标题:少样本动作识别的时空关系建模
源文链接:Thatipelli_Spatio-Temporal_Relation_Modeling_for_Few-Shot_Action_Recognition_CVPR_2022_paper.pdf (thecvf.com)![]() https://openaccess.thecvf.com/content/CVPR2022/papers/Thatipelli_Spatio-Temporal_Relation_Modeling_for_Few-Shot_Action_Recognition_CVPR_2022_paper.pdf
https://openaccess.thecvf.com/content/CVPR2022/papers/Thatipelli_Spatio-Temporal_Relation_Modeling_for_Few-Shot_Action_Recognition_CVPR_2022_paper.pdf
源码链接:GitHub - Anirudh257/strm: [CVPR 2022] Official Pytorch Implementation for "Spatio-temporal Relation Modeling for Few-shot Action Recognition". SOTA Results for Few-shot Action Recognition[CVPR 2022] Official Pytorch Implementation for "Spatio-temporal Relation Modeling for Few-shot Action Recognition". SOTA Results for Few-shot Action Recognition - Anirudh257/strm![]() https://github.com/Anirudh257/strm 发表:CVPR-2022
https://github.com/Anirudh257/strm 发表:CVPR-2022
摘要
我们提出了一种新颖的少样本动作识别框架STRM,该框架在增强特定类别的特征判别性的同时,学习更高阶的时间表示。我们方法的核心是一个创新的时空丰富化模块,该模块通过专用的局部块级和全局帧级特征丰富化子模块来聚合空间和时间上下文。局部块级丰富化捕获基于外观的动作特征。另一方面,全局帧级丰富化明确编码广泛的时间上下文,从而随时间捕获相关的对象特征。然后,利用这些时空丰富化表示来学习查询和支持动作子序列之间的关系匹配。我们还在块级丰富化特征上引入了一个查询类相似度分类器,通过加强提出框架中不同阶段的特征学习来增强特定类别的特征判别性。我们在四个少样本动作识别基准数据集上进行了实验:Kinetics、SSv2、HMDB51和UCF101。我们广泛的消融研究揭示了所提出贡献的优势。此外,我们的方法在四个基准数据集上都达到了最先进的状态。在具有挑战性的SSv2基准测试中,与文献中现有的最佳方法相比,我们的方法在分类准确率上实现了3.5%的绝对提升。我们的代码和模型已公开可用,可在https://github.com/Anirudh257/strm上获取。
1. 简介
少样本(FS)动作识别是一个具有挑战性的计算机视觉问题,其任务是将未标记的查询视频分类到支持集中具有有限样本的每个动作类别之一。这个问题设置对于细粒度动作识别特别相关[11],因为收集足够多的标记样本是一个挑战[4, 5]。大多数现有的少样本动作识别方法通常搜索单个支持视频[31]或支持类别的平均表示[2, 3]。然而,这些方法仅利用帧级表示,并未明确利用视频子序列来进行时间关系建模。
在少样本动作识别的背景下,查询视频和有限的支持动作之间的时间关系建模是一个主要挑战,因为动作通常以不同的速度执行并发生在不同的时间点(时间偏移)。此外,视频表示需要编码由多个子动作构成的动作的相关信息,以增强查询视频和支持视频之间的匹配。此外,对动作的空间和时间上下文的有效表示对于区分需要时间关系推理的细粒度类别至关重要,在这些类别中,动作可以在不同的背景下使用不同的对象执行,例如,在某物后面泼洒某物。
上述时间关系建模问题最近被Temporal-Relational CrossTransformers(TRX)[19]所探索,TRX通过以基于部分的方式比较查询视频和支持视频的子序列来解决动作速度和偏移量变化的问题。此外,TRX通过将子序列表示为具有不同基数的元组来建模复杂的高阶时间关系。然而,TRX在处理使用不同对象和背景执行的动作时存在困难(见图1)。这可能是因为在时间关系建模过程中没有显式利用可用的丰富时空上下文信息。此外,TRX中的元组表示是固定的,需要为每个基数设置单独的CrossTransformer[7]分支,这影响了模型的灵活性。在这里,我们着手在建模查询和有限支持动作之间的时间关系时共同解决上述问题。
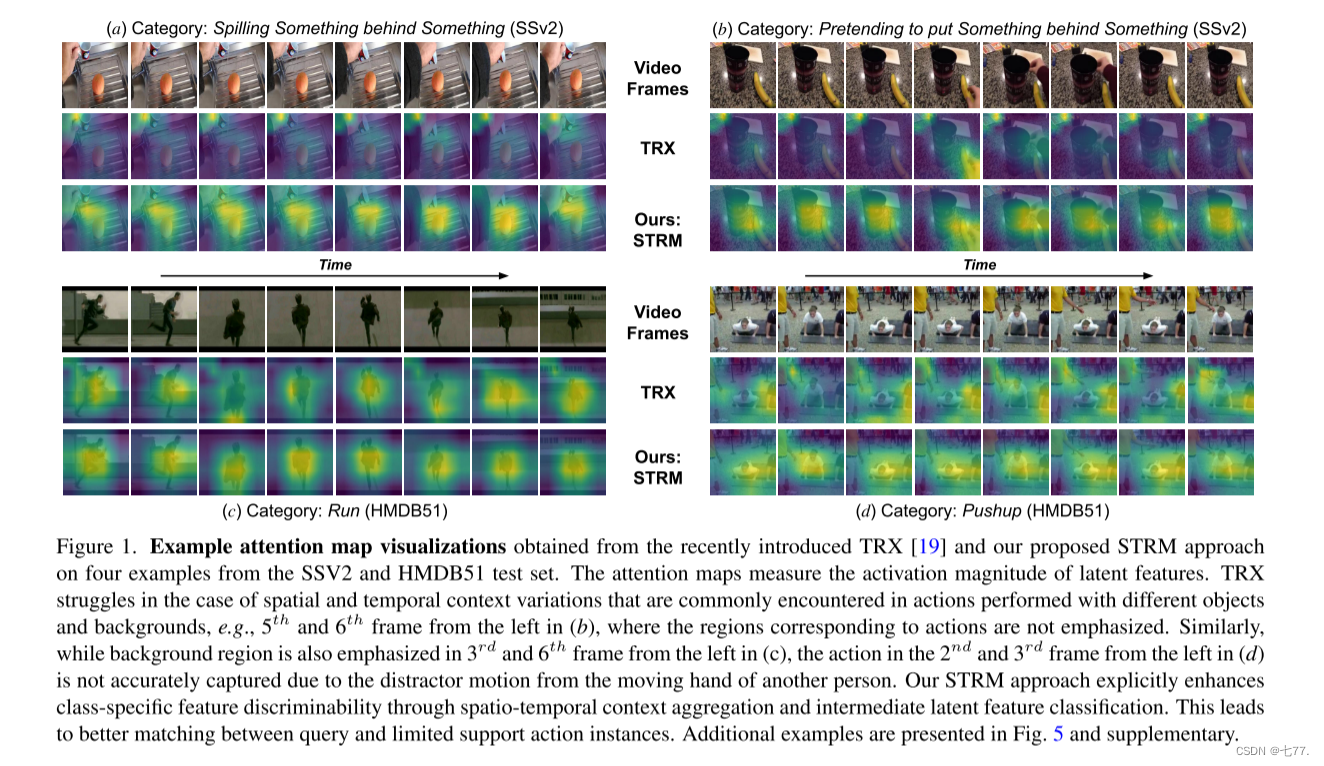
图1. 来自SSV2和HMDB51测试集的四个示例上,最近引入的TRX [19]和我们提出的STRM方法的注意力图可视化示例。这些注意力图衡量了潜在特征的激活程度。TRX在动作执行过程中常见的空间和时间上下文变化时表现不佳,这些变化通常与不同的对象和背景有关,例如(b)中从左数第五个和第六个帧,其中与动作相对应的区域并未得到强调。类似地,在(c)中从左数第三个和第六个帧中,背景区域也被强调了,但(d)中从左数第二个和第三个帧中的动作由于另一个人的移动手的干扰运动而没有被准确捕获。我们的STRM方法通过时空上下文聚合和中间潜在特征分类来明确增强特定类别的特征判别性。这导致了查询和有限的支持动作实例之间的更好匹配。更多示例见图5和补充材料中。
在这项工作中,我们认为帧中的局部块特征和视频中的全局帧特征都是有效丰富空间和时间上下文信息编码的理想线索。这种特征丰富化提高了特定类别的判别性,使模型能够关注视频中的相关对象及其对应的运动。此外,学习在不同阶段对特征表示进行分类有望加强模型寻找类可分特征的能力,从而进一步提高特定类别的判别性。而且,这种特定类别的判别性可以通过高阶时间关系的自动学习生成的较少基数组来实现。
我们在四个FS(少样本)动作识别基准测试集上进行了广泛的实验:Kinetics [4]、SSv2 [11]、HMDB51 [14] 和 UCF101 [23]。我们的大量消融实验表明,提出的时空丰富化和查询-类别相似度分类器都增强了特征的判别性,从而在基准测试上取得了显著的改进。时空丰富化模块进一步使得仅使用一个基数就能对时间关系进行建模。我们的方法在四个基准测试集上都优于文献中现有的FS动作识别方法。在具有挑战性的SSv2基准测试集上,使用ResNet-50作为主干网络时,我们的方法达到了68.1%的分类准确率,比最近引入的TRX [19]高出3.5%的绝对增益。图1展示了在SSv2和HMDB51示例上,我们的方法与TRX在注意力图可视化方面的比较。
2. 准备工作
问题定义:少样本(FS)动作识别的目标是将一个未标记的查询视频分类到“支持集”中的C个动作类别之一,其中每个类别包含K个在训练期间未见过的标记实例。为此,令Q = {q1, ..., qL}表示一个包含L帧的待分类查询视频,其将被分类到类别c ∈ C中。此外,令Sc表示动作类别c的支持集,其中包含K个视频,第k个视频表示为Sc^k = {sc^k1, ..., sc^kL}。为了简化,我们将每个视频表示为均匀采样的L帧序列。在这项工作中,我们遵循[16]中的情节训练范式,其中在每个情节中,从训练集中随机采样少样本任务来学习C类K次分类任务。接下来,我们将描述基准的FS动作识别框架。
2.1. 基本FS行动识别框架
在这项工作中,我们采用了最近引入的Temporal-relational CrossTransformer(TRX)[19]方法作为基准,该方法已在多个动作识别基准测试中取得了最先进的性能。TRX通过使用CrossTransformers[7]将查询视频与支持类视频中不同速度和瞬间发生的动作进行匹配来分类查询视频。首先,对于查询视频中的每个子序列,通过聚合动作类别支持视频中所有可能的子序列来计算特定于查询的类别原型。聚合权重基于查询子序列与支持类别子序列之间的交叉注意力值。之后,计算查询视频子序列的嵌入与其对应的特定于查询的类别原型之间的距离,并取平均值以获得查询到类别的距离。
TRX方法引入了手工制作的表示来捕获高阶时间关系,其中子序列通过基于用于编码子序列的帧数量的不同基数的元组来表示。例如,以ei ∈ RD作为第i帧的表示,位于ti和tj之间的子序列可以表示为一个对(ei, ej) ∈ R2D,一个三元组(ei, ek, ej) ∈ R3D,一个四元组(ei, ek, el, ej) ∈ R4D等,使得1≤i<k<l<j≤L。对于一个基数为ω ∈ Ω的元组t = (t1, ..., tω),令qt ∈ RD'为查询Qt = [et1; ...; etω] ∈ RωD的值嵌入,pct ∈ RD'为基于注意力聚合的支持元组Sckt ∈ RωD的值嵌入得到的特定于查询基数的类别原型。然后,查询视频Q和支持集Sc在多个基数上的距离由下式给出:
其中Πω = {(t1, ..., tω) ∈ Nω : 1 ≤ t1 < ... < tω ≤ L}是所有可能基数为ω的元组的集合。在训练过程中,通过使用标准的交叉熵损失来最小化从查询视频到其真实类别的距离T(·, ·)。更多细节,请参考[19]。
限制:如上所述,TRX在查询和支持动作子序列之间进行时间关系建模。然而,这种建模在面对空间上下文变化(查询视频和支持视频中相关对象的外观变化)以及与之相关的时间上下文变化(跨帧的空间上下文聚合)时表现不佳。这种变化通常在细粒度动作类别中遇到(见图1)。此外,TRX使用了多个CrossTransformers,每个不同基数对应一个,以基于子序列的不同手工制作时间表示来建模高阶时间关系。因此,这导致了一个不太灵活的模型,除了需要为不同基数设计专门的分支外,还需要手动搜索不同的Ω组合以找到最优的Ω*。接下来,我们将介绍我们提出的方法,该方法旨在综合解决上述问题。
3.提出的STRM方法
动机:在这里,我们介绍了一种少样本(FS)动作识别框架STRM,它致力于增强特定类别的特征辨别能力,同时缓解灵活性问题。
特征辨别能力:与仅关注时间关系建模的TRX不同,我们的方法强调了在建模时间关系之前,通过聚合空间和时间上下文来有效丰富视频子序列表示的重要性。通过局部表示来学习丰富的空间和时间关系,使得特征辨别能力得以增强,从而有效利用有限的样本进行少样本动作识别。
模型灵活性:如前所述,TRX使用不同基数的手工制作高阶时间表示,因此需要搜索多个组合。相反,我们的方法学习在低基数下以较低的归纳偏差来建模高阶关系,从而提高了模型的灵活性。
为了同时解决上述两个问题,我们引入了一种丰富机制,旨在增强局部块级别(空间)上单个帧的特征辨别能力,以及全局帧级别(时间)上视频本身的特征辨别能力,同时学习高阶时间表示以提高灵活性。
3.1. 整体架构
图2展示了我们的整体少样本(FS)动作识别框架STRM。L个视频帧通过图像特征提取器,输出具有P×P空间分辨率的D维帧特征。然后,帧特征在空间上进行展平以获得xi ∈ RP2×D,其中i∈[1, L],接着输入到我们新颖的空间时间丰富模块中,该模块包括块级别和帧级别的丰富子模块,以获取具有类别辨别性的表示。块级别丰富(PLE)子模块通过关注每帧中的空间上下文来局部增强块特征,并输出每帧的空间丰富特征fi ∈ RP2×D。对fi进行空间平均以获得D维帧级别表示,然后将它们连接起来形成H ∈ RL×D。接下来,帧级别丰富(FLE)子模块通过编码视频中不同帧的时间上下文来全局增强帧表示,并输出空间时间丰富的帧级别表示E∈RL×D。这些表示E被输入到时间关系建模(TRM)模块中,该模块通过将查询视频的子序列与支持动作进行匹配来分类查询视频。此外,通过引入查询类别相似性分类器对中间表示H进行分类,加强了在不同阶段学习相应的类别级别信息,并有助于进一步提高整体特征辨别能力。我们的框架通过使用标准交叉熵损失项LTM和LQC在TRM模块的类别预测和查询类别相似性分类器上联合学习。接下来,我们将介绍我们提出的空间时间丰富模块。
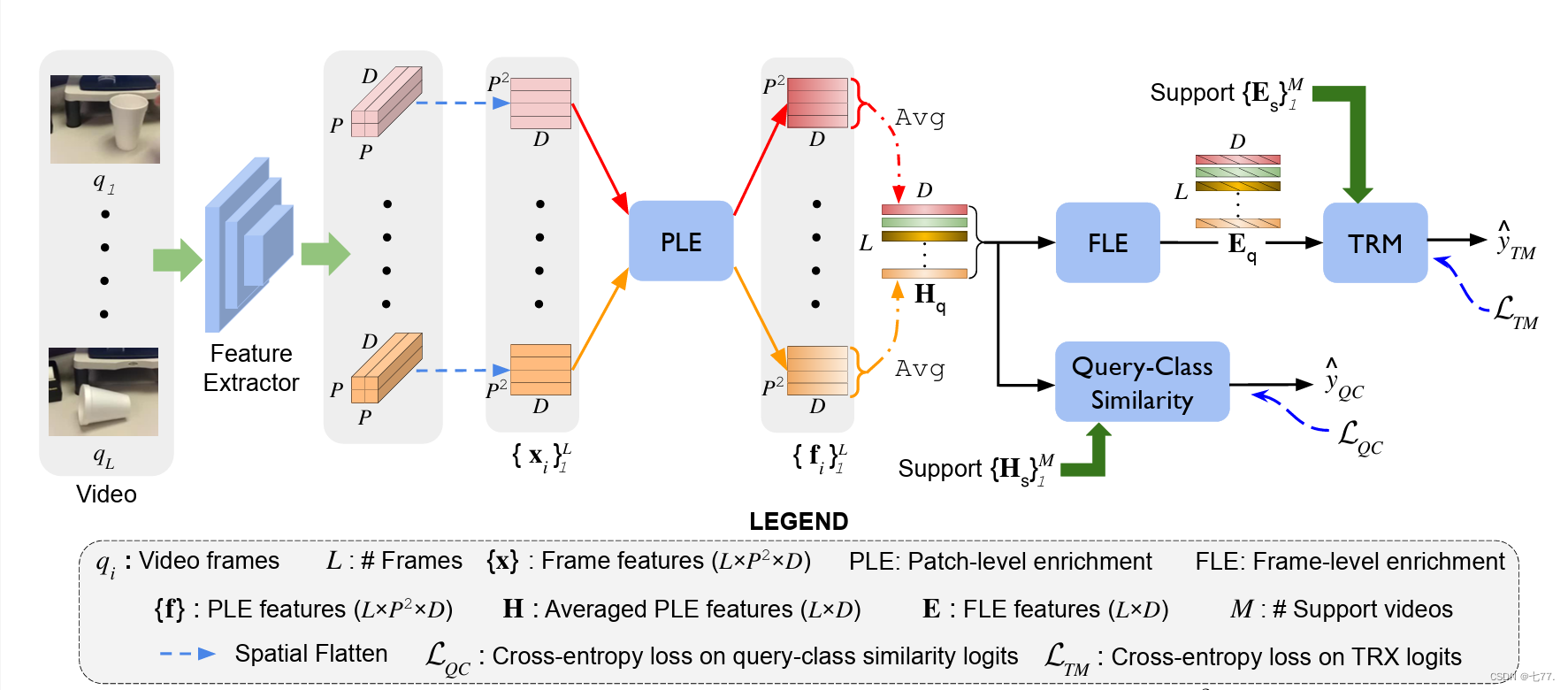
图2. 提出的STRM架构(第3.1节)。对于视频帧qi(i ∈ [1, L]),提取空间展平的D维特征xi ∈ RP2×D。这里,P2是块的数量。特征xi被输入到块级别丰富(PLE,第3.2.1节)模块中,该模块关注帧中块之间的空间上下文,并输出空间丰富的特征fi ∈ RP2×D。接下来,通过对fi进行空间平均和时间串联,获得全局表示H∈RL×D。然后,这些H被输入到帧级别丰富(FLE,第3.2.2节)模块中,该模块通过聚合视频中帧之间的动作时间上下文来建模高阶时间表示。查询视频和支持视频的时空丰富特征E∈RL×D随后被输入到TRM中,TRM建模它们之间的时间关系。此外,在全局表示H上应用查询类别相似性分类器(第3.3节)加强了网络在不同阶段学习类别辨别特征的能力。我们的框架通过使用LTM和LQC进行联合学习。
3.2. 时空丰富
我们方法的核心在于引入一个时空丰富模块,该模块致力于增强(i)单个帧中局部块特征的空间特性,以及(ii)视频中帧间全局帧特征的时间特性。通过在视频中有效利用空间和时间上下文信息,可以在建模查询视频和支持视频之间时间关系之前,提高类别特定特征的辨别能力。
3.2.1丰富局部块特征
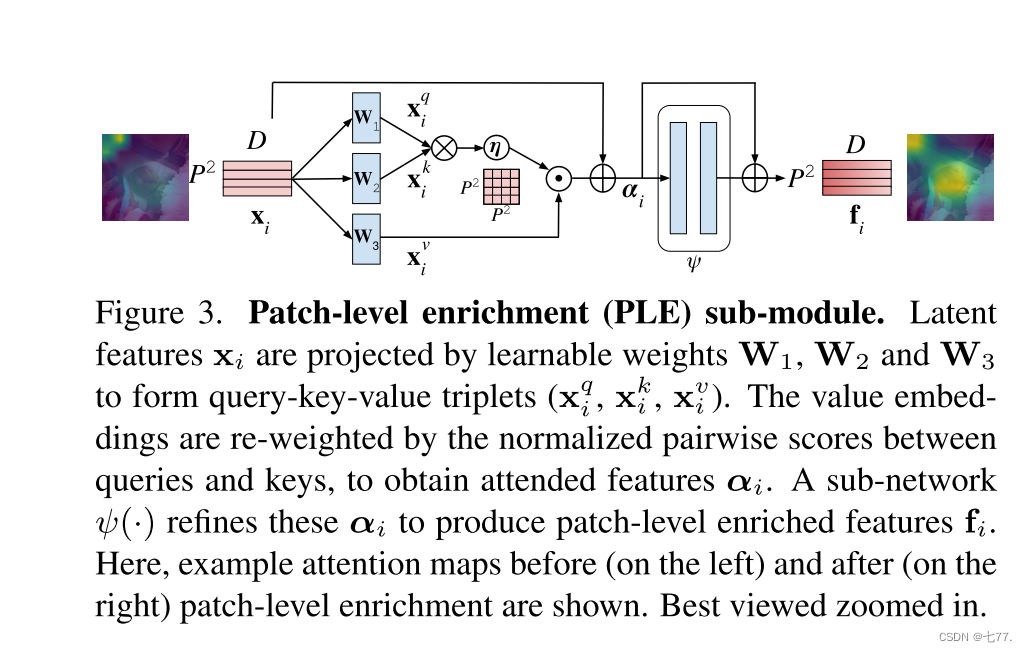
图3. 块级别丰富(PLE)子模块。通过可学习权重W1、W2和W3将潜在特征xi投影以形成查询-键-值三元组(xq_i, xk_i, xv_i)。值嵌入通过查询和键之间的归一化成对得分进行重加权,以获得关注的特征αi。一个子网络ψ(·)细化这些αi以生成块级别的丰富特征fi。在这里,展示了块级别丰富之前(左侧)和之后(右侧)的示例注意力图。放大查看效果最佳。
帧中的块特征共同编码了其空间信息。增强这些特征以编码帧中所有块之间的帧级空间上下文是必要的,以捕获基于外观的相似性以及不同动作类别之间的差异。为此,我们引入了一个块级别丰富(PLE)子模块,它采用自注意力机制[27],使块特征通过聚合一致的块上下文来关注自身。PLE子模块如图3所示。设xi ∈ RP2×D表示帧qi(i ∈ [1, L])中P2个块的潜在特征。权重W1, W2, W3 ∈ RD×D将这些潜在特征投影以获得查询-键-值三元组,表示为:
当值嵌入保持块p ∈ [1, P2]的当前状态时,查询和键向量对P2个块之间的两两成对的相似性进行评分。这些值嵌入通过相应的归一化分数重新加权以获得“令牌混合”(关注)特征αi,表示为:
其中η表示softmax函数。然后,一个子网络ψ(·)逐点细化这些关注的特征αi ∈ RP2×D,并输出空间丰富的特征fi ∈ RP2×D,表示为:
这有助于改进帧中基于外观的动作上下文在块之间的聚合(见图5第三行)。
3.2.2丰富全局框架特性
上述描述的局部块级别丰富(PLE)旨在在一个动作视频的每帧内部局部地聚合空间上下文,这使得我们能够关注帧中的相关对象。然而,它并没有明确地编码时间上下文,因此在遇到随时间变化的对象运动时会出现困难(见图5)。在这里,我们通过引入一个包含MLP混合器[25]层的帧级别丰富(FLE)子模块,来继续在整个视频帧间全局地丰富时间上下文。虽然自注意力是基于令牌之间的成对相似性指导的依赖于样本(特定于输入)的混合,但MLP混合器中的令牌混合通过输入无关且持久的关系记忆来同化整个全局感受野。这种令牌的全局同化使得MLP混合器更适合于丰富全局帧表示。FLE子模块如图4所示。对于帧qi,设hi ∈ RD是通过空间平均PLE输出fi ∈ RP2×D得到的全局表示。然后,整个视频的拼接全局表示H = [h1; ... ; hL]⊤ ∈ RL×D通过FLE子模块进行处理。首先,通过跨通道(特征维度)共享的两层MLP Wt(·)混合帧令牌。接着,利用跨令牌共享的另一个两层MLP Wr(·)对中间特征H∗进行令牌细化。FLE中的两个混合操作由以下公式给出:
其中,E ∈ RL×D 是丰富后的特征,Wt1, Wt2 ∈ RL×L 和 Wr1, Wr2 ∈ RD×D 分别是用于令牌混合和通道混合的可学习权重。在这里,σ 表示 ReLU 非线性激活函数。特别是,令牌混合操作确保了帧表示通过可学习权重 Wt1 和 Wt2 相互交互并吸收高阶时间关系。因此,FLE 子模块在时间上增强了帧表示 hi,具有包含所有帧的全局感受野,并为 i ∈ [1, L] 生成了时间上丰富的表示 ei。
对于查询视频和支持视频,丰富后的帧级别全局表示 ei(i ∈ [1, L])随后被输入到时间关系建模(TRM)模块中,该模块建模查询动作和支持动作之间的时间关系。在我们的框架中,TRM 是一个基于单个基数 Ω = {2} 的 TRX(等式 1),因为我们的时空丰富模块学习建模高阶时间表示,而无需多个手工制作的基数表示。给定真实标签 y ∈ RC,我们的框架随后使用 TRM 预测的类别概率 ˆyTM ∈ RC 上的标准交叉熵(CE)损失进行端到端学习,由下式给出:
总之,我们的时空丰富模块利用局部和全局、依赖于样本和与样本无关的丰富机制的优点,以改进动作的空间和时间上下文的聚合。因此,在较低基数的表示中获得了特定于类别的判别特征以及高阶时间关系的同化。
3.3. 查询类别相似度
如上所述,所提出的框架由特征提取器、时空丰富化以及时间关系建模模块组成,这些模块是通过在输出概率 ˆyTM 上的交叉熵(CE)损失进行端到端学习的。然而,从中间层输出学习分类查询视频表示,加强了模型在管道不同阶段寻找特定类别特征的能力。因此,这种多阶段分类提高了特征的判别性,从而改善了查询视频与支持视频之间的匹配。为此,我们在块级别的丰富化表示 hi(i ∈ [1, L])上引入了一个查询-类别相似度分类器。首先,我们为视频中的元组 t = (t1, · · · , tω) ∈ Πω 获取潜在元组表示 lt = [ht1; · · · ; htω] ∈ RωD。然后,它们通过 Wcls ∈ RωD×D′′ 进行投影,得到 zt = σ(W⊤clslt),其中 σ 是 ReLU 非线性激活函数。接着,对于查询视频 Q 中的每个 zQt,计算它与 K 个支持视频中所有元组在动作类别 c 下的最高相似度。查询 Q 中所有元组的这些得分被聚合起来,以获得查询与类别 c 之间的查询-类别相似度 M(Q, c)。以 zcj 表示来自 K 个支持视频的一个动作 c 的元组 j ∈ [1, K · |Πω|],查询-类别相似度由下式给出:
其中 ϕ(·, ·) 是一个相似度函数。然后,这 C 个相似度得分通过 softmax 层获得类别概率 ˆyQC ∈ RC,并通过以下交叉熵(CE)损失进行训练:
使用 λ 作为超权重,我们的 STRM(时空关系建模模块)通过以下联合公式进行训练:
因此,我们提出的 STRM,包括一个时空丰富化模块和一个中间查询-类别相似度分类器,增强了特征的判别性(见图 5),并改善了查询与其支持动作类别之间的匹配。
4. 实验
数据集:我们的方法在四个流行的基准测试集上进行了评估:Something-Something V2(SSv2)[11]、Kinetics[4]、HMDB51[14]和UCF101[23]。SSv2是一个众包数据集,具有挑战性,并且其中的动作需要时序推理。对于SSv2,我们使用[3]中给出的训练/验证/测试集中的64/12/24个动作类别的划分。对于Kinetics,我们使用与[3, 34]相同的64/12/24个动作类别的划分。此外,我们使用[31]中的划分在HMDB51和UCF101上进行评估。在所有数据集上都采用了标准的5次5样本评估,并报告了10,000个随机测试任务的平均准确率。
实现细节:与[3, 19]类似,我们使用在ImageNet[6]上预训练的ResNet-50[12]作为视频L=8个均匀采样帧的特征提取器。在D=2,048的情况下,使用自适应最大池化将空间分辨率降低到P=4。PLE和FLE中的所有可学习权重矩阵都实现为全连接(FC)层。PLE中的子网络ψ(·)是一个3层FC网络,潜在大小设置为1,024。我们为Wcls设置D''=1,024。对于TRM,我们在等式1中使用Ω={2},并设置D'=1,152,如[19]所示。超权重λ设置为0.1。对于SSv2数据集,我们使用75,000个随机采样的训练片段进行学习率为10−3的训练,而较小的数据集则使用10−4的学习率进行训练。我们的STRM框架使用SGD优化器进行端到端训练。
4.1. 最先进的比较
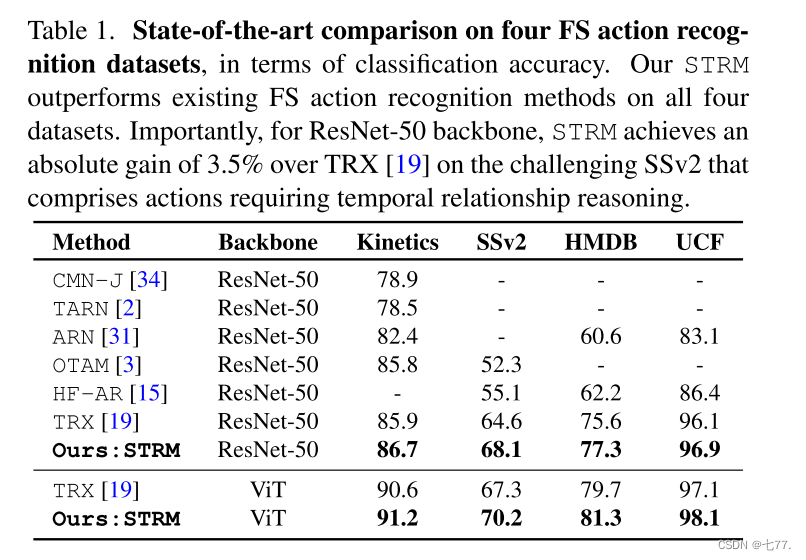
表1展示了在四个基准测试集上,针对标准的5次5样本动作识别任务的最新方法比较。为了公平起见,表1中仅比较了使用2D主干网络提取每帧特征的方法。在Kinetics上,最近的OTAM[3]和TRX[19]工作达到了相当的分类准确率,分别为85.8%和85.9%。我们的STRM通过实现86.5%的改进性能,优于现有方法。在更具挑战性的SSv2数据集上,该数据集包含需要时序关系推理的动作,OTAM和HF-AR[15]分别实现了52.3%和55.1%的准确率,而TRX由于其时序关系建模,获得了64.6%的准确率。与现有最佳方法TRX相比,我们的STRM在SSv2上取得了显著的3.5%的绝对提升。类似地,我们的STRM在HMDB51和UCF101上也取得了改进的性能,在所有四个基准测试集上都达到了新的最佳状态。为了进一步评估我们的贡献,我们将ResNet-50替换为ViT[8]作为主干网络。即使使用这种更强大的主干网络,我们的STRM也在所有数据集上都优于TRX。此外,当使用3D ResNet-50和MViT[9]作为主干网络时,我们的STRM在SSv2上相对于TRX分别获得了1.5%和1.9%的提升。请注意,3D ResNet-50和MViT是在Kinetics400[4]上预训练的,并且由于预训练类别可能与新类别重叠,因此它们并不总是与少样本动作数据集兼容。我们STRM的持续改善强调了通过结合局部(依赖于样本的)块级和全局(不依赖于样本的)帧级丰富化以及查询类相似性分类器来增强时空特征,对于少样本动作识别的有效性。
4.2. 消融研究
所提出贡献的影响:在这里,我们系统地分析了所提出的时空增强模块以及查询类分类器的影响。请注意,我们的时空增强模块包括PLE(局部特征增强模块)和FLE(帧级特征增强模块)两个子模块。图6(左)展示了在SSv2数据集上,当在基线TRM(时间关系模块)中整合我们的两个贡献(时空增强模块和查询类分类器)时的性能比较。注意,基线TRM是一个具有基数Ω={2}的TRX[19]。基线TRM实现了62.1%的少样本动作分类准确率(红色条)。在基线中整合我们的PLE,以在时序建模之前丰富局部块级特征中的空间上下文,准确率提高到63.7%(橙色条)。类似地,仅通过在TRM中整合FLE(绿色条)来丰富全局帧级特征中的时序上下文,准确率提高了3.2%。此外,在TRM中联合整合PLE和FLE(浅蓝色条)可以进一步增强特征中的时空上下文,从而提高了66.8%的准确率。最后,在我们的方法中整合查询类分类器加强了不同阶段类可分特征的学习,并进一步提高了特征的判别能力,因此实现了68.1%的优异性能。最终的STRM框架(蓝色条)相对于基线(红色条)实现了6.0%的绝对提升。
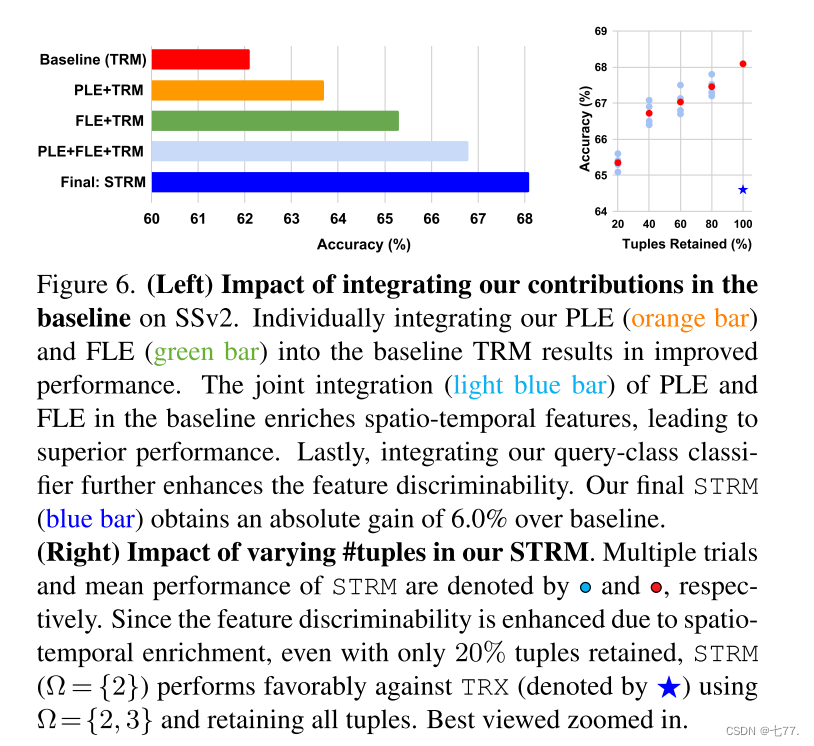
图6.(左)在SSv2数据集上,将我们的贡献集成到基线模型中的影响。单独将我们的PLE(橙色条)和FLE(绿色条)集成到基线TRM(时间关系模块)中,均能提高性能。在基线中联合集成PLE和FLE(浅蓝色条)丰富了时空特征,从而实现了卓越的性能。最后,集成我们的查询类分类器进一步增强了特征的判别力。我们最终的STRM(蓝色条)相较于基线获得了6.0%的绝对提升。
(右)我们STRM中不同元组数量的影响。STRM的多次试验和平均性能分别由空心圆和实心圆表示。由于时空特征的丰富性增强了特征的判别力,即使仅保留20%的元组,使用基数Ω={2}的STRM也能与使用基数Ω={2, 3}并保留所有元组的TRX(由星号表示)相媲美。建议放大观看以获得最佳效果。
基数变化的影响:表2展示了在我们的STRM(时空关系模块)中,建模时序关系时基数变化的影响。这里对Kinetics和SSv2数据集进行了比较,并展示了相应基数组合中存在的元组数量。我们观察到,即使在较低的基数下,我们的STRM也能达到最佳性能。特别是,当基数Ω={2}时,我们的STRM在两个数据集上都取得了最佳性能。相比之下,TRX使用手工设计的高阶时序表示需要Ω={2, 3}才能在SSv2上达到其最优性能64.6%。此外,值得一提的是,我们的STRM在计算量上与TRX相当,仅需要大约4%的额外浮点运算量(FLOPs)。我们的方法在较低基数下优于TRX的性能,是因为通过时空特征增强以及FLE子模块中的token(令牌)混合引起的高阶时序表示学习,实现了增强的特征判别力。

元组数量变化的影响:图6(右)展示了在SSv2数据集上,我们的STRM方法在保留不同数量的元组以匹配查询和支持视频时的性能。我们观察到,当保留的元组数量减少时,性能略有下降。但是,即使在较低的基数(Ω={2})下仅保留20%的元组时,我们的STRM也能达到65.4%的准确率,并且优于TRX的64.6%,而TRX依赖于多个基数(Ω={2, 3})下的所有元组。这表明,我们的时空增强模块与查询类分类器相结合,在较低的基数下学习高阶时序表示时,就能增强特征的判别力。因此,我们的STRM提供了更好的模型灵活性,而无需为不同的基数设置专门的TRM分支。
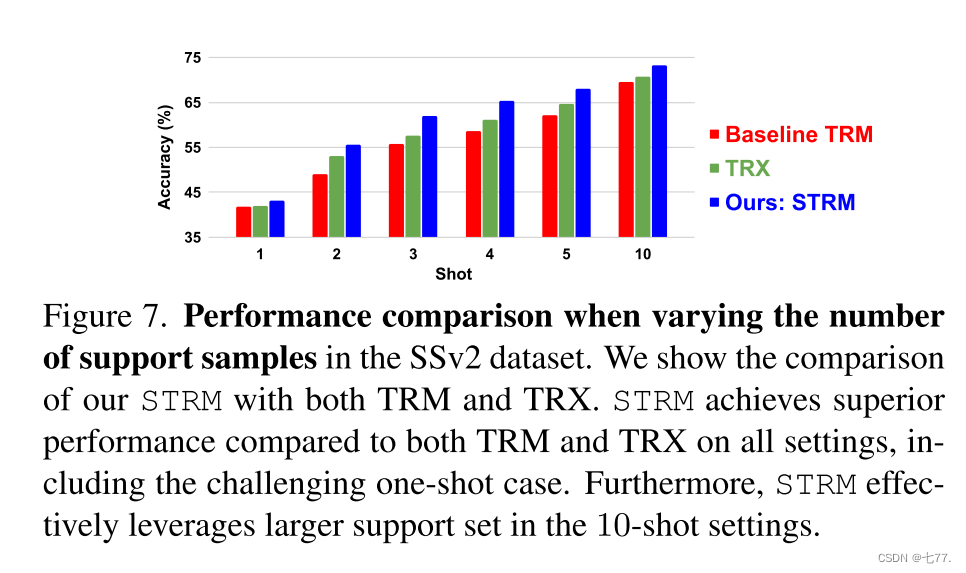
与不同数量的支持样本的比较:图7展示了在SSv2数据集上,当改变支持样本数量时,STRM与基线和TRX的比较结果。这里,我们展示了K次(K ≤ 5和10)分类的结果。相比TRM和TRX,在所有K次设置的情况下,我们的STRM都取得了持续的性能提升。特别地,我们的STRM在极端的单次学习情况以及10次学习设置中均表现出色,它有效地利用了更大的支持集。在补充材料中提供了额外的结果。
5. 与现有技术的关系
多项工作已经研究了图像分类[1, 7, 10]、目标检测[13, 29]和分割[17]中的少样本(FS)问题。早期的方法要么是基于适应的[18]、生成的[32],或者是基于度量的[22, 28],而最近的工作[7, 21]则结合了这些方法的优点。在少样本动作识别的背景下,[33, 34]采用记忆网络来表示关键帧,而[2]则对齐变长查询和支持视频。与此不同,[3]利用单调时间顺序来强制视频对之间的时间一致性。最近的工作TRX[19]专注于通过利用固定的高阶时序表示来建模时序关系。与TRX不同,我们的STRM引入了一个时空增强模块来产生时空增强的特征。时空增强模块通过使用自注意力层[20, 27, 30]在局部块级别上丰富特征,同时利用MLP混合器层[24-26]在全局帧级别上丰富特征。我们的时空增强也使得在较低的基数下学习高阶时序表示成为可能。所提出的时空增强模块在少样本动作识别框架中,使用自注意力层进行局部块级别的增强,并通过集成MLP混合器进行全局帧级别的增强。此外,我们还引入了一个查询类分类器来学习从中间层分类特征表示。
6. 讨论
我们提出了一个少样本(FS)动作识别框架STRM,该框架包括时空增强和时序关系建模(TRM)模块,以及一个查询类相似度分类器。我们的STRM通过结合局部和全局、依赖于样本和不依赖于样本的增强机制来增强时空特征,并在不同阶段加强特征的类可分离性。因此,这增强了时空特征的判别力,并允许在较低基数的表示中学习高阶时序关系。我们广泛的消融研究揭示了所提出贡献的益处,在所有基准测试中均取得了最先进的结果。一个可能的未来方向(超出当前工作的范围)是将少样本动作识别能力扩展到跨不同领域的泛化。
读后总结
乍一看内容好像很丰富,仔细一看,感觉没什么创新,在5,6中有概括。


![[17] 使用Opencv_CUDA 进行滤波操作](https://img-blog.csdnimg.cn/direct/0b3071cbfb7048d6b71b4b57964702fb.png)