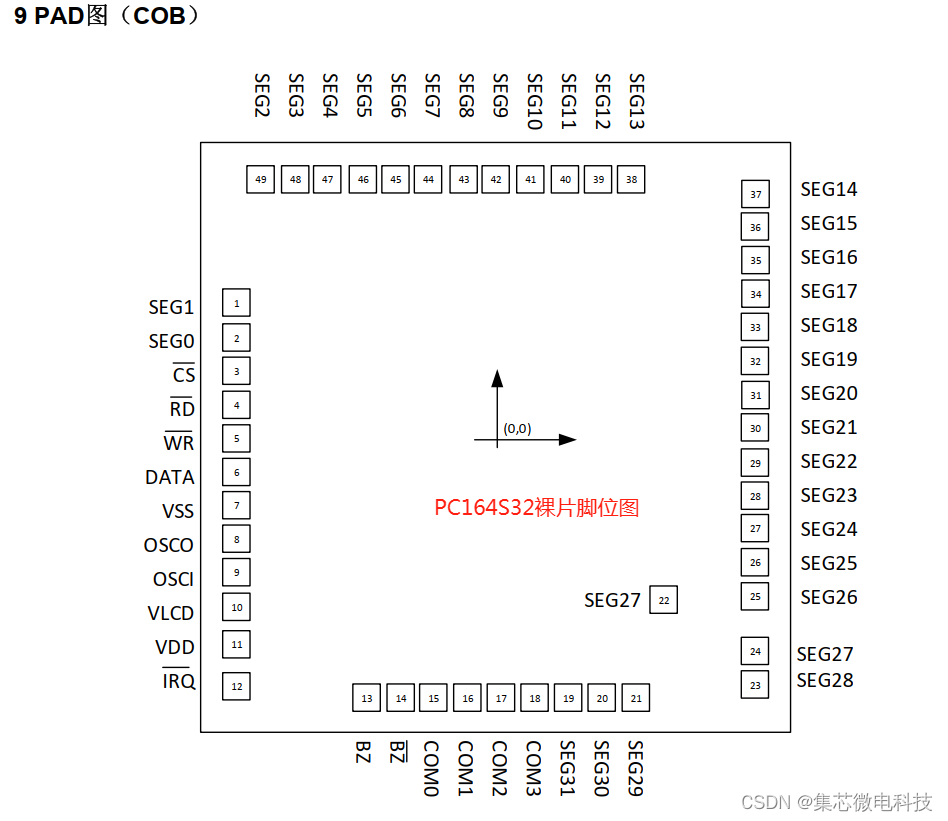
一、多进程模型概述
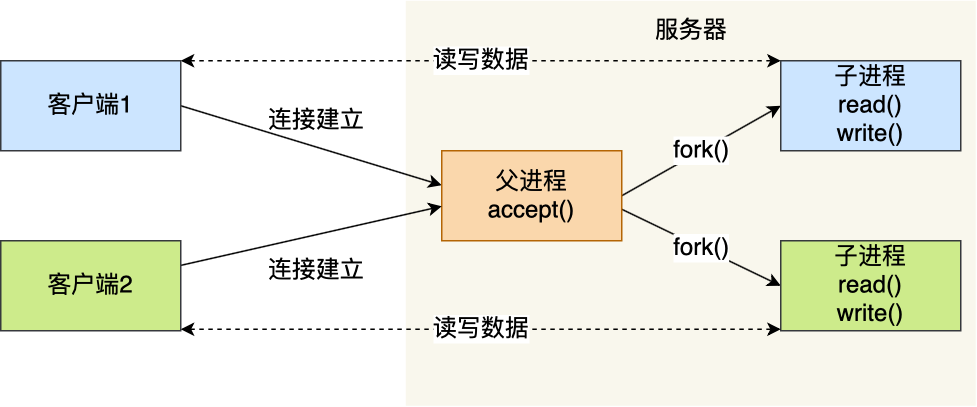
基于最初的阻塞网络 I/O ,若服务器要为多个客户端提供支持,在较为传统的手段中,多进程模型是常用的选择,即为每个客户端都分配一个进程来处理其请求。 服务器的主进程主要负责对客户连接的监听,一旦与客户端的连接成功达成,accept() 函数便会返回一个“已连接 Socket”。此时,通过 fork() 函数创建一个子进程,实际上是把父进程的所有相关内容都进行复制,涵盖了文件描述符、内存地址空间、程序计数器以及执行的代码等等。 在这两个进程刚刚完成复制的时刻,几乎毫无差异。然而,会依据返回值来辨别是父进程还是子进程。倘若返回值为 0 ,那就是子进程;要是返回值为其他的整数,那便是父进程。 正因子进程会复制父进程的文件描述符,所以能够直接运用“已连接 Socket ”与客户端进行通信。 可以看到,子进程无需关注“监听 Socket”,仅需留意“已连接 Socket”;而父进程则相反,将客户服务交由子进程处理,故而父进程不必关心“已连接 Socket”,只需重视“监听 Socket”。
下面这张图描述了从连接请求到连接建立,父进程创建生子进程为客户服务。
二、多进程模型服务端代码
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<pthread.h>
#include<fcntl.h>
#include<sys/socket.h>
#include<netinet/ip.h>
#include<arpa/inet.h>
#define SERROPT 8000 // 定义服务器端口号
#define SERIP "192.168.117.127" // 定义服务器 IP 地址
int main(int argc, char* argv[])
{
// 创建一个套接字
// socket参数:1.协议类型 2.流式套接字 3.传 0(默认 TCP 协议)
int lfd = socket(AF_INET, SOCK_STREAM, 0); // 创建一个 TCP 套接字,返回文件描述符 lfd
struct sockaddr_in seraddr, cliaddr; // 定义服务器和客户端的地址结构体
seraddr.sin_family = AF_INET; // 设置服务器地址结构体的协议族为 IPv4
seraddr.sin_port = htons(SERROPT); // 设置服务器端口号,将主机字节序转换为网络字节序
seraddr.sin_addr.s_addr=INADDR_ANY; // 设置服务器的 IP 地址为任意可用地址
bind (lfd, (struct sockaddr*)&seraddr, sizeof(seraddr)); // 将套接字与服务器地址绑定
listen(lfd,64); // 监听套接字,设置最大等待连接数为 64
socklen_t clilen = sizeof(cliaddr); // 客户端地址结构体长度
while(1) // 无限循环,持续接受客户端连接
{
int scfd = accept(lfd, (struct sockaddr*)&cliaddr, &clilen); // 接受客户端连接,返回新的套接字描述符 scfd
int pid =fork(); // 创建子进程
if(pid == 0) // 如果是子进程
{
close(lfd); // 关闭父进程的监听套接字
while(1) // 子进程中的无限循环,用于处理与客户端的通信
{
char buf[1024]; // 定义接收缓冲区
int rr = read(scfd, buf, sizeof(buf)); // 从客户端读取数据到缓冲区,返回读取的字节数
write(STDERR_FILENO, buf, rr); // 将读取的数据写到标准错误输出
write(scfd, buf, rr); // 将数据反射回客户端,证明客户端已接收
}
}
}
return 0;
} Ip地址换成自己虚拟机Ip地址,运行服务器再创建一个终端输入命令(nc 你的ip地址 你设置的端口号)就可以连接到服务器进行通讯。
三、多进程模型注意事项及不足
注意事项:
- 当子进程结束运行并退出后,尽管它不再处于活动状态,但内核仍会保留一些关于它的基本信息,比如进程的退出状态等。这些保留的信息会占用一定的内存空间,如果父进程不及时进行回收处理,子进程就会变成僵尸进程。僵尸进程持续累积会不断消耗系统的内存等资源,最终可能导致系统资源匮乏,影响整个系统的正常运行。
- 为了避免子进程成为僵尸进程,父进程需要承担“善后”的责任。具体的处理方式有两种,即调用 wait() 函数和 waitpid() 函数。这两个函数可以让父进程获取子进程的退出状态等信息,并释放子进程所占用的系统资源。
不足之处:
- 谈到使用多个进程来服务多个客户端的模式。在客户端数量较少,比如只有 100 个的时候,这种方式可能还能满足需求。但是当客户端数量大幅增加到一万个时,这种方式就会面临严重的问题。因为创建每个进程都会消耗系统的资源,比如内存、CPU 时间等。
- 进程间上下文切换也是一个关键问题。当从一个进程切换到另一个进程时,不仅需要切换用户空间的资源,例如虚拟内存的映射、栈中的数据、全局变量的值等;还需要切换内核空间的资源,像内核堆栈的内容以及各种寄存器的值。这种大量且频繁的上下文切换会带来巨大的开销,导致系统性能显著下降。
- 例如,假设有一个服务器同时处理多个文件下载的进程。当进程数量较少时,系统能够轻松应对。但如果同时有大量的下载请求,每个请求都创建一个进程,系统可能会因为资源消耗过度和频繁的上下文切换而变得缓慢甚至崩溃。
- 再比如,在一个多进程的数据库服务器中,如果进程数量过多且上下文切换频繁,可能会导致查询响应时间延长,影响用户体验。
总之,多进程模型在处理少量客户端时可能可行,但在面对大规模客户端时存在诸多限制和问题。