盘点下常见 HDFS JournalNode 异常的问题原因和修复方法
最近在多个客户现场以及公司内部环境,都遇到了因为 JournalNode 异常导致 HDFS 服务不可用的问题,在此总结下相关知识。
1 HDFS HA 高可用和 JournalNode 概述
- HDFS namenode 有 SPOF 单点故障,因为对客户端提供元数据读写服务的是单一的一个 NameNode,Secondary NameNode 仅仅提供了 HDFS 故障时的可恢复性,而没有提供整个HDFS服务的高可用性;
- 之所以说 Secondary NameNode 仅仅提供了 HDFS 故障时的可恢复性而不是高可用性,是因为 HDFS 发生故障时,Secondary NameNode 并不会自动晋升为 nameNode, 运维管理员需要介入进行手动处理后才能恢复 HDFS 对外服务;
- 在底层,Secondary NameNode 提供了 fsimage 和 editLog 的合并功能(old fsimage + edit logs = new fsimage),这一过程称为 checkpoint,是基于参数 dfs.namenode.checkpoint.period 和 dfs.namenode.checkpoint.txns,按照时间和事件共同触发的;
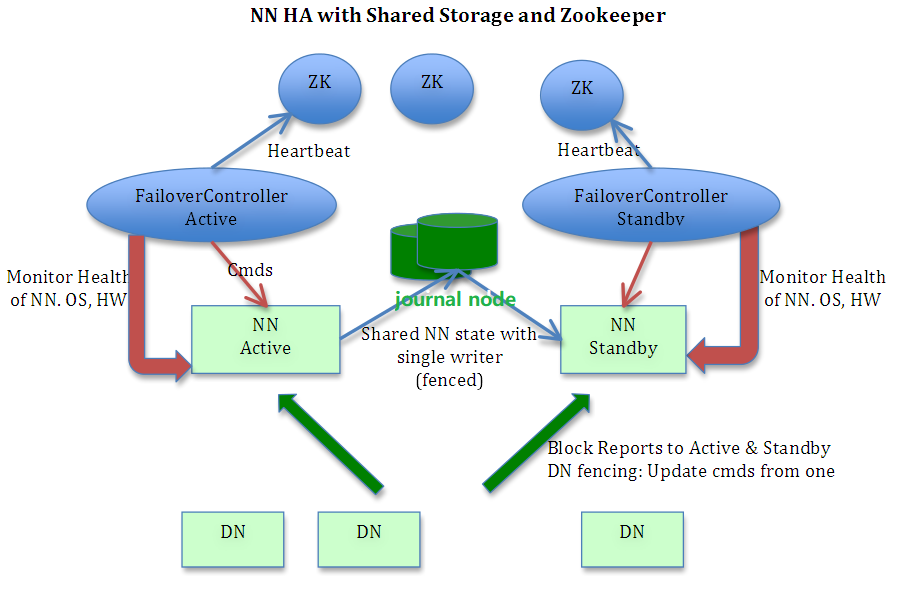
- 为解决 HDFS NAMENODE 的 SPOF,可以配置启用 HDFS 的 HA 高可用,此时其架构如下,可以看到包括 active 与 standby 两个namenode 互为主备,包括奇数个 zkfc 基于zk 提供 nn 的故障检测和自动转移,包括奇数个 JournalNode 提供两个 nn 之间共享 editLogs;
- Active Namenode 与 StandBy Namenode 为了同步 editLog 状态数据,会通过一组称作 JournalNodes 的独立进程进行相互通信: 当 active 状态的 NameNode 的命名空间有任何修改时,Active Namenode 会向 JournalNodes 中写 editlog 数据, 而 StandBy Namenode 会一直监控 JournalNodes 中 editLog 的变化,并把变化应用于自己的命名空间,从而确保两者命名空间状态的同步和一致,当 Active Namenode 故障出错时,standby Namenode 就可以不丢失数据地实时晋升为 Active Namenode 对外提供服务;
- HDFS HA 的详细架构图如下:
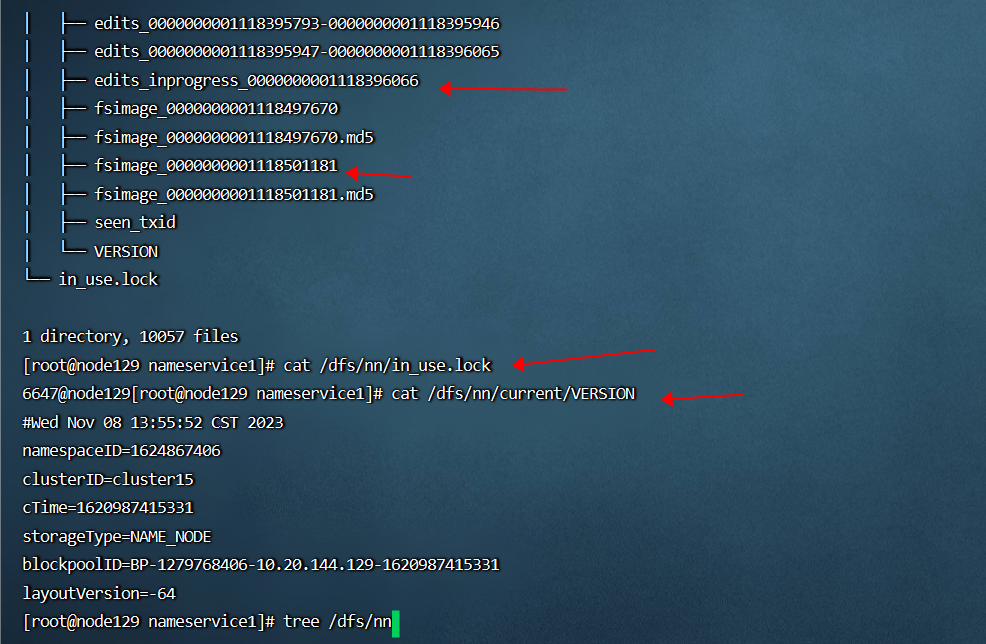
- HDFS NN 存储元数据信息的本地文件系统目录结构和关键文件如下:
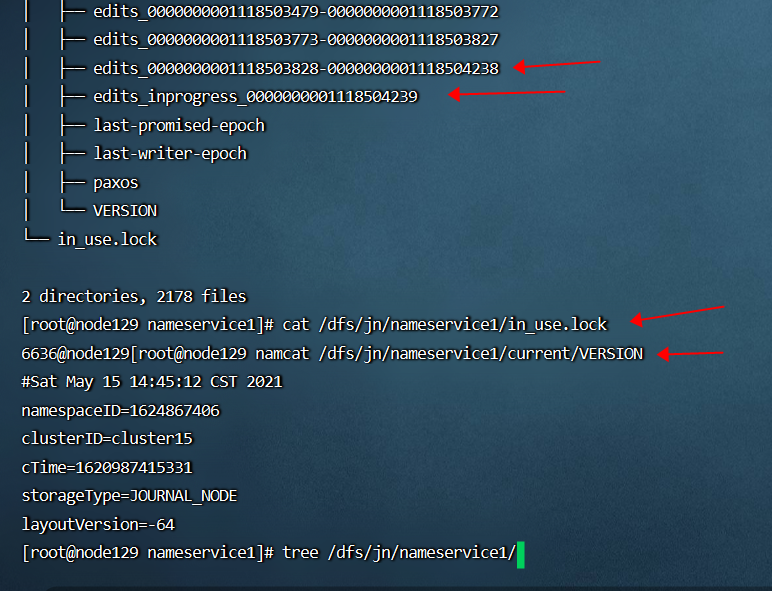
- HDFS JN 存储元数据信息的本地文件系统目录结构和关键文件如下:
- When the NameNode starts up, it reads the FsImage and EditLog from disk, applies all the transactions from the EditLog to the in-memory representation of the FsImage, and flushes out this new version into a new FsImage on disk. It can then truncate the old EditLog because its transactions have been applied to the persistent FsImage. This process is called a checkpoint;
- The secondary NameNode merges the fsimage and the edits log files periodically and keeps edits log size within a limit. It is usually run on a different machine than the primary NameNode since its memory requirements are on the same order as the primary NameNode.
- In a typical HA cluster, two or more separate machines are configured as NameNodes. At any point in time, exactly one of the NameNodes is in an Active state, and the others are in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standbys are simply acting as workers, maintaining enough state to provide a fast failover if necessary.
- In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called “JournalNodes” (JNs). When any namespace modification is performed by the Active node, it durably logs a record of the modification to a majority of these JNs. The Standby node is capable of reading the edits from the JNs, and is constantly watching them for changes to the edit log. As the Standby Node sees the edits, it applies them to its own namespace. In the event of a failover, the Standby will ensure that it has read all of the edits from the JournalNodes before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs.
- In order to provide a fast failover, it is also necessary that the Standby node have up-to-date information regarding the location of blocks in the cluster. In order to achieve this, the DataNodes are configured with the location of all NameNodes, and send block location information and heartbeats to all.- It is vital for the correct operation of an HA cluster that only one of the NameNodes be Active at a time. Otherwise, the namespace state would quickly diverge between the two, risking data loss or other incorrect results. In order to ensure this property and prevent the so-called “split-brain scenario,” the JournalNodes will only ever allow a single NameNode to be a writer at a time. During a failover, the NameNode which is to become active will simply take over the role of writing to the JournalNodes, which will effectively prevent the other NameNode from continuing in the Active state, allowing the new Active to safely proceed with failover.
- There must be at least 3 JournalNode daemons, since edit log modifications must be written to a majority of JNs. This will allow the system to tolerate the failure of a single machine. You may also run more than 3 JournalNodes, but in order to actually increase the number of failures the system can tolerate, you should run an odd number of JNs, (i.e. 3, 5, 7, etc.). Note that when running with N JournalNodes, the system can tolerate at most (N - 1) / 2 failures and continue to function normally.
2 HDFS JournalNode 异常的常见原因
- 从上述分析可知,HDFS HA 的正常工作依赖于 JournalNode 的正常工作,当集群中半数以上的 JournalNode 节点发生异常后,HDFS HA 就无法正常工作了;
- 由于 JournalNode 如此重要,绝大部分的大数据集群管理软件如 ClouderaManager/Ambari等,都会监控 JournalNode 并在其异常时发送告警通知;
- 如下即是 ClouderaManager 对 JN 同步状态和磁盘空间常见的的监控报警信息:
- The health test result for JOURNAL_NODE_SYNC_STATUS has become bad: The active NameNode is out of sync with this JournalNode.
- This role's JournalNode Edits Directory is on a filesystem with less than 10.0 GiB of its space free. /dfs/jn (free: 4.0 GiB (2.68%), capacity: 149.9 GiB)
- 造成 HDFS JournalNode 异常的常见原因有:
- JournalNode 节点的本地磁盘故障或磁盘满,导致写入的 editLog 数据异常;
- JournalNode 节点异常并重装了操作系统;
- 出于扩展集群的需求,新增了JournalNode 节点;
3 HDFS JournalNode 异常的常规修复方法
HDFS JournalNode 异常,大体应该遵循如下逻辑进行修复:
- 准备工作:确定当前可以正常工作的 JournalNode 节点,其 editLog 文件的存放位置(即参数dfs.journalnode.edits.dir的值),以及当前最新的 editLog 文件 (各个节点各个 editLog 文件的文件名中都包含了递增的 sequence number 序列号,比如历史 editLog 文件 edits_0000000000056586378-0000000000056586407 和 当前 editLog 文件 edits_inprogress_0000000000056586408,序列号最大的即是最新的 editLog 文件);
- 停止 HDFS 集群;
- 删除 editLog 脏数据:如果是 JournalNode 节点的本地磁盘故障或磁盘满,则修复/更换磁盘或清理磁盘空间,并删除已经写入的异常的 editLog 文件(也可以删除 dfs.journalnode.edits.dir目录下的所有子目录和文件,包括 VERSION 文件, edits 文件等;删除前建议先备份);
- 恢复 editLog 数据:从当前可以正常工作的 JournalNode 节点,拷贝其正常的 editLog 数据文件,可以拷贝 dfs.journalnode.edits.dir目录下的所有子目录和文件,包括 VERSION 文件, edits 文件等 (事实上只拷贝 VERSION 文件和最新的 editLog 文件也可以,此时后续启动 JournalNode 后,会自动拷贝其它历史 editLog);
- 确保拷贝过来的所有文件的用户和用户组是HDFS:chown -R hdfs:hdfs ./*;
- 启动 HDFS 服务,查看日志,确保恢复正常;
- 问题 journalnode 节点修复重启后,自动同步和滚动 editLog 的部分日志如下:
2023-11-08 14:19:03,112 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer: Downloaded file edits_0000000000056292183-0000000000056292202 of size 2367 bytes.
2023-11-08 14:19:03,113 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer: Downloading missing Edit Log from http://uf30-2:8480/getJournal?jid=ns1&segmentTxId=56292203&storageInfo=-64%3A1693184092%3A1603367087970%3Acluster12&inProgressOk=false to /dfs/jn/ns1
2023-11-08 14:19:03,159 INFO org.apache.hadoop.hdfs.server.common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 4000.00 KB/s. Synchronous (fsync) write to disk of /dfs/jn/ns1/edits.sync/edits_0000000000056292203-0000000000056292232 took 0.00s.
2023-11-08 16:02:32,313 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer: Syncing Journal /192.168.71.70:8485 with uf30-2/192.168.71.71:8485, journal id: ns1
2023-11-08 16:03:18,694 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Finalizing edits file /dfs/jn/ns1/current/edits_inprogress_0000000000056587366 -> /dfs/jn/ns1/current/edits_0000000000056587366-0000000000056587395
2023-11-08 16:03:18,856 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /dfs/jn/ns1/current/edits_0000000000056587366-0000000000056587395, fileSize: 4142. Sent total: 4142 bytes. Size of last segment intended to send: -1 bytes.
4 HDFS JournalNode 异常修复时遇到的常见问题
- JournalNotFormattedException:即 Journal 未格式化异常,这种错误经常出现在重装 Journal 节点操作系统时,或添加新 Journal 节点时,修复方法为从其它正常 Journal 节点拷贝 VERSION 文件即可,详细报错如下:
org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: journal storage directory /dfs/jn/nameservice1 not formatted
- editLog 过期损坏异常:这种错误经常出现在某个 Journal节点因磁盘异常或其它原因,长期没有跟其它 Journal 节点同步 editLog 数据,导致其最新的 editLog 文件(即edits_inprogressxxx 文件)过期异常,修复方法为按照上述步骤,删除其异常的 edits_inprogressxxx 文件或全部的 editLog文件,然后重启 Journal 角色即可(重启后会自动从其它正常 Journal 节点拷贝 editLog 文件),详细报错如下:
FSImage Caught exception after scanning through 0 ops from /dfs/jn/ns1/current/edits_inprogress_0000000000055367073 while determining its valid length. Position was 229376
java.io.IOException: Can't scan a pre-transactional edit log.
at org.apache.hadoop.hdfs.server.namenode.FSEditLogOp$LegacyReader.scanOp(FSEditLogOp.java:5264)
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.scanNextOp(EditLogFileInputStream.java:243)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.scanEditLog(FSEditLogLoader.java:1248)
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.scanEditLog(EditLogFileInputStream.java:327)
at org.apache.hadoop.hdfs.server.namenode.FileJournalManager$EditLogFile.scanLog(FileJournalManager.java:566)
at org.apache.hadoop.hdfs.qjournal.server.Journal.scanStorageForLatestEdits(Journal.java:210)
at org.apache.hadoop.hdfs.qjournal.server.Journal.<init>(Journal.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:99)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:145)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.getEditLogManifest(JournalNodeRpcServer.java:216)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.getEditLogManifest(QJournalProtocolServerSideTranslatorPB.java:228)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27411)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
- /dfs/jn/ns1/in_use.lock 文件锁异常:这种错误经常出现在目录 /dfs/jn 或其子目录和文件的 owner/group 不是 JournalNode 进程的启动用户(一般是HDFS:HDFS),或者异常启动了多个 JournalNode 进程, 修复方法为更改 /dfs/jn 目录及其子目录和文件的 owner/group 为 JournalNode 进程的启动用户,(chown -R hdfs:hdfs /dfs/jn)并重启 JournalNode 服务进程,详细报错如下:
It appears that another node 165959@uf30-1 has already locked the storage directory: /dfs/jn/ns1
java.nio.channels.OverlappingFileLockException
at sun.nio.ch.SharedFileLockTable.checkList(FileLockTable.java:255)
at sun.nio.ch.SharedFileLockTable.add(FileLockTable.java:152)
at sun.nio.ch.FileChannelImpl.tryLock(FileChannelImpl.java:1107)
at java.nio.channels.FileChannel.tryLock(FileChannel.java:1155)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.tryLock(Storage.java:841)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.lock(Storage.java:809)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.analyzeStorage(Storage.java:622)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.analyzeStorage(Storage.java:573)
at org.apache.hadoop.hdfs.qjournal.server.JNStorage.analyzeAndRecoverStorage(JNStorage.java:253)
at org.apache.hadoop.hdfs.qjournal.server.JNStorage.<init>(JNStorage.java:77)
at org.apache.hadoop.hdfs.qjournal.server.Journal.<init>(Journal.java:153)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:99)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:145)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.getEditLogManifest(JournalNodeRpcServer.java:216)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.getEditLogManifest(QJournalProtocolServerSideTranslatorPB.java:228)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27411)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
xxx
IPC Server handler 4 on 8485, call Call#4204 Retry#0 org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocol.getEditLogManifest from 192.168.71.71:35892
java.io.IOException: Cannot lock storage /dfs/jn/ns1. The directory is already locked
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.lock(Storage.java:814)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.analyzeStorage(Storage.java:622)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.analyzeStorage(Storage.java:573)
at org.apache.hadoop.hdfs.qjournal.server.JNStorage.analyzeAndRecoverStorage(JNStorage.java:253)
at org.apache.hadoop.hdfs.qjournal.server.JNStorage.<init>(JNStorage.java:77)
at org.apache.hadoop.hdfs.qjournal.server.Journal.<init>(Journal.java:153)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:99)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:145)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.getEditLogManifest(JournalNodeRpcServer.java:216)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.getEditLogManifest(QJournalProtocolServerSideTranslatorPB.java:228)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27411)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)