第 5 章 Kafka 消费者
5.1 Kafka 消费方式

5.2 Kafka 消费者工作流程
5.2.1 消费者总体工作流程

一个消费者组中的多个消费者,可以看作一个整体,一个组内的多个消费者是不可能去消费同一个分区的数据的,要不然就消费重复了。5.2.2 消费者组原理
Consumer Group(CG):
消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
• 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
• 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者

消费者组初始化流程:

消费计划的制定:
生产者把数据发送给各个分区,每个broker节点都有一个coordinator(协调器),消费者组对分区进行消费,到底哪个消费者消费哪个分区呢?首先groupId对50取模,看最后的结果是哪个分区节点,假如是1分区,那么1分区的协调器就是本次消费者组的老大,消费者纷纷向该协调器进行注册,协调器从中随机选择一个消费者作为本次消费的Leader,然后把本次消费的具体情况发送给Leader,让其制定一个消费计划(就是哪个消费者消费哪个分区),然后Leader发送给协调器,协调器再进行群发,将计划公布,各个消费者按照这个计划进行消费。消费者组详细消费流程:

假如本次抓取的数量是500条,大小超过了50M,那以50M为主。
5.2.3 消费者重要参数


5.3 消费者 API
5.3.1 独立消费者案例(订阅主题)
1)需求:
创建一个独立消费者,消费 first 主题中数据。
注意:在消费者 API 代码中必须配置消费者组 id。命令行启动消费者不填写消费者组 id 会被自动填写随机的消费者组 id。

2)实现步骤
(1)创建包名:com.bigdata.kafka.consumer
(2)编写代码
package com.bigdata.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* 编写代码消费kafka中的数据
*/
public class Customer01 {
public static void main(String[] args) {
// 其实就是map
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 创建一个kafka消费者的对象
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 消费者消费的是kafka集群的数据,消费哪个主题的数据呢?
List<String> topics = new ArrayList<>();
topics.add("first");// list总可以设置多个主题的名称
kafkaConsumer.subscribe(topics);
// 因为消费者是不停的消费,所以是while true
while(true){
// 每隔一秒钟,从kafka 集群中拉取一次数据,有可能拉取多条数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
// 循环打印每一条数据
for (ConsumerRecord record:records) {
// 打印数据中的值
System.out.println(record.value());
// 打印一条数据
System.out.println(record);
}
}
}
}测试:
(1)在 IDEA 中执行消费者程序
(2)在 Kafka 集群控制台,创建 Kafka 生产者,并输入数据。
bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092 --topic first
>hello
(3)在IDEA控制台查看。
5.3.2 独立消费者案例(订阅分区)
1)需求:创建一个独立消费者,消费 first 主题 0 号分区的数据。

2)实现步骤
(1)代码编写
package com.bigdata.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* 编写代码消费kafka中的数据 消费者只消费某个固定分区的数据
*/
public class Customer02 {
public static void main(String[] args) {
// 其实就是map
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
// 字段反序列化 key 和 value
/**
* 如何将自力传输到天安门看升国旗
* 1、先将自己序列化 原子
* 2、管道(网线)
* 3、再进行反序列化 (自力的NDA) 活泼可爱的自力
* 结论是:只要是一个对象,它想保存或者想传输,必须序列化
* 传输过去之后,进行反序列化。
* 比如:java hadoop
*/
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "abc");
// 创建一个kafka消费者的对象
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 消费者消费的是kafka集群的数据,消费哪个主题的数据呢?
List<TopicPartition> partitions = new ArrayList<>();
partitions.add(new TopicPartition("first",0));
// 指定某个分区进行消费
kafkaConsumer.assign(partitions);
// 因为消费者是不停的消费,所以是while true
while(true){
// 每隔一秒钟,从kafka 集群中拉取一次数据,有可能拉取多条数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
// 循环打印每一条数据
for (ConsumerRecord record:records) {
// 打印数据中的值
System.out.println("目前消费的分区是"+record.partition()+",value的值为:"+record.value());
// 打印一条数据
System.out.println(record);
}
}
}
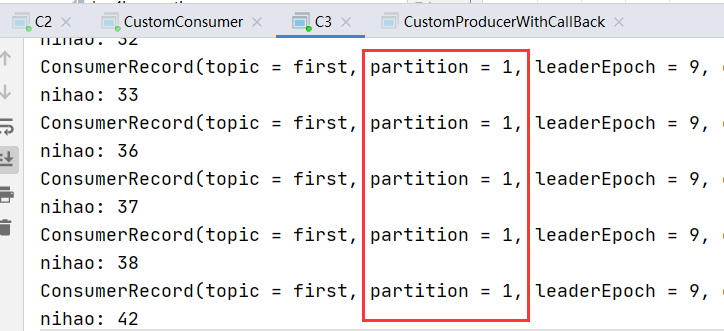
}5.3.3 消费者组案例
1)需求:测试同一个主题的分区数据,只能由一个消费者组中的消费者只能消费一个分区的数据,不能同时消费多个分区的数据。
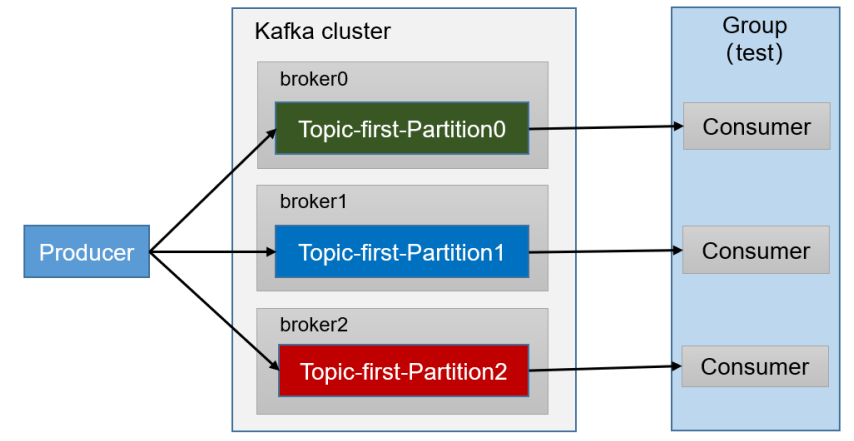
2)案例实操
(1)运行CustomConsumer ,通过idea,将这个类运行三次

或者使用如下设置:
2023版本:

老版本:

配置完成,点击后面的运行,就可以同一个类,运行三次了。运行三次就是三个消费者。
(2)启动代码中的生产者发送50条数据,在 IDEA 控制台即可看到两个消费者在消费不同 分区的数据(如果只发生到一个分区,可以在发送时增加延迟代码 Thread.sleep(2);)。


5.4 生产经验——分区的分配以及再平衡
这个章节主要讲:本次消费任务的计划是如何制定的?
1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据。
2、Kafka有四种主流的分区分配策略: Range、RoundRobin(轮询)、Sticky(粘性)、CooperativeSticky(配合的粘性)。
可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用多个分区分配策略。
| 参数名称 | 描述 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于session.timeout.ms,也不应该高于 session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超 过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该 消费者被移除,消费者组执行再平衡 |
| partition.assignment.strategy | 消 费 者 分 区 分 配 策 略 , 默 认 策 略 是 Range +CooperativeSticky。Kafka 可以同时使用多个分区分配策略。 可 以 选 择 的 策 略 包 括 : Range 、 RoundRobin 、 Sticky 、CooperativeSticky |
5.4.1 Range 以及再平衡
1)Range 分区策略原理

2)Range 分区分配策略案例
(1)修改主题 first 为 7 个分区。
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --alter --topic first --partitions 7
注意:分区数可以增加,但是不能减少。
(2)这样可以由三个消费者
CustomConsumer、CustomConsumer1、CustomConsumer2 组成消费者组,组名都为“test”, 同时启动 3 个消费者。
(3)启动 CustomProducer 生产者,发送 500 条消息,随机发送到不同的分区。
备注:只需要将以前的CustomProducerCallback,修改发送次数为500次即可。
package com.bigdata.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerCallback {
public static void main(String[] args) throws InterruptedException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"192.168.235.128:9092");
// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 3. 创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 500; i++) {
// 添加回调
kafkaProducer.send(new ProducerRecord<>("first",
"bigdata " + i), new Callback() {
// 该方法在 Producer 收到 ack 时调用,为异步调用
@Override
public void onCompletion(RecordMetadata metadata,
Exception exception) {
if (exception == null) {
// 没有异常,输出信息到控制台
System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition());
} else {
// 出现异常打印
exception.printStackTrace();
}
}
});
// 延迟一会会看到数据发往不同分区
Thread.sleep(20);
}
// 5. 关闭资源
kafkaProducer.close();
}
}说明:Kafka 默认的分区分配策略就是 Range + CooperativeSticky,所以不需要修改策略。
默认是Range,但是在经过一次升级之后,会自动变为CooperativeSticky。这个是官方给出的解释。
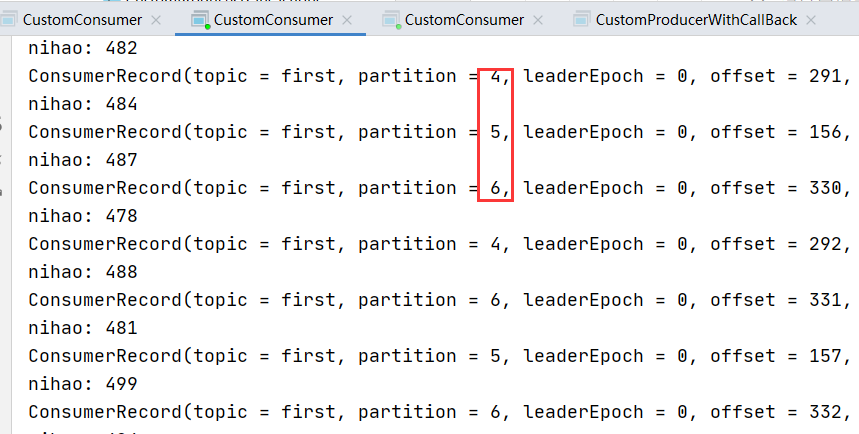
默认的分配器是[RangeAssignor, CooperativeStickyAssignor],默认情况下将使用RangeAssignor,但允许通过一次滚动反弹升级到CooperativeStickyAssignor,该滚动反弹会将RangeAssignor从列表中删除。(4)观看 3 个消费者分别消费哪些分区的数据。
假如消费情况和预想的不一样:
1、集群是否健康,比如某些kafka进程没启动
2、发送数据的时候7个分区没有使用完,因为它使用了粘性分区。如何让它发送给7个分区呢,代码中添加:
// 延迟一会会看到数据发往不同分区
Thread.sleep(20);发现一个消费者消费了,5,6分区,一个消费了0,1,2分区,一个消费了3,4分区。



此时并没有修改分区策略,原因是默认是Range.
3)Range 分区分配再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 3、4 号分区数据。
2 号消费者:消费到 5、6 号分区数据。
0号的数据,没人消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、1、2、3 号分区数据。
2 号消费者:消费到 4、5、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。

5.4.2 RoundRobin(轮询) 以及再平衡
1)RoundRobin 分区策略原理

2)RoundRobin 分区分配策略案例
(1)依次在 CustomConsumer、CustomConsumer1、CustomConsumer2 三个消费者代 码中修改分区分配策略为 RoundRobin。

轮询的类的全路径是:
org.apache.kafka.clients.consumer.RoundRobinAssignor
A list of class names or class types, ordered by preference, of supported partition assignment strategies that the client will use to distribute partition ownership amongst consumer instances when group management is used. Available options are:
org.apache.kafka.clients.consumer.RangeAssignor: Assigns partitions on a per-topic basis.
org.apache.kafka.clients.consumer.RoundRobinAssignor: Assigns partitions to consumers in a round-robin fashion.
org.apache.kafka.clients.consumer.StickyAssignor: Guarantees an assignment that is maximally balanced while preserving as many existing partition assignments as possible.
org.apache.kafka.clients.consumer.CooperativeStickyAssignor: Follows the same StickyAssignor logic, but allows for cooperative rebalancing.package com.bigdata.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumerWithFenPei {
public static void main(String[] args) {
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop11:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");
// 指定分区的分配方案
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 消费者订阅主题,主题有数据就会拉取数据
// 指定消费的主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
// 一个消费者可以订阅多个主题
kafkaConsumer.subscribe(topics);
while(true){
//1 秒中向kafka拉取一批数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String,String> record :records) {
// 打印一条数据
System.out.println(record);
// 可以打印记录中的很多内容,比如 key value offset topic 等信息
System.out.println(record.value());
}
}
}
}
修改一下消费者组为test2
(2)重启 3 个消费者,重复发送消息的步骤,观看分区结果



3)RoundRobin 分区分配再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5 号分区数据
2 号消费者:消费到 4、1 号分区数据
0 号消费者 以前对应的数据没有人消费
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、2、4、6 号分区数据
2 号消费者:消费到 1、3、5 号分区数据
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
5.4.3 Sticky 以及再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前, 考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。 粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区 到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
比如分区有 0 1 2 3 4 5 6
消费者有 c1 c2 c3
c1 消费 3个 c2 消费2个 c3 消费2个分区
跟以前不一样的是,c1 消费的3个分区是随机的,不是按照 0 1 2 这样的顺序来的。 
1)需求
设置主题为 first,7 个分区;准备 3 个消费者,采用粘性分区策略,并进行消费,观察
消费分配情况。然后再停止其中一个消费者,再次观察消费分配情况。
2)步骤
(1)修改分区分配策略为粘性。
注意:3 个消费者都应该注释掉,之后重启 3 个消费者,如果出现报错,全部停止等
会再重启,或者修改为全新的消费者组。
// 修改分区分配策略
ArrayList<String> startegys = new ArrayList<>();
startegys.add("org.apache.kafka.clients.consumer.StickyAssignor");
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, startegys);(2)使用同样的生产者发送 500 条消息。
可以看到会尽量保持分区的个数近似划分分区。
3)Sticky 分区分配再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5、3 号分区数据。
2 号消费者:消费到 4、6 号分区数据。
0 号消费者的任务没人顶替它消费
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 2、3、5 号分区数据。
2 号消费者:消费到 0、1、4、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
5.4.4 CooperativeSticky 的解释【新的kafka中刚添加的策略】
在消费过程中,会根据消费的偏移量情况进行重新再平衡,也就是粘性分区,运行过程中还会根据消费的实际情况重新分配消费者,直到平衡为止。
好处是:负载均衡,不好的地方是:多次平衡浪费性能。5.5 offset 位移[偏移量](重要)
记录消费到了哪里的这个值,就是偏移量。
5.5.1 offset 的默认维护位置
从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets 【topic 其实就是数据,就是位置 topic -log --segment- 一个个文件】
Kafka0.9版本之前,consumer默认将offset 保存在Zookeeper中。
kafka0.11 版本 高于 kafka 0.9,咱们用的kafka是 3.0版本。
假如公司中想重置kafka。 删除每一个kafka logs 以及 datas,zk中的kafka 文件夹删除掉。

为什么要把消费者的偏移量从zk中挪到 kafka中呢?原因是避免Conusmer频发跟zk进行通信。
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是group.id+topic+ 分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行 compact (压缩),也就是每个 group.id+topic+分区号就只保留最新数据。
1)消费 offset 案例
(0)思想:__consumer_offsets 为 Kafka 中的 topic,那就可以通过消费者进行消费。
(1)在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false,
默认是 true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为 false。
如果不修改是无法查看offset的值的,因为这些都是加密数据。
修改完,记得同步给其他的节点
重新启动zk和kafka.
zk.sh start
kf.sh start(2)采用命令行方式,创建一个新的 topic。
bin/kafka-topics.sh --bootstrap-server hadoop11:9092 --create --topic bigdata --partitions 2 --replication-factor 2(3)启动生产者往 bigdata 生产数据。
bin/kafka-console-producer.sh --topic bigdata --bootstrap-server hadoop11:9092(4)启动消费者消费 bigdata 数据。
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic five --group suibian注意:指定消费者组名称,更好观察数据存储位置(key 是 group.id+topic+分区号)
假如出现消费不到数据的情况,将分区去掉或者组名称修改一下,起个别的名字(5)查看消费者消费主题__consumer_offsets。
bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server bigdata01:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
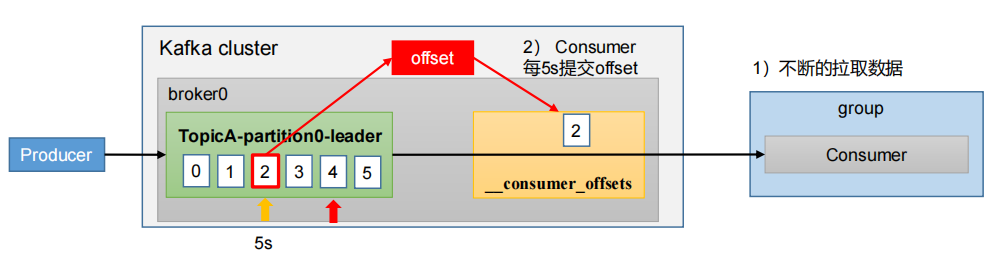
5.5.2 自动提交 offset
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能,默认是true
auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
代码演示:
1)消费者自动提交 offset
package com.bigdata.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumerAutoOffset {
public static void main(String[] args) {
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop11:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 是否自动提交 offset 通过这个字段设置
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
// 提交 offset 的时间周期 1000ms,默认 5s
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 消费者订阅主题,主题有数据就会拉取数据
// 指定消费的主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
// 一个消费者可以订阅多个主题
kafkaConsumer.subscribe(topics);
while(true){
//1 秒中向kafka拉取一批数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String,String> record :records) {
// 打印一条数据
System.out.println(record);
// 可以打印记录中的很多内容,比如 key value offset topic 等信息
System.out.println(record.value());
}
}
}
}5.5.3 手动提交 offset
虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
• commitSync (同步提交):必须等待offset提交完毕,再去消费下一批数据。
• commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
1)同步提交 offset
由于同步提交 offset 有失败重试机制,故更加可靠,但是由于一直等待提交结果,提交的效率比较低。以下为同步提交 offset 的示例。
package com.bigdata.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumerByHandSync {
public static void main(String[] args) {
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop11:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 是否自动提交 offset 通过这个字段设置
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 消费者订阅主题,主题有数据就会拉取数据
// 指定消费的主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
// 一个消费者可以订阅多个主题
kafkaConsumer.subscribe(topics);
while(true){
//1 秒中向kafka拉取一批数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String,String> record :records) {
// 打印一条数据
System.out.println(record);
// 可以打印记录中的很多内容,比如 key value offset topic 等信息
System.out.println(record.value());
}
// 同步提交 offset
kafkaConsumer.commitSync();
}
}
}
2)异步提交 offset
虽然同步提交 offset 更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会受到很大的影响。因此更多的情况下,会选用异步提交 offset 的方式。
以下为异步提交 offset 的示例:
记得将自动提交给关了
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
// 同步提交 offset
//kafkaConsumer.commitSync();
// 异步提交
kafkaConsumer.commitAsync();5.5.4 指定 Offset 消费 【重要】
auto.offset.reset = earliest | latest | none 默认是 latest。
当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
(1)earliest:自动将偏移量重置为最早的偏移量,--from-beginning
(2)latest(默认值):自动将偏移量重置为最新偏移量。
(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // 设置为latest

这个参数的力度太大了。不是从头,就是从尾。有没有一种方法能我们自己选择消费的位置呢?
有。
kafka提供了seek方法,可以让我们从分区的固定位置开始消费。
入参为seek (TopicPartition topicPartition,offset offset)。前面我们讲过TopicPartition这个对象里有2个成员变量。一个是Topic,一个是partition。再结合offset,完全就可以定位到某个主题、某个分区的某个leader副本的active日志文件的某个位置。
offset是指分区的消息偏移量

package com.bigdata.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
import java.util.Set;
public class CustomConsumerSeek {
public static void main(String[] args) {
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop11:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 2 订阅一个主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 执行计划
// 此时的消费计划是空的,因为没有时间生成
Set<TopicPartition> assignment = kafkaConsumer.assignment();
while(assignment.size() == 0){
// 这个本身是拉取数据的代码,此处可以帮助快速构建分区方案出来
kafkaConsumer.poll(Duration.ofSeconds(1));
// 一直获取它的分区方案,什么时候有了,就什么时候跳出这个循环
assignment = kafkaConsumer.assignment();
}
for (TopicPartition tp:assignment) {
kafkaConsumer.seek(tp,10);
}
while(true){
//1 秒中向kafka拉取一批数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String,String> record :records) {
// 打印一条数据
System.out.println(record);
// 可以打印记录中的很多内容,比如 key value offset topic 等信息
System.out.println(record.value());
}
}
}
}
注意:每次执行完,需要修改消费者组名;
5.5.5 指定时间消费
需求:在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。
例如要求按照时间消费前一天的数据,怎么处理?
操作步骤:
package com.bigdata.consumer;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
/**
* 从某个特定的时间开始进行消费
*/
public class Customer05 {
public static void main(String[] args) {
// 其实就是map
Properties properties = new Properties();
// 连接kafka
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "testf");
// 指定分区的分配方案 为轮询策略
//properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
ArrayList<String> startegys = new ArrayList<>();
startegys.add("org.apache.kafka.clients.consumer.StickyAssignor");
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, startegys);
// 创建一个kafka消费者的对象
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 消费者消费的是kafka集群的数据,消费哪个主题的数据呢?
List<String> topics = new ArrayList<>();
topics.add("five");// list总可以设置多个主题的名称
kafkaConsumer.subscribe(topics);
// 因为消费者是不停的消费,所以是while true
// 指定了获取分区数据的起始位置。
// 这样写会报错的,因为前期消费需要指定计划,指定计划需要时间
// 此时的消费计划是空的,因为没有时间生成
Set<TopicPartition> assignment = kafkaConsumer.assignment();
while(assignment.size() == 0){
// 这个本身是拉取数据的代码,此处可以帮助快速构建分区方案出来
kafkaConsumer.poll(Duration.ofSeconds(1));
// 一直获取它的分区方案,什么时候有了,就什么时候跳出这个循环
assignment = kafkaConsumer.assignment();
}
Map<TopicPartition, Long> hashMap = new HashMap<>();
for (TopicPartition partition:assignment) {
hashMap.put(partition,System.currentTimeMillis()- 60*60*1000);
}
Map<TopicPartition, OffsetAndTimestamp> map = kafkaConsumer.offsetsForTimes(hashMap);
for (TopicPartition partition:assignment) {
OffsetAndTimestamp offsetAndTimestamp = map.get(partition);
kafkaConsumer.seek(partition,offsetAndTimestamp.offset());
}
while(true){
// 每隔一秒钟,从kafka 集群中拉取一次数据,有可能拉取多条数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
// 循环打印每一条数据
for (ConsumerRecord record:records) {
// 打印数据中的值
System.out.println(record.value());
System.out.println(record.offset());
// 打印一条数据
System.out.println(record);
}
}
}
}
5.5.6 漏消费和重复消费
重复消费:已经消费了数据,但是 offset 没提交。
漏消费:先提交 offset 后消费,有可能会造成数据的漏消费。

思考:怎么能做到既不漏消费也不重复消费呢?详看消费者事务。
5.6 生产经验——消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset 过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质(比 如MySQL)。这部分知识会在后续项目部分涉及。
事务的四大特征:ACID
转账:张三 --> 李四

5.7 生产经验——数据积压(消费者如何提高吞吐量)
负利率:钱存银行,银行收你钱。
目前:只能存一年,1.9,1万存一年190元。



bit --> byte --> kb -->mb -->gb --> tb --> pb --> eb -> zb -->yb
第 6 章 Kafka-Eagle 监控
Kafka-Eagle 框架可以监控 Kafka 集群的整体运行情况,在生产环境中经常使用。
在生产过程中,想创建topic、查看所有topic、想查看某个topic 想查看分区等,都需要写命令,能不能有一个图形化的界面,让我们操作呢?6.1 MySQL 环境准备
Kafka-Eagle 的安装依赖于 MySQL,MySQL 主要用来存储可视化展示的数据。如果集
群中之前安装过 MySQL 可以跨过该步。
6.2 Kafka 环境准备
1)关闭 Kafka 集群
kf.sh stop
2)修改/opt/installs/kafka3/bin/kafka-server-start.sh 命令中
vi bin/kafka-server-start.sh
修改如下参数值:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
注意:修改之后在启动 Kafka 之前要分发之其他节点
xsync.sh kafka-server-start.sh
6.3 Kafka-Eagle 安装
0)官网:https://www.kafka-eagle.org
1)上传压缩包 kafka-eagle-bin-2.0.8.tar.gz 到集群/opt/modules 目录
2)解压到本地
tar -zxvf kafka-eagle-bin-2.0.8.tar.gz3)将 efak-web-2.0.8-bin.tar.gz 解压至/opt/installs
cd kafka-eagle-bin-2.0.8
tar -zxvf efak-web-2.0.8-bin.tar.gz -C /opt/installs/ 4)修改名称
mv efak-web-2.0.8/ efak
5)修改配置文件 /opt/installs/efak/conf/system-config.properties
vi system-config.properties
修改如下:
# offset 保存在 kafka
cluster1.efak.offset.storage=kafka
efak.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=bigdata01:2181,bigdata02:2181,bigdata03:2181/kafka
cluster2.zk.list=bigdata01:2181,bigdata02:2181,bigdata03:2181/kafka
# 修改数据库连接:&serverTimezone=GMT 时区一定要写,否则报405错误!
# 127.0.0.1 = localhost hosts文件中定义的
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&serverTimezone=GMT
efak.username=root
efak.password=1234567)添加环境变量
# kafkaEFAK
export KE_HOME=/opt/installs/efak
export PATH=$PATH:$KE_HOME/bin注意:source /etc/profile
启动数据库:
[root@hadoop11 conf]# systemctl start mysqld
[root@hadoop11 conf]# systemctl status mysqld新建一个数据库,叫做ke

8)启动
(1)注意:启动之前需要先启动 ZK 以及 KAFKA。
zk.sh start
kf.sh startxcall.sh zkServer.sh start
kf.sh start
(2)启动 efak
bin/ke.sh start
说明:如果停止 efak,执行命令
bin/ke.sh stop
假如启动无法访问,怎么办?查看日志,必定有答案!!
使用的时候,一定要在配置文件中编写正确的路径,否则kafka集群没办法连接:
cluster1.zk.list=hadoop11:2181,hadoop12:2181,hadoop13:2181/kafka
cluster2.zk.list=hadoop11:2181,hadoop12:2181,hadoop13:2181/kafka查看可视化大屏的时候:
1、同步一下时间 systemctl restart chronyd
2、要开启消费者
3、要开发生产者
4、关闭flume (选项)
5、如果都没效果,可以添加一句话 在zkServer.sh 中
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
全部重启一下,这些服务
要想看到大屏数据,此处的JMX必须是上线状态:


6.4 Kafka-Eagle 页面操作
1)登录页面查看监控数据
http://ip地址:8048/
或者
http://ip地址:8048/ke

切记:假如访问不了,查看efak中的log日志,里面的错误特别的详细,绝对可以解决你的问题。
eagle 可以通过这个图形化界面管理Topic,查看kafka的集群的消息发送和消费情况,还可以操作zk.
6.5-Kafka-UI的安装
上传安装包 到 /opt/modules下面
tar -zxvf kafka-ui-lite-1.2.11-bin.tar.gz -C /opt/installs/
mv kafka-ui-lite-1.2.11/ kafka-ui
进入bin路径下:./kafkaUI.sh -d start进入界面:http://bigdata01:8889/

七、第七章--与其他软件整合
Flume和kafka的整合
1、Kafka作为Source 【数据进入到kafka中,抽取出来】

在flume的conf文件夹下,有一个flumeconf 文件夹:

创建一个flume脚本文件: kafka-memory-logger.conf
Flume 1.9用户手册中文版 — 可能是目前翻译最完整的版本了

a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 100
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = bigdata01:9092,bigdata02:9092,bigdata03:9092
a1.sources.r1.kafka.topics = five
a1.sources.r1.kafka.consumer.group.id = qiaodaohu
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = logger
a1.sinks.k1.maxBytesToLog = 128接着创建一个topic ,名字叫做 kafka-flume,或者直接使用以前的five 主题
kafka-topics.sh --create --topic kafka-flume --bootstrap-server bigdata01:9092 --partitions 3 --replication-factor 1测试:
启动一个消息生产者,向topic中发送消息,启动flume,接收消息

kafka-console-producer.sh --topic kafka-flume --bootstrap-server bigdata01:9092启动flume,查看log日志:
flume-ng agent -n a1 -c ../conf -f ./kafka-memory-logger.conf -Dflume.root.logger=INFO,console
编写一个脚本:flume-kafka-sink.conf
##a1就是flume agent的名称
## source r1
## channel c1
## sink k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = bigdata01
a1.sources.r1.port = 44444
# 修改sink为kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = bigdata01:9092
a1.sinks.k1.kafka.topic = five
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1netcat --> memory -->kafka创建topic (flume-kafka):
kafka-topics.sh --create --topic flume-kafka --bootstrap-server bigdata01:9092 --partitions 3 --replication-factor 1测试:
启动:
flume-ng agent -n a1 -c conf -f $FLUME_HOME/job/flume-kafka-sink.conf -Dflume.root.logger=INFO,console使用telnet命令,向端口发送消息:
yum -y install telnet
telnet bigdata01 44444在窗口不断的发送文本数据,数据被抽取到了kafka中,如何获取kafka数据呢?使用消费者:
kafka-console-consumer.sh --topic flume-kafka --bootstrap-server bigdata01:9092 --from-beginning这样数据就被消费了。
假定一个场景:
fluem可以抽取不断产生的日志,抽取到的日志数据,发送给kafka,kafka经过处理,展示在页面上,或者进行汇总统计。