处理文本内容的命令
正则表达式匹配的是文本内容,linux的文本三剑客 都是针对文本内容
文本三剑客:
grep 过滤文本内容
sed 针对文本内容进行增删改查
awk 按行取列
文本三剑客都是按行进行匹配。
grep
grep的作用就是使用正则表达式来匹配文本内容。
选项:
-m 匹配几次之后停止
[root@localhost opt]# grep -m 1 root /etc/passwd root:x:0:0:root:/root:/bin/bash
-v 取反
[root@localhost opt]# cat /opt/123.txt qwe 123 aaa bbb ccc [root@localhost opt]# grep -v 123 /opt//123.txt qwe aaa bbb ccc
-n 显示匹配的行号
[root@localhost opt]# grep -n root /etc/passwd 1:root:x:0:0:root:/root:/bin/bash 10:operator:x:11:0:operator:/root:/sbin/nologin
-c 只统计匹配的行数
[root@localhost opt]# grep -c root /etc/passwd 2
-o 仅显示匹配的结果
[root@localhost opt]# grep -o root /etc/passwd root root root root
-q 静默模式。不输出任何信息
[root@localhost opt]# grep -q root /etc/passwd [root@localhost opt]#
-A 数字 后几行
[root@localhost opt]# grep -A 3 root /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin -- operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin
-B 数字 前几行
-C 数字 前后各几行
-e 或者
-E 匹配扩展正则表达式
-f 匹配两个文件相同的内容,以第一个文件为准
[root@localhost opt]# vim 123.txt qwe 123 aaa bbb ccc [root@localhost opt]# vim 456.txt 123 qwe ddd ccc [root@localhost opt]# grep -f 123.txt 456.txt 123 qwe ccc
-r 递归目录 目录下的文件内容。软连接不包含在内
-R 递归目录 目录下的文件内容。包含软连接。
[root@localhost opt]# grep -r qwe /opt /opt/dec/123.txt:qwe /opt/123.txt:qwe /opt/456.txt:qwe [root@localhost opt]# grep -R qwe /opt /opt/dec/123.txt:qwe /opt/123.txt:qwe /opt/999.txt:qwe /opt/456.txt:qwe
排序:
sort
sort
以行为单位,对文件的内容进行排序
sort 选项 参数
cat file | sort 选项
-f 忽略大小写,默认会把大写字母排在前面
-b 忽略每行之前的空格
-n 按照数字进行排序
-r 反向排序
-u 相同的数据仅显示一行
-o 把排序后的结构转存到指定的文件
uniq
uniq 去除连续重复的行,只显示一行
-c 统计连续重复的行的次数,合并连续重复的行
-u 显示仅出现一次的行(包括不是连续出现的重复行)
-d 仅显示连续重复的行(不包括非连续出现的内容)
tr 用来对标准输出的字符进行替换,压缩和删除。
tr 选项 参数
-c 保留字符集1的字符,其他的字符用字符集2来进行替换
-d 删除字符集中的一部分
-s 把字符集1的部分替换成字符集2的部分 连续重复出现的字符串压缩成一个字符
cut
cut和awk 都可以按行取列。
cut 快速裁剪
-d 指定分隔符(默认的分割符是tab键)
-f 对字段进行截取,指定输出段的内容
-complement 输出的时候排除指定的字段
-output-delimiter 更改输出内容的分割符
[root@localhost ~]# head -n 1 /etc/passwd | cut -d ':' -f 1-5 --output-delimiter=' ' root x 0 0 root
-b 以字节为单位进行截取
-c 以字符为单位进行截取
文件的拆分:split
split 大文件拆分成若干小的文件
-l 按行来进行分割
-b 按照大小来进行分割
面试题:
现在有一个日志文件,很大,5G,第一个能不能快速的打开?
第一个方法:拆分 -l 按行 -b 大小
这种文件推荐使用按大小。
文件合并:
cat
paste
面试题:
cat合并和paste合并之间有什么区别
cat是上下合并
paste是左右合并
面试题:
统计当前主机的连接状态:
[root@localhost opt]# ss -antp | grep -v '^State' | cut -d ' ' -f 1 | sort | uniq -c 1 ESTAB 13 LISTEN
正则表达式:
正则表达式:由一类特殊字符以及文本字符所编写的一个模式,模式又来匹配文件当中的内容(字符)。
效验我们输入的内容是否满足规定,格式,长度等等要求。
主要用来匹配文本内容,命令的结果。
通配符:只能用于匹配文件名和目录名,不能匹配文件内容和命令结构。
正则表达式:
基本正则表达式:
元字符(字符匹配)
. 任意单个字符,也可以是一个汉字
\ 转义符 恢复其本意

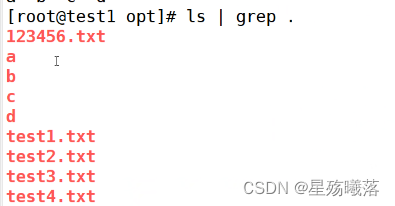
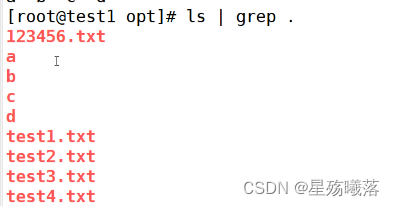
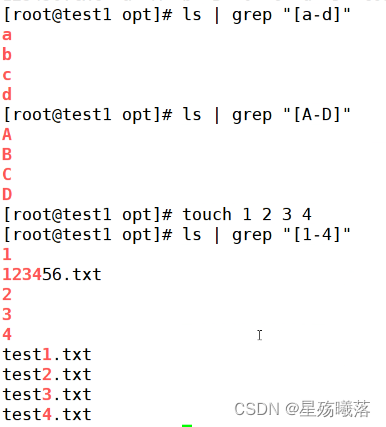
[] 匹配指定范围内的任意单个字符或者数字
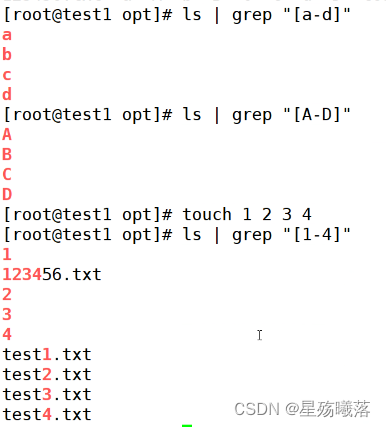
[^] 取反
^# 以#为开头
^$ 表示空行
匹配字符出现的次数:
* 匹配前面的字符任意次,0次也可以。贪婪模式,尽可能的匹配。

.* 匹配前面的任意字符,至少要有一次。匹配所有。

\? 匹配前面的字符0次或者1次,可有可无。
\+ 匹配前面的字符只少出现一次
\{n\} 匹配前面的字符=n次,可以小于n,但是不能大于n,而且前面的字符必须要是连续出现
\{m,n\}匹配前面的字符至少m次,至多n次。必须是连续出现,超出的不在匹配范围。
位置锚定:
^:以什么为开头,行首锚定
$:以什么为结尾,行尾锚定
[root@localhost opt]# cat -n test1.txt 1 13770325194 2 13131301010 3 111111111111 4 aaacvvaada 5 rootroot 6 root 7 rootrootroot [root@localhost opt]# cat test1.txt | grep -n "^root$" #这一行只能有root 6:root
\< 或者 \b 词首锚定,匹配单词的左侧(连续的数字,字母。下划线都算单词内部)
\> 或者 \b 词尾锚定 用于匹配单词的右侧
\broot\b 匹配整个单词。空格隔开的也算整个单词
^root$ 整行只有这一个单词
区别
分组和逻辑关系
分组()
或者 \|
扩展正则表达式:
grep -E
元字符(字符匹配)
. 任意单个字符,也可以是一个汉字
\ 转义符 恢复其本意

[] 匹配指定范围内的任意单个字符或者数字
[^] 取反
^# 以#为开头
^$ 表示空行
匹配字符出现的次数:
* 匹配前面的字符任意次,0次也可以。贪婪模式,尽可能的匹配。

.* 匹配前面的任意字符,至少要有一次。匹配所有。

? 匹配前面的字符0次或者1次,可有可无。
* 匹配前面的字符只少出现一次
{n} 匹配前面的字符=n次,可以小于n,但是不能大于n,而且前面的字符必须要是连续出现
{m,n}匹配前面的字符至少m次,至多n次。必须是连续出现,超出的不在匹配范围。
位置锚定:
^:以什么为开头,行首锚定
$:以什么为结尾,行尾锚定
[root@localhost opt]# cat -n test1.txt 1 13770325194 2 13131301010 3 111111111111 4 aaacvvaada 5 rootroot 6 root 7 rootrootroot [root@localhost opt]# cat test1.txt | grep -n "^root$" #这一行只能有root 6:root
\< 或者 \b 词首锚定,匹配单词的左侧(连续的数字,字母。下划线都算单词内部)
\> 或者 \b 词尾锚定 用于匹配单词的右侧
\broot\b 匹配整个单词。空格隔开的也算整个单词
^root$ 整行只有这一个单词
区别
分组和逻辑关系
分组()
或者 |
grep -E
egrep


![[AIGC] 使用Google的Guava库中的Lists工具类:常见用法详解](https://img-blog.csdnimg.cn/img_convert/eff2bcfa34ee962710f630945017689b.jpeg)