项目完整代码:https://github.com/YYYUUU42/Yu-dynamic-thread-pool
如果该项目对你有帮助,可以在 github 上点个 ⭐ 喔 🥰🥰
1. 线程池概念
2. ThreadPoolExecutor 介绍
2.1. ThreadPoolExecutor是如何运行,如何同时维护线程和执行任务的
2.2. 任务执行流程
3. 为什么需要动态线程池
4. 动态化线程池
4.1. 整体设计
4.2. 流程图
5. 基于 Redis 实现
5.1. 为什么使用Redis的发布订阅
5.2. 具体实现流程
5.3. 测试
1. 线程池概念
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如Tomcat。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
- 频繁申请/销毁资源和调度资源,将带来额外的消耗,可能会非常巨大。
- 对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险。
- 系统无法合理管理内部的资源分布,会降低系统的稳定性。
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。
使用线程池好处
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
2. ThreadPoolExecutor 介绍
2.1. ThreadPoolExecutor是如何运行,如何同时维护线程和执行任务的
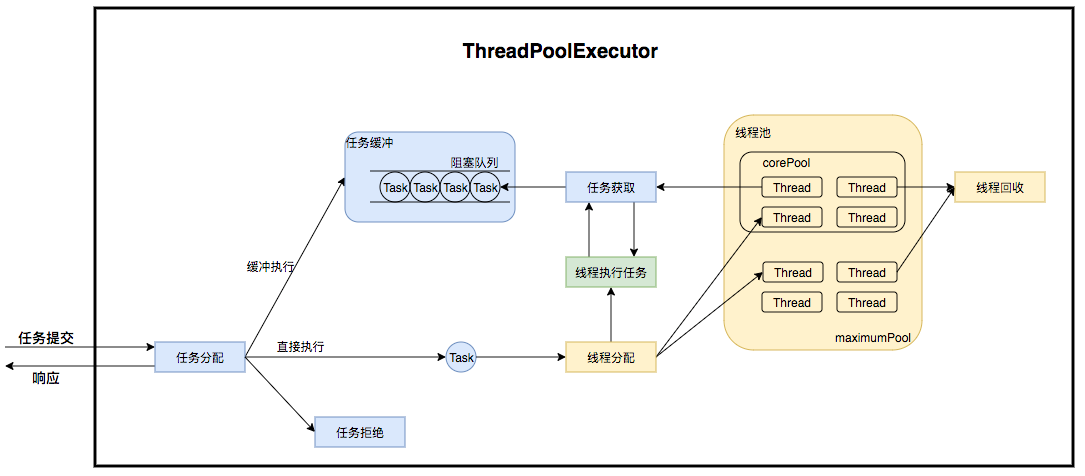
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。
任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:
- 直接申请线程执行该任务;
- 缓冲到队列中等待线程执行;
- 拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
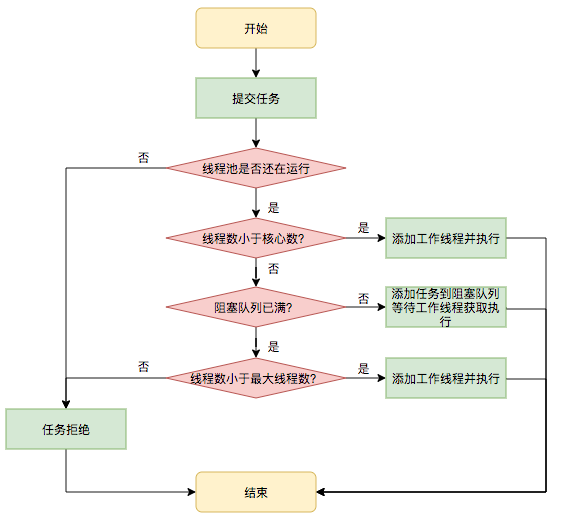
2.2. 任务执行流程
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
3. 为什么需要动态线程池
线程池在业务系统应该都有使用到,帮助业务流程提升效率以及管理线程,多数场景应用于大量的异步任务处理。虽然线程池提供了我们许多便利,但也并非尽善尽美,比如下面这些问题就无法很好解决。
- 线程池随便定义,线程资源过多,造成服务器高负载。
- 线程池参数不易评估,随着业务的并发提升,业务面临出现故障的风险。
- 线程池任务堆积,触发拒绝策略,影响既有业务正常运行。
常见的线程池配置:
执行线程池执行任务的类型
- IO密集型任务:一般来说:文件读写、DB读写、网络请求等
- CPU密集型任务:一般来说:计算型代码、Bitmap转换、Gson转换等
- 高并发、任务执行时间短 -->( CPU核数+1 ),减少线程上下文的切换
- 并发不高、任务执行时间长
-
- IO密集型的任务 --> (CPU核数 * 2 + 1)
- 计算密集型任务 --> ( CPU核数+1 )
- 并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考

但是并没有通用的线程池计算方式。并发任务的执行情况和任务类型相关,IO密集型和CPU密集型的任务运行起来的情况差异非常大,但这种占比是较难合理预估的,这导致很难有一个简单有效的通用公式帮我们直接计算出结果。
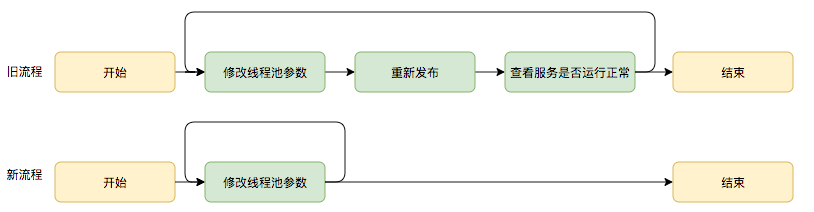
既然不能够保证一次计算出来合适的参数,那么是否可以将修改线程池参数的成本降下来,这样至少可以发生故障的时候可以快速调整从而缩短故障恢复的时间呢?基于这个思考,我们是否可以将线程池的参数从代码中迁移到分布式配置中心上,实现线程池参数可动态配置和即时生效,线程池参数动态化前后的参数修改流程对比如下:
4. 动态化线程池
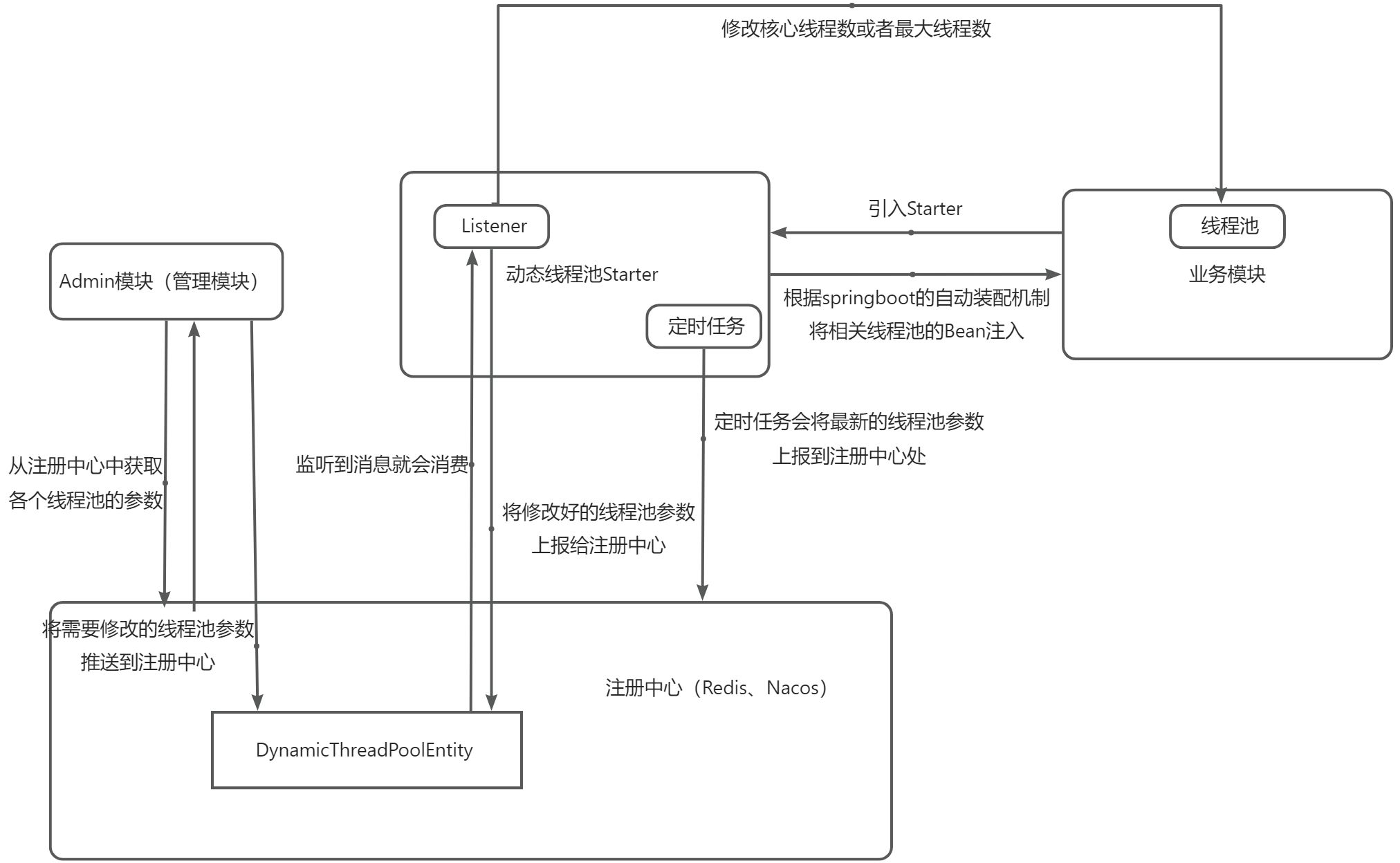
4.1. 整体设计
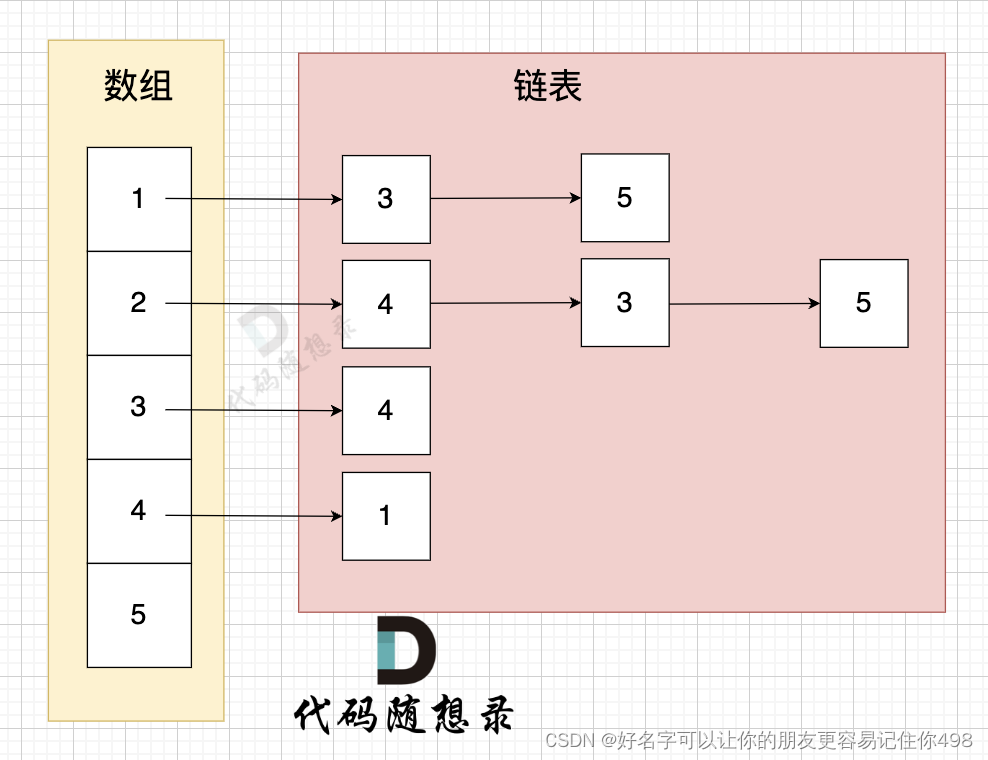
简化线程池配置:线程池构造参数有8个,但是最核心的是3个:corePoolSize、maximumPoolSize,workQueue,它们最大程度地决定了线程池的任务分配和线程分配策略。
为了解决参数不好配,修改参数成本高等问题。在Java线程池留有高扩展性的基础上,封装线程池,允许线程池监听同步外部的消息,根据消息进行修改配置。
将线程池的配置放置在平台侧,允许简单的查看、修改线程池配置。
4.2. 流程图
5. 基于 Redis 实现
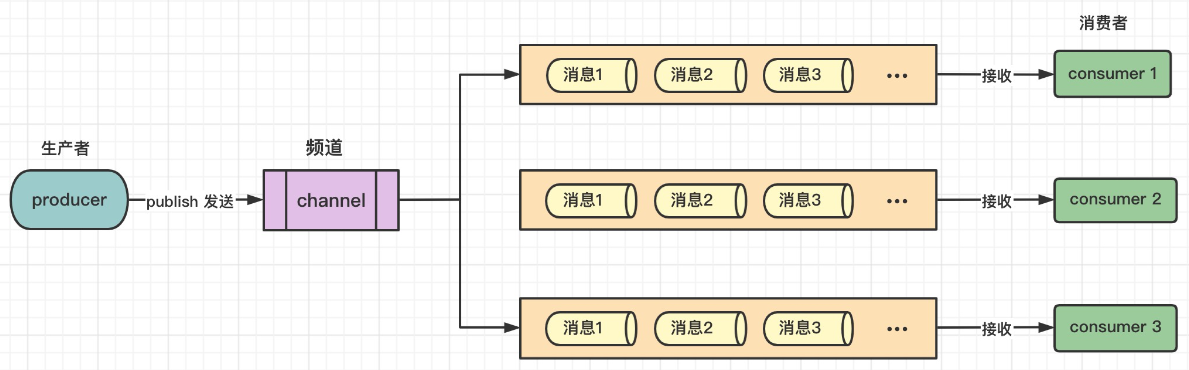
这里主要就是利用 Redis 的发布订阅功能来实现的
- 在上述流程图中,管理模块可以直接从 Redis 中获取各个线程池的参数,将需要修改的线程池参数推送到 Redis 对应的主题中
- 动态线程池的 Starter 的订阅者订阅了主题,一有消息就会消费,再将修改好的线程池相关参数上报到 Redis中
5.1. 为什么使用Redis的发布订阅
针对消息订阅发布功能,大部分使用的是kafka、RabbitMQ、ActiveMQ, RocketMQ等这几种,redis的订阅发布功能跟这三者相比,相对轻量,针对数据准确和安全性要求没有那么高可以直接使用
5.2. 具体实现流程
首先在使用线程池的业务端创建相对应的线程池bean
@Slf4j
@EnableAsync
@Configuration
@EnableConfigurationProperties(ThreadPoolConfigProperties.class)
public class ThreadPoolConfig {
/**
* 创建线程池
*/
@Bean("threadPoolExecutor01")
public ThreadPoolExecutor threadPoolExecutor01(ThreadPoolConfigProperties properties) {
// 线程池拒绝策略
RejectedExecutionHandler handler;
switch (properties.getPolicy()){
case "AbortPolicy":
handler = new ThreadPoolExecutor.AbortPolicy();
break;
case "DiscardPolicy":
handler = new ThreadPoolExecutor.DiscardPolicy();
break;
case "DiscardOldestPolicy":
handler = new ThreadPoolExecutor.DiscardOldestPolicy();
break;
case "CallerRunsPolicy":
handler = new ThreadPoolExecutor.CallerRunsPolicy();
break;
default:
handler = new ThreadPoolExecutor.AbortPolicy();
break;
}
// 创建线程池
return new ThreadPoolExecutor(properties.getCorePoolSize(),
properties.getMaxPoolSize(),
properties.getKeepAliveTime(),
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(properties.getBlockQueueSize()),
Executors.defaultThreadFactory(),
handler);
}
@Bean("threadPoolExecutor02")
public ThreadPoolExecutor threadPoolExecutor02(ThreadPoolConfigProperties properties) {
// 线程池拒绝策略
RejectedExecutionHandler handler;
switch (properties.getPolicy()){
case "AbortPolicy":
handler = new ThreadPoolExecutor.AbortPolicy();
break;
case "DiscardPolicy":
handler = new ThreadPoolExecutor.DiscardPolicy();
break;
case "DiscardOldestPolicy":
handler = new ThreadPoolExecutor.DiscardOldestPolicy();
break;
case "CallerRunsPolicy":
handler = new ThreadPoolExecutor.CallerRunsPolicy();
break;
default:
handler = new ThreadPoolExecutor.AbortPolicy();
break;
}
// 创建线程池
return new ThreadPoolExecutor(properties.getCorePoolSize(),
properties.getMaxPoolSize(),
properties.getKeepAliveTime(),
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(properties.getBlockQueueSize()),
Executors.defaultThreadFactory(),
handler);
}
}然后就是线程池的一些操作(查询线程池列表、根据线程池名称查询线程池配置、更新线程池配置)
其中,由于在业务模块定义了线程池的 Bean,这个 Bean 是 ThreadPoolExecutor 类型的。当 Spring 启动时,它会创建这个Bean,并将其添加到内部的Bean容器中。
其中有个 Map<String, ThreadPoolExecutor> threadPoolExecutorMap集合。这个 Map 是由 Spring 自动注入的,它包含了所有类型为 ThreadPoolExecutor 的 Bean。键是 Bean 的名称,值是对应的 Bean 实例。因此,这个 Map 中会包含业务模块中定义的线程池。

@Slf4j
public class DynamicThreadPoolServiceImpl implements IDynamicThreadPoolService {
/**
* 服务名称
*/
private final String applicationName;
/**
* 线程池集合
*/
private final Map<String, ThreadPoolExecutor> threadPoolExecutorMap;
public DynamicThreadPoolServiceImpl(String applicationName, Map<String, ThreadPoolExecutor> threadPoolExecutorMap) {
this.applicationName = applicationName;
this.threadPoolExecutorMap = threadPoolExecutorMap;
}
/**
* 查询线程池列表
*/
@Override
public List<ThreadPoolConfigEntity> queryThreadPoolList() {
Set<String> threadPoolBeanNames = threadPoolExecutorMap.keySet();
List<ThreadPoolConfigEntity> threadPoolList = new ArrayList<>(threadPoolBeanNames.size());
for (String beanName : threadPoolBeanNames) {
ThreadPoolConfigEntity threadPoolConfigVO = getThreadPoolConfig(beanName);
threadPoolList.add(threadPoolConfigVO);
}
return threadPoolList;
}
/**
* 根据线程池名称查询线程池配置
*/
@Override
public ThreadPoolConfigEntity queryThreadPoolConfigByName(String threadPoolName) {
return getThreadPoolConfig(threadPoolName);
}
/**
* 更新线程池配置
*/
@Override
public void updateThreadPoolConfig(ThreadPoolConfigEntity threadPoolConfigEntity) {
if (threadPoolConfigEntity == null || !applicationName.equals(threadPoolConfigEntity.getAppName())) return;
ThreadPoolExecutor threadPoolExecutor = threadPoolExecutorMap.get(threadPoolConfigEntity.getThreadPoolName());
if (threadPoolExecutor == null) {
return;
}
// 设置参数 「调整核心线程数和最大线程数」
threadPoolExecutor.setCorePoolSize(threadPoolConfigEntity.getCorePoolSize());
threadPoolExecutor.setMaximumPoolSize(threadPoolConfigEntity.getMaximumPoolSize());
}
/**
* 获取线程池配置
*/
private ThreadPoolConfigEntity getThreadPoolConfig(String beanName) {
ThreadPoolExecutor threadPoolExecutor = threadPoolExecutorMap.get(beanName);
if (threadPoolExecutor == null) {
return new ThreadPoolConfigEntity(applicationName, beanName);
}
ThreadPoolConfigEntity threadPoolConfigVO = new ThreadPoolConfigEntity(applicationName, beanName);
threadPoolConfigVO.setCorePoolSize(threadPoolExecutor.getCorePoolSize());
threadPoolConfigVO.setMaximumPoolSize(threadPoolExecutor.getMaximumPoolSize());
threadPoolConfigVO.setActiveCount(threadPoolExecutor.getActiveCount());
threadPoolConfigVO.setPoolSize(threadPoolExecutor.getPoolSize());
threadPoolConfigVO.setQueueType(threadPoolExecutor.getQueue().getClass().getSimpleName());
threadPoolConfigVO.setQueueSize(threadPoolExecutor.getQueue().size());
threadPoolConfigVO.setRemainingCapacity(threadPoolExecutor.getQueue().remainingCapacity());
return threadPoolConfigVO;
}
}这些线程池的操作其实都是 Listener 来操作的
@Slf4j
public class RedisAdjustListener implements MessageListener<ThreadPoolConfigEntity> {
private final IDynamicThreadPoolService dynamicThreadPoolService;
private final IRegistry registry;
public RedisAdjustListener(IDynamicThreadPoolService dynamicThreadPoolService, IRegistry registry) {
this.dynamicThreadPoolService = dynamicThreadPoolService;
this.registry = registry;
}
@Override
public void onMessage(CharSequence charSequence, ThreadPoolConfigEntity threadPoolConfigEntity) {
log.info("动态线程池,调整线程池配置。线程池名称:{} 核心线程数:{} 最大线程数:{}", threadPoolConfigEntity.getThreadPoolName(), threadPoolConfigEntity.getPoolSize(), threadPoolConfigEntity.getMaximumPoolSize());
dynamicThreadPoolService.updateThreadPoolConfig(threadPoolConfigEntity);
// 更新后上报最新数据
List<ThreadPoolConfigEntity> threadPoolConfigEntities = dynamicThreadPoolService.queryThreadPoolList();
registry.reportThreadPool(threadPoolConfigEntities);
ThreadPoolConfigEntity threadPoolConfigEntityCurrent = dynamicThreadPoolService.queryThreadPoolConfigByName(threadPoolConfigEntity.getThreadPoolName());
registry.reportThreadPoolConfigParameter(threadPoolConfigEntityCurrent);
log.info("动态线程池,上报线程池配置:{}", JSON.toJSONString(threadPoolConfigEntity));
}
}然后将最新的数据放到注册中心去
public class RedisRegistry implements IRegistry {
private final RedissonClient redissonClient;
public RedisRegistry(RedissonClient redissonClient) {
this.redissonClient = redissonClient;
}
/**
* 线程池配置列表
*/
@Override
public void reportThreadPool(List<ThreadPoolConfigEntity> threadPoolEntities) {
RList<ThreadPoolConfigEntity> redisList = redissonClient.getList(RegistryEnumVO.THREAD_POOL_CONFIG_LIST_KEY.getKey());
redisList.clear();
redisList.addAll(threadPoolEntities);
}
/**
* 线程池配置参数
*/
@Override
public void reportThreadPoolConfigParameter(ThreadPoolConfigEntity threadPoolConfigEntity) {
String cacheKey = RegistryEnumVO.THREAD_POOL_CONFIG_PARAMETER_LIST_KEY.getKey() + ":" + threadPoolConfigEntity.getAppName() + ":" + threadPoolConfigEntity.getThreadPoolName();
RBucket<ThreadPoolConfigEntity> bucket = redissonClient.getBucket(cacheKey);
bucket.set(threadPoolConfigEntity, Duration.ofDays(30));
}
}因为其实管理端读取到的线程池数据都是从Redis中获取到的,所以也需要有一个定时任务更新注册中心的数据
@Slf4j
public class ThreadPoolDataReportJob {
private final IDynamicThreadPoolService dynamicThreadPoolService;
private final IRegistry registry;
public ThreadPoolDataReportJob(IDynamicThreadPoolService dynamicThreadPoolService, IRegistry registry) {
this.dynamicThreadPoolService = dynamicThreadPoolService;
this.registry = registry;
}
/**
* 每 10 秒上报一次线程池信息
*/
@Scheduled(cron = "0/10 * * * * ?")
public void execReportThreadPoolList() {
List<ThreadPoolConfigEntity> threadPoolConfigEntities = dynamicThreadPoolService.queryThreadPoolList();
registry.reportThreadPool(threadPoolConfigEntities);
log.info("动态线程池,上报线程池信息:{}", JSON.toJSONString(threadPoolConfigEntities));
for (ThreadPoolConfigEntity threadPoolConfigEntity : threadPoolConfigEntities) {
registry.reportThreadPoolConfigParameter(threadPoolConfigEntity);
log.info("动态线程池,上报线程池配置:{}", JSON.toJSONString(threadPoolConfigEntity));
}
}
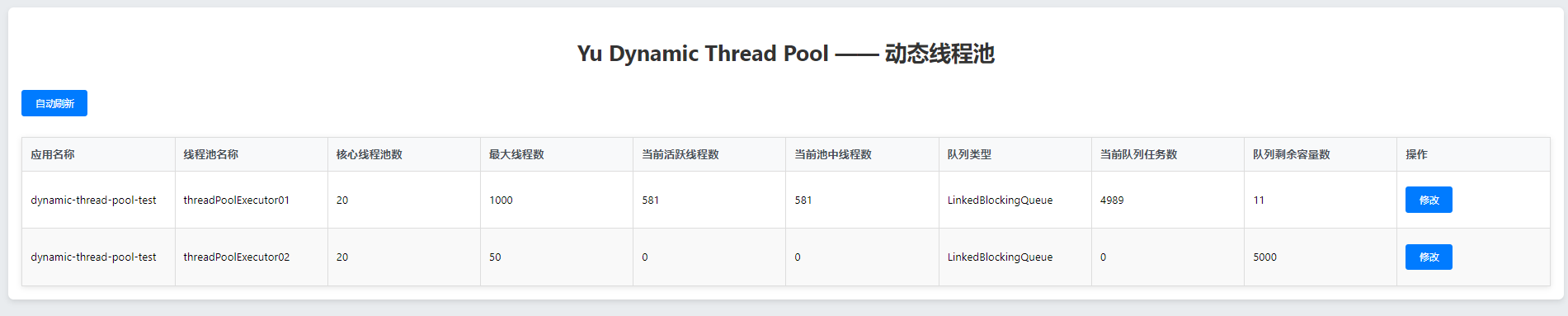
}5.3. 测试
这些写一个方法模拟线程执行
public ApplicationRunner applicationRunner(ExecutorService threadPoolExecutor01) throws InterruptedException {
return new ApplicationRunner() {
@Override
public void run(ApplicationArguments args) throws Exception {
while (true) {
Random random = new Random();
int randomInitialDelay = random.nextInt(3) + 1;
int randomSleepTime = random.nextInt(3) + 1;
threadPoolExecutor01.submit(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(randomInitialDelay);
log.info("Task started after " + randomInitialDelay + " seconds.");
TimeUnit.SECONDS.sleep(randomSleepTime);
log.info("Task executed for " + randomSleepTime + " seconds.");
} catch (Exception ex) {
Thread.currentThread().interrupt();
}
}
});
Thread.sleep(random.nextInt(10) + 1);
}
}
};
}修改前

修改最大线程数
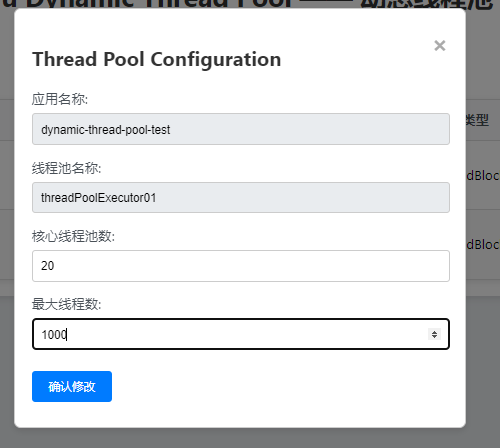
修改后