对于分类预测学习任务,从指定的数据源读取数据,对数据进行必要的处理,选取合适的特征,构造分类模型,确定一个人的年收入是否超过50K。
数据来源:1994年美国人口普查数据库。数据存放在data目录中,其中,adult.data存放训练数据,adult.test存放测试数据。
(下载地址:https://archive.ics.uci.edu/ml/datasets/Adult )
特征列介绍:
age:年龄,整数
workclass:工作性质,字符串,包含少数几种取值,例如:Private、State-gov等
education:教育程度,字符串,包含少数几种取值,例如:Bachelors、Masters等
education_num:受教育年限,整数
maritial_status:婚姻状况,字符串,包含少数几种取值,例如:Never-married、Divorced等
occupation:职业,字符串,包含少数几种取值,例如:Sales、Tech-Support等
relationship:亲戚关系,字符串,包含少数几种取值,例如:Husband、Wife等
race:种族,字符串,包含少数几种取值,例如:White、Black等
sex:性别,字符串,包含少数几种取值,例如:Female, Male
capital_gain:资本收益,浮点数
capital_loss:资本损失,浮点数
hours_per_week:每周工作小时数,浮点数
native_country:原籍,包含少数几种取值,例如:United-States, Mexico等
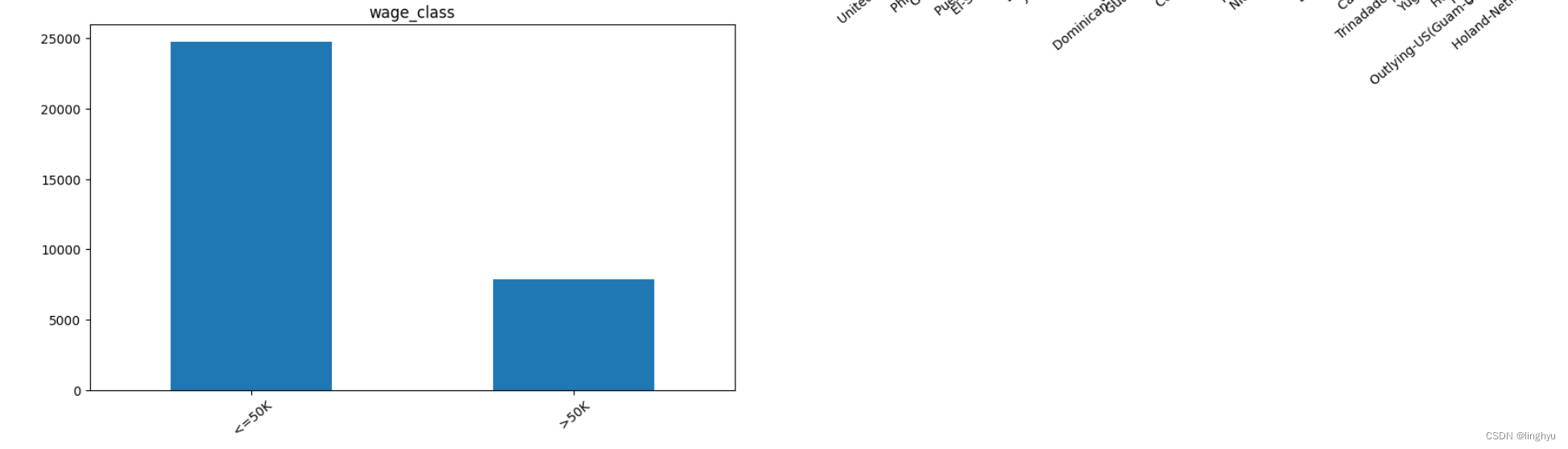
分类标签列:income >50K ≤50K
数据探查
熟悉数据,查看数据结构和数据分布情况
- 读取数据文件,查看行列信息

行列信息结果:
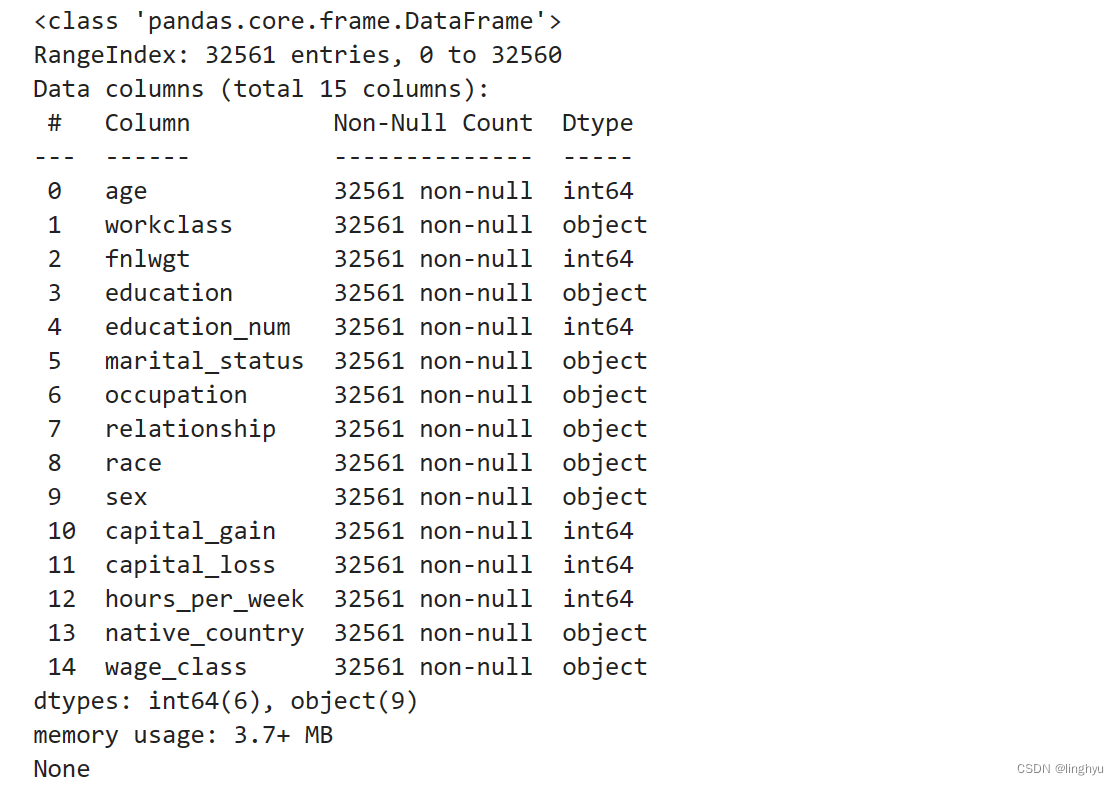
- 查看数值类型列的数据描述信息
对于数值类型的列,可以分别查看每列的基本统计信息,例如:数据个数、均值、标准差、极值、四分位数、中位数
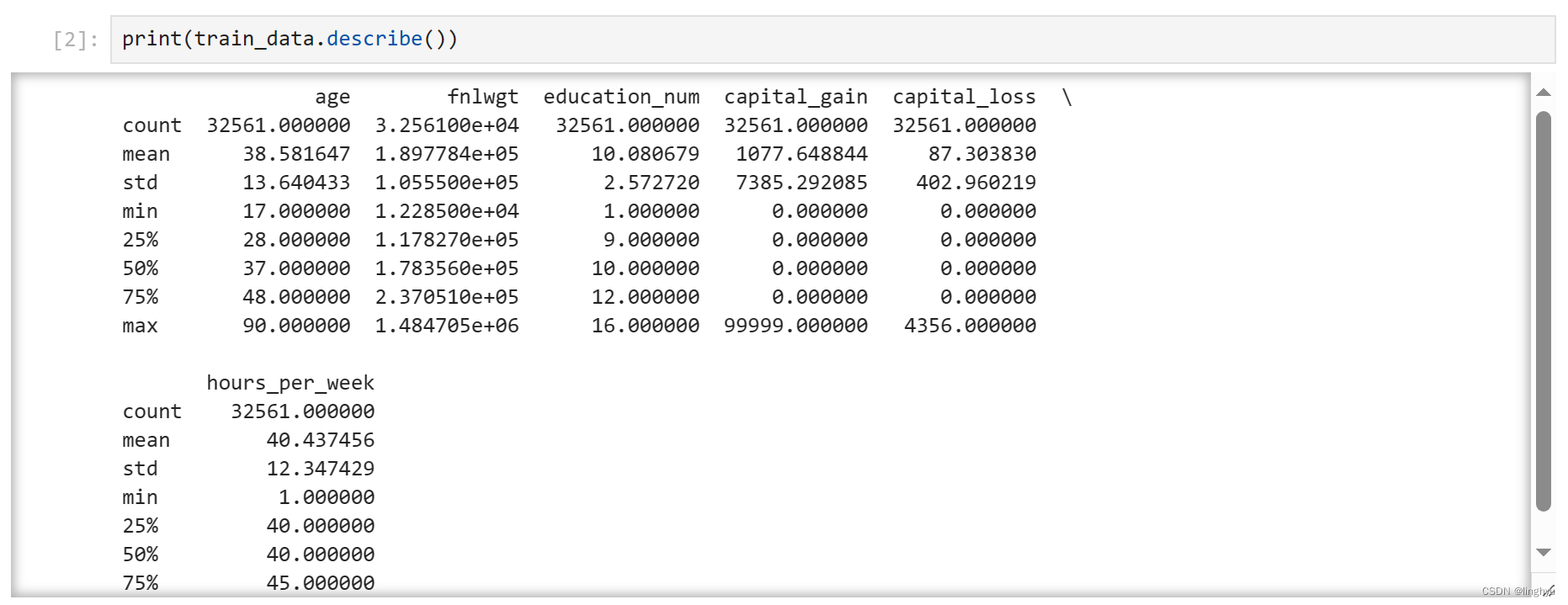
- 以可视化的方式查看数值类型的取值分布情况
在上一步骤中,capital_gain和capital_loss列的极小值、四分位数均为0,而极大值很大,这意味着其数据主要分布在0附近。可以通过分箱统计的方式查看数值分布情况。
直方统计图是很直观的查看数值分布的方法。下面的代码将所有数值分成20个区间,然后统计每个区间中的数据个数。

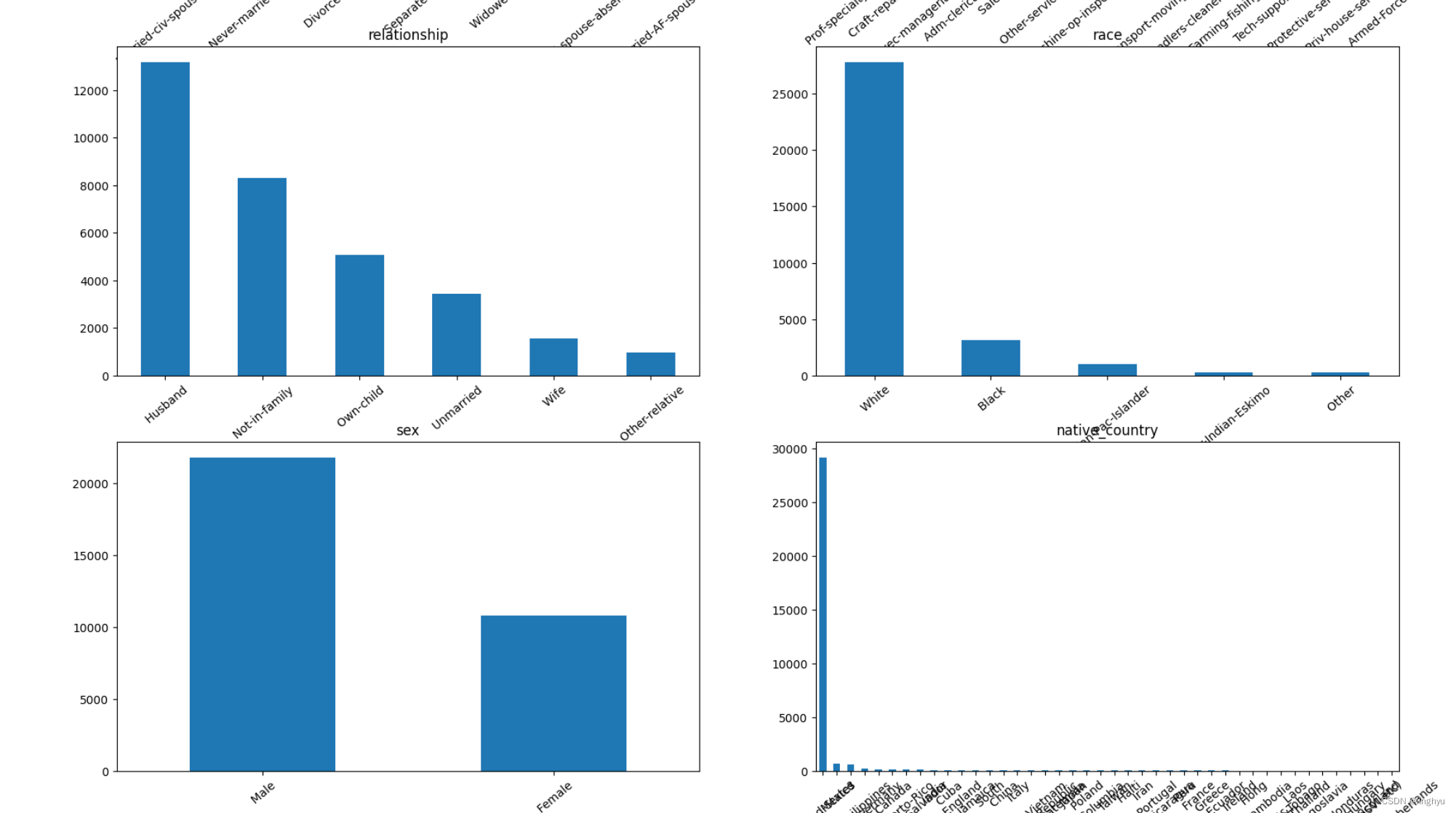
- 查看文本类型列的取值
对于文本类型的列,观察文本的取值有哪些,unique函数用于提取出数据集合中的唯一值。


可以发现,某些列(例如:workclass, occupation,native_country等)包含'?'这样的字符,可视为缺失值。后续应处理此类缺失值;训练数据的wage_class包括两个值:<=50K 和 >50K 而测试数据的是:<=50K. 和 >50K. 后续应使二者统一。

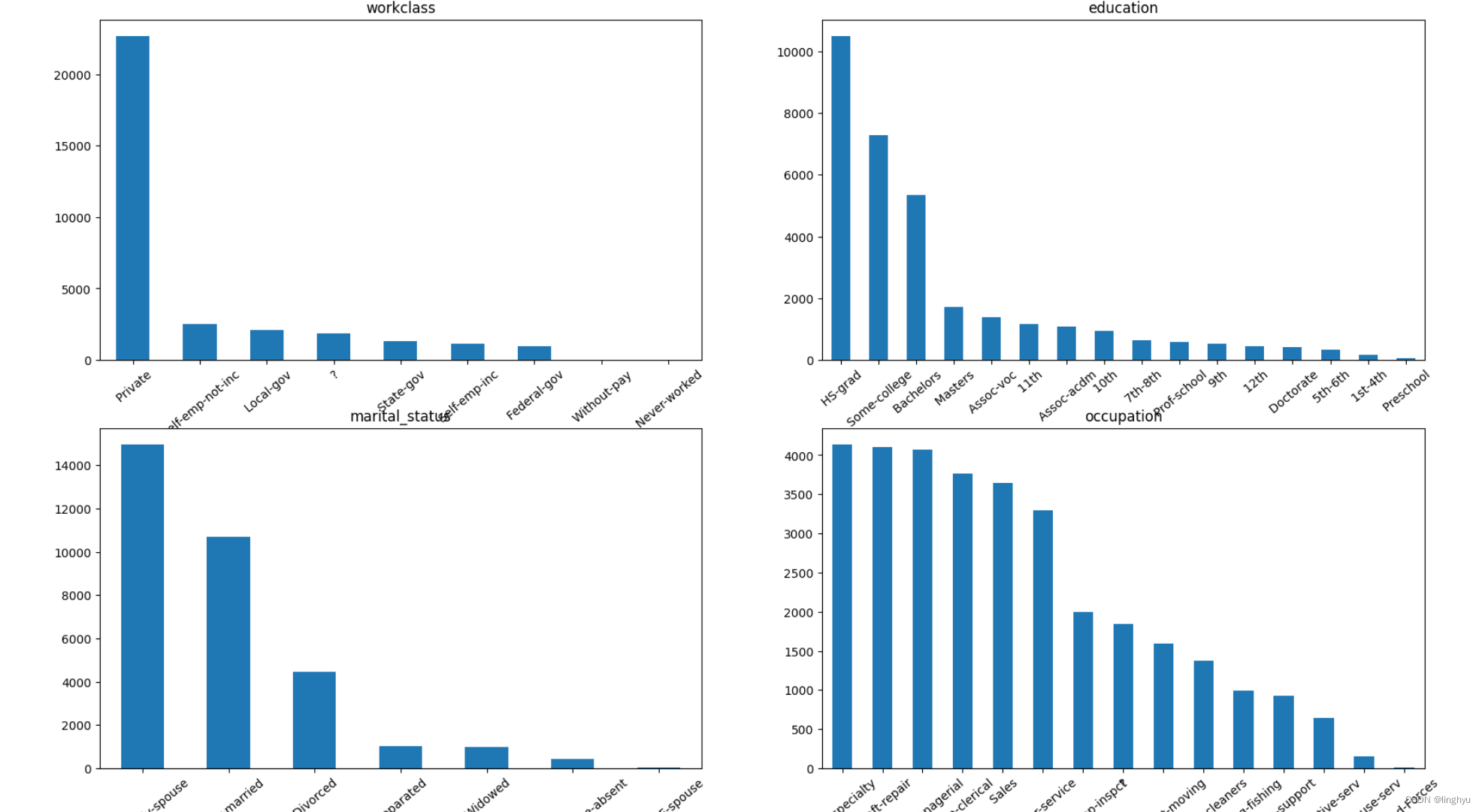
- 查看文本类型的取值分布情况
首先,对一个包含多个文本列名的列表text_columns使用一个for循环遍历这个列表。在循环中,使用plt.subplot()函数创建一个子图,将多个图形绘制到一个平面上。然后,提取train_data数据集中对应于当前文本列名的数据,并计算每个值的计数。

- 观察某行数据及单个字段
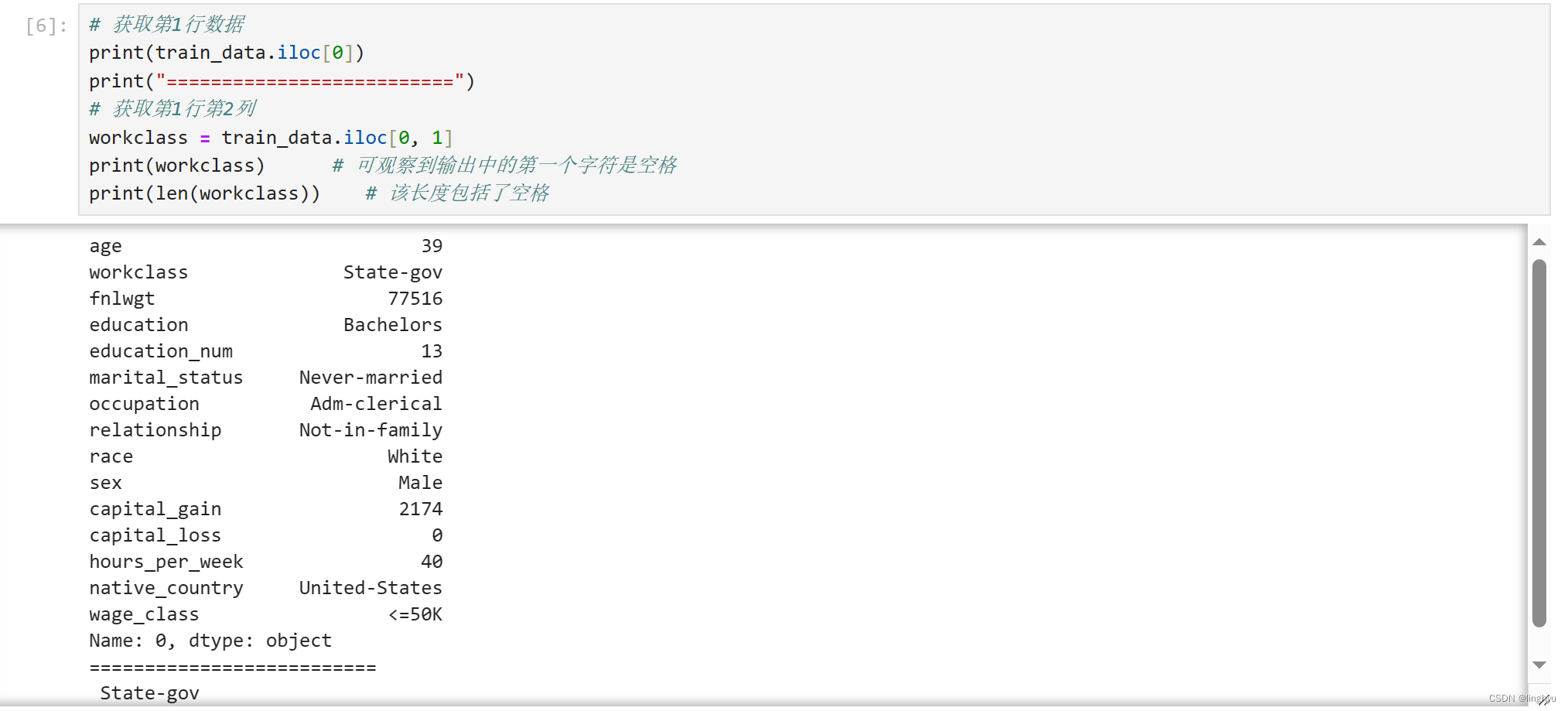
上面的探查中,发现workclass字段的第一个字符为空格符,进一步可以发现,所有的文本字段第一个字符均为空格。为便于数据处理,后续应设法将多余的空格去除
- 分析education取值与wage_class的对应数量关系
通过查看某个特征的若干种取值分别对应着多少个特定分类的样本,可以大致了解哪些取值在样本中比重较大,哪些取值比重较小。
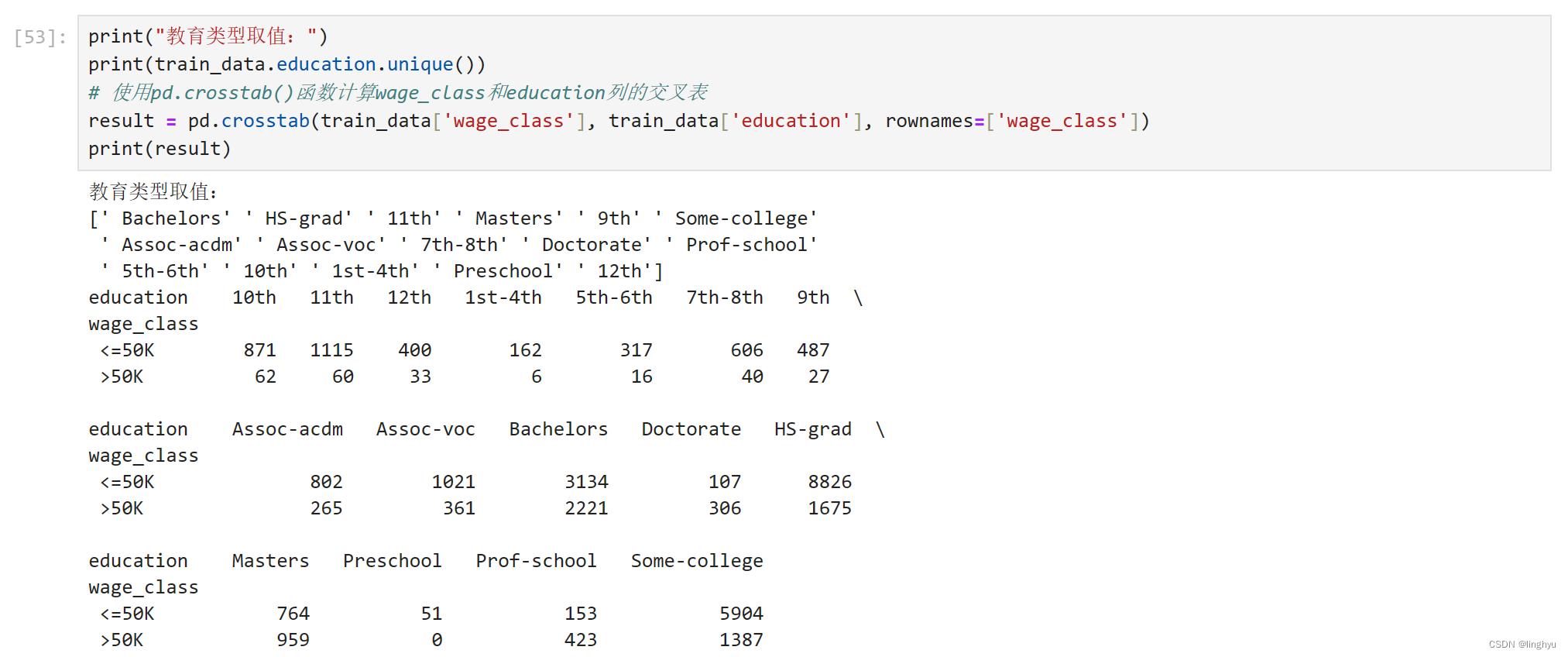
可以看到,当education为Doctorate, Masters或Prof-school时,收入>50K的样本数要超过<=50K的数量;而其余取值则相反。这可能意味着,上述3种取值对于收入是否超过50K有较大影响。
pandas.crosstab是用于生成交叉表的函数。在数据分析中,交叉表(也称为列联表)是一种特殊的二维表格,用于汇总和分组两个或多个变量之间的数据。 pandas.crosstab可以接受多个数组,并将它们转换为交叉表。
数据清洗
- 去除所有文本字段首尾的多余空格
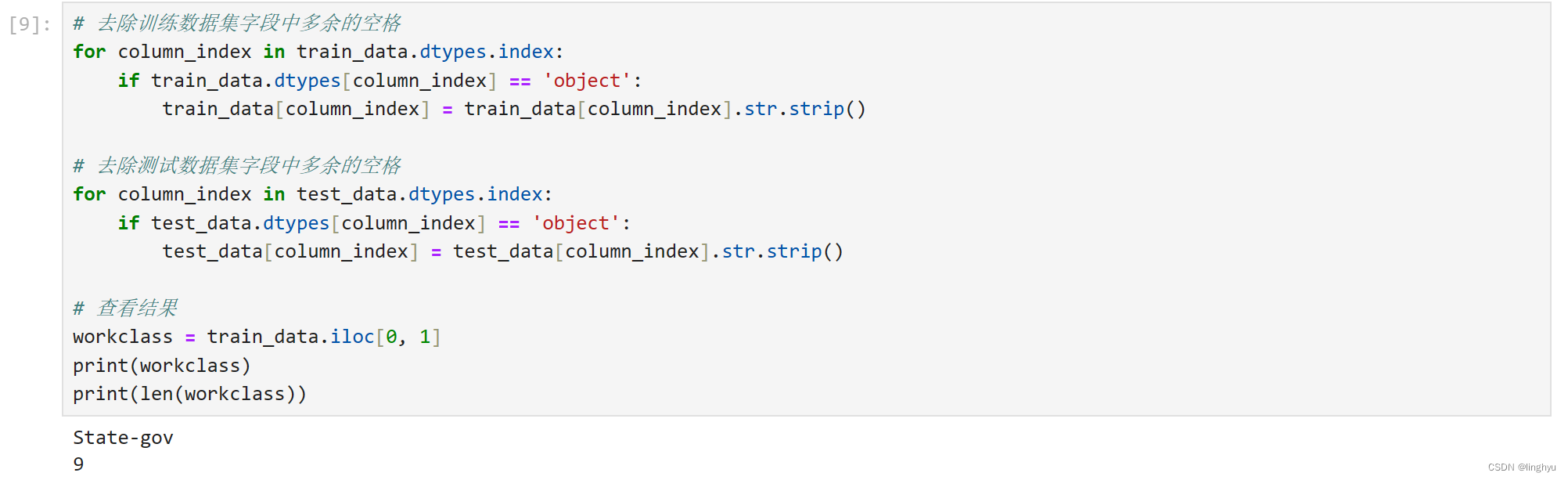
train_data.dtypes属性记录了数据集中所有列的类型信息,包括列下标索引(index)及对应的类型名称,train_data.dtypes[index] 返回指定下标索引的列的类型。此处仅匹配类型为文本字符串(object)的列。
train_data[column_index].str.strip()用于将指定列数据转换成字符串,然后调用strip函数去除首尾空格
- 统一分类标签
训练数据和测试数据的wage_class字段的值应统一,将测试数据集中的标签列更改成与训练数据集的一致,即:去掉原始标签值最后的"."号

- 处理'?'字段
对于训练数据集,用'?'标记的字段,视为无效值,本例中直接移除含有无效值的样本行。

对于测试数据集,带'?'的数据,用出现次数最多的值(文本字段)填充。
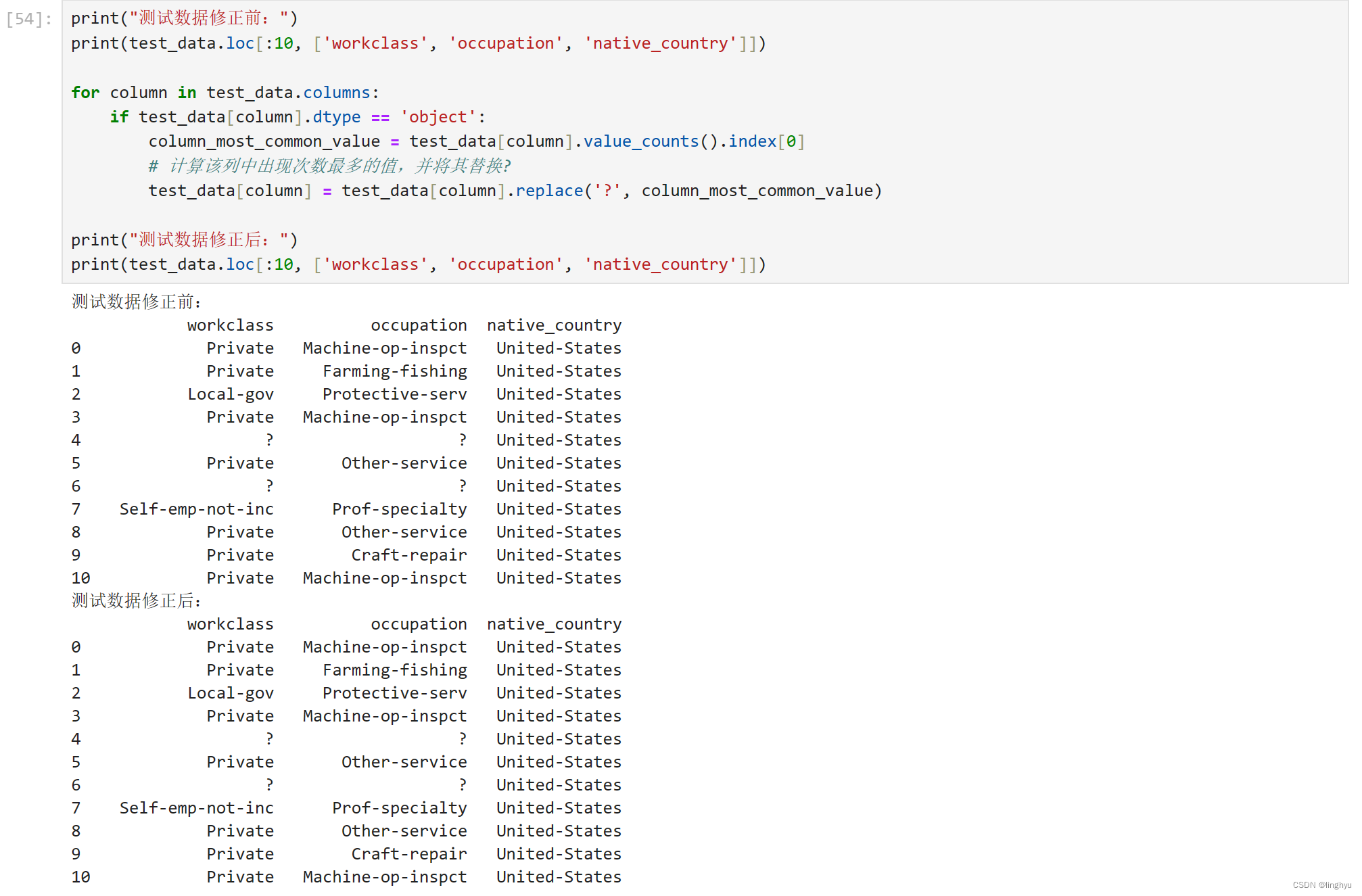
pandas.replace是一个用于替换DataFrame或Series中特定值的函数。给定一个DataFrame或Series,可以使用replace方法将其中的某些值替换为其他值。
pandas.dropna是一个用于去除DataFrame或Series中空值的函数。给定一个DataFrame或Series,可以使用dropna方法从中移除包含缺失数据(NA或NaN)的行或列。
数据预处理
- 文本字段转换成数值字段的方法试验
workclass的取值是文本类型,但模型训练需要的特征必须是数值,因此需要转换
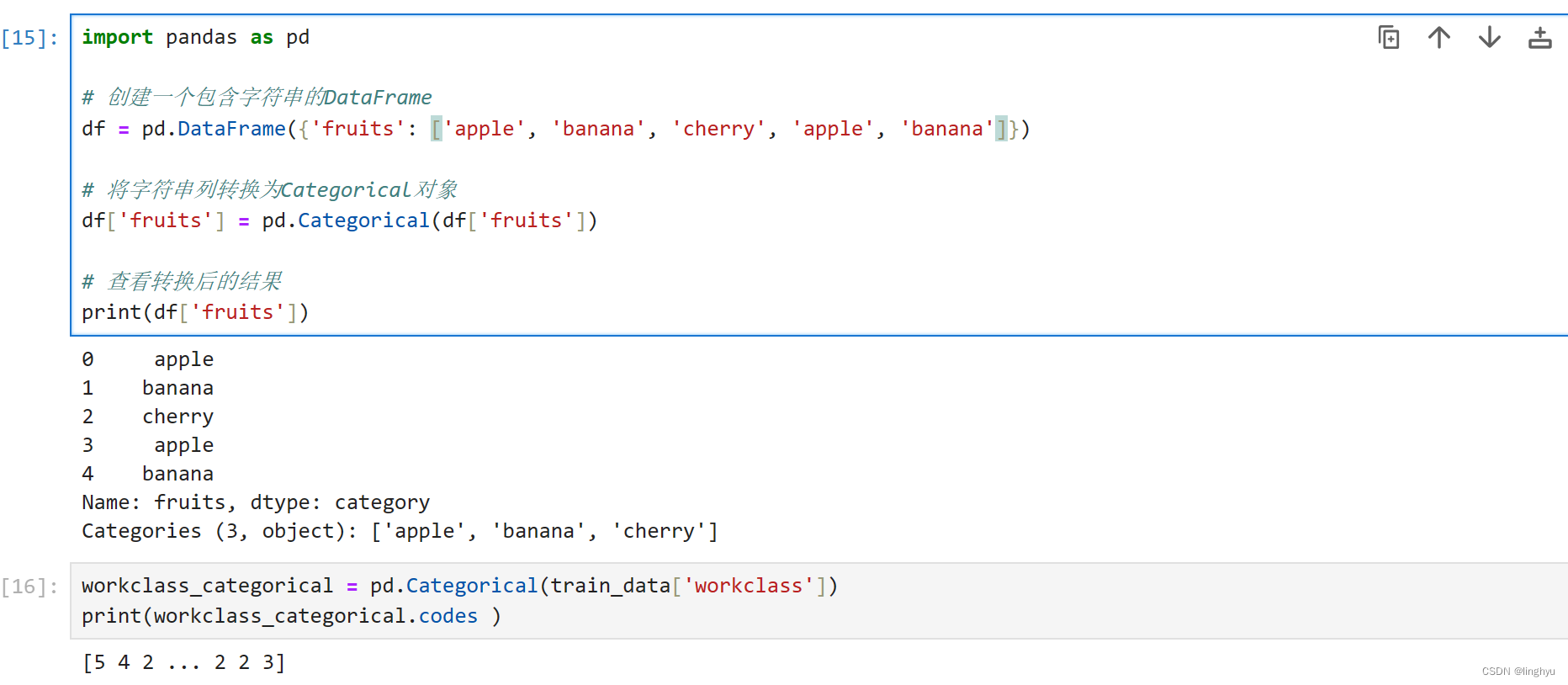
通过Categorical函数,可将文本转换成数值。相同的文本值被赋予相同的数值,并且从1,2,3...依次增长
pandas.Categorical是pandas库中的一个数据类型,用于表示具有有限数量的不同值的数据。它可以用于对离散数据进行处理和分析,例如将字符串、整数或其他数据类型转换为分类变量。通过将数据转换为Categorical对象,我们可以更有效地利用内存,同时提高分析效率,因为Categorical对象在内部使用整数编码来表示不同的分类变量。此外,Categorical对象还支持许多方便的方法,如排序、聚合和查找唯一值等。
下面是一个示例,展示如何使用pandas.Categorical将字符串列转换为分类变量:
在下面的示例中,我们首先创建了一个包含字符串的DataFrame,然后将其"fruits"列转换为Categorical对象。最后,我们打印了转换后的"fruits"列,可以看到它现在被存储为三个不同的类别:apple、banana和cherry。
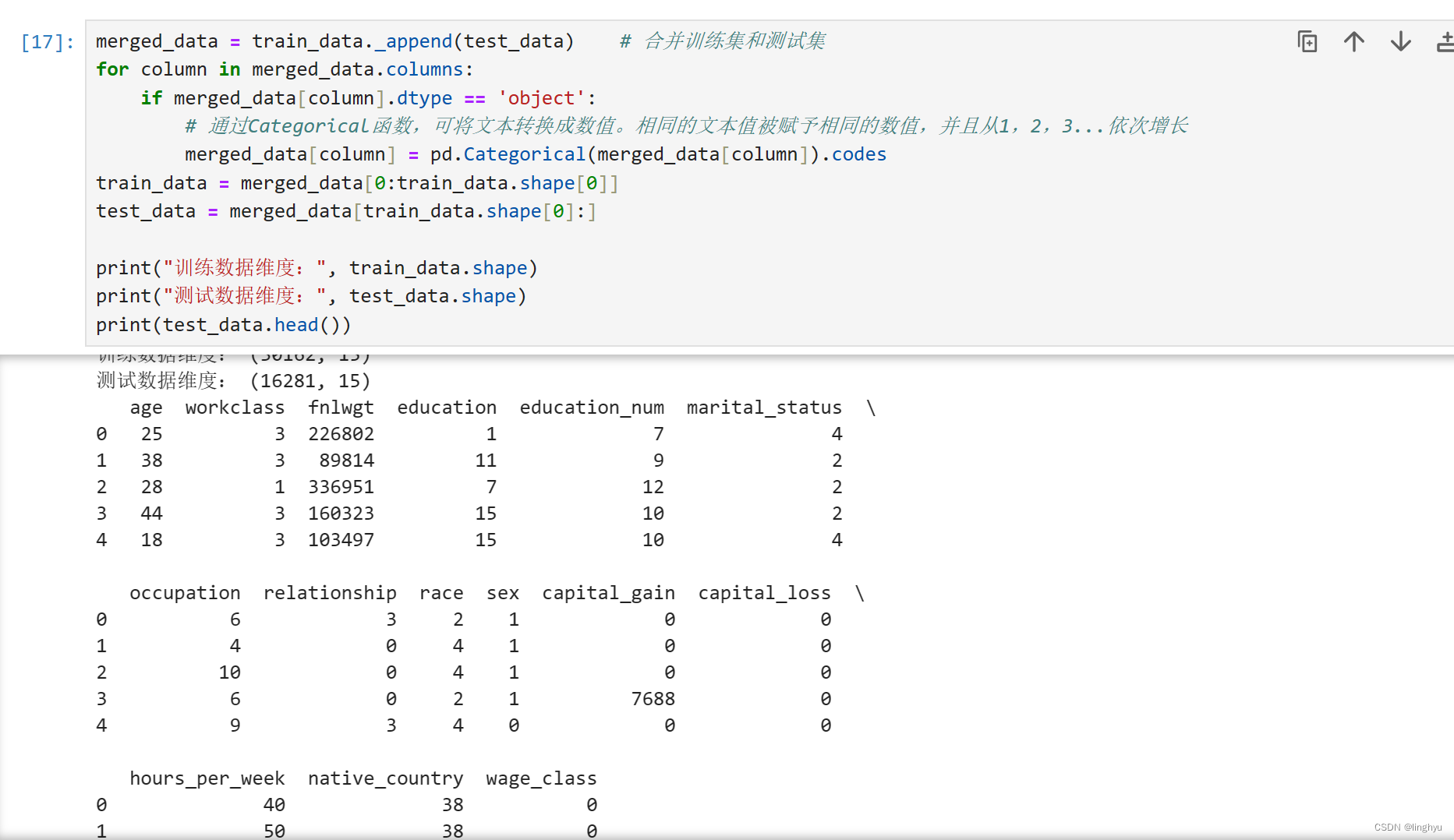
- 将所有文本列均转换成数值编码
将训练数据和测试数据合并起来进行编码。

模型训练
1. 准备工作
准备好训练特征数据集、标签数据集和测试特征数据集、标签数据集,预设超参数。
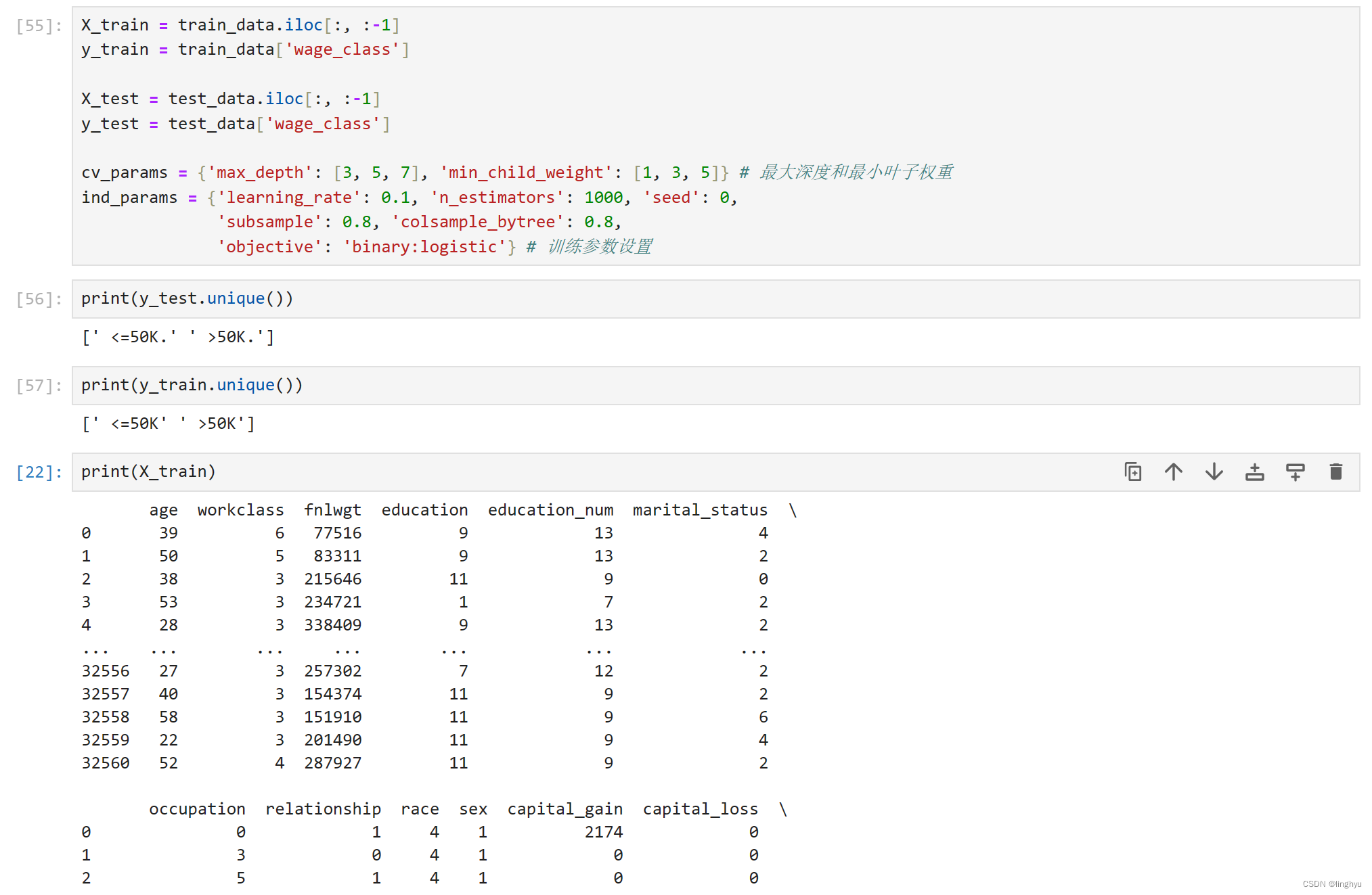
2.使用XGBoost模型训练,并且优选出最佳的模型参数
先固定learning_rate和subsample,以便优选另外两个超参数:max_depth, min_child_weight。
训练过程截图:
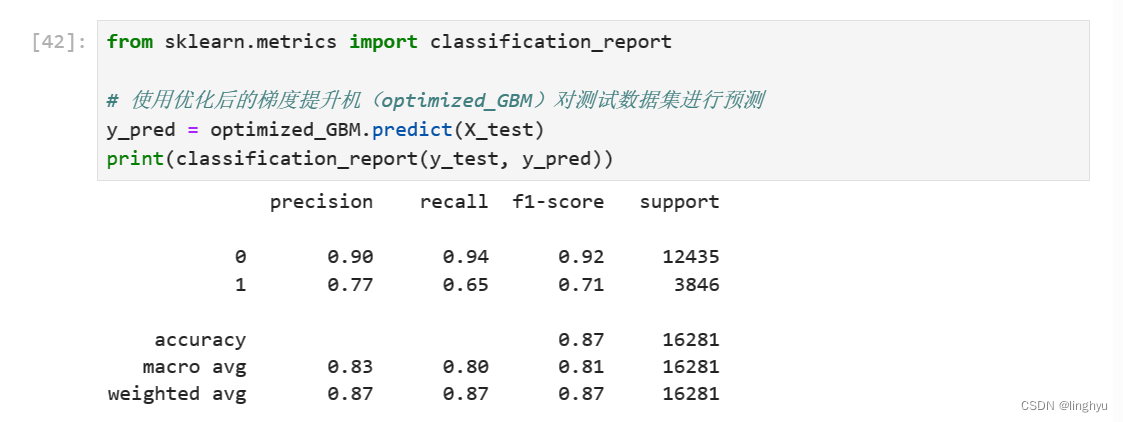
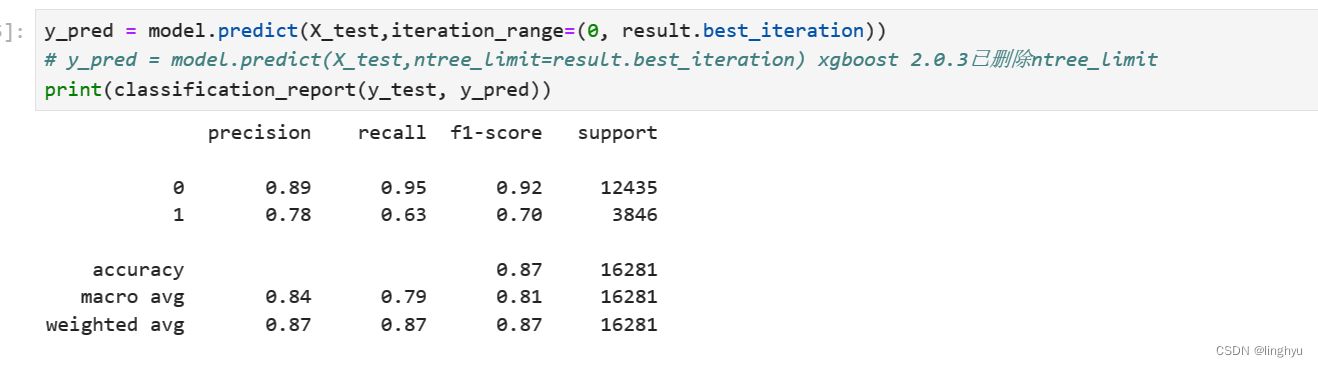
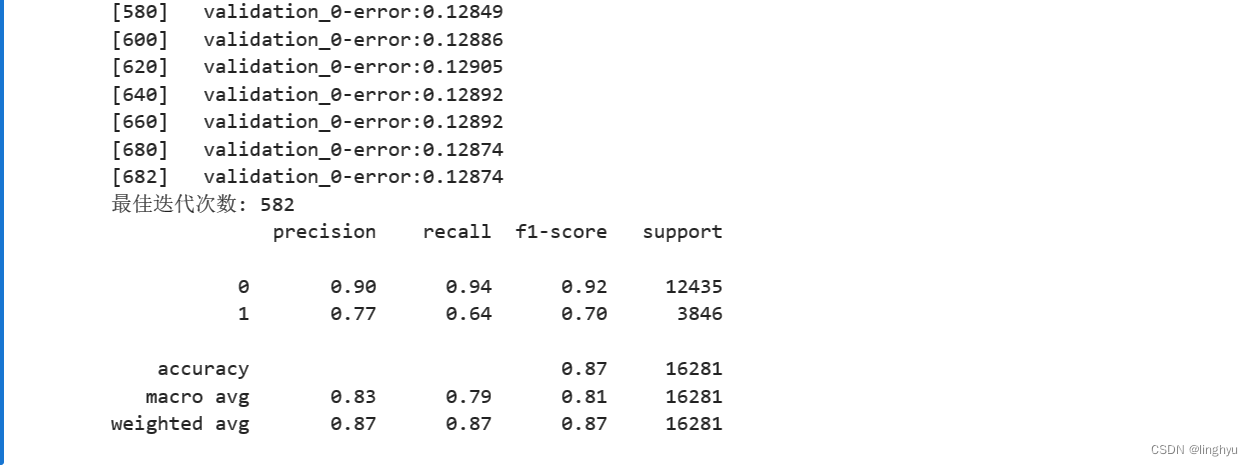
3. 计算模型性能
针对测试数据进行预测,分别计算每个类别的精确度、召回率和F1值
4. 再次调整超参数
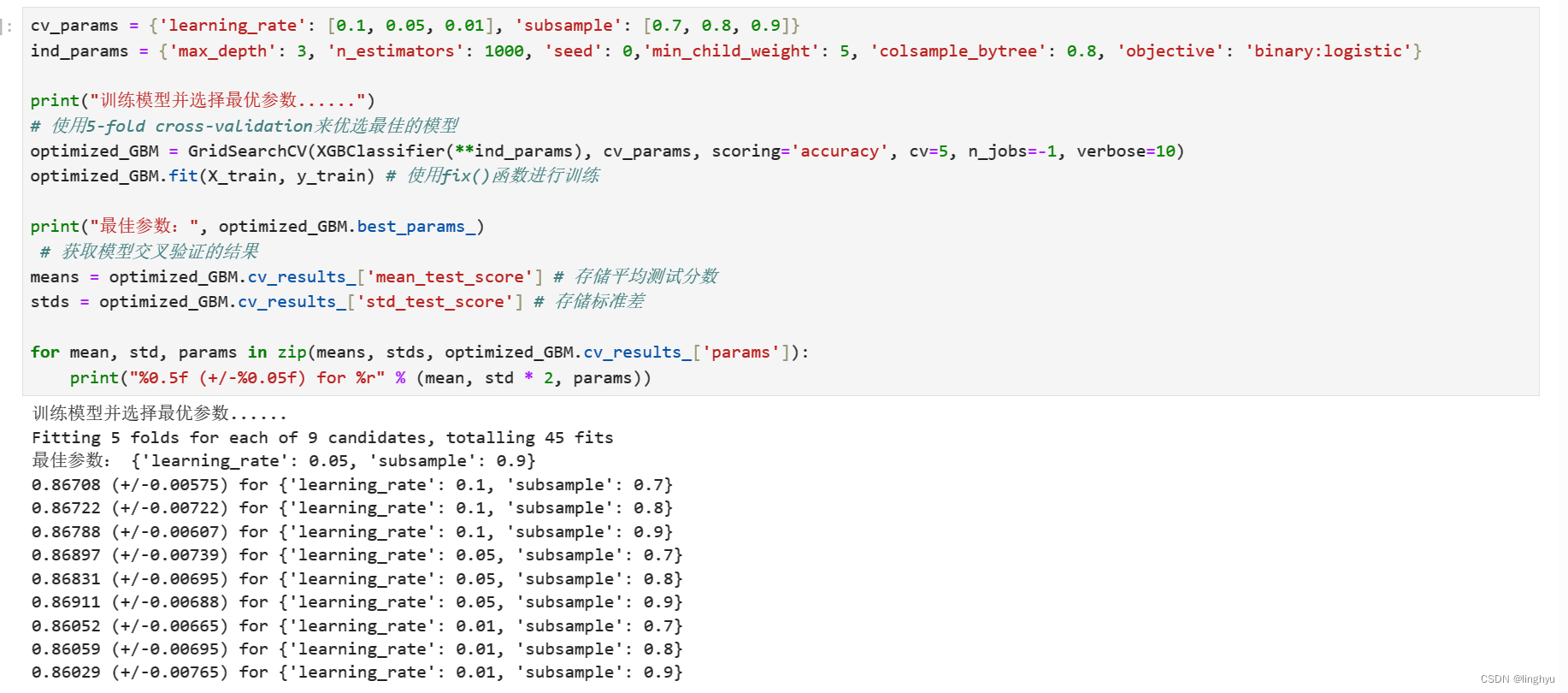
在上述最优超参数{‘max_depth’: 3, ‘min_child_weight’: 5},条件下调整learning_rate, 以及subsample并选出最优超参数
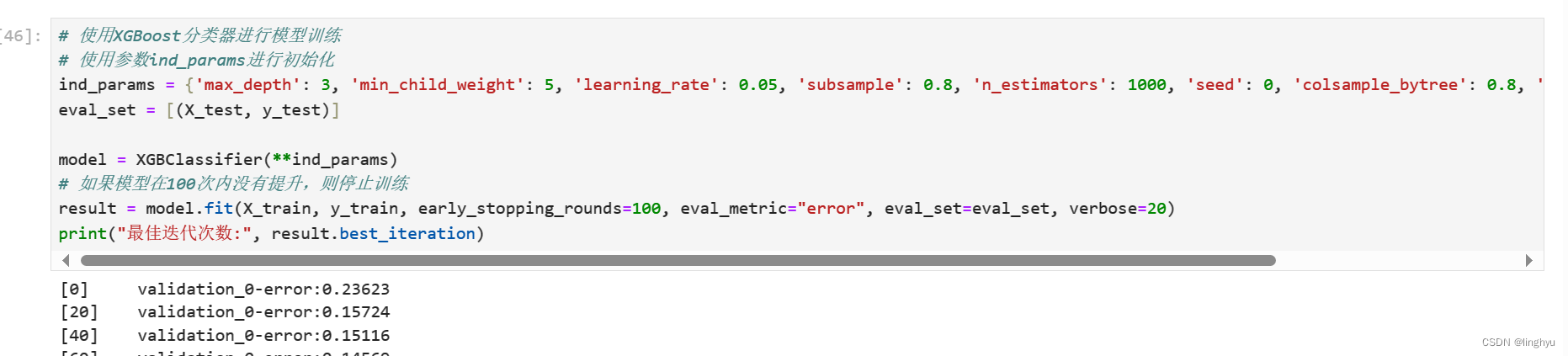
5. 寻找最优的模型训练迭代停止时机
利用前述选定的最佳参数:{'max_depth': 3, 'min_child_weight': 5, 'learning_rate': 0.05, 'subsample': 0.8},构建最有XGBoost模型
XGBoost模型训练时,如果迭代次数过多会进入过拟合。表现就是随着迭代次数的增加,测试集上的测试误差开始下降;当开始过拟合或者过训练时,测试集上的测试误差开始上升,或者波动
通过设置early_stopping_rounds可指定停止训练的时机。当测试集上的误差在early_stopping_rounds轮迭代之内都没有降低的话,就停止训练
通过best_iteration属性可获得最佳的迭代次数
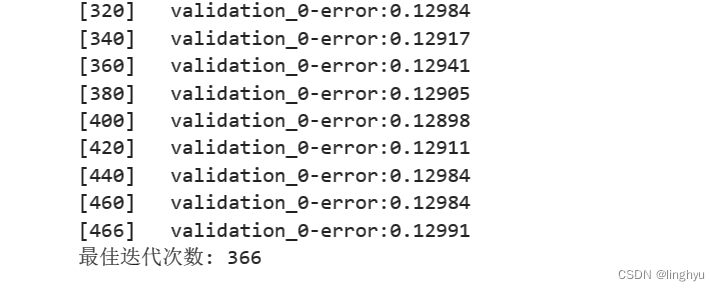
6. 计算最终模型的性能
特征分析
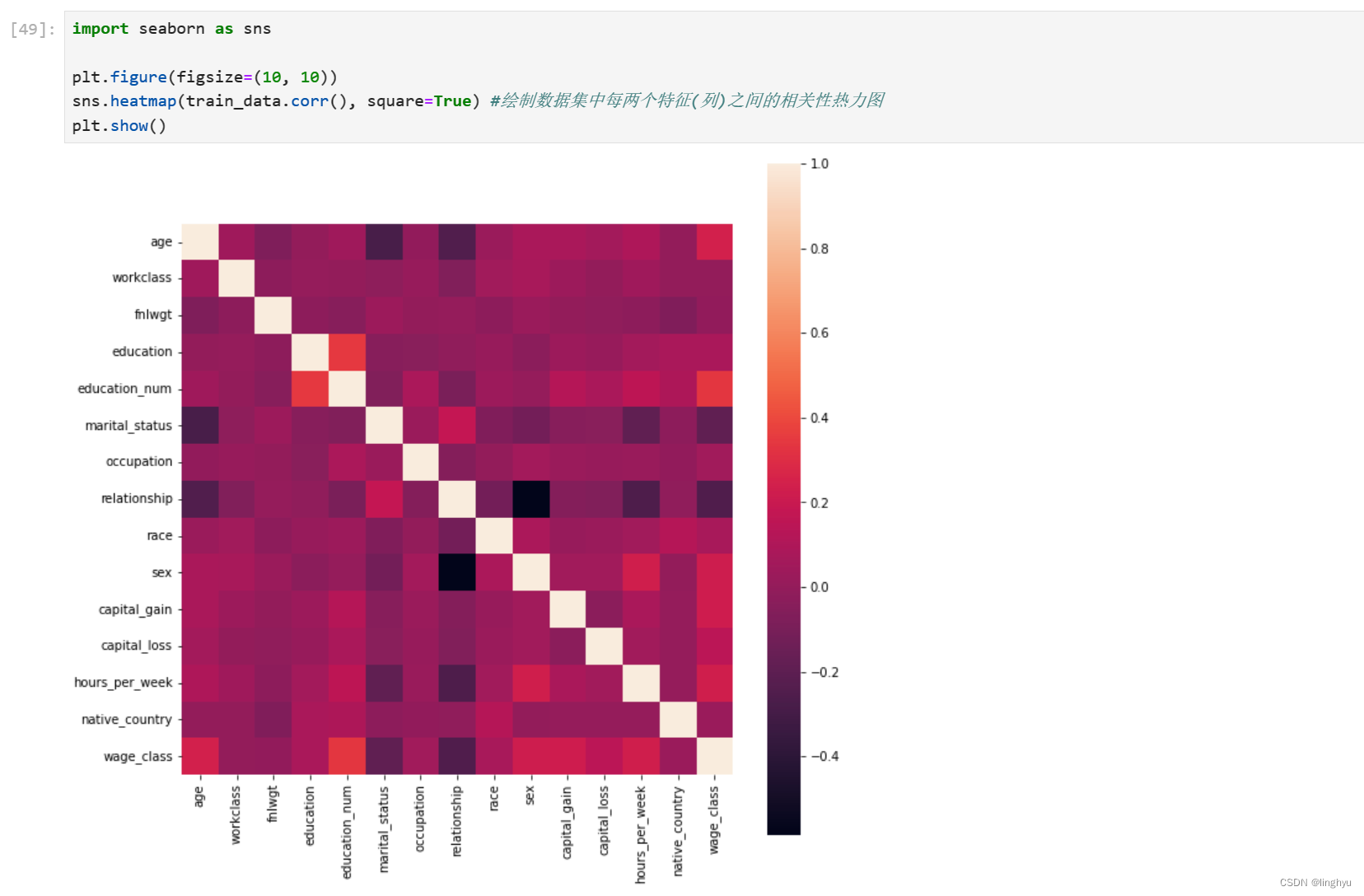
1. 查看各个特征之间的相关性
绘制数据集中每两个特征(列)之间的相关性热力图,可观察到sex和relationship的负相关性很强(黑色方格),education和education_num的正相关性也比较强(白色方格),因此可以各保留1个特征 * 去掉部分强相关特征后,对建模结果几乎们没有影响,但应该能减少计算量。
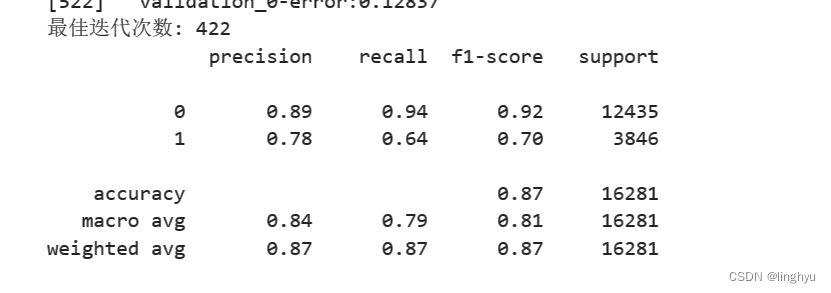
2. 去除强相关的冗余特征
本例中去除education_num,保留education特征;去除relationship,保留sex特征。

预测并计算性能:
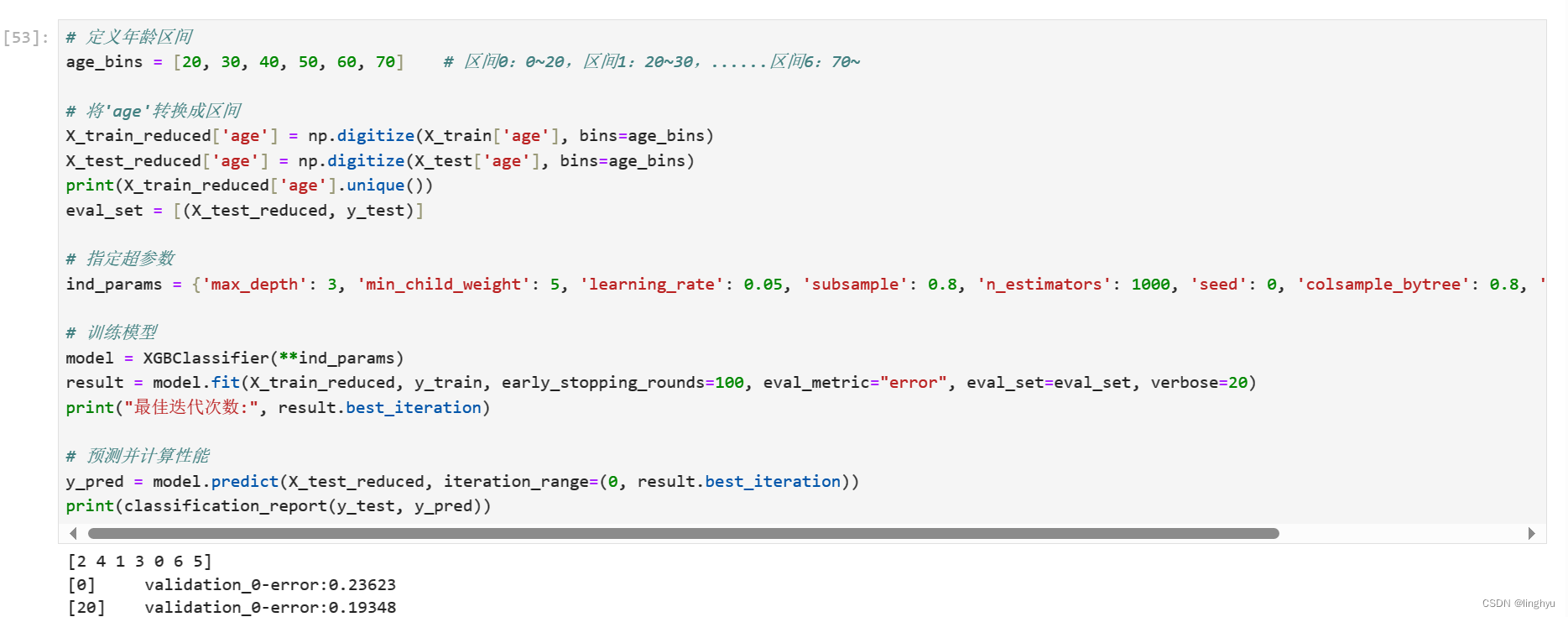
3. 将age特征分箱处理
考虑到age(年龄)是连续的自然数值,在一定程度上,考虑年龄区间可能会比年龄值本身更有意义
numpy.digitize方法用于将数据集划分到指定的区间中,并重新赋给区间编号值







![[面试题]RabbitMQ](https://img-blog.csdnimg.cn/direct/6507af77273149edbd66e3abcb940ebf.jpeg#pic_left)
