阅读完此论文后,对着代码过一遍思路
原文地址:https://arxiv.org/abs/2304.14394
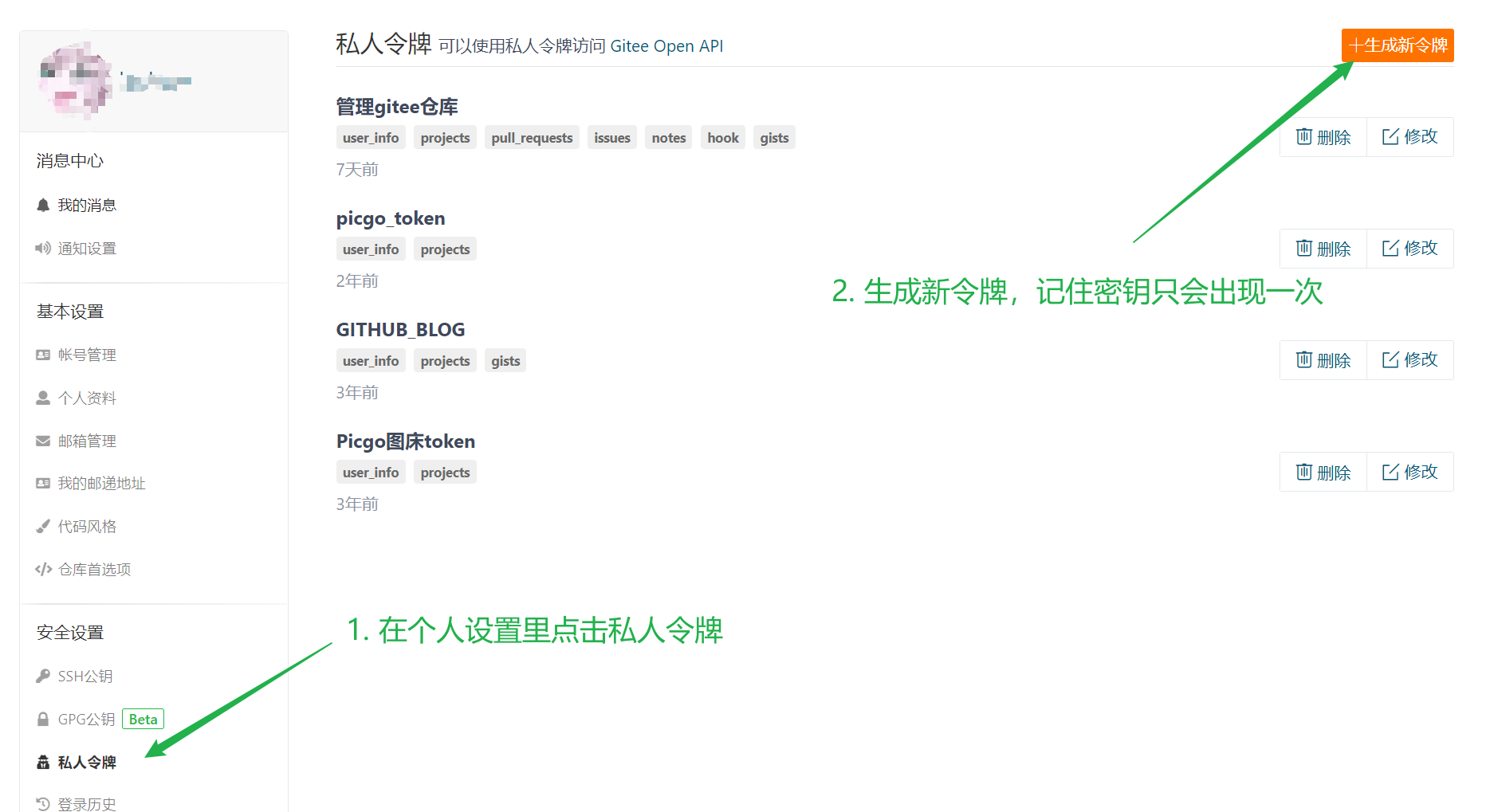
本文将视觉跟踪建模为一个序列生成问题,以自回归的方式预测目标边界框。抛弃了设计复杂的头网络,采用encoder-decoder transformer architecture,编码器用ViT提取视觉特征(≈OSTrack),而解码器用因果转换器自回归生成一个边界框值序列。

图像表示
编码器输入模板和搜索图像。现有的跟踪器中模板图像的分辨率通常小于搜索图像的分辨率,SeqTrack使用相同的尺寸,发现在模板中添加更多的背景有助于提高跟踪性能(在其他工作里使用小尺寸模板图像都解释的是为了减少背景干扰,这里说法不是很一致)。
DATA:
MAX_SAMPLE_INTERVAL: 400
MEAN:
- 0.485
- 0.456
- 0.406
SEARCH:
CENTER_JITTER: 3.5
FACTOR: 4.0
SCALE_JITTER: 0.5
SIZE: 384
NUMBER: 1
STD:
- 0.229
- 0.224
- 0.225
TEMPLATE:
CENTER_JITTER: 0
FACTOR: 4.0
SCALE_JITTER: 0
SIZE: 384
NUMBER: 2
TRAIN:
DATASETS_NAME:
- GOT10K_train_full
DATASETS_RATIO:
- 1
SAMPLE_PER_EPOCH: 30000序列表示
边界框转换为离散序列[ x , y , w , h ] [ x , y , w , h][x,y,w,h],将每个连续坐标统一离散为[ 1 , nbins]之间的整数。使用共享词汇表V(4000),V中的每个单词对应一个可学习的嵌入,在训练过程中进行优化。如下代码所示:
class DecoderEmbeddings(nn.Module):
def __init__(self, vocab_size, hidden_dim, max_position_embeddings, dropout):
super().__init__()
self.word_embeddings = nn.Embedding(
vocab_size, hidden_dim)
self.position_embeddings = nn.Embedding(
max_position_embeddings, hidden_dim
)
self.LayerNorm = torch.nn.LayerNorm(
hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
input_embeds = self.word_embeddings(x)
embeddings = input_embeds
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings最终使用一个带softmax的多层感知器,根据输出嵌入对V中的单词进行采样来将嵌入映射回单词。
模型架构
它的基本架构是这样:
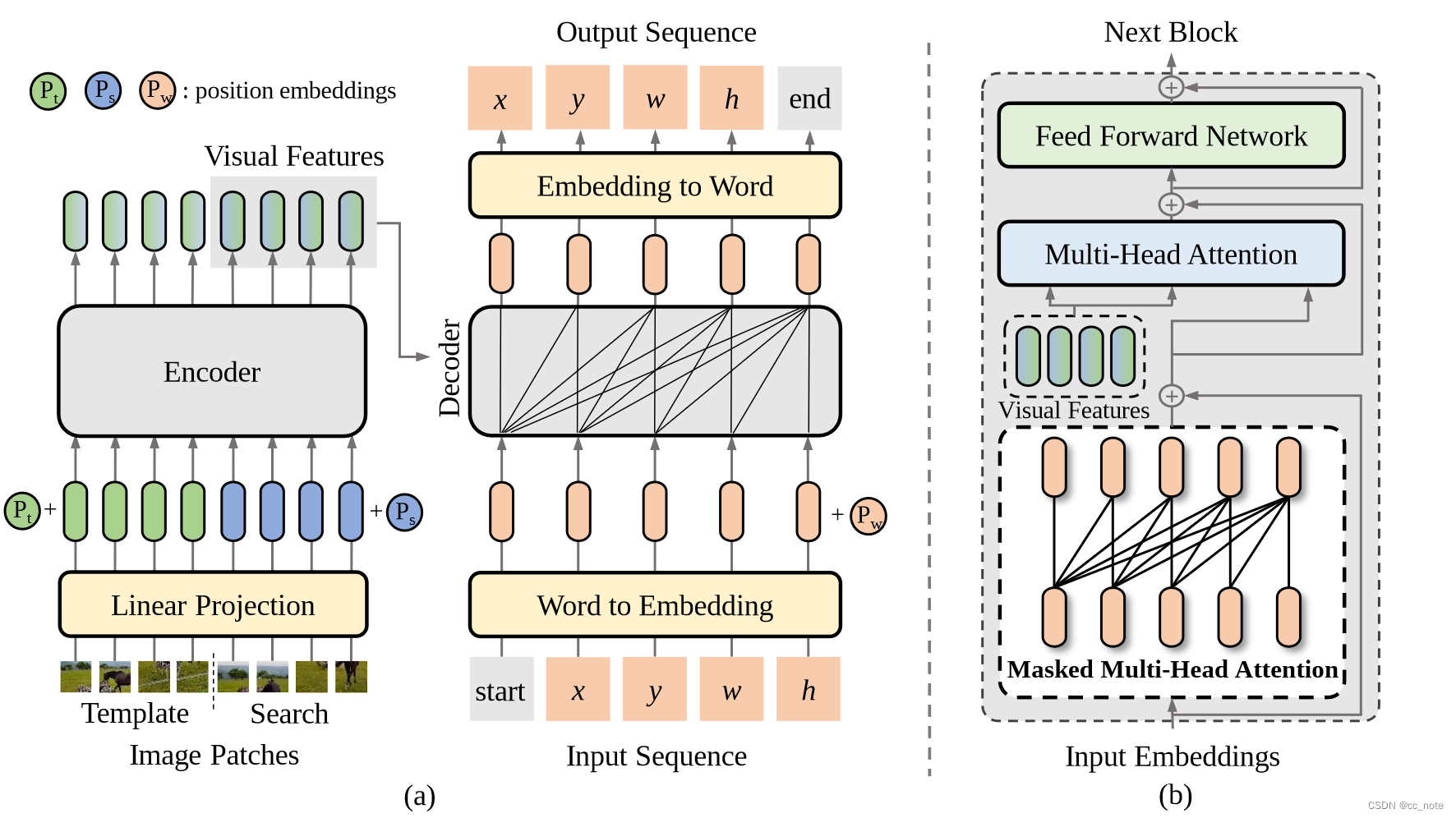
SeqTrack的架构,a:左边编码器拿的ViT,右边解码器用的transformer里的。编码器提取视觉特征,解码器利用特征自回归生成边界框序列。b:解码器结构,最下层输入目标序列,先自注意力再与视觉特征做注意力,自回归输出生成目标序列。
解码时加入一个因果注意力掩码(NLP那边用的差不多,防止偷看后边的果)
使用了两个特殊的标记:start和end。开始令牌告诉模型开始生成,而结束令牌则表示生成的完成。
训练时,解码器的输入序列为[start,x,y,w,h] [start,x,y,w,h][start,x,y,w,h],目标序列为[ x , y , w , h , e n d ] [ x , y , w , h , end][x,y,w,h,end]。(NLP里的)
编码器
- 去掉了分类用的cls token。
- 在最后一层附加一个线性投影来对齐编码器和解码器的特征维度。
self.bottleneck = nn.Linear(encoder.num_channels, hidden_dim) - 只有搜索图像的特征被送入解码器。
def forward_features(self, images_list):
num_template = self.num_template
template_list = images_list[0:num_template]
search_list = images_list[num_template:]
num_search = len(search_list)
z_list = []
for i in range(num_template):
z = template_list[i]
z = self.patch_embed(z)
z = z + self.pos_embed[:, self.num_patches_search:, :]
z_list.append(z)
z_feat = torch.cat(z_list, dim=1)
x_list = []
for i in range(num_search):
x = search_list[i]
x = self.patch_embed(x)
x = x + self.pos_embed[:, :self.num_patches_search, :]
x_list.append(x)
x_feat = torch.cat(x_list, dim=1)
xz_feat = torch.cat([x_feat, z_feat], dim=1)
xz = self.pos_drop(xz_feat)
for blk in self.blocks: #batch is the first dimension.
if self.use_checkpoint:
xz = checkpoint.checkpoint(blk, xz)
else:
xz = blk(xz)
xz = self.norm(xz) # B,N,C
return xz解码器
- 接收来自前一个block的词嵌入并利用一个因果关系掩码保证每个序列元素的输出只依赖于其前面的序列元素。
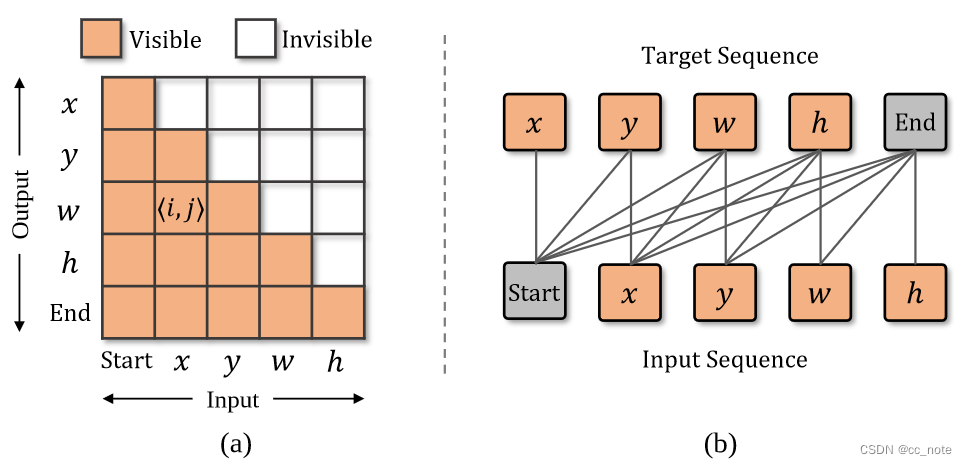
生成因果掩码代码如下:
def generate_square_subsequent_mask(sz):
r"""Generate a square mask for the sequence. The masked positions are filled with float('-inf').
Unmasked positions are filled with float(0.0).
"""
#each token only can see tokens before them
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float(
'-inf')).masked_fill(mask == 1, float(0.0))
return mask
训练和推理
训练
损失函数:通过交叉熵损失最大化target tokens在前一个子序列和输入视频帧上的对数似然。
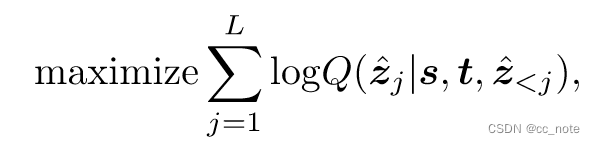
推理
引入在线模板更新和窗口惩罚,在推理过程中融合先验知识,进一步提高了模型精度和鲁棒性,使用generated tokens的似然来自动选择可靠的动态模板。引入了一种新的窗口惩罚策略,当前搜索区域中心点的离散坐标为[ n_bins / 2 , n_bins / 2],即为上一帧目标中心点位置。在生成x和y时,我们根据整数(即词)与nbins / 2的差来惩罚V中整数(即词)的可能性。差值越大惩罚越大。
实验
创建seqtrack虚拟环境并且激活
conda create -n seqtrack python=3.8
conda activate seqtrack所需要的安装包如下所示
echo "****************** Installing pytorch ******************"
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
#conda install -y pytorch=1.11 torchvision torchaudio cudatoolkit=11.3 -c pytorch
echo ""
echo ""
echo "****************** Installing yaml ******************"
pip install PyYAML
echo ""
echo ""
echo "****************** Installing easydict ******************"
pip install easydict
echo ""
echo ""
echo "****************** Installing cython ******************"
pip install cython
echo ""
echo ""
echo "****************** Installing opencv-python ******************"
pip install opencv-python
echo ""
echo ""
echo "****************** Installing pandas ******************"
pip install pandas
echo ""
echo ""
echo "****************** Installing tqdm ******************"
conda install -y tqdm
echo ""
echo ""
echo "****************** Installing coco toolkit ******************"
pip install pycocotools
echo ""
echo ""
echo "****************** Installing jpeg4py python wrapper ******************"
pip install jpeg4py
echo ""
echo ""
echo "****************** Installing tensorboard ******************"
pip install tb-nightly
echo ""
echo ""
echo "****************** Installing tikzplotlib ******************"
pip install tikzplotlib
echo ""
echo ""
echo "****************** Installing thop tool for FLOPs and Params computing ******************"
pip install --upgrade git+https://github.com/Lyken17/pytorch-OpCounter.git
echo ""
echo ""
echo "****************** Installing colorama ******************"
pip install colorama
echo ""
echo ""
echo "****************** Installing lmdb ******************"
pip install lmdb
echo ""
echo ""
echo "****************** Installing scipy ******************"
pip install scipy
echo ""
echo ""
echo "****************** Installing visdom ******************"
pip install visdom
echo ""
echo ""
echo "****************** Installing vot-toolkit python ******************"
pip install git+https://github.com/votchallenge/vot-toolkit-python
echo ""
echo ""
echo "****************** Installing timm ******************"
pip install timm==0.5.4
echo ""
echo ""
echo "****************** Installing yacs ******************"
pip install yacs
echo ""
echo ""
echo "****************** Installation complete! ******************"
运行以下命令安装
bash install.sh将项目路径添加到环境变量
export PYTHONPATH=<absolute_path_of_SeqTrack>:$PYTHONPATH跟踪数据格式如下所示
${SeqTrack_ROOT}
-- data
-- lasot
|-- airplane
|-- basketball
|-- bear
...
-- got10k
|-- test
|-- train
|-- val
-- coco
|-- annotations
|-- images
-- trackingnet
|-- TRAIN_0
|-- TRAIN_1
...
|-- TRAIN_11
|-- TEST运行以下命令来设置此项目的路径
python tracking/create_default_local_file.py --workspace_dir . --data_dir ./data --save_dir .训练SeqTrack
python -m torch.distributed.launch --nproc_per_node 8 lib/train/run_training.py --script seqtrack --config seqtrack_b256 --save_dir .根据基准进行测试和评估这个部分还未全部完成,后续会持续跟进
code
SeqTrack:(SeqTrack-L256为例)
class SEQTRACK(nn.Module):
""" This is the base class for SeqTrack """
def __init__(self, encoder, decoder, hidden_dim,
bins=1000, feature_type='x', num_frames=1, num_template=1):
""" Initializes the model.
Parameters:
encoder: torch module of the encoder to be used. See encoder.py
decoder: torch module of the decoder architecture. See decoder.py
"""
super().__init__()
self.encoder = encoder
self.num_patch_x = self.encoder.body.num_patches_search
self.num_patch_z = self.encoder.body.num_patches_template
self.side_fx = int(math.sqrt(self.num_patch_x))
self.side_fz = int(math.sqrt(self.num_patch_z))
self.hidden_dim = hidden_dim
self.bottleneck = nn.Linear(encoder.num_channels, hidden_dim) # the bottleneck layer, which aligns the dimmension of encoder and decoder
self.decoder = decoder
self.vocab_embed = MLP(hidden_dim, hidden_dim, bins+2, 3)
self.num_frames = num_frames
self.num_template = num_template
self.feature_type = feature_type
# Different type of visual features for decoder.
# Since we only use one search image for now, the 'x' is same with 'x_last' here.
if self.feature_type == 'x':
num_patches = self.num_patch_x * self.num_frames
elif self.feature_type == 'xz':
num_patches = self.num_patch_x * self.num_frames + self.num_patch_z * self.num_template
elif self.feature_type == 'token':
num_patches = 1
else:
raise ValueError('illegal feature type')
# position embeding for the decocder
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, hidden_dim))
pos_embed = get_sinusoid_encoding_table(num_patches, self.pos_embed.shape[-1], cls_token=False)
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))encoder:(ViT)
@register_model
def vit_large_patch16(pretrained=False, pretrain_type='default',
search_size=384, template_size=192, **kwargs):
patch_size = 16
model = VisionTransformer(
search_size=search_size, template_size=template_size,
patch_size=patch_size, num_classes=0,
embed_dim=1024, depth=24, num_heads=16, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
cfg_type = 'vit_large_patch16_224_' + pretrain_type
if pretrain_type == 'scratch':
pretrained = False
return model
model.default_cfg = default_cfgs[cfg_type]
if pretrained:
load_pretrained(model, pretrain_type, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3))
return modeldecoder:(DETR)
class SeqTrackDecoder(nn.Module):
def __init__(self, d_model=512, nhead=8,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False, bins=1000, num_frames=9):
super().__init__()
self.bins = bins
self.num_frames = num_frames
self.num_coordinates = 4 # [x,y,w,h]
max_position_embeddings = (self.num_coordinates+1) * num_frames
self.embedding = DecoderEmbeddings(bins+2, d_model, max_position_embeddings, dropout)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.body = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead