Bert基于Transformer架构是解决自然语言处理的深度学习模型,常使用在文本分类、情感分析、词性标注等场合。
本文将使用Bert模型对中文文本进行分类,其中训练集数据18W条,验证集数据1W条,包含10个类别的文本数据,数据可以自己从Kaggel上下载。
| 中文新闻标题 | 类别标签 | 类别名 |
| 锌价难续去年辉煌 | 0 | 金融 |
| 金科西府 名墅天成 | 1 | 房地产 |
| 同步A股首秀:港股缩量回调 | 2 | 经济 |
| 状元心经:考前一周重点是回顾和整理 | 3 | 教育 |
| 一年网事扫荡10年纷扰开心网李鬼之争和平落幕 | 4 | 科技 |
| 60年铁树开花形状似玉米芯(组图) | 5 | 社会 |
| 发改委治理涉企收费每年为企业减负超百亿 | 6 | 国际 |
| 布拉特:放球员一条生路吧 FIFA能消化俱乐部的攻击 | 7 | 体育 |
| 体验2D巅峰 倚天屠龙记十大创新概览 | 8 | 游戏 |
| Rain入伍前最后开唱 本周六“雨”润京城(图) | 9 | 娱乐 |
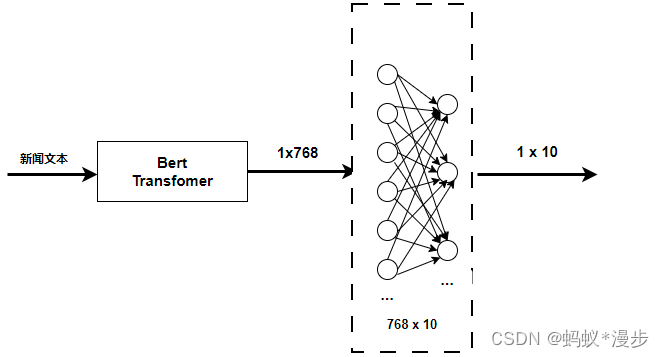
分类模型的结构比较简单,示意图如下:
Dataset是我们用的数据集的库,是Pytorch中所有数据集加载类中应该继承的父类。其中父类中的两个私有成员函数必须被重载,否则将会触发错误提示。其中__len__应该返回数据集的大小,而__getitem__应该编写支持数据集索引的函数。
DataLoader是PyTorch提供的一个数据加载器,它可以将数据分成小批次进行加载,并自动完成数据的批量加载、随机洗牌、并发预取等操作。在神经网络的训练过程中,我们通常需要处理大量的数据。如果一次性将所有数据加载到内存中,不仅会消耗大量的内存资源,还可能导致程序运行缓慢甚至崩溃。因此,我们需要一种机制来将数据分成小批次进行加载,而DataLoader正是为了满足这一需求而诞生的。
#首先导入需要用到的数据包
from transformers import BertModel, BertTokenizer
import torch.nn as nn
import torch
from torch.utils.data import Dataset, DataLoader
from torch import optim
import os
class BertClassifier(nn.Module):
def __init__(self, bert_model, output_size):
super(BertClassifier, self).__init__()
self.bert = bert_model
self.classifier = nn.Linear(bert_model.config.hidden_size, output_size)
def forward(self, input_ids, attention_mask):
# 获取BERT模型的CLS输出
text_output = self.bert(input_ids=input_ids, attention_mask=attention_mask)
#得到线性层的结果
logits=self.classifier(text_output.pooler_output)
return logits
#读取数据
class data_load(Dataset):
def __init__(self,path):
self.data=list()
file=open(path,'r',encoding='utf-8')
for line in file:
text,label=line.strip().split('\t')
self.data.append((text,int(label)))
file.close()
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
#用于dataloader,对于每个小批量的数据,进行分词和填充
def collate_fn(batch,tokenizer):
texts=[text[0] for text in batch]
labels=[text[1] for text in batch]
labels=torch.tensor(labels,dtype=torch.long)
tokens=tokenizer(
texts,
add_special_tokens=True,
max_length=512,
padding=True,
truncation=True,
return_tensors='pt',
)
return tokens['input_ids'],tokens['attention_mask'],labels
if __name__=="__main__":
dataset=data_load('./train.txt')
print(len(dataset))
output :180000
#加载模型,生成分词器
tokenizer=BertTokenizer.from_pretrained('bert-base-chinese')
bert_model = BertModel.from_pretrained('bert-base-chinese')
#dataset:要加载的数据集对象,必须是实现了len()和getitem()方法的对象
data_loader=DataLoader(dataset,
batch_size=128,
shuffle=True,
collate_fn=lambda x:collate_fn(x,tokenizer))
# 指定机器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#打印分词器支持的最大长度,输入的中文数据不能超过512
#如果进行长文本分类,需要进行文本截断或分块处理
# print(tokenizer.model_max_length)
#定义bertclassifier模型为10分类
model=BertClassifier(bert_model,output_size=10).to(device)
model.train()
#优化器
optimizer=optim.AdamW(model.parameters(),lr=5e-5)
#交叉熵损失误差
criterion=nn.CrossEntropyLoss()
#存放模型
os.makedirs('output_models',exist_ok=True)
epoch_n=10
for epoch in range(1,epoch_n+1):
for batch_index,data in enumerate(data_loader):
input_ids=data[0].to(device)
attention_mask=data[1].to(device)
label=data[2].to(device)
#清空梯度
optimizer.zero_grad()
#前向传播
output=model(input_ids,attention_mask)
loss=criterion(output,label)
loss.backward() #计算梯度
optimizer.step() #更新模型参数
#计算正确率,用于观察模型结果
predict=torch.argmax(output,dim=1)
correct=(predict==label).sum().item()
acc=correct/output.size(0)
print(f"Epoch {epoch}/{epoch_n}") #迭代轮数
print(f"Batch {batch_index+1}/{len(data_loader)}")
print(f"Loss: {loss.item():.4f}") #损失
print((f"Acc {correct}/{output.size(0)}=={acc:.3f}")) #正确率
#每一次迭代都保存一次模型结果
model_name=f'./output_models/chinese_news_classify{epoch}.pth'
print("saved model: %s" % (model_name))
torch.save(model.state_dict(),model_name)可以看到随着训练的进行,模型的准确率越来越高。由于数据量和机器内存原因,训练的时间比较长,就没有全部跑完。
Epoch 1/10
Batch 59/1407
Loss: 0.4286
Acc 113/128==0.883
saved model: ./output_models/chinese_news_classify1.pth
Epoch 1/10
Batch 60/1407
Loss: 0.4399
Acc 114/128==0.891
saved model: ./output_models/chinese_news_classify1.pth
Epoch 1/10
Batch 61/1407
Loss: 0.5028
Acc 109/128==0.852
saved model: ./output_models/chinese_news_classify1.pth
Epoch 1/10
Batch 62/1407
Loss: 0.3180
Acc 120/128==0.938
使用训练好的模型预测中文文本
from kaggel_chinese_text import BertClassifier
from transformers import BertModel, BertTokenizer
import torch
test_text='铁血铸辉煌 天骄3公会战唤起新激情'
bert_model = BertModel.from_pretrained('bert-base-chinese')
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model=BertClassifier(bert_model,10)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.load_state_dict(torch.load('./output_models/chinese_news_classify1.pth',map_location=device))
model.to(torch.device(device))
model.eval()
inputs = tokenizer.encode_plus(
test_text,
add_special_tokens=True,
max_length=128,
padding='max_length',
truncation=True,
return_tensors='pt'
)
input_ids = inputs['input_ids']
# print("shape of inut_ids:",input_ids.shape)
attention_mask = inputs['attention_mask']
with torch.no_grad():
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
outputs = model(input_ids,attention_mask)
_, predicted = torch.max(outputs, 1)
print(predicted.item())
#能正确预测文本属于游戏类型
output: 8