✨个人主页: 熬夜学编程的小林
💗系列专栏: 【C语言详解】 【数据结构详解】【C++详解】
目录
1、堆排序
1.1、基本思想
1.2、初步代码实现
1.3、代码优化
1.4、代码测试
总结
1、堆排序
在博主数据结构第十二弹---堆的应用有详细讲解堆排序喔~~~
数据结构第十二弹---堆的应用https://blog.csdn.net/2201_75584283/article/details/135348207![]() https://blog.csdn.net/2201_75584283/article/details/135348207
https://blog.csdn.net/2201_75584283/article/details/135348207
1.1、基本思想
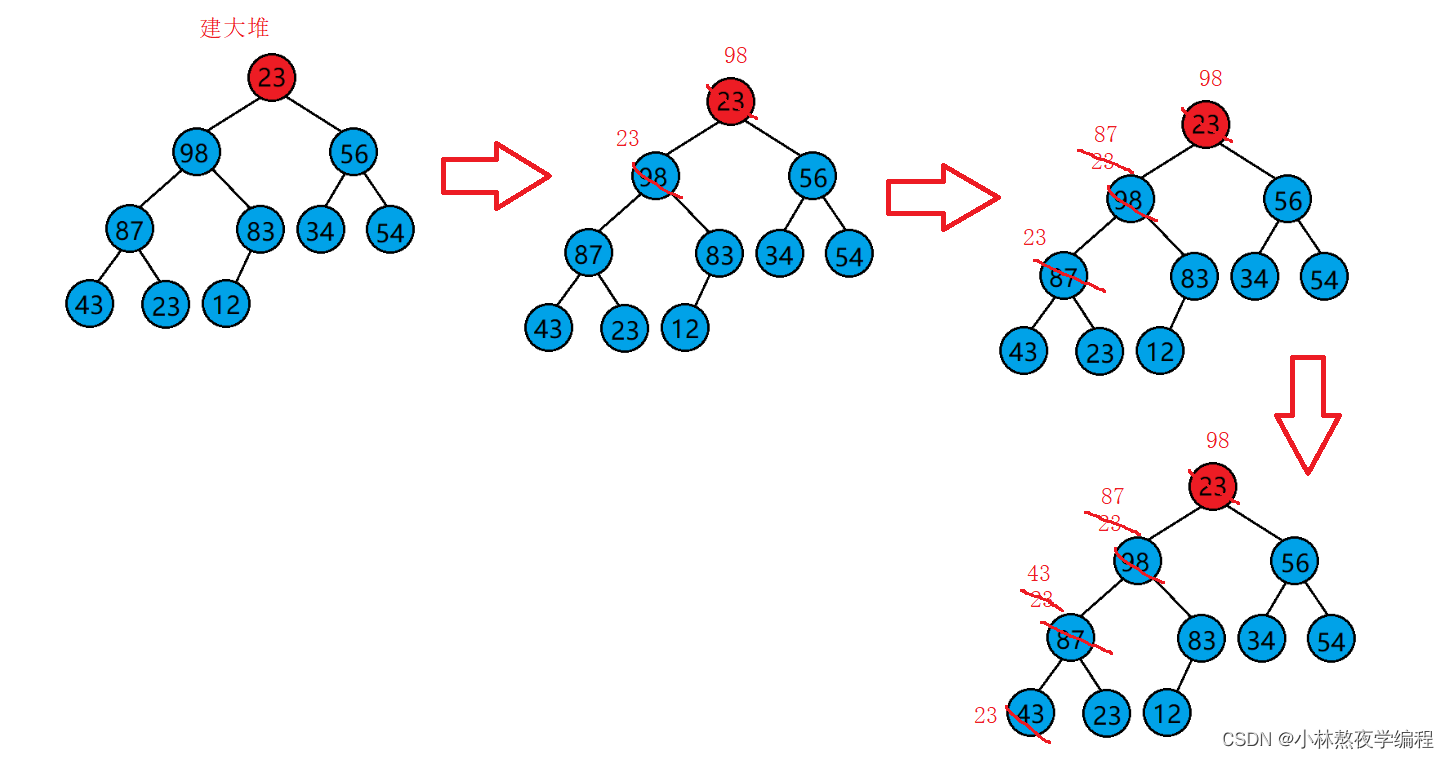
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
为什么升序用到的是大堆呢?
因为:大堆的堆顶是最大的数,可以将其放在数组尾,然后再通过向下调整算法找到次大的数。而小堆的堆顶是最小的数,需要放在第一个位置,如果用原来的堆找不到次小的数,而重新建堆则会更加繁琐。
降序用小堆同理。
动图如下:

1.2、初步代码实现
堆排序的实现可以分为两部分:构建最大堆(或最小堆)和执行排序过程。
注意:此处我们实现的是大堆!!!
第一步:建堆
我们此处是对数组内部的数进行排序,那么怎样才能创建成大堆呢?
这里我们可以使用向上调整算法,从第二个数开始遍历数组,如果不满足大堆则交换父子元素。
for (int i = 1; i < n; i++)
{
AjustUp(a, i);
}
大堆向上调整:
- 将被调整的数值与其父节点比较,若是大于父节点,则与父节点交换。
- 若子节点下标为child,父节点下标为(child - 1) / 2。
- 当子节点小于父节点时,或者当子节点已经为堆顶时,停止比较。
代码实现:
void AdjustUp(int* a, int child)
{
int parent = 0;
while (child > 0)
{
parent = (child - 1) / 2;
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
}
else
{
break;
}
}
}
小堆向上调整:
与向下调整大堆思想的唯一区别就是:将被调整的数值与父节点比较,若是小于父节点,则与父节点交换,将小根堆比较条件改为小于即可
if (a[child] < a[parent])//孩子小于父亲则交换
{
...
}每次向上调整算法的时间复杂度为O(log N)。
所以使用向上调整建好堆的时间复杂度为(N*log N)
第二步:执行排序操作
进行了向上调整之后,此时的数组就是一个大堆了,要怎样才能达到升序呢?
- 使用大根堆选出最大的数,放在数组的最后一个位置,依次选出进行排序。
- 将堆顶和最后一个数交换。
- 然后将新堆顶向下调整,形成堆。
- 向下调整时,注意交换后的最后位置不在新堆里,所以要下标要减一。
- 没有对堆结构造成破坏,不用对每个数都调整。
//2.向下调整 O(N*logN)
int end = n - 1;
while (end > 0) //从最后一个位置开始交换并调整
{
Swap(&arr[0], &arr[end]);
AdjustDown(arr, end, 0);//此处为大根堆向下调整方式
end--;
}大堆向下调整:
- 将被调整的数值与其最大的子节点比较,若是小于最大的子节点,则与该子节点交换。
- 若父节点下标为parent,左子节点下标为 parent * 2 + 1,右子节点的下标为 parent * 2 + 2。
- 获取最大的子节点时,可以先将左子节点作为最大节点,再与右子节点比较,若是大于右子节点,则将左子节点下标加1得到右子节点下标。
- 再循环体内比较左右子节点之前,要先判断右子节点存在,防止堆最后一个节点是左子节点造成越界访问。
- 当子节点小于父节点时,或者当子节点超过堆的范围时,停止比较。
//向下调整算法 大堆
void AdjustDown(int* a, int size, int parent)
{
//1.假设左孩子为小的数据
int child = parent * 2 + 1;
while (child < size)
{
//2.如果左孩子>右孩子 则将右孩子赋值
//有可能只有左孩子 所以加条件
//以下未有左右孩子且左孩子>右孩子情况,则将child++
if (child + 1 < size && a[child] < a[child + 1])
{
child++;
}
//3.将孩子与父亲进行比较 如果孩子小则交换
//然后将父亲和孩子移动到下一个位置
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}小堆向下调整:
- 将被调整的数值与其最小的子节点比较,若是大于最小的子节点,则与该子节点交换。
- 将小根堆向下调整时左右子节点的比较条件和父节点与子节点的比较改为小于即可。
if (child + 1 < size && a[child] > a[child + 1])
{
...
}
if (a[child] < a[parent])
{
...
}堆排序的代码如下:
void HeapSort(int arr[], int n)
{
assert(arr);
//1.建堆 向上调整 O(N*logN)
for (int i = 1; i < size; i++)
{
AdjustUp(arr, i);
}
//2.向下调整 O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&arr[0], &arr[end]);
AdjustDown(arr, end, 0);
end--;
}
}1.3、代码优化
在建堆的时候,我们既可以使用向上调整算法建堆,也可以使用向下调整算法建堆,在堆的应用那一弹我们计算了向下调整算法建堆的时间复杂度,对整个数组进行向下调整的时间复杂度是O(N),因此我们在堆排序的时候也可以统一使用向下调整算法!!!
向下调整:
- 向下调整是从后往前调整,先将后面构成堆,再调整上面的节点。
- 以叶子节点作为根进行向下调整是完全没有必要的,叶子节点没有子节点,所以对最后一个叶子节点的父节点开始向下调整。
- 最后一个节点下标是n-1,它的父节点为 (n-1-1) / 2。
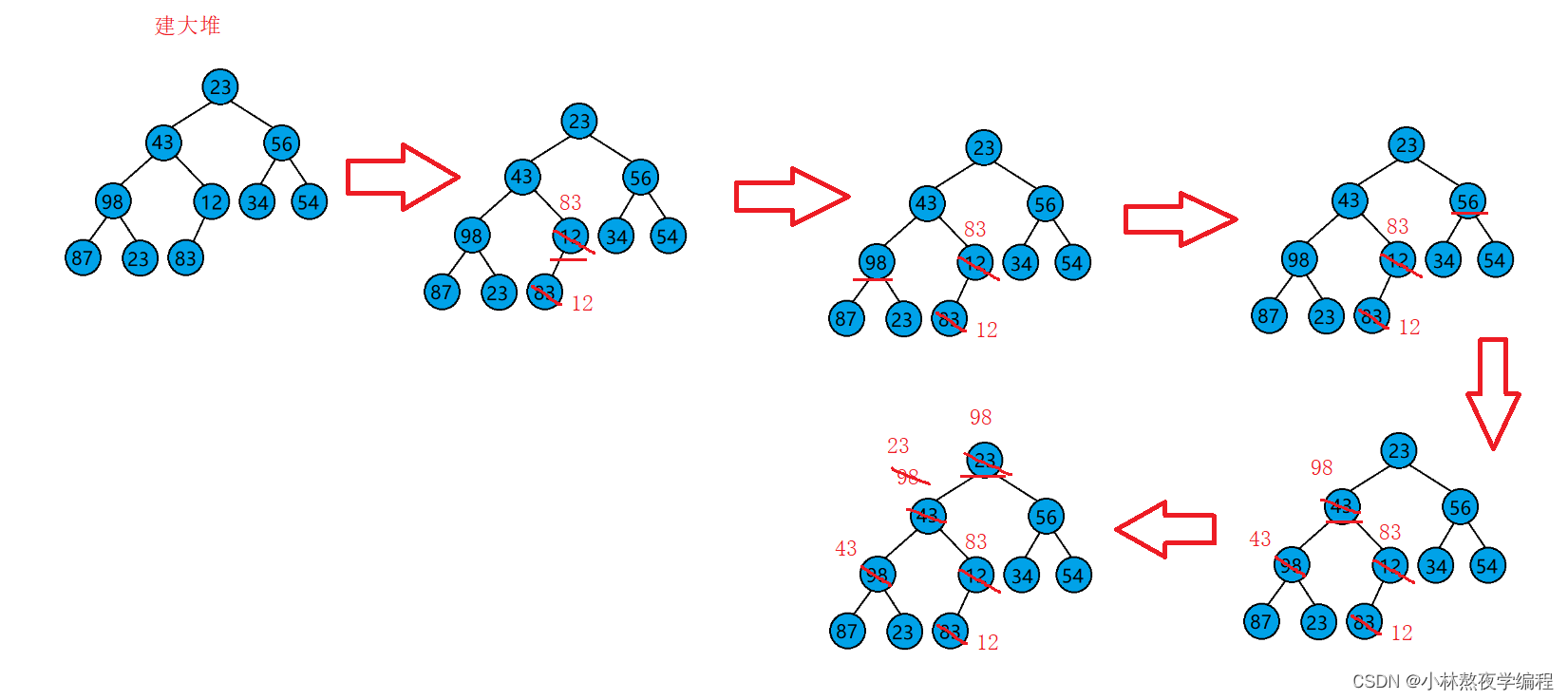
//1.向下调整建堆 O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; i--)//从n-2 到 0 进行调整
{
AdjustDown(arr, n, i);
}
堆排序代码如下:
void HeapSort(int arr[], int n)
{
assert(arr);
//1.向下调整建堆 O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; i--)//从n-2 到 0 进行调整
{
AdjustDown(arr, n, i);
}
//2.向下调整 O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&arr[0], &arr[end]);
AdjustDown(arr, end, 0);
end--;
}
}1.4、代码测试
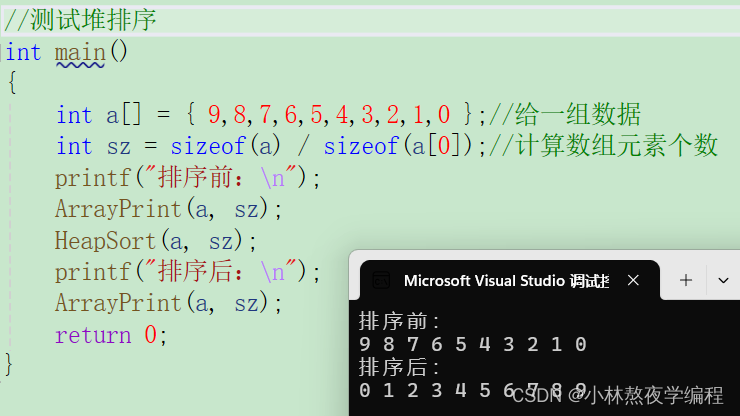
测试代码:
//测试堆排序
int main()
{
int a[] = { 9,8,7,6,5,4,3,2,1,0 };//给一组数据
int sz = sizeof(a) / sizeof(a[0]);//计算数组元素个数
printf("排序前:\n");
ArrayPrint(a, sz);
HeapSort(a, sz);
printf("排序后:\n");
ArrayPrint(a, sz);
return 0;
}测试结果:
堆排序的特性总结:
1. 堆排序使用堆来选数,效率就高了很多。
2. 时间复杂度:O(N*logN)。
3. 空间复杂度:O(1)。
4. 稳定性:不稳定。5. 复杂性:复杂。
总结
本篇博客就结束啦,谢谢大家的观看,如果公主少年们有好的建议可以留言喔,谢谢大家啦!