1440,表示保留时长为一天(24 * 60 = 1440 min)
注意这个配置修改后会立即生效,在哪个机器进行配置,就在哪生效
web UI 操作 HDFS
切换到 root 用户,修改 core-site.xml 文件,然后重启集群
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
HDFS 权限

这个 supergroup 是启动 namenode 的用户(在本文中是 hadoop 用户)
谁启动谁就是超级用户,root 在 Linux 上超级用户,但是在 HDFS 中只是普通用户,无特权

HDFS 存储原理
block 块与备份
这是文件在 HDFS 中存储的统一单位,叫 block,一个 block 默认的大小是 256 MB(可以修改)
如果有个块出问题了怎么办?这样文件取出来后是损坏的(有点像 raid 0)
修改备份数

block 配置文件

临时设置备份数和 fsck 命令


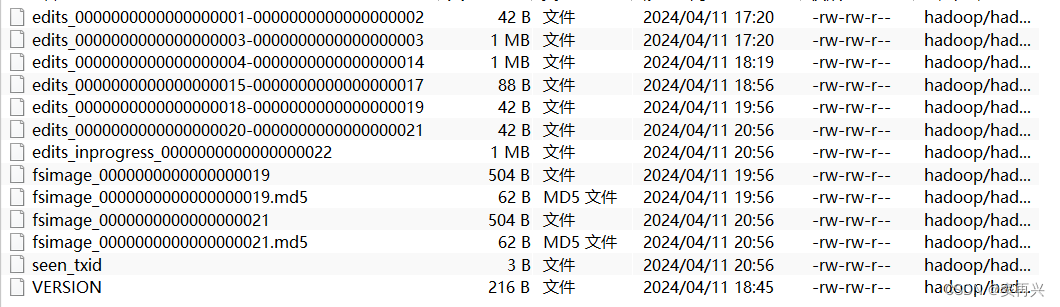
元数据记录-NameNode
HDFS 中有很多的块和文件,hadoop 如何记录和整理文件和 block 之间的关系?通过 NameNode 写入的两个文件
edits 文件
是一个流水账文件,记录了 HDFS 中的每一次操作,还有本次操作影响的文件和对应的 block

还有就是因为记录的是流水账,如果前面记录了新增文件,后面又删除了,所以查找文件时,需要从头到尾遍历所有的 edits 文件,这样效率就很低
解决方法:只要最后的结果,叫做 edits 文件的合并(那这种方法和 AOF 文件一样),这样的体积就会小很多
fsimage 文件
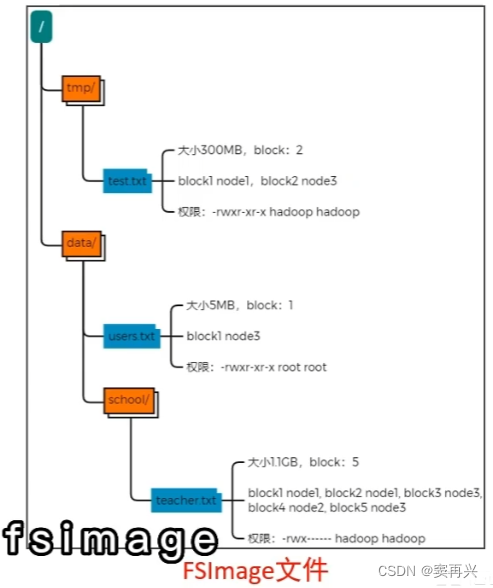
如果之前已经存在了 fsimage 文件,会将全部的 edits 文件和已经存在的 fsimage 文件进行合并,形成新的 fsimage 文件
合并时间设置

谁来进行合并
在 HDFS 架构中,NameNode 有个辅助角色:SecondaryNameNode
它就是进行数据合并的,这也是它唯一的作用,不启动它的话,文件搜索的速度会越来越慢
它通过 HTTP 获取 edits 和 fsimage,合并完成后再提供给 NameNode
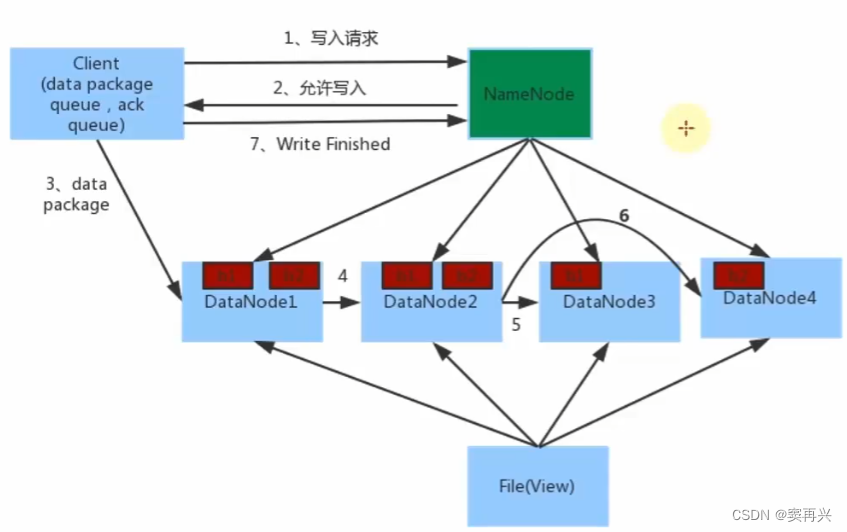
HDFS 写入数据流程
- 客户端向 NameNode 发送写入请求
- NameNode 检查客户端是否具有写入权限,HDFS 剩余空间是否充足;如果都 OK,那么会返回允许写入的消息,和要写入的地址(某个 DataNode 的 IP)
- 客户端向指定的 DataNode 发送数据包(写入数据)
- 被写入数据的 DataNode,会完成数据备份的操作,并将这些数据发送给其他的 DataNode
- 客户端通知 NameNode 写入完毕;NameNode 向 edits 和 fsimage 文件中写入数据
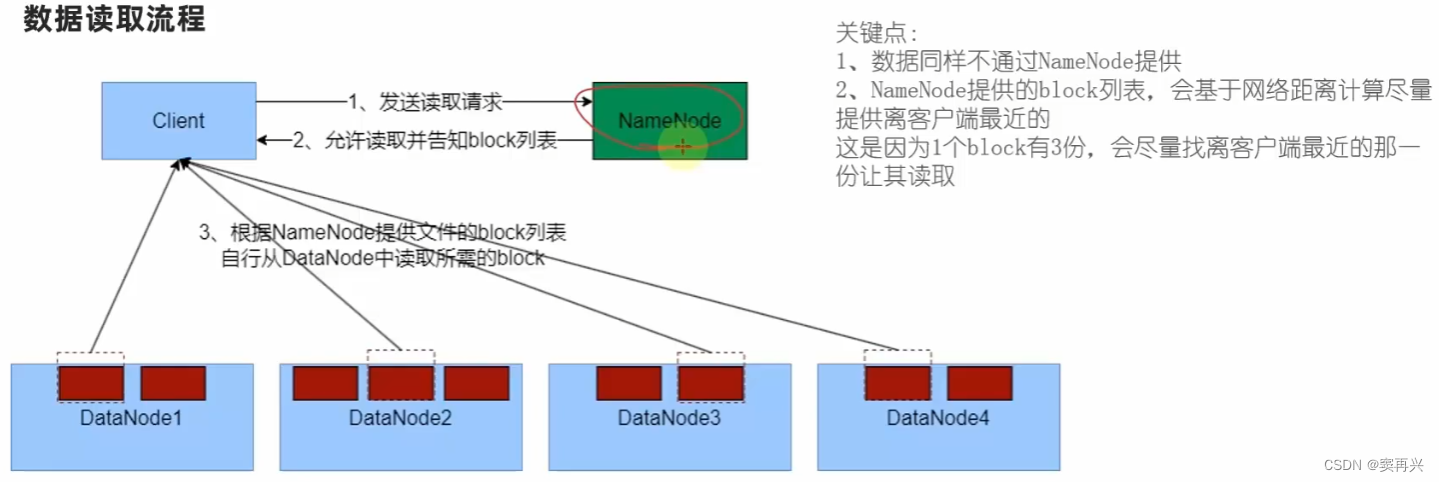
HDFS 读取文件流程
- 客户端发送读取请求给 NameNode
- NameNode 允许读取,并返回该文件的 block 列表
- 客户端根据列表,去 DataNode 中读取文件
MapReduce
分布式计算
多台计算机一起来计算,就是分布式计算;那这就会涉及多台计算机的管理问题
- 对于很大的数据,每台计算机得到一部分来进行计算
- 算完后,将各自的结果汇总到一台计算机中
- 最后由这台计算机计算出最终的结果
- 让一个节点作为总指挥,将任务分成若干个步骤
- 总指挥将任务下发给多个计算机,它们执行计算
不同点:在执行完某些步骤后,不同计算机之间会进行结论的交换后,才能继续进行计算
MapReduce 使用的是 分散-汇总模式,而更牛的框架(spark、flink 使用中心调度-步骤执行模式)
介绍
它是 Hadoop 的一个组件,用来进行分布式计算的一个框架;计算的模式:分散-汇总模式
- Map,提供“分散”功能,由多个服务器分布式地对数据进行处理
- Reduce,提供“汇总”功能,将分布式计算的结果进行汇总
但是现在基本都是使用 Hive 框架,它的底层是 MapReduce,所以这里只是简单介绍
简单分析执行原理
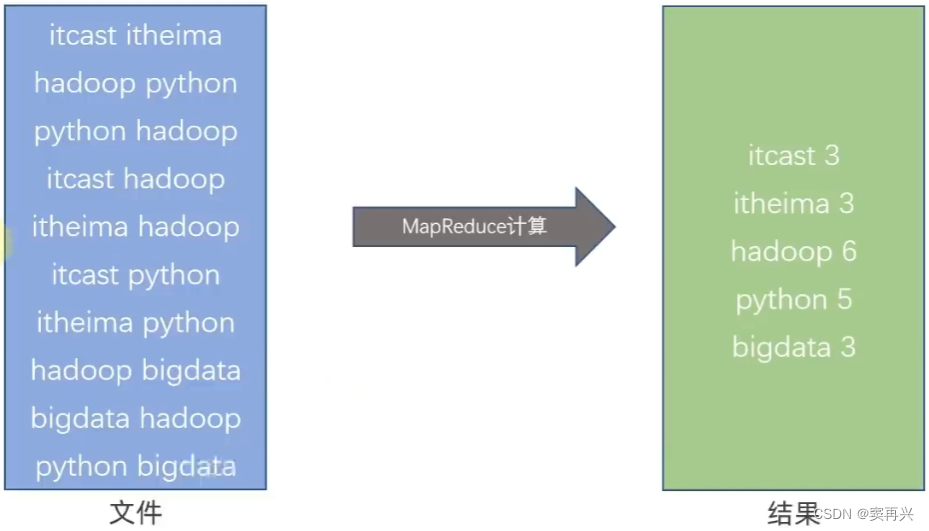
现在有三台服务器,两台执行 Map 的任务,一台执行 Reduce 的任务
会将文件分为多个部分,每台机器统计该部分的单词数量,最后将结果交给汇总的服务器
Yarn
对于多台服务器,需要有规划、统一地去调度各种硬件资源,提高资源利用率
MapReduce 是基于 Yarn 运行的,这样可以得到更好的资源利用率
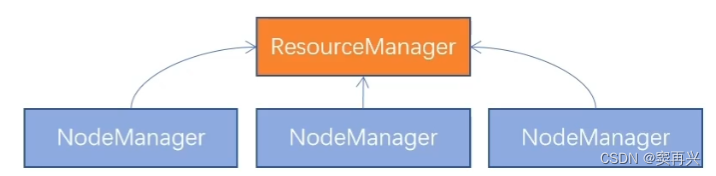
核心架构
- 主角色:ResourceManger,负责集群的资源调度,协调调度各个程序所需的资源(老板)
- 从角色:NodeManager,负责单台服务器的资源调度(各部门经理)
一个程序过来申请资源,就先去找 ResourceManager 要资源,老大再去通知小弟
容器
NodeManager 预先占用一部分资源,再将这部分资源提供给程序使用;程序使用的资源上限就是容器占用资源的大小,不能突破
程序需要 4GB 内存,那 NodeManager 就先占用 4GB 内存,然后将这些内存给程序使用
辅助架构
代理服务器-ProxyServer
在 Yarn 运行时,也会有一个 Web UI,如果在公网上就可能遭受攻击
历史服务器-JobHistoryServer
记录历史运行的程序信息、产生的日志、提供WEB UI站点供用户使用浏览器查看。
有它的原因是 Yarn 是用容器来分配资源的,如果要查看某个容器的日志,是比较麻烦的
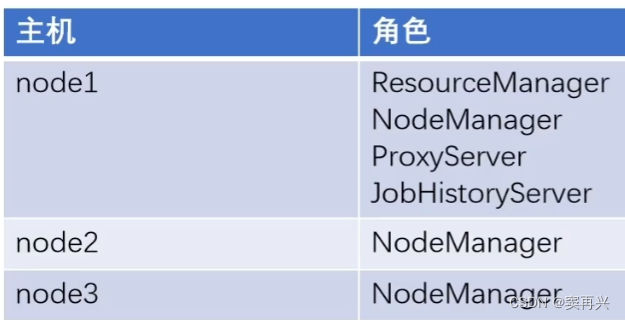
Yarn 集群部署
ProxyServer、JobHistoryServer 进程作为辅助节点
而 MapReduce 是运行在 Yarn 容器中的,所以无需独立启动进程,它也没有独立的进程,改改配置文件即可
MapReduce 配置文件
切换为 root 用户,来到 /export/server/hadoop-3.3.4/etc/hadoop 目录
# 设置 JDK 路径
export JAVA_HOME=/export/server/jdk
# 设置 JobHistoryServer 进程内存为 1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为 INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce 的运行框架设置为 YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description>历史服务器地址:node1:10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>历史服务器web端口为node1的19888</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description>历史信息在HDFS的记录临时路径</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>历史信息在HDFS的记录路径</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为 HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为 HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为 HADOOP_HOME</description>
</property>
YARN 配置文件
切换为 root 用户,来到 /export/server/hadoop-3.3.4/etc/hadoop 目录
# JDK 环境变量
export JAVA_HOME=/export/server/jdk
# HADOOP_HOME
export HADOOP_HOME=/export/server/hadoop
# 配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
# 日志文件的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
<configuration>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description>历史服务器URL</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合,可以在浏览器中看到整理好的日志</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>ResourceManager设置在node1节点</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager数据的本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为MapReduce程序开启shuffle服务</description>
</property>
把配置文件发送给其他服务器
cd /export/server/hadoop/etc/hadoop
scp * node2:/export/server/hadoop-3.3.4/etc/hadoop/
scp * node3:/export/server/hadoop-3.3.4/etc/hadoop/
一键启动停止
start-yarn.sh
启动历史服务器
mapred --daemon start historyserver
单独控制进程
$HADOOP_HOME/bin/yarn,此程序也可以用以单独控制所在机器的进程启停
yarn --daemon (start|stop) (resourcemanager|nodemanager|proxyserver)
查看结果 & 打快照
访问 http://node1:8088/,如果能看到页面,说明一切 OK