torch.optim的官方文档
官方文档中文版
一、Implementation
torch.optim的官方文档在介绍一些optimizer Algorithms时提及它们的implementation共有如下三个类别:for-loop, foreach (multi-tensor), and fused。
Chat-GPT对这三个implementation的解释是:
- For-loop实现
for-loop 实现是最传统和直接的实现方式。它会遍历每一个参数,对每一个参数单独进行更新。这种方法的优点是简单易懂,容易实现和调试。但缺点是效率较低,尤其是在处理大量参数时,因为每个参数更新的操作是逐个执行的。
适用场景:
- 小规模模型或参数较少的情况。
- 需要简单且容易调试的实现方式。
- Foreach (multi-tensor) 实现
foreach (multi-tensor) 实现方式通过在一个操作中处理多个张量以提高效率。它将多个参数的更新操作批量化,从而减少操作的开销和提高内存访问效率。这种方法在处理大量参数时可以显著提升性能。
适用场景:
- 大规模模型或包含大量参数的情况。
- 需要在不牺牲灵活性的前提下提高计算效率。
- Fused 实现
fused 实现方式是性能最优的一种,它将多个操作融合在一起,以减少内存访问和操作开销。这种方法通常依赖于特定的硬件加速,例如 GPU 上的 CUDA 核函数,可以显著加快计算速度。
适用场景:
- 超大规模模型或需要极高性能的情况。
- 在硬件加速器(如 GPU 或 TPU)上运行时。
这三种implementation的性能表现排名为:fused > foreach > for-loop。在条件允许的情况下,torch.optim会更倾向于将foreach设置为default implementation。尽管fused比foreach更高效,但是目前其适用性并不如foreach好。
二、Algorithms
一些常见的algorithm有:SGD、Adam等,不同的algorithms可能有不同的implementation。大致如下:
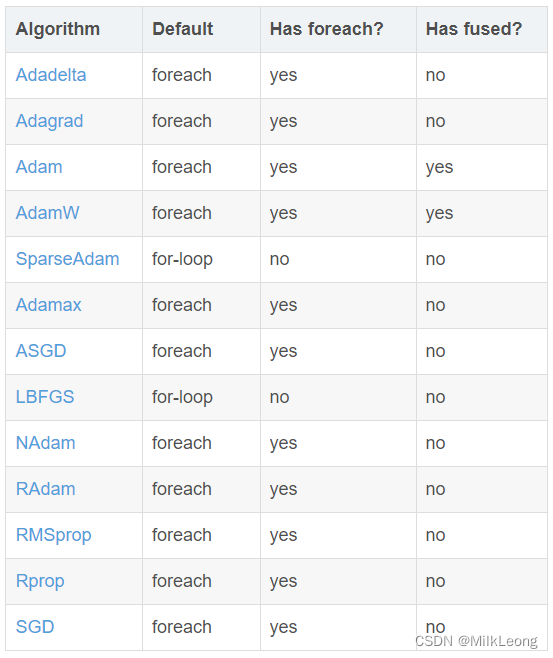
Chat-GPT-4o认为不同的优化算法有不同的适用场景和任务,比如分类、回归、图像处理、自然语言处理等。下面是这些优化算法的一些适用场景和特点:
-
Adadelta
适用场景: 适用于大规模深度学习任务,尤其是那些需要动态调整学习率的任务。
任务类型: 分类、回归。
特点: 自适应学习率算法,适合处理稀疏数据和梯度变化较大的情况。 -
Adagrad
适用场景: 适用于稀疏数据和文本数据的任务,比如自然语言处理。
任务类型: 分类、回归。
特点: 自适应学习率算法,对频繁更新的参数进行较小的更新,对不常更新的参数进行较大的更新。 -
Adam
适用场景: 广泛适用于各种深度学习任务,包括图像处理、语音识别、自然语言处理等。
任务类型: 分类、回归、生成模型。
特点: 结合了AdaGrad和RMSprop的优点,自适应学习率和动量。 -
AdamW
适用场景: 适用于需要权重衰减(L2正则化)的任务,例如Transformer模型。
任务类型: 分类、回归、生成模型。
特点: 类似Adam,但在权重衰减的处理上进行了改进,防止权重衰减影响动量。 -
SparseAdam
适用场景: 适用于稀疏数据的深度学习任务。
任务类型: 分类、回归。
特点: 专为稀疏数据设计,能够高效处理稀疏梯度。 -
Adamax
适用场景: 适用于大型神经网络,尤其是需要稳定训练的任务。
任务类型: 分类、回归、生成模型。
特点: Adam的变种,在处理大规模数据时更稳定。 -
ASGD (Averaged Stochastic Gradient Descent)
适用场景: 适用于需要快速收敛的任务。
任务类型: 分类、回归。
特点: 通过对多个模型参数进行平均,使得模型参数更稳定。 -
LBFGS (Limited-memory BFGS)
适用场景: 适用于小型数据集和传统机器学习任务。
任务类型: 分类、回归。
特点: 二阶优化算法,适合非深度学习的优化问题。 -
NAdam (Nesterov-accelerated Adaptive Moment Estimation)
适用场景: 适用于需要快速和稳定优化的深度学习任务。
任务类型: 分类、回归、生成模型。
特点: 结合了Nesterov动量和Adam算法的优点,提高了收敛速度和稳定性。 -
RAdam (Rectified Adam)
适用场景: 适用于不稳定训练过程的深度学习任务。
任务类型: 分类、回归、生成模型。
特点: 改进了Adam算法的学习率调整机制,防止了学习率过高导致的不稳定。 -
RMSprop
适用场景: 适用于循环神经网络(RNN)等需要稳定训练的任务。
任务类型: 分类、回归、生成模型。
特点: 自适应学习率算法,适合处理不稳定的梯度。 -
Rprop (Resilient Propagation)
适用场景: 适用于传统的机器学习任务和小型神经网络。
任务类型: 分类、回归。
特点: 基于梯度符号的优化算法,适合小规模数据集。 -
SGD (Stochastic Gradient Descent)
适用场景: 通用的深度学习和机器学习任务,尤其适合大规模数据集。
任务类型: 分类、回归、生成模型。
特点: 基本优化算法,适合需要手动调整学习率和动量的情况。
这些优化算法各有优缺点,选择合适的优化算法取决于具体的任务和数据特点。一般来说,Adam及其变种由于其高效的自适应学习率调整机制和较好的收敛性能,广泛应用于各种深度学习任务,如分类、回归、自然语言处理和图像生成等。