一、下载Kaldi模型
下载地址:GitHub - kaldi-asr/kaldi: kaldi-asr/kaldi is the official location of the Kaldi project.
下载文件解释:
一般常用的是src、tools和egs包
src(源代码)包: 包含Kaldi的核心源代码,提供了实现语音识别所需的基础功能,例如声学建模、特征提取、解码器等。
tools(工具)包: 包含与Kaldi相关的工具和第三方依赖项。这些工具可以用于数据预处理、特征提取、模型训练等。例如,sph2pipe工具用于处理SPH音频格式,sox工具用于音频格式转换和处理
egs(示例)包:包含一些示例和教程,用于演示如何使用Kaldi构建语音识别系统。这些示例通常包括数据准备、特征提取、模型训练和解码等步骤,帮助用户理解和使用Kaldi。
cmake 目录:包含用于构建 Kaldi 的 CMake 脚本和相关文件。CMake 是一个跨平台的构建工具,用于自动化构建过程scripts 目录:包含用于执行各种任务的脚本文件。这些脚本可以用于数据准备、特征提取、模型训练、解码等操作。
二、按照INSTALL文件编译
This is the official Kaldi INSTALL. Look also at INSTALL.md for the git mirror installation.
[Option 1 in the following does not apply to native Windows install, see windows/INSTALL or following Option 2]Option 1 (bash + makefile):
Steps:
(1)
go to tools/ and follow INSTALL instructions there.(2)
go to src/ and follow INSTALL instructions there.Option 2 (cmake):
Go to cmake/ and follow INSTALL.md instructions there.
Note, it may not be well tested and some features are missing currently.
(一)在tools/中安装
查看其中的INSTALL
To check the prerequisites for Kaldi, first run
extras/check_dependencies.sh
and see if there are any system-level installations you need to do. Check the
output carefully. There are some things that will make your life a lot easier
if you fix them at this stage. If your system default C++ compiler is not
supported, you can do the check with another compiler by setting the CXX
environment variable, e.g.
CXX=g++-4.8 extras/check_dependencies.sh
Then run
make
which by default will install ATLAS headers, OpenFst, SCTK and sph2pipe.
OpenFst requires a relatively recent C++ compiler with C++11 support, e.g.
g++ >= 4.7, Apple clang >= 5.0 or LLVM clang >= 3.3. If your system default
compiler does not have adequate support for C++11, you can specify a C++11
compliant compiler as a command argument, e.g.
make CXX=g++-4.8
If you have multiple CPUs and want to speed things up, you can do a parallel
build by supplying the "-j" option to make, e.g. to use 4 CPUs
make -j 4
In extras/, there are also various scripts to install extra bits and pieces that
are used by individual example scripts. If an example script needs you to run
one of those scripts, it will tell you what to do.
1. 要检查Kaldi的依赖项,并安装
(1)检查依赖项
extras/check_dependencies.sh
每次运行,会给出安装依赖的建议。安装完每一步依赖,再运行一遍,直到可以成功运行
使用以下命令,安装所需要的依赖包:
这个命令将会安装 g++, make, automake, autoconf, git, sox, gfortran, libtool,
subversion, 和 python2.7。
sudo apt-get install g++ make automake autoconf git sox gfortran libtool subversion python2.7
继续跳出安装建议:
sudo apt-get install zlib1g-dev
安装intel-mkl-full
sudo apt-get install intel-mkl-full
安装过程会跳出如下提示:
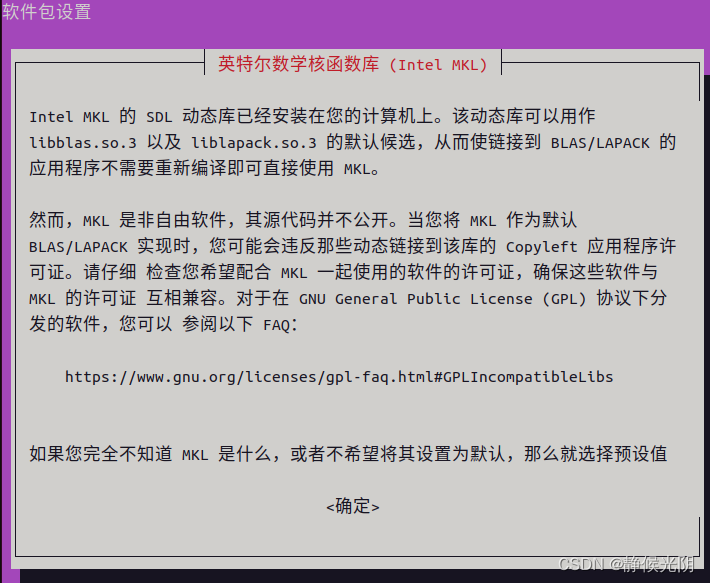
使用Tab按键,选中确定后回车,下列步骤选择默认"否",继续安装

此时,再运行extras/check_dependencies.sh应该会看到如下反馈,表示依赖安装完毕。

(2)兼容问题的处理方案(上面一步执行成功的请跳过)
如果extras/check_dependencies.sh因为兼容问题不能正确执行,可以按照下列格式,指定你拥有的g++最新版本执行。这里的4.8可以更换为您系统当前的g++版本。
CXX=g++-4.8 extras/check_dependencies.sh
2. 编译
(1)在tools文件夹下执行下列命令:
make
安装完毕,显示如下:

(2)兼容问题的处理方案(上面一步执行成功的请跳过)
如果执行make时因为兼容问题不能正确执行,可以按照下列格式,指定你拥有的g++最新版本执行。这里的4.8可以更换为您系统当前的g++版本。
make CXX=g++-4.8
3. CPU配置
如果您有多个CPU并希望加快速度,可以通过向make提供"-j"选项来进行并行构建,例如使用4个CPU:
make -j 4
执行完毕,显示如下:

4. 安装模型
(1)按照提示,安装IRSTLM
extras/install_irstlm.sh
执行完毕,显示如下:

(2)继续执行下列安装代码
extras/install_kaldi_lm.sh
5. 设置环境变量
按照上面安装后的提示:“Please source tools/env.sh in your path.sh to enable it” 设置环境变量。
上一步操作后,当前目录为kaldi-master/tools,需要退回到kaldi-master目录下,使用cd命令退一层目录,执行环境变量配置命令, 将tools/env.sh脚本中的命令和设置加入到当前Shell的环境中。
cd ..
source tools/env.sh执行结果如下

(二)在src/中安装
其中的INSTALL文件,显示如下:
These instructions are valid for UNIX-like systems (these steps have
been run on various Linux distributions; Darwin; Cygwin). For native Windows
compilation, see ../windows/INSTALL.
You must first have completed the installation steps in ../tools/INSTALL
(compiling OpenFst; getting ATLAS and CLAPACK headers).
The installation instructions are
./configure --shared
make depend -j 8
make -j 8
Note that we added the "-j 8" to run in parallel because "make" takes a long
time. 8 jobs might be too many for a laptop or small desktop machine with not
many cores.
For more information, see documentation at http://kaldi-asr.org/doc/
and click on "The build process (how Kaldi is compiled)".
上述文件:
这些说明适用于类UNIX系统(这些步骤已在各种Linux发行版、Darwin和Cygwin上运行过)。对于原生Windows编译,请参见…/windows/INSTALL。
您必须首先完成…/tools/INSTALL中的安装步骤(编译OpenFst;获取ATLAS和CLAPACK头文件)。
1. 执行./configure --shared
./configure --shared2. 编译命令
(1)执行命令一:
第一次执行使用A.第一种执行方式,非第一次执行,使用B. 第二种执行方式
A. 第一种执行方式:直接生成依赖关系,同时运行的作业数被固定为2。
make depend -j 2直接生成依赖关系,同时运行的作业数被固定为2。其中,数字 2 是调用cpu核心数,一半为当前硬件cpu核心数的一半以内为宜。如果不做设置,该命令不会限制并行作业的数量,甚至会压倒强大的工作站,因为Kaldi构建是高度并行化的。
当前使用虚拟机是4核cpu,所以执行时选择了使用2颗核心。执行完毕显示如下:

B. 第二种执行方式:首先会执行清理操作,然后生成依赖关系,同时运行的作业数由系统CPU核心数决定。
make -j clean depend执行完毕后,显示如下:

(2)执行命令二:
make -j 2再次强调:其中,数字 2 是调用cpu核心数,一半为当前硬件cpu核心数的一半以内为宜。如果不做设置,该命令不会限制并行作业的数量,甚至会压倒强大的工作站,因为Kaldi构建是高度并行化的。
编译完成显示如下:

(三)测试
1. yesno语音识别
参考网站:刘永浩记__Kaldi理解与部署cvte模型_kaldi cvte-CSDN博客
进入egs/yesno/s5文件夹,执行run.sh,命令如下:
./run.sh 在执行该脚本的时候,会首先从kaldi官网上下载yesno例子的wav文件,然后再对其进行训练和识别

执行结束显示如下:

在最后显示:%WER 0.00 [ 0 / 232, 0 ins ,0 del ,0 sub ],表示识别结果非常准确。
WER(Word Error Rate)代表的是字错误率,是衡量语音识别系统的准确程度的标准
计算公式:WER=(ins+del+sub)/N
其中:
ins: 被插入的单词的个数(多认的)
del: 被删除的单词的个数(少认的)
sub: 被替换的单词个数(认错的)
N: 总共的单词个数
上述执行结果,表示,总共单词个数为232个,多认的(ins)、少认的(del)、认错的(sub)单词数加起来,去除以总共测试的单词数(N),WER反映了识别的准确率,该值越小越好。
2. 以aishell为例的语音识别过程
参考网站:kaldi做语音识别_语音识别_Paprika_coin-GitCode 开源社区
cd egs/aishell/s5
修改cmd.sh的配置,我是用的是geany,可以通过sudo apt install geany下载安装。
geany cmd.sh
(1)将cmd.sh修改为:
export train_cmd="run.pl --mem 2G" #"queue.pl --mem 2G"
export decode_cmd="run.pl --mem 4G" #"queue.pl --mem 4G"
export mkgraph_cmd="run.pl --mem 8G" #"queue.pl --mem 8G
原文件的queue是基于集群的,这里我们用本机/服务器跑,因此改为run.sh。
(2)新建目录
首先在根目录下建立路径:/export/a05/xna/data然后下载数据集。
回到根目录命令:
cd /新建export文件夹,并进入该文件夹,由于在根目录下操作,需要使用sudo
sudo mkdir export
cd export新建a05文件夹,并进入
sudo mkdir a05
cd a05新建xna文件夹,并进入
sudo mkdir xna
cd xna新建data文件夹
sudo mkdir data(3) 执行下载数据并训练
之后输入下列命令开始执行,这里下载数据集要在run.sh前面加sudo命令,这是路径的缘故。下载数据集用到的脚本是local/download_and_untar.sh 需要下载两个数据文件:data_aishell 和 resource_aishell.
sudo ./run.sh
就开始进行语音识别过程了。强烈建议逐行运行,运行当前行时,把其他暂时注释调,这样清楚看见每个阶段的过程。
过程简单阐述如下:
- 语料数据准备 下载语料库到本地/服务器的文件夹
- 数据关系,词典、语言文件(text, wav.scp, utt2pk, spk2utt)准备,训练集、测试集、验证集准备
- 单音素(或者其他模型)训练和解码
- 构建解码图
- 解码查看结果

由于我的虚拟机只能使用2个CPU核心,无法使用GPU,处理速度太慢。这里不展示最后结果。


![[HGAME 2022 week1]Matryoshka(古典密码混合)](https://img-blog.csdnimg.cn/direct/3d828969548b4036893562abc1b0d54f.png)