【Kafka】Kafka生产者数据重复、数据有序、数据乱序-07
- 1. 数据重复
- 1.1 数据传递语义
- 1.2 幂等性
- 1.2.1 如何开启幂等性
- 1.2.2 同一个消息,多个分区都会存在吗?
- 1.3 事务
- 1.3.1 Kafka 事务原理
- 1.3.2 Kafka事务的作用和意义
- 作用
- 具体应用场景
- 2. 数据有序
- 3. 数据乱序
1. 数据重复
1.1 数据传递语义
-
至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
-
最多一次(At Most Once)= ACK级别设置为0
-
总结:
At Least Once可以保证数据不丢失,但是不能保证数据不重复;
At Most Once可以保证数据不重复,但是不能保证数据不丢失。 -
精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。
Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
1.2 幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。
重复数据的判断标准:具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID(Producer Id)是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。
当幂等性Producer开启时,Kafka通过以下机制来保证消息的幂等性:
- Producer ID(PID)和Sequence Number:
每个幂等性Producer在初始化时都会分配一个唯一的Producer ID(PID)。
每条消息在发送时会被分配一个递增的Sequence Number(序列号)。
Kafka Broker通过PID和Sequence Number来判断消息是否重复。 - 去重机制:
当Broker收到一条消息时,会检查消息的PID和Sequence Number。如果消息的PID和Sequence Number已经存在,Broker会认为这是一个重复的消息,并且不会再次写入。
这种机制只在单个分区内有效。如果消息发送到不同的分区,Kafka无法保证幂等性。

1.2.1 如何开启幂等性
开启方法:
- 二次开发代码中添加 “props.put(“enable.idempotence”,true)”。
- 客户端配置文件中添加 “enable.idempotence = true”。
// 初始化配置,开启事务特性
Properties props = new Properties();
props.put("enable.idempotence", true);
props.put("transactional.id", "transaction1");
...
KafkaProducer producer = new KafkaProducer<String, String>(props);
1.2.2 同一个消息,多个分区都会存在吗?
在Kafka中,同一个消息在多个分区中一般不会存在。Kafka的设计原则之一是消息在分区间是分布的,而不是复制的。以下是一些关键点:
Kafka消息分区
-
分区(Partition):
每个Kafka主题(Topic)可以有多个分区(Partitions),消息在这些分区之间分布。每个消息会被发送到一个特定的分区,而不是所有分区。
分区可以提高并行处理能力和扩展性,因为不同的分区可以由不同的消费者并行处理。 -
消息键(Message Key):
当你向Kafka发送消息时,可以指定一个键(Key)。Kafka使用这个键来决定消息应该被写入哪个分区。相同键的消息会被写入同一个分区,从而保证了消息的顺序性。
如果没有指定键,Kafka会使用轮询(Round-Robin)或者其他算法来将消息分配到不同的分区。 -
副本(Replica):
虽然同一个消息不会被写入多个分区,但Kafka有一个副本机制(Replication),用于提高数据的可靠性和容错性。每个分区有一个主副本(Leader)和多个从副本(Follower),这些副本会在不同的Broker上保存相同的数据。
当Producer发送消息到一个分区的主副本时,主副本会将消息复制到从副本中,以保证数据的高可用性。
1.3 事务
1.3.1 Kafka 事务原理
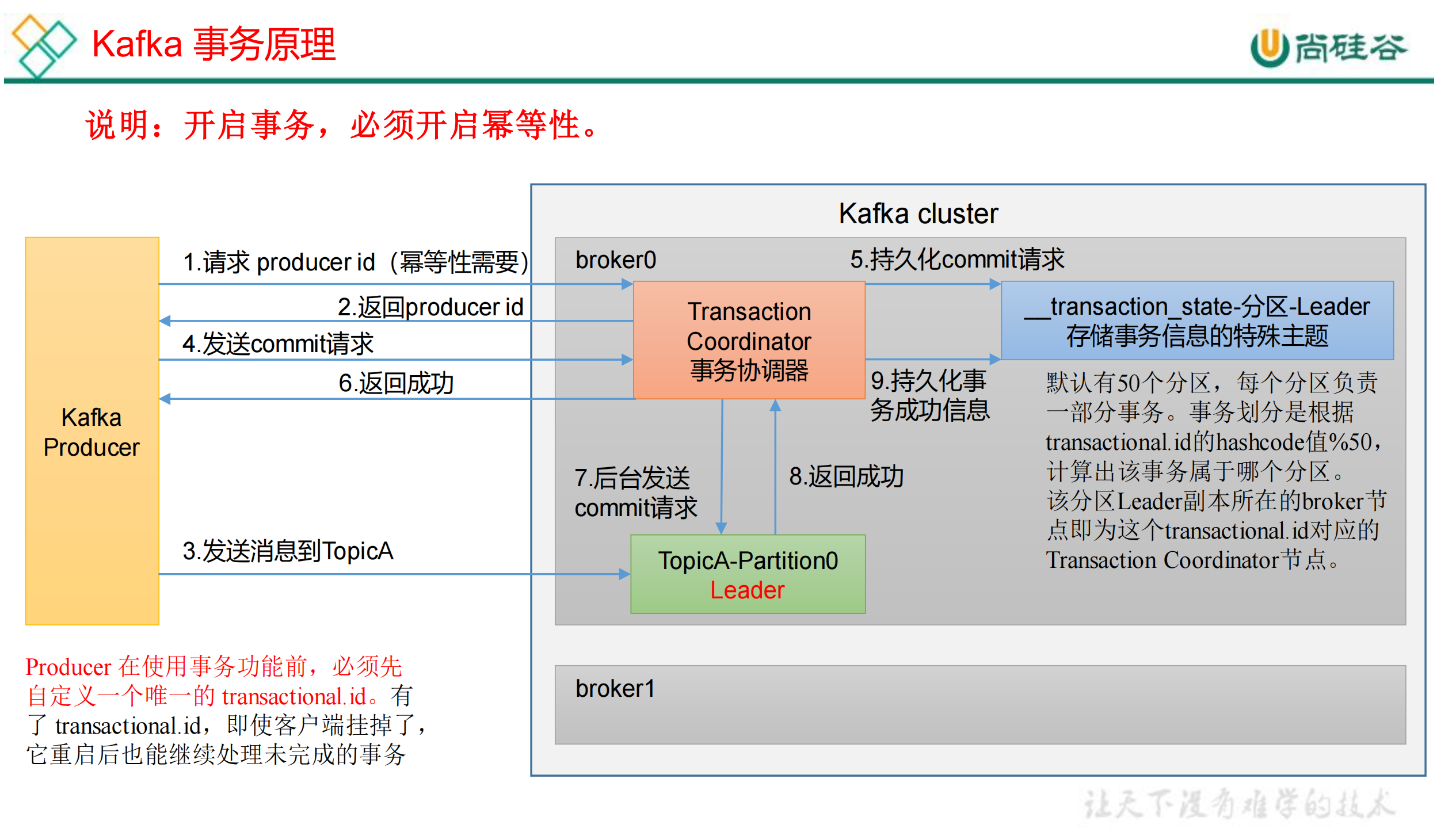
Kafka 的事务一共有如下5个API
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId) throws ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerTranactions {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型 key.serializer
// properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 指定事务id
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "tranactional_id_01");
// 1 创建kafka生产者对象
// "" hello
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 初始化事务
kafkaProducer.initTransactions();
// 开启事务
kafkaProducer.beginTransaction();
try {
// 2 发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "atguigu" + i));
}
// 模拟失败
int i = 1 / 0;
// 提交事务
kafkaProducer.commitTransaction();
} catch (Exception e) {
// 放弃事务
kafkaProducer.abortTransaction();
} finally {
// 3 关闭资源
kafkaProducer.close();
}
}
}
1.3.2 Kafka事务的作用和意义
作用
-
保证消息的原子性:
事务可以保证一组消息的写入要么全部成功,要么全部失败。对于需要在多个分区或多个主题上写入数据的场景,事务能够确保数据的原子性。 -
避免数据丢失和重复:
通过事务机制,Kafka可以避免消息在网络或系统故障时出现丢失或重复的情况。事务保证了每条消息的唯一性和可靠性。 -
支持跨分区和跨主题的操作:
事务支持跨多个分区和多个主题的原子操作,使得Kafka在处理复杂数据流时更加灵活和可靠。 -
简化一致性处理:
使用事务,开发者可以更简单地实现分布式系统中的数据一致性,而不需要手动处理分布式事务协调和一致性检查。 -
支持幂等性:
事务机制基于幂等性,确保每条消息在分区内唯一,不会因重试操作导致重复消息。
具体应用场景
- 金融交易:
在金融系统中,事务可以确保交易数据的完整性和一致性,避免资金损失和数据错乱。 - 订单处理:
电商平台中的订单处理需要保证多个步骤(如库存检查、支付处理、订单确认)的原子性,事务可以确保订单处理的可靠性。 - 日志聚合:
在日志收集和处理系统中,事务可以保证多条相关日志的完整性,避免丢失或重复。 - 数据同步:
在多数据中心或多系统的数据同步中,事务可以确保数据的同步操作原子性,避免数据不一致。
2. 数据有序
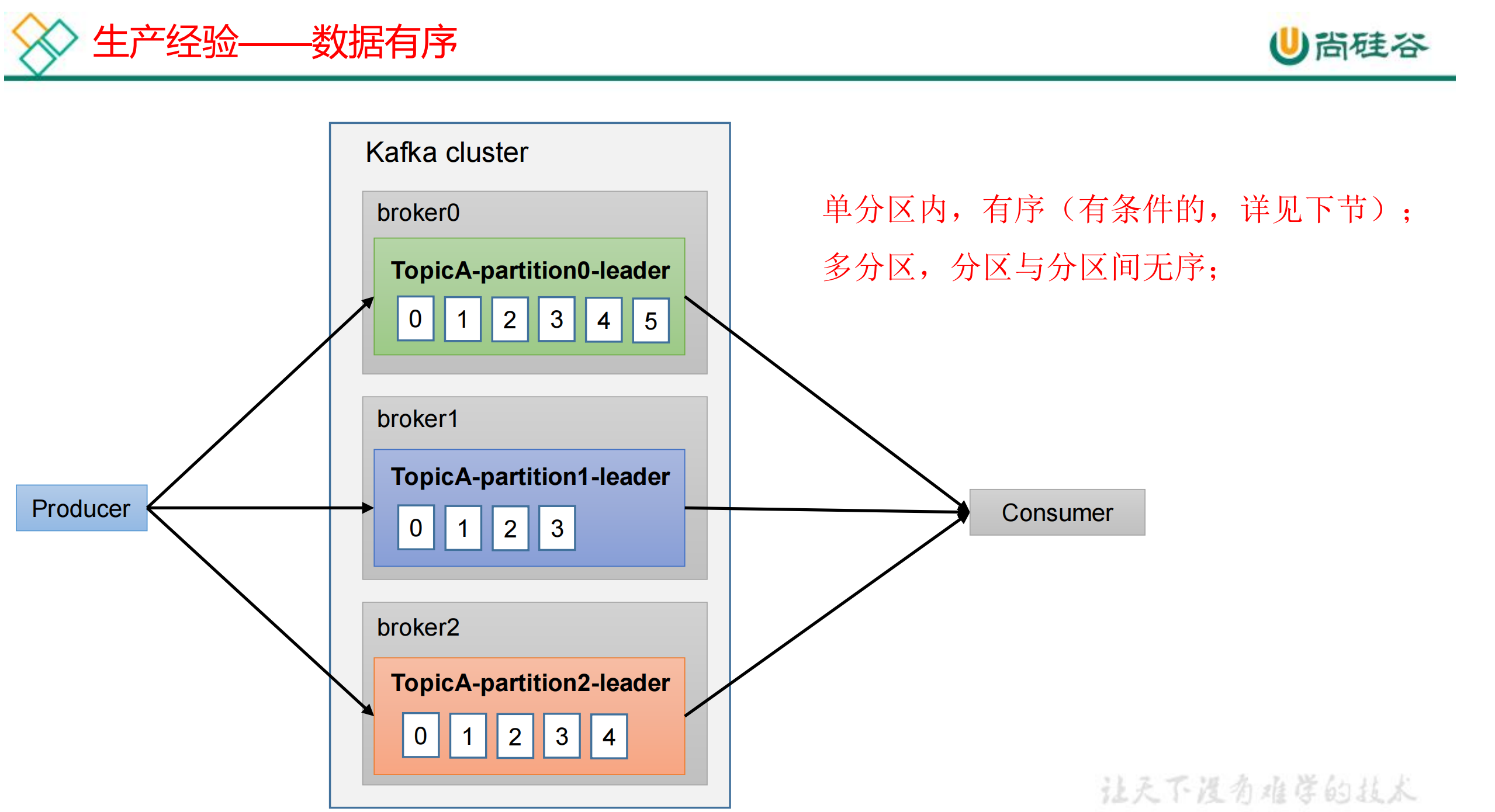
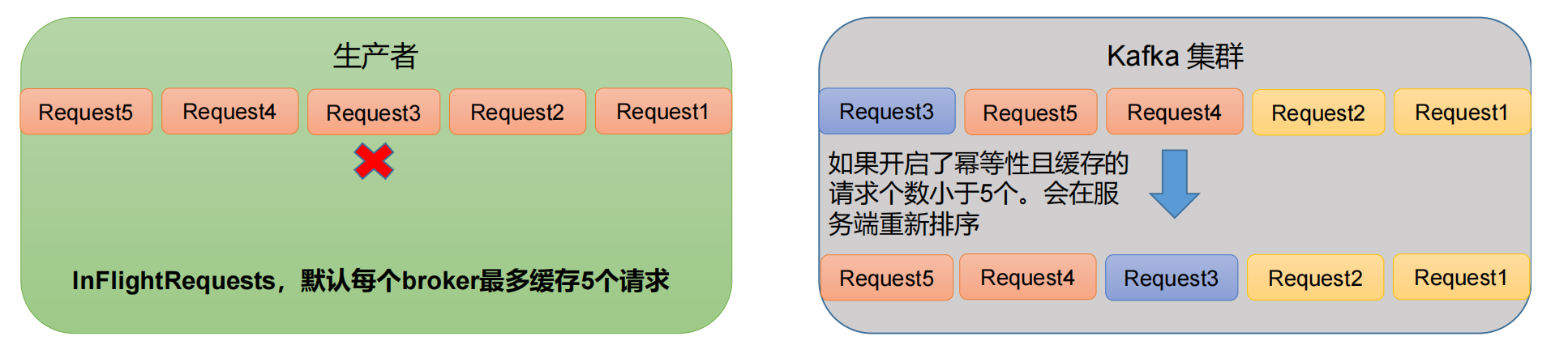
3. 数据乱序
- kafka在1.x版本之前保证数据单分区有序,条件如下:
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。
- kafka在1.x及以后版本保证数据单分区有序,条件如下:
a.未开启幂等性 :max.in.flight.requests.per.connection需要设置为1
b.开启幂等性:max.in.flight.requests.per.connection需要设置小于等于5
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,
故无论如何,都可以保证最近5个request的数据都是有序的。





![[面试题]RabbitMQ](https://img-blog.csdnimg.cn/direct/6507af77273149edbd66e3abcb940ebf.jpeg#pic_left)





![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 机器人搬砖(100分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/f8335274b3b44df3a537966511be76a4.png)