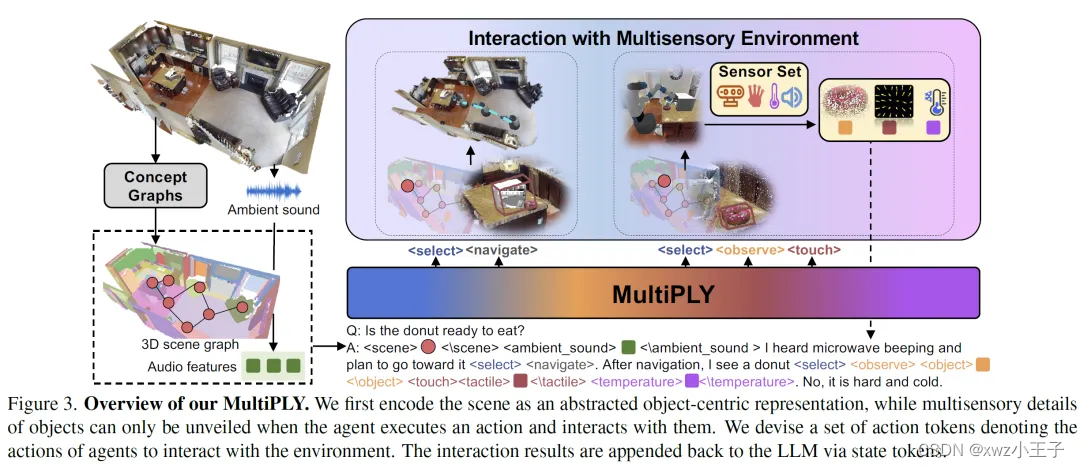
前言
🔥 优质竞赛项目系列,今天要分享的是
酒店评价的情感倾向分析
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
概述
本文基于7K条携程酒店评价数据为文本数据,将其导入到Keras的模型架构然后进行训练出一个可用于实际场所预测情感的模型。
项目所需模块
import tensorflow as tf
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
import tensorflow.keras as keras
# 导入jieba分词库
import jieba
import re
数据
数据说明
7000多条携程酒店评论数据,5000多条正向评论,2000多条负向评论。
字段说明
- 评论数目(总体):7766
- 评论数目(正向):5322
- 评论数目(负向):2444

数据处理
# 读取数据
data = pd.read_csv("/home/kesci/input/labelreview5456/ChnSentiCorp_htl_all.csv")
# 查看数据的前5项
data.head()

分词处理
# 去除标点符号和数字
# 要去除标点符号和数字,常用的办法就是使用正则表达式来处理,或者自行编写遍历替换函数
# 模式串
patten = r"[!\"#$%&'()*+,-./:;<=>?@[\\\]^_`{|}~—!,。?·¥、《》···【】:" "''\s0-9]+"
re_obj = re.compile(patten)
# 替换函数--去除标点符号和数字
def clear(text):
return re_obj.sub('', text)
# 将正则表达式替换函数应用于每一行
data["review"] = data["review"].apply(clear)
# 查看前5行替换结果
data["review"][:5]

采用精简处理,启用HMM(隐式马尔科夫网络)处理
def cut_words(words):
return jieba.lcut(words) # 使用lcut分词
#apply函数对series的每一行数据进行处理
data["review"] = data["review"].apply(cut_words)
data["review"][:5]

停用词处理
# 使用 中文停用词表
stop_words = "/home/kesci/work/stopwords-master/stopwords.txt"
stop_list = [
i.strip() for i in open(stop_words, encoding='utf-8').readlines()
] #读取停用词列表
def remove_stop(words): #移除停用词函数
texts = []
for word in words: # 遍历词列表里的每一个词
if word not in stop_list: # 若不在停用词列表中就将结果追加至texts列表中
texts.append(word)
return texts
data['review'] = data['review'].apply(remove_stop)
# 查看前5行
data["review"][:5]

样本均衡
data["label"].value_counts().plot(kind = 'bar')
plt.text(0, 6000, str(data["label"].value_counts()[1]),
ha = 'center', va = 'top')
plt.text(1, 3000, str(data["label"].value_counts()[0]),
ha = 'center', va = 'top')
plt.ylim(0, 6500)
plt.title('正负样本的个数')
plt.show()

从柱状图可以看出,该数据集共7766条数据,其中正样本(label = 1)共有5322条,负样本(label = 0)共有2444条,没有重复数据
显然样本存在严重的不均衡问题,这里考虑两种样本均衡的策略
(1)欠采样,正负样本各2000条,一共4000条
(2)过采样,正负样本各3000条,一共6000条
为减少计算量和对比两种均衡策略的效果,这里采用先把整体数据进行处理,再做样本均衡采样
def get_balanced_words(size,
positive_comment=data[data['label'] == 1],
negtive_comment=data[data['label'] == 0]):
word_size = size // 2
#获取正负评论数
num_pos = positive_comment.shape[0]
num_neg = negtive_comment.shape[0]
# 当 正(负)品论数中<采样数量/2 时,进行上采样,否则都是下采样;
# 其中pandas的sample方法里的repalce参数代表是否进行上采样,默认不进行
balanced_words = pd.concat([
positive_comment.sample(word_size,
replace=num_pos < word_size,
random_state=0),
negtive_comment.sample(word_size,
replace=num_neg < word_size,
random_state=0)
])
# 打印样本个数
print('样本总数:', balanced_words.shape[0])
print('正样本数:', balanced_words[data['label'] == 1].shape[0])
print('负样本数:', balanced_words[data['label'] == 0].shape[0])
print('')
return balanced_words
建立多层感知机分类模型

可以看到共有四层:平坦层共有1600个神经元,平坦层在这里可以看作为输入层。隐藏层共有256个神经;输出层只有1个神经元。全部必须训练的超参数有474113个,通常超参数数值越大,代表此模型越复杂,需要更多时间进行训练。
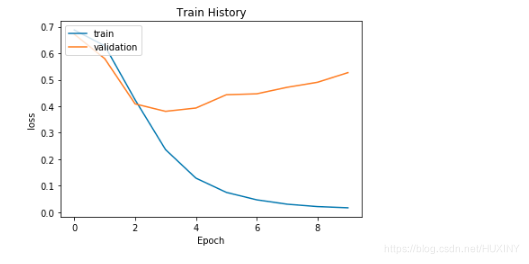
训练模型

网络检测率以及检测结果


input_text = """
去之前会有担心,因为疫情,专门打了电话给前台,前台小哥哥好评,耐心回答,打消了我的顾虑,nice!!
看得出有做好防疫情清洁消毒工作,前台登记反复询问,确保出行轨迹安全,体温测量登记,入住好评,选了主题房,设计是我喜欢的.
总之下次有需要还是会自住或推荐!!
"""
predict_review(input_text)
result : 正面评价!
至此,对携程酒店评价的情感倾向分析,以建立一个简单的多层感知器模型结束,由于文章所限,后续的模型优化以及与其他深度学习的模型的比较就不进行简述,有兴趣的同学可以留意学长后续文章。谢谢各位同学!
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate