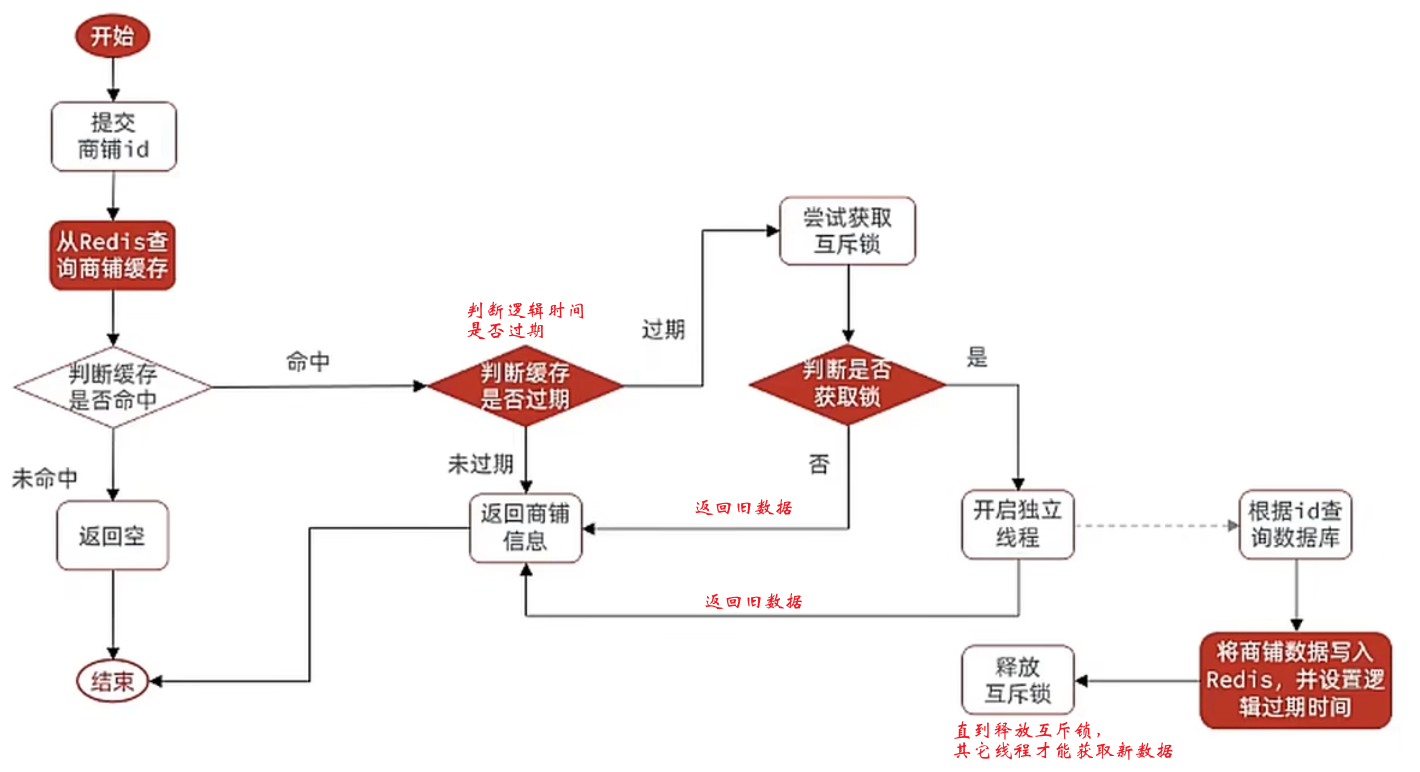
引言
今天带来论文Are Large Language Models All You Need for Task-Oriented Dialogue?的笔记。
主要评估了LLM在完成多轮对话任务以及同外部数据库进行交互的能力。在明确的信念状态跟踪方面,LLMs的表现不及专门的任务特定模型。然而,如果为它们提供了正确的槽值,它们可以通过生成的回复引导对话顺利结束。
1. 总体介绍
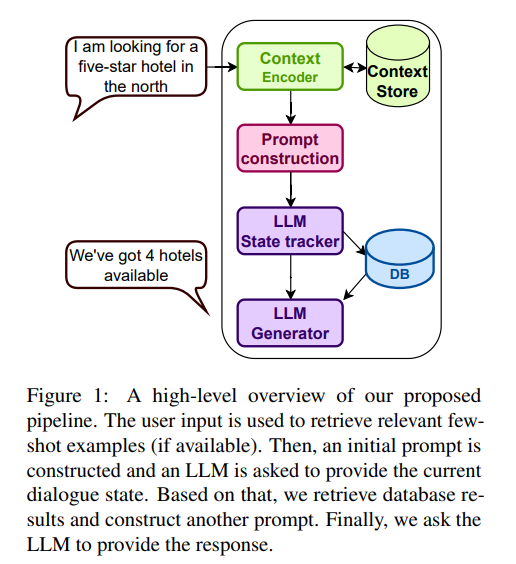
本篇工作在任务导向对话(Task Oriented Dialouge,TOD)上评估LLM的性能。为此引入了基于LLM的TOD对话流水线(图1)。使用状态跟踪和响应生成作为两个主要的步骤,隐含了对话策略的功能。在零样本设定下,模型仅接收领域描述,在少样本设定下,使用了一些检索到的示例。在https://github.com/vojtsek/to-llm-bot上发布了实验代码。
2. 相关工作
介绍了大语言模型和指令微调。 重点是下面两个:
基于语言模型的TOD建模 Zhang等人和Peng等人引入了基于预训练语言模型的任务导向对话建模,他们遵循了Lei等人提出的基于文本的状态编码和两阶段生成方法:首先使用语言模型解码结构化的信念状态,表示为文本。然后使用信念状态检索数据库信息,并再次调用语言模型生成响应,该响应以信念状态和检索到的信息为条件。其他人则提出了生成模型与检索式方法的结合。这些方法都在领域内的数据上进行了微调,和作者采用的纯上下文学习方法形成了对比。
少样本对话建模 是一种专注于从少量领域内样例中学习对话的神经模型的方法之一,最早的这种方法是基于循环神经网络的可训练混合代码网络,其中部分组件采用手工制作。较新的方法利用了预训练Transformer语言模型的能力。Hu等人使用了LLMs和上下文学习来进行信念状态跟踪,将任务制定为SQL查询生成。
3. 方法
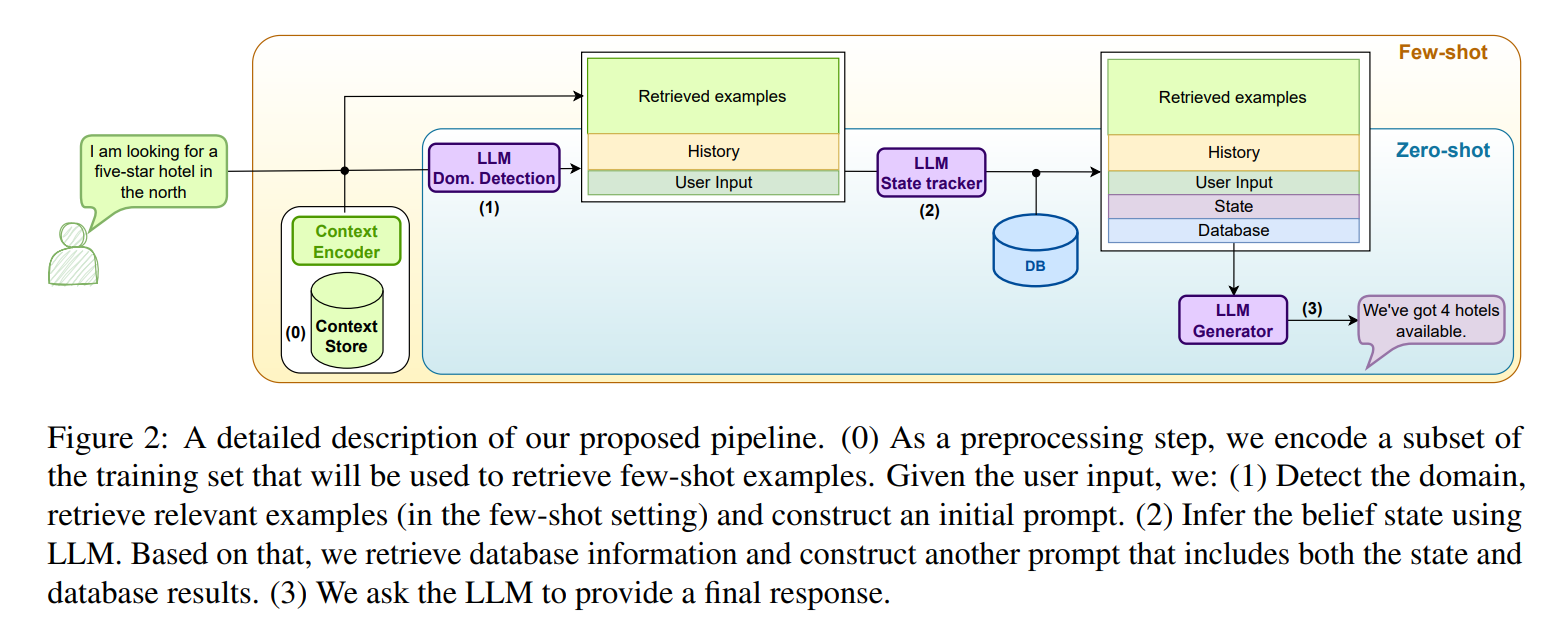
图2显示了所提出的流程的总体描述。系统由预训练的LLM和(可选的)上下文存储在向量数据库中组成。在每个对话轮次中执行三次LLM调用,使用特定的提示。首先,LLM执行领域检测和状态跟踪。更新后的信念状态用于数据库查询,并将查询结果用于后续基于LLM的响应生成步骤。在少样本设置中,上下文存储用于存储训练集中的有限数量的示例,这些示例根据与对话上下文的相似性进行检索,并包含在LLM提示中。
3.1 提示词构建
目标是比较所选LLMs的原始能力,因此作者不关注提示工程技术,并选择在本工作中所有LLMs都使用的通用提示。为所有示例定义一个单一领域检测提示,以及给定数据集中每个领域的一对提示:状态跟踪提示(见表1)和响应提示。

Definition: 从关于酒店的对话中提取实体与值。
以冒号分隔的"实体:值"形式呈现。
不要在冒号之间加入空格。
使用连字符分隔不同的"实体:数值"对。
需要提取的数值有:
- "pricerange":酒店的价格
[对话历史]
顾客:"我想找一个便宜的住所。"
领域检测提示包括任务描述和两个静态领域检测示例。除了一般指令外,每个状态跟踪提示包含领域描述、相关槽位列表、对话历史记录和当前用户话语。响应提示不包含每个领域的槽位列表,但是代替的它们包含当前的信念状态和数据库结果。在少样本设置中,每个跟踪和响应提示还包含从上下文存储中检索的正例和负例示例。提示示例详见附录的表5和表6。
3.2 领域检测和状态追踪
在状态跟踪过程中,每轮对LM进行两次提示:首先,检测当前活动(active,激活)的领域,然后输出在当前轮次中发生变化或出现的槽值。然后,使用这些输出来更新累积的全局信念状态。
使用两个提示步骤是因为需要模型在多个领域的情况下进行操作,即处理跨多个领域的对话。因此,需要能够检测当前活动的领域。通过首先使用一个领域检测的提示来实现这一点。
一旦获得了活动领域的预测,可以在处理信念状态预测的第二个提示中包含手动设计的领域描述。表1提供了一个用于状态跟踪的提示示例。对于少样本变体,从上下文存储中检索与活动领域相关的少样本示例。
初步实验表明,LLMs很难在每个轮次中始终输出所有活动的槽值。因此,只建模状态更新,采用MinTL方法。在这种方法中,模型只生成在当前轮次中发生变化的槽-值对。然后,使用这些轮次级别的更新来累积全局信念状态。为了获得机器可读的输出,以便用于数据库查询或API调用,在提示中指定模型应该提供JSON格式的输出,并且提供的少样本示例也相应进行了格式化处理。
3.3 响应生成
当前的信念状态用于查询数据库,以找到与活动领域中所有用户指定的槽位匹配的条目。根据信念状态和数据库结果,可以直接生成响应。给定的LLM提示包括对话历史、用户话语、信念状态和数据库结果(以及在少样本设置中检索到的示例),并要求模型提供一个合适的系统响应。
生成去标记化的响应,即用占位符替换槽位值。除了简化模型的任务外,去标记化的输出还使我们能够评估成功率。提示指定模型应将实体值作为去标记化的占位符提供,并相应构建任何少样本示例。
3.4 上下文存储
引入了一个包含编码对话上下文的存储。这个上下文存储是可选的,只在少样本提示变体中需要。使用来自固定长度历史窗口的对话上下文作为要编码到向量数据库中的键。一旦检索到相关示例,将它们包含在提示中以更好地指导模型。一些LLM还依赖于负面(对立地)示例。因此,采用了Peng等的一致性分类任务方法来生成负面示例:采用一些检索到的信念状态示例,通过将一些正确的槽值替换为随机值来破坏它们,并将它们作为负面示例呈现在提示中。
4. 实验设定
5. 实验结果
5.1 领域检测
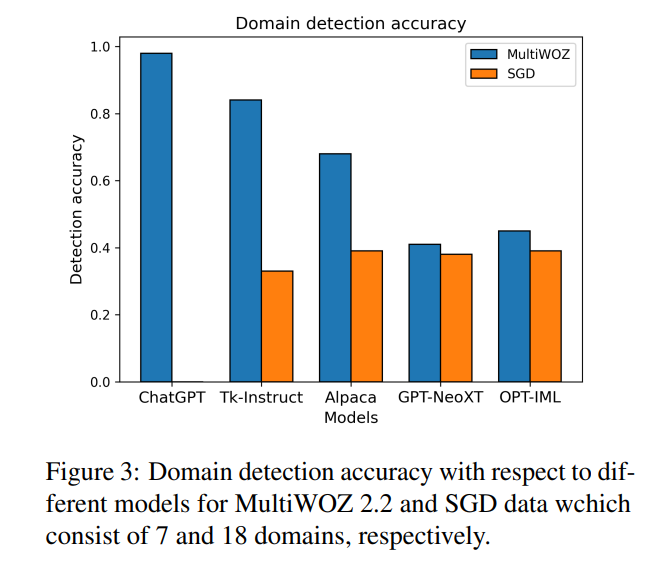
各种模型的领域检测准确率差异很大,这很可能会影响检索到的少样本示例的质量和后续提示的适当性。然而,领域检测是基于轮次的,有一些情况(例如提供地址、道别等)总是以相同的方式处理,即使它们在形式上属于不同的领域。因此,并非所有来自被错误分类的领域的检索示例一定包含无关的上下文。
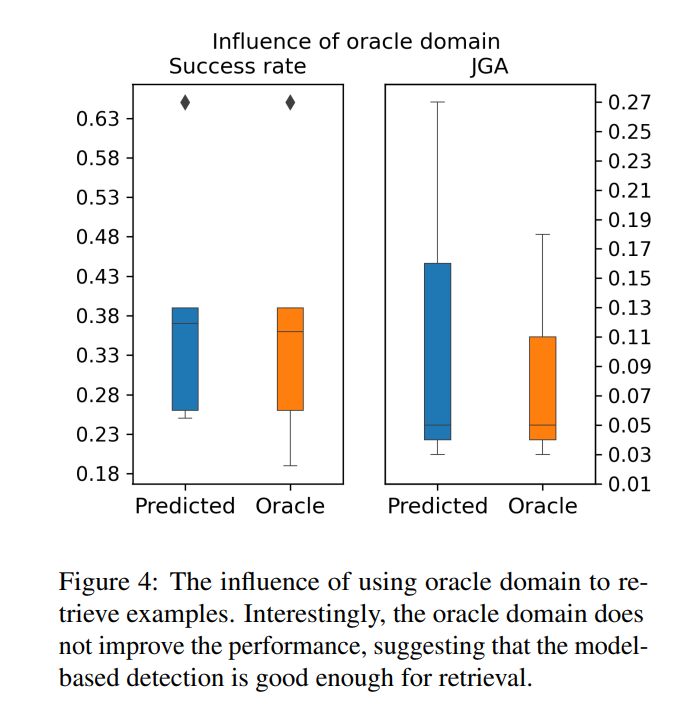
使用理论上正确的领域并没有提高性能,甚至在某些情况下性能变差。这表明模型预测的领域通常已经足够好,并且额外提供领域信息并不会对最终的系统性能产生贡献。
5.2 信念状态跟踪

在比较各个模型的结果时,ChatGPT明显优于其他模型。少样本与零样本设置似乎并不对结果产生很大影响,除了GPT-NeoXT模型。
5.3 响应生成
总体而言,BLEU分数较低,远低于监督式最先进模型。Tk-Instruct和ChatGPT在这方面是最强的,并且表现大致相当。
5.4 对话级表现
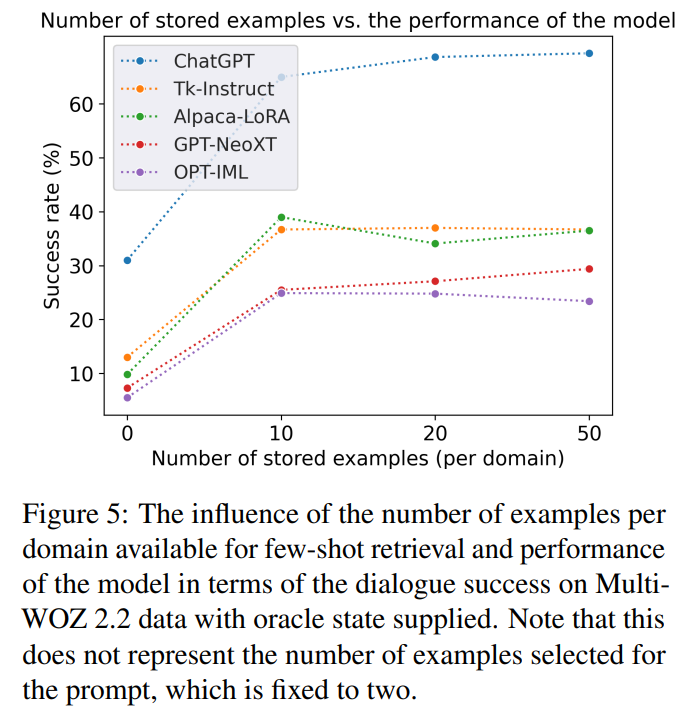
对话成功的结果在表2中提供,LLMs和监督式自定义模型的性能之间存在较大差距。ChatGPT似乎优于其他模型,与状态跟踪类似。然而,在零样本设置中,差异并不那么明显。在大多数情况下,添加检索到的少样本示例是有帮助的。当提供理论上正确的信念状态时,检索示例的贡献更为明显,这种情况下对于所有模型都有帮助。图5探讨了上下文存储大小对对话成功率的影响。似乎通过仅提供少量示例而不是零样本提示可以实现最大的改进,但增加用于检索的示例池的大小并不会带来进一步的性能提升。
6 模型分析
介绍了人工评估和错误分析。
错误行为可以分为可恢复的提示错误和固有错误,前者可以通过提示工程修复,后者属于不容易通过提示工程修复的错误,比如幻觉和不相关的内容。
7 结论
即使在提供上下文中的少样本示例的情况下,LLM在信念状态跟踪方面表现不佳。如果提供正确的信念状态,模型可以成功地与用户进行交互,提供有用的信息并满足用户的需求。因此,精心选择代表性示例并将LLM与领域内的信念跟踪器结合起来,可以成为任务导向型对话流程中可行的选择。
8. 限制
模型对特定提示的选择很敏感。具体而言,信念状态的期望格式在模型之间有所变化,并且存在一些模型特定的指令。
A 提示词构建



总结
⭐ 作者测试了基于LLM做领域识别、状态追踪和响应生成。但是状态追踪的效果不好,如果想用LLM做TOD需要额外加入状态追踪逻辑。





![[leetcode hot 150]第十五题,三数之和](https://img-blog.csdnimg.cn/direct/cb45550577ee47baa1b796fc6063d0d9.png)