哈希
哈希,有限空间映射一个无限的空间。在空间内,有序化进行快速查询。
用空间换时间。
1.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
题解步骤:
1.你要判断加起来能不能等于目标值,你就需要遍历全部的数值。
这里就是使用for循环,遍历里面的每一个元素。
int n = nums.length;
for(int i = 0 ; i < n ; ++i)
2.对于选到的第一个值,要判断其他值和它相加是不是等于目标值。
【提高速度的点在于步骤2,因为步骤1他是遍历了每一个数值,这里是为了确保准确性】
步骤2的解法:
暴力解:
直接使用循环来多次遍历全部组合。
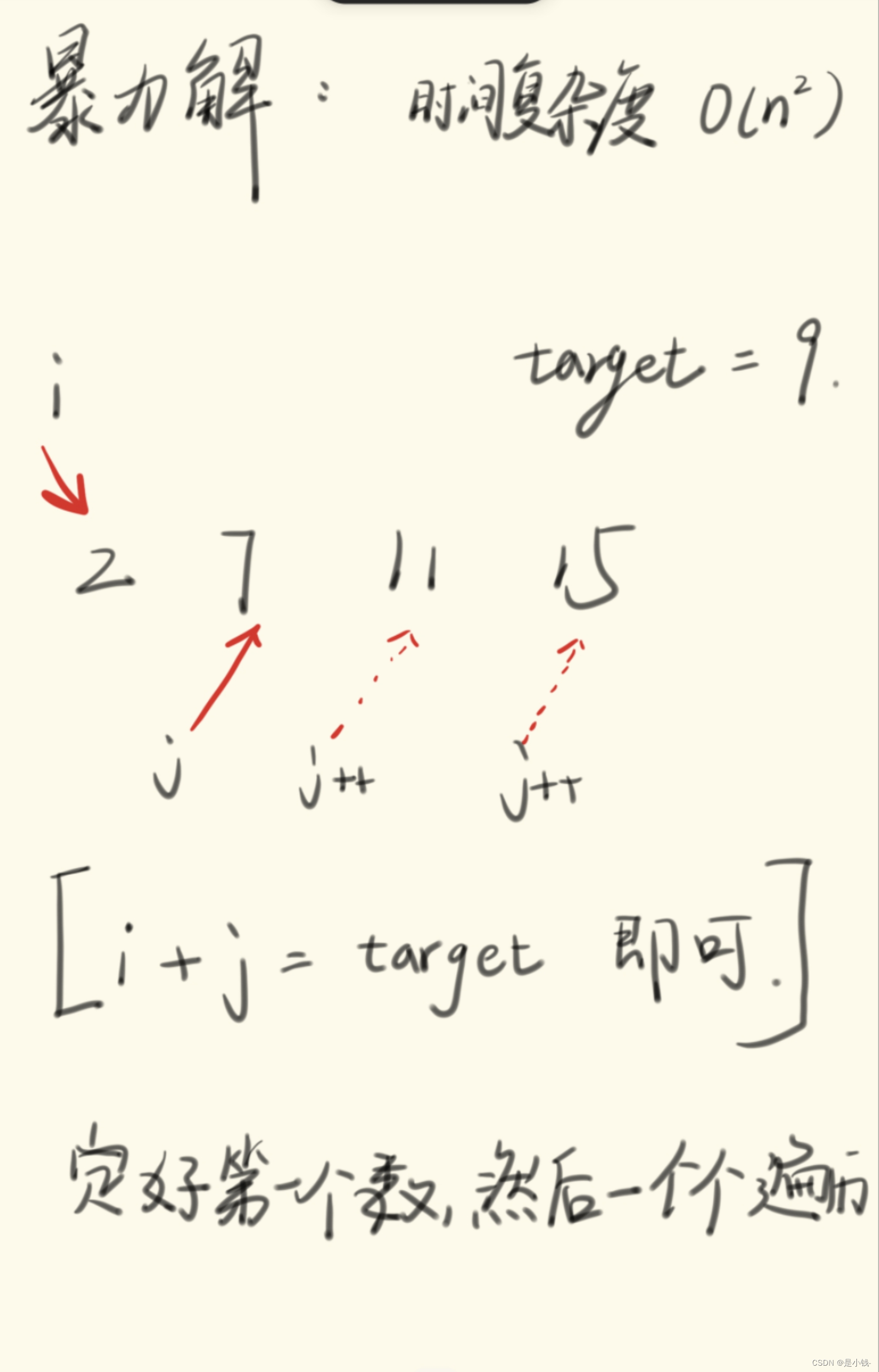
//在上面的基础上
int n = nums.length;
for(int i = 0 ; i < n ; ++i) {
for(int j = i; j < n ; ++j) {
if (nums[i]+nums[j] == target){
return new int[] {i,j};
}
}
}
return new int[0];
哈希解:
利用特别的数据结构来省略循环步骤。
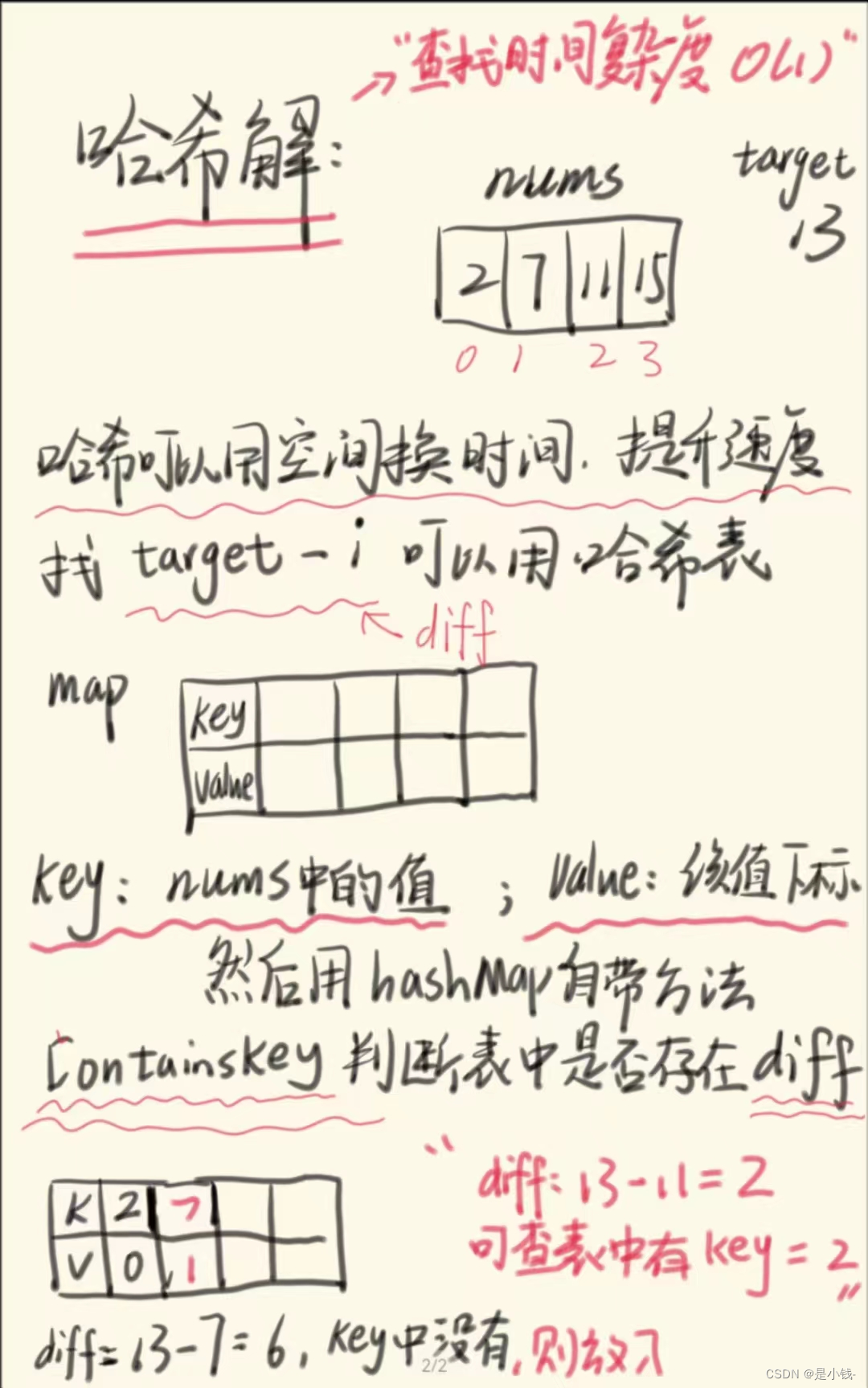
int n = nums.length;
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < n; ++i) {
int choose = nums[i];
int diff = target - choose;
if (map.containsKey(diff)) {
return new int[] { map.get(diff), i };
}
map.put(choose, i);
}
return null;
49.字母异位词分组
相关标签 :数组 哈希表 字符串 排序 【难度:中等】
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:
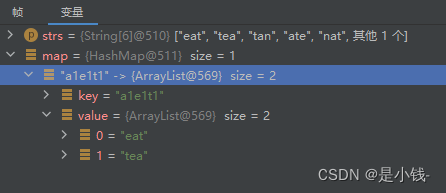
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
输入: strs = [""]
输出: [[""]]
示例 3:
输入: strs = ["a"]
输出: [["a"]]
提示:
1 <= strs.length <= 1040 <= strs[i].length <= 100strs[i]仅包含小写字母
解题步骤:
1.遍历所有的字母字符串
for (String str : strs) {}
2.判断字母是不是处理了,已经存在里面了。
【字母异位词的性质就是字母相同,但是排列不同的字符串。这里说明他们按照某种方式排序处理后,应该是一样的。一般称这种位标准化,把结果统一成一个标准规格】
这里就可以使用字典排序,abcdef…… 【 Arrays.sort() 】
步骤2有两种方法:
排序: 【字典排序,利用hashMap的k-v;相同的标准,存对应的集合】
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List> map = new HashMap<>();
for (String str : strs) {
// 将字符串分割出来,然后按照字典排序
char[] chars = str.toCharArray();
Arrays.sort(chars);
String key = new String(chars);
// 判断拆开排序后的字符串是不是已经存在hash表中了,没有则创建一个新的
if (!map.containsKey(key)) {
map.put(key, new ArrayList<>());
}
// 已经有这个key,则把单词添加进去
map.get(key).add(str);
}
return new ArrayList(map.values());
}
}
计数【哈希】:

1.先记录每个元素的字母
2.根据每个元素字母+出现次数 拼凑出一个新的值【用于区分】
3.根据相同新的值来分类即可
public static List<List<String>> groupAnagrams(String[] strs) {
// key:区分值 value:相同区分值的
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) {
// 创建长度为26的数组,记录每个字母出现的次数
int[] counts = new int[26];
int length = str.length();
// 字符串 -> 字符数组。遍历字符串的每一个字符,给对应的字母数组计数 +1
for (int i = 0; i < length; i++) {
counts[str.charAt(i) - 'a']++;
}
// 创建StringBuffer对象,用于构建表示当前字符串字母出现次数的字符串
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 26; i++) {
//如果某个字母出现了(即 counts[i] != 0)
if (counts[i] != 0) {
// 我们就将该字母和其出现次数追加到 sb 中。
sb.append((char) ('a' + i));
sb.append(counts[i]);
}
}
String key = sb.toString();
// map.getOrDefault 方法获取与 key 对应的列表,如果不存在则创建一个新的列表。
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
return new ArrayList<List<String>>(map.values());
}
getOrDefault 方法:
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))
? v
: defaultValue;
}
- 如果键存在且有对应的值,则返回该值。
- 如果键存在但值为
null,则返回null。 - 如果键不存在,则返回指定的默认值
defaultValue。
128.最长连续序列
相关标签
并查集 数组 哈希表 难度 : 中等
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109
题目分析:
要先明白该类型的特性。
【连续序列:最前面的数字没前置数字 中间的数字都有后续数字 最后面的数字没用后置数字】
流程:
1.所以可以从第一个数开始判断,判断是否他有前置数字。没有的话,就可以把他当作第一个节点,来开始计算。
// 判断有没有前置数字,是否是首节点
if (!set.contains(i - 1)) {
// 判断有没有后置数字
// 然后因为要一直往后判断,则要有一个临时值记录增加1后的值,一直刷新
int temp = i;
// 这里长度有1个,就是头节点
tempResult = 1;
2.然后再判断看作第一个节点 + 1后,是否存在;存在则重复该操作 【实则是当前节点 +1,+2,+……,直到到了尾节点就退出】
while (set.contains(temp + 1)) {
// 有后续自然需要将临时值加1,用来判断下一次 【 i+2 …… 】
temp++;
// 长度再加 +1
tempResult++;
}
3.然后因为可能不止一对这种连续的序列,就将每一次的序列进行对比,大的存起来与下一次的序列进行对比,最终返回最大的序列长度。
// 选择最大的值返回,那么这里就是比对每一次的结果,然后最后把值返回出去
result = Math.max(result, tempResult);
完整代码:
public int longestConsecutive(int[] nums) {
// 先去重
HashSet<Integer> set = new HashSet<>();
for (int num : nums) {
set.add(num);
}
// 最终结果
int result = 0;
// 这里需要有一个变量记录每一次的长度
int tempResult = 0;
for (Integer i : set) {
// 判断有没有前置数字,是否是首节点
if (!set.contains(i - 1)) {
// 判断有没有后置数字
// 然后因为要一直往后判断,则要有一个临时值记录增加1后的值,一直刷新
int temp = i;
// 这里长度有1个,就是头节点
tempResult = 1;
while (set.contains(temp + 1)) {
// 有后续自然需要将临时值加1,用来判断下一次 【 i+2 …… 】
temp++;
// 长度再加 +1
tempResult++;
}
// 选择最大的值返回,那么这里就是比对每一次的结果,然后最后把值返回出去
result = Math.max(result, tempResult);
}
}
return result;
}
由此可以总结:
两数之和 : 注意使用哈希来代替遍历:
字母异位词分组 : 借助对数据的重新标准化来定制哈希从而聚合数据:
最长连续序列 : 通过分解目标结构的规则来实现分步查找。