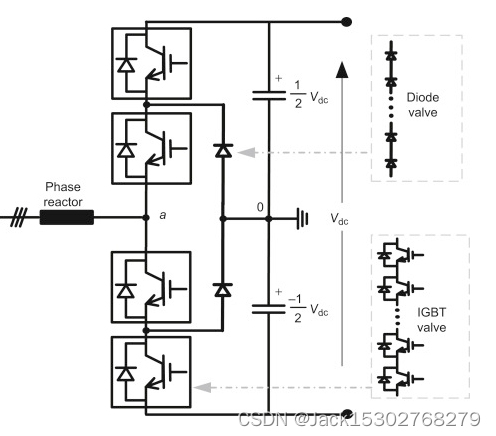
作者:Rishikesh Radhakrishnan

使用开源的 Llama 3 和 Elastic 构建 RAG
Llama 3 是 Meta 最近推出的开源大型语言模型。这是 Llama 2 的后继者,根据已发布的指标,这是一个重大改进。与 Gemma 7B Instruct、Mistral 7B Instruct 等最近发布的一些模型相比,它具有良好的评估指标。该模型有两个变体,分别是 80 亿和 700 亿参数。值得注意的是,在撰写这篇博客时,Meta 仍在训练 400B+ 版本的 Llama 3。
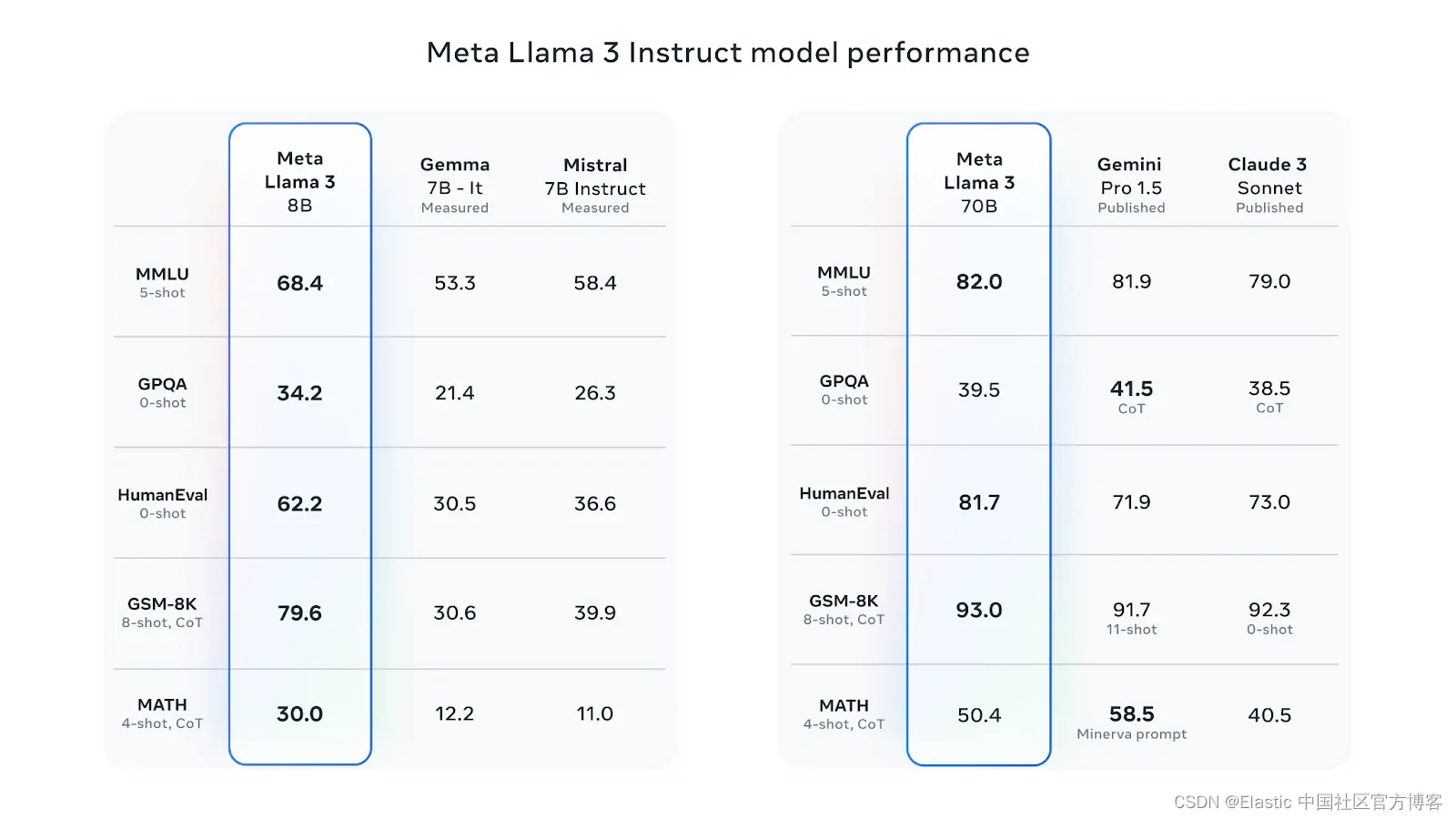
Meta Llama 3 Instruct 模型性能。(来自 https://ai.meta.com/blog/meta-llama-3/)
上图显示了与其他模型相比,Llama3 在不同数据集上的性能数据。为了针对现实世界场景进行性能优化,Llama3 还在高质量的人工评估集上进行了评估。

跨多个类别和提示的人工评估的汇总结果(来自 https://ai.meta.com/blog/meta-llama-3/)
本博客将介绍使用两种方法实现的 RAG。
- Elastic、Llamaindex、Llama 3 (8B) 版本使用 Ollama 在本地运行。
- Elastic、Langchain、ELSER v2、Llama 3 (8B) 版本使用 Ollama 在本地运行。
Notebook 可在此 GitHub 位置获取。
数据集
对于数据集,我们将使用 json 格式的虚构组织政策文档,可在此处获取。
配置 Ollama 和 Llama3
由于我们使用 Llama 3 8B 参数大小模型,我们将使用 Ollama 运行该模型。按照以下步骤安装 Ollama。
- 浏览到 URL https://ollama.com/download 以根据你的平台下载 Ollama 安装程序。
注意:Windows 版本目前处于预览阶段。
- 按照说明为你的操作系统安装和运行 Ollama。
- 安装后,按照以下命令下载 Llama3 模型。
ollama run llama3这可能需要一些时间,具体取决于你的网络带宽。运行完成后,你将看到以下界面。

要测试 Llama3,请从新终端运行以下命令或在提示符下输入文本。
curl -X POST http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt":"Why is the sky blue?" }'
在提示符下,输出如下所示。
❯ ollama run llama3
>>> Why is the sky blue?
The color of the sky appears blue to our eyes because of a fascinating combination of scientific factors. Here's the short answer:
**Scattering of Light**: When sunlight enters Earth's atmosphere, it encounters tiny molecules of gases like nitrogen (N2) and oxygen (O2).
These molecules scatter the light in all directions, but they do so more efficiently for shorter wavelengths (like blue and violet light) than
longer wavelengths (like red and orange light).
**Rayleigh Scattering**: This scattering effect is known as Rayleigh scattering, named after the British physicist Lord Rayleigh, who first
described it in the late 19th century. It's responsible for the blue color we see in the sky.
**Atmospheric Composition**: The Earth's atmosphere is composed of approximately 78% nitrogen, 21% oxygen, and small amounts of other gases.
These gases are more abundant at lower altitudes, where they scatter shorter wavelengths (like blue light) more effectively than longer
wavelengths (like red light).
**Sunlight's Wavelengths**: When sunlight enters the Earth's atmosphere, it contains a broad spectrum of wavelengths, including visible light
with colors like red, orange, yellow, green, blue, indigo, and violet. The shorter wavelengths (blue and violet) are scattered more than the
longer wavelengths (red and orange), due to Rayleigh scattering.
**What We See**: As our eyes look up at the sky, we see the combined effect of these factors: the shorter wavelengths (blue light) being
scattered in all directions by the atmospheric gases, while the longer wavelengths (red and orange light) continue to travel in a more direct
path to our eyes. This results in the blue color we perceive as the sky.
So, to summarize: the sky appears blue because of the scattering of sunlight's shorter wavelengths (blue light) by the tiny molecules in the
Earth's atmosphere, combined with the atmospheric composition and the original wavelengths present in sunlight.
Now, go enjoy that blue sky!
>>> Send a message (/? for help)
我们现在使用 Ollama 在本地运行 Llama3。
Elasticsearch 设置
我们将为此使用 Elastic 云设置。请按照此处的说明进行操作。成功部署后,请记下 API 密钥和云 ID,我们将需要它们作为设置的一部分。
应用程序设置
有两个 notebooks,一个用于使用 Llamaindex 和 Llama3 实现的 RAG,另一个用于 Langchain、ELSER v2 和 Llama3。在第一个 notebook 中,我们使用 Llama3 作为本地 LLM 并提供嵌入。对于第二个 notebook,我们使用 ELSER v2 作为嵌入,使用 Llama3 作为本地 LLM。
方法 1:使用 Ollama 在本地运行 Elastic、Llamaindex、Llama 3 (8B) 版本。
步骤 1:安装所需的依赖项。
!pip install llama-index
!pip install llama-index-cli
!pip install llama-index-core
!pip install llama-index-embeddings-elasticsearch
!pip install llama-index-embeddings-ollama
!pip install llama-index-legacy
!pip install llama-index-llms-ollama
!pip install llama-index-readers-elasticsearch
!pip install llama-index-readers-file
!pip install llama-index-vector-stores-elasticsearch
!pip install llamaindex-py-client
以上部分安装了所需的 llamaindex 包。
第 2 步:导入所需的依赖项
我们首先导入应用程序所需的包和类。
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from llama_index.core import VectorStoreIndex, QueryBundle
from llama_index.llms.ollama import Ollama
from llama_index.core import Document, Settings
from getpass import getpass
from urllib.request import urlopen
import json
我们首先向用户提供提示,以捕获云 ID 和 API 密钥值。
#https://www.elastic.co/search-labs/tutorials/install-elasticsearch/elastic-cloud#finding-your-cloud-id
ELASTIC_CLOUD_ID = getpass("Elastic Cloud ID: ")
#https://www.elastic.co/search-labs/tutorials/install-elasticsearch/elastic-cloud#creating-an-api-key
ELASTIC_API_KEY = getpass("Elastic Api Key: ")
如果你不熟悉如何获取云 ID 和 API 密钥,请按照上面代码片段中的链接来指导你完成该过程。
步骤 3:文档处理
我们首先下载 json 文档,然后使用有效负载构建 Document 对象。
url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json"
response = urlopen(url)
workplace_docs = json.loads(response.read())
documents = [Document(text=doc['content'],
metadata={"name": doc['name'],"summary": doc['summary'],"rolePermissions": doc['rolePermissions']})
for doc in workplace_docs]
我们现在定义 Elasticsearch 向量存储 (ElasticsearchStore)、使用 Llama3 创建的嵌入和 pipeline,以帮助处理上面构建的有效负载并提取到 Elasticsearch 中。
提取管道允许我们使用不同的组件组成管道,其中一个组件允许我们使用 Llama3 生成嵌入。
es_vector_store = ElasticsearchStore(index_name="workplace_index",
vector_field='content_vector',
text_field='content',
es_cloud_id=ELASTIC_CLOUD_ID,
es_api_key=ELASTIC_API_KEY)
# Embedding Model to do local embedding using Ollama.
ollama_embedding = OllamaEmbedding("llama3")
# LlamaIndex Pipeline configured to take care of chunking, embedding
# and storing the embeddings in the vector store.
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=512, chunk_overlap=100),
ollama_embedding
], vector_store=es_vector_store
)
ElasticsearchStore 定义了要创建的索引的名称、向量字段和内容字段。并且这个索引是在运行管道时创建的。
创建的索引映射如下:

管道使用以下步骤执行。管道运行完成后,索引 workplace_index 现在可供查询。请注意,向量字段 content_vector 被创建为维度为 4096 的密集向量。维度大小来自从 Llama3 生成的嵌入的大小。
pipeline.run(show_progress=True,documents=documents)
步骤 4:LLM 配置
我们现在设置 Llamaindex 以使用 Llama3 作为 LLM。正如我们之前介绍的那样,这是在 Ollama 的帮助下完成的。
Settings.embed_model = ollama_embedding
local_llm = Ollama(model="llama3")
第 5 步:语义搜索
我们现在将 Elasticsearch 配置为 Llamaindex 查询引擎的向量存储。然后,查询引擎将使用来自 Elasticsearch 的上下文相关数据来回答你的问题。
index = VectorStoreIndex.from_vector_store(es_vector_store)
query_engine = index.as_query_engine(local_llm, similarity_top_k=10)
# Customer Query
query = "What are the organizations sales goals?"
bundle = QueryBundle(query_str=query,
embedding=Settings.embed_model.get_query_embedding(query=query))
response = query_engine.query(bundle)
print(response.response)
以下是我以 Llama3 作为 LLM 并以 Elasticsearch 作为向量数据库收到的回复。
According to the "Fy2024 Company Sales Strategy" document, the organization's primary goal is to:
* Increase revenue by 20% compared to fiscal year 2023.
* Expand market share in key segments by 15%.
* Retain 95% of existing customers and increase customer satisfaction ratings.
* Launch at least two new products or services in high-demand market segments.
至此,基于使用 Llama3 作为本地 LLM 并生成嵌入的 RAG 设置就结束了。
现在让我们转到第二种方法,该方法使用 Llama3 作为本地 LLM,但我们使用 Elastic 的 ELSER v2 来生成嵌入并进行语义搜索。
方法 2:使用 Ollama 在本地运行 Elastic、Langchain、ELSER v2、Llama 3 (8B) 版本。
步骤 1:安装所需的依赖项。
!pip install langchain
!pip install langchain-elasticsearch
!pip install langchain-community
!pip install tiktoken
以上部分安装了所需的 langchain 包。
第 2 步:导入所需的依赖项
我们首先导入应用程序所需的包和类。此步骤与上述方法 1 中的第 2 步类似。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_elasticsearch import ElasticsearchStore
from langchain_community.llms import Ollama
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain_elasticsearch import ElasticsearchStore
from langchain_elasticsearch import SparseVectorStrategy
from getpass import getpass
from urllib.request import urlopen
import json
接下来,向用户提供提示以捕获云 ID 和 API 密钥值。
#https://www.elastic.co/search-labs/tutorials/install-elasticsearch/elastic-cloud#finding-your-cloud-id
ELASTIC_CLOUD_ID = getpass("Elastic Cloud ID: ")
#https://www.elastic.co/search-labs/tutorials/install-elasticsearch/elastic-cloud#creating-an-api-key
ELASTIC_API_KEY = getpass("Elastic Api Key: ")
步骤 3:文档处理
接下来,我们下载 json 文档并构建有效负载。
url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json"
response = urlopen(url)
workplace_docs = json.loads(response.read())
metadata = []
content = []
for doc in workplace_docs:
content.append(doc["content"])
metadata.append(
{
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions": doc["rolePermissions"],
}
)
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=256
)
docs = text_splitter.create_documents(content, metadatas=metadata)
此步骤与方法 1 不同,因为我们使用 LlamaIndex 提供的管道来处理文档。这里我们使用 RecursiveCharacterTextSplitter 来生成块。
我们现在定义 Elasticsearch 向量存储 ElasticsearchStore。
es_vector_store = ElasticsearchStore(
es_cloud_id=ELASTIC_CLOUD_ID,
es_api_key=ELASTIC_API_KEY,
index_name="workplace_index_elser",
strategy=SparseVectorStrategy(
model_id=".elser_model_2_linux-x86_64"
)
)
向量存储定义了要创建的索引以及用于嵌入和检索的模型。你可以通过导航到机器学习下的训练模型来检索 model_id。
这还会导致在 Elastic 中创建一个摄取管道,该管道在将文档摄取到 Elastic 时生成并存储嵌入。
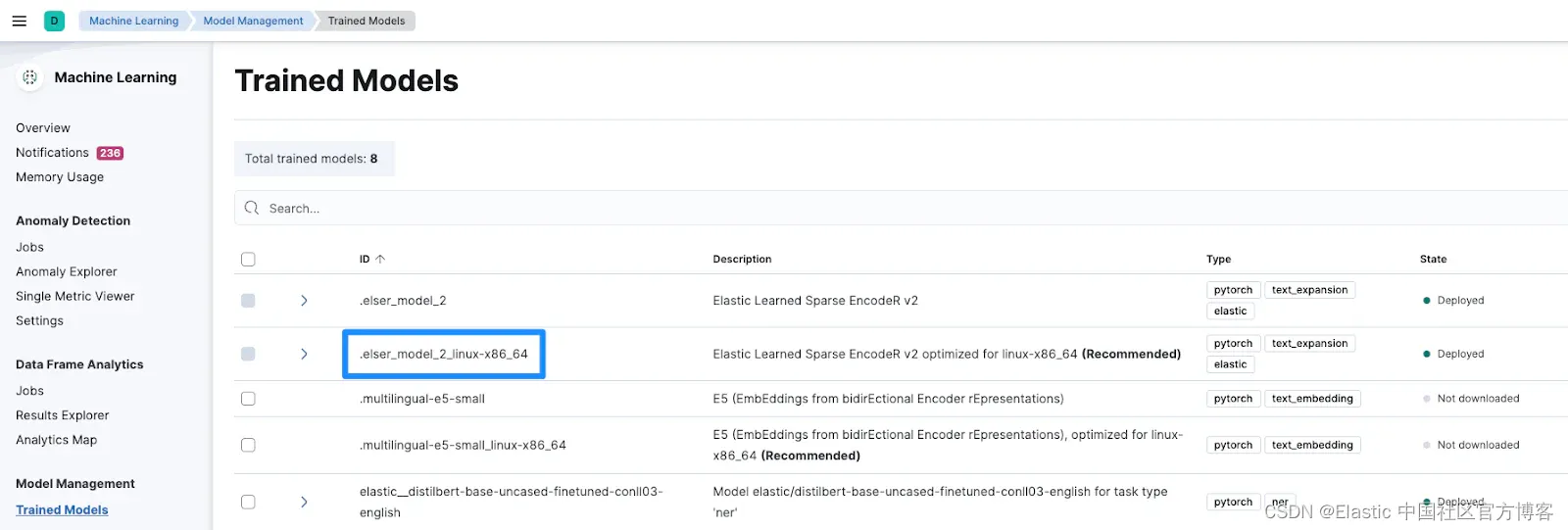
我们现在添加上面处理过的文档。
es_vector_store.add_documents(documents=docs)
步骤 4:LLM 配置
我们设置要使用的 LLM,如下所示。这又不同于方法 1,在方法 1 中我们也使用 Llama3 进行嵌入。
llm = Ollama(model="llama3")
第 5 步:语义搜索
现在,所有必要的构建块都已准备就绪。我们将它们组合在一起,使用 ELSER v2 和 Llama3 作为 LLM 执行语义搜索。本质上,Elasticsearch ELSER v2 使用其语义搜索功能为用户问题提供上下文相关的响应。然后,用户的问题将通过 ELSER 的响应得到丰富,并使用模板进行结构化。然后,使用 Llama3 对其进行处理以生成相关响应。
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
retriever = es_vector_store.as_retriever()
template = """Answer the question based only on the following context:\n
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
chain.invoke("What are the organizations sales goals?")
使用 Llama3 作为 LLM 并使用 ELSER v2 进行语义搜索的响应如下:
According to the provided context, the organization's sales goals for Fiscal Year 2024 are:
1. Increase revenue by 20% compared to fiscal year 2023.
2. Expand market share in key segments by 15%.
3. Retain 95% of existing customers and increase customer satisfaction ratings.
These goals are outlined under "Objectives for Fiscal Year 2024" in the provided document.
这结束了基于使用 Llama3 作为本地 LLM 和使用 ELSER v2 进行语义搜索的 RAG 设置。
结论
在这篇博客中,我们研究了使用 Llama3 和 Elastic 实现 RAG 的两种方法。我们探索了 Llama3 作为 LLM 并生成嵌入。接下来,我们使用 Llama3 作为本地 LLM,并使用 ELSER 进行嵌入和语义搜索。我们使用了两个不同的框架,LlamaIndex 和 Langchain。你可以使用其中任何一个框架实现这两种方法。Notebook 使用 Llama3 8B 参数版本进行了测试。这两个 notebooks 都可以在这个 GitHub 位置找到。
准备好自己尝试一下了吗?开始免费试用。
Elasticsearch 集成了 LangChain、Cohere 等工具。加入我们的高级语义搜索网络研讨会,构建你的下一个 GenAI 应用程序!
原文:Elasticsearch RAG: How to build RAG with Llama 3 open-source and Elastic — Elastic Search Labs