- 说明
- 优点
- 图像表示流程
- 代码实现如下
- 全部代码
说明
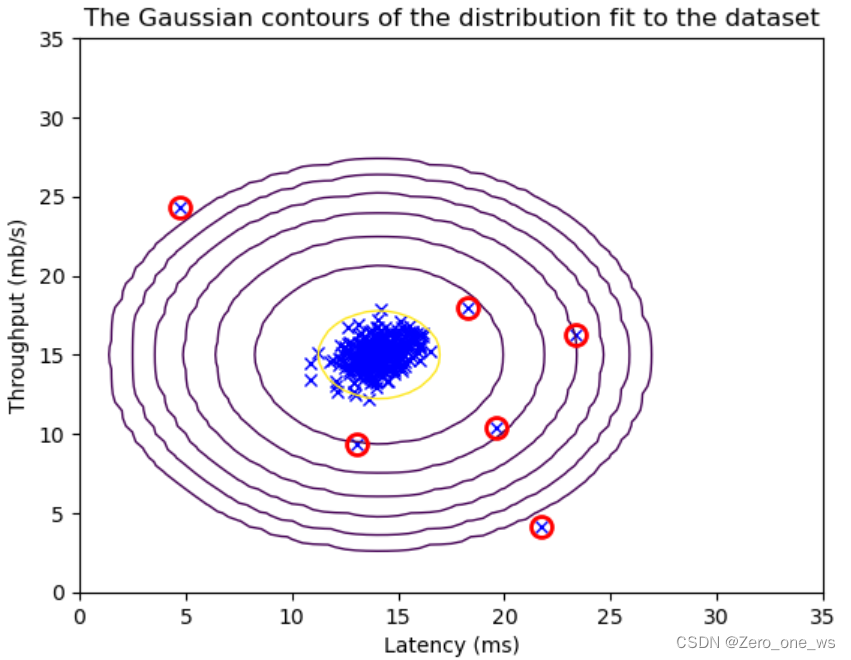
使用极其庞大的词表在模型压缩和图像token化方面带来了显著优势。由于词表巨大,我们不得不利用向量数据库对词表进行搜索,以找到最匹配的token。预测出的token会再次通过嵌入矩阵(em)转换为向量形式,然后从大规模的向量化词表中检索出来。
根据计算,使用16位来表示large_token_id,可以表达每三个像素、三个通道作为一个token的图像。生成的尺寸大小取决于序列的长度。而嵌入矩阵(em)的维度为(1000,h),即40位可以表示每九个三通道像素作为一个token。如果我们的图像数据能够覆盖所有可能性,那么词表将变得极其庞大,以至于即使是阿里云这样的存储巨头也无法容纳,甚至可能超过整个地球上所有存储设备之和。
然而,实际上,随着序列长度的增加,可能性会逐渐减少。因此,16位也有可能覆盖所有信息,将其转换为token。而且,由于推理序列通常不会太长,这种方法在处理实际问题时仍然具有可行性。
总的来说,使用超级大的词表在模型压缩和图像token化方面具有显著优势。通过向量数据库对词表进行搜索,以及将预测出的token再次通过嵌入矩阵转换为向量形式,可以有效地处理大规模的图像数据。尽管词表可能非常庞大,但随着序列长度的增加,可能性逐渐减少,使得这种方法在实际应用中仍然具有可行性。
优点
可以在推理的时候由于em小所以模型很小,推理只需要强大的cpu,和足够的内存磁盘
图像表示流程

代码实现如下
import paddle
import faiss
from new_model_13 import GPT as GPT13
import pandas as pd
from sklearn.preprocessing import normalize
import json
import math
from collections import Counter
from tqdm import tqdm
import numpy as np
def gen_small_voc():
num = "0123456789" + 'qwertyuiopasdfghjklzxcvbnm' + "QWERTYUIOPASDFGHJKLZXCVBNM"
num = list(num)
small_em_voc = dict()
voc_id = 0
for i in range(16):
for n in num:
small_em_voc[voc_id] = "{}_{}".format(i, n)
voc_id += 1
return small_em_voc
def random_gen_voc():
num = "0123456789" + 'qwertyuiopasdfghjklzxcvbnm' + "QWERTYUIOPASDFGHJKLZXCVBNM"
num = list(num)
p_list = ["{}_{}".format(i, np.random.choice(num)) for i in range(16)]
return "#".join(p_list)
def gen_text_voc_to_token_id(text, large_em_voc, small_voc_em):
text = list(text)
text_list = []
for ii in text:
one = large_em_voc.get(ii, None)
if one is None:
while True:
two = random_gen_voc()
if large_em_voc.get(two, None) is None:
large_em_voc[two] = ii
large_em_voc[ii] = two
two = [small_voc_em.get(i) for i in two.split("#")]
text_list.append(two)
break
else:
two = [small_voc_em.get(i) for i in one.split("#")]
text_list.append(two)
return text_list, large_em_voc
def train():
with open("唐诗.json", "r", encoding="utf-8") as f:
data = f.read()
data = json.loads(data)
data = [i[4].split() for i in data if len(i[4].split()) > 3]
data = np.hstack(data)
data = [i for i in data if len("".join(i.split())) == 24 and "a" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "f" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "e" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "h" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "X" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "“" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and '□' not in i]
data = [i for i in data if len("".join(i.split())) == 24 and '《' not in i]
data = [i for i in data if len("".join(i.split())) == 24 and '》' not in i]
small_em_voc = gen_small_voc()
small_voc_em = {k: v for v, k in small_em_voc.items()}
large_em_voc = dict()
model = GPT13(len(small_em_voc), 512, 32, 8)
# model.load_dict(paddle.load("gpt.pdparams"))
print("参数量:",
sum([i.shape[0] * i.shape[-1] if len(i.shape) > 1 else i.shape[-1] for i in model.parameters()]) / 1000000000,
"B")
loss_func = paddle.nn.CrossEntropyLoss()
opt = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.0003)
for epoch in range(190):
bar = tqdm(range(0, len(data), 1000))
for i in bar:
j = i + 1000
large_data = []
for one in data[i:j]:
two, large_em_voc = gen_text_voc_to_token_id(one, large_em_voc, small_voc_em)
large_data.append(two)
out, _ = model(paddle.to_tensor(large_data)[:, :-1])
loss = loss_func(out, paddle.to_tensor(large_data)[:, 1:].reshape([out.shape[0], -1]))
bar.set_description("epoch___{}__loss__{}".format(epoch, loss.item()))
opt.clear_grad()
loss.backward()
opt.step()
paddle.save(model.state_dict(), "duo_yang_xing.pkl")
pd.to_pickle(large_em_voc, "large_em_voc.pkl")
pd.to_pickle(small_em_voc, "small_em_voc.pkl")
def val():
with open("唐诗.json", "r", encoding="utf-8") as f:
data = f.read()
data = json.loads(data)
data = [i[4].split() for i in data if len(i[4].split()) > 3]
data = np.hstack(data)
data = [i for i in data if len("".join(i.split())) == 24 and "a" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "f" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "e" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "h" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "X" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and "“" not in i]
data = [i for i in data if len("".join(i.split())) == 24 and '□' not in i]
data = [i for i in data if len("".join(i.split())) == 24 and '《' not in i]
data = [i for i in data if len("".join(i.split())) == 24 and '》' not in i]
small_em_voc = pd.read_pickle("small_em_voc.pkl")
small_voc_em = {k: v for v, k in small_em_voc.items()}
large_em_voc = pd.read_pickle("large_em_voc.pkl")
model = GPT13(len(small_em_voc), 512, 32, 8)
model.load_dict(paddle.load("duo_yang_xing.pkl"))
model.eval()
print("参数量:",
sum([i.shape[0] * i.shape[-1] if len(i.shape) > 1 else i.shape[-1] for i in model.parameters()]) / 1000000000,
"B")
k_list = []
faiss_index = faiss.IndexFlatIP(8192)
for k, v in large_em_voc.items():
if len(k) <= 1:
# one = paddle.max(
# model.embedding(paddle.to_tensor([small_voc_em.get(i) for i in v.split("#")]).reshape([1, -1])), 1)
one = model.embedding(paddle.to_tensor([small_voc_em.get(i) for i in v.split("#")]).reshape([1, -1]))
one = one.reshape([1, -1])
one /= np.linalg.norm(one, axis=-1, keepdims=True)
faiss_index.add(one)
k_list.append(k)
word = data[0][:10]
for _ in range(17):
two, large_em_voc = gen_text_voc_to_token_id(word, large_em_voc, small_voc_em)
out, _ = model(paddle.to_tensor(two).unsqueeze(0))
out = paddle.argmax(out, -1)[:, -16:]
out_num = [small_em_voc.get(i.item()) for i in out[0]]
out_voc = large_em_voc.get("#".join(out_num))
if out_voc is None:
# out_em = paddle.max(model.embedding(out), 1)
out_em = model.embedding(out)
out_em = out_em.reshape([1,-1])
out_em /= np.linalg.norm(out_em, axis=-1, keepdims=True)
di,ii=faiss_index.search(out_em,k=10)
word += k_list[ii[0][0]]
else:
word += out_voc
print(word)
if __name__ == '__main__':
train()
val()
全部代码
超级