通过python的pymysql库连接到本地的MySQL数据库,并执行查询操作来获取数据,然后打印出每一行的数据,这里以一个简单的学生表为例进行介绍。
1. MySQL的安装与数据准备
首先需要安装MySQL,在安装完成之后使用Navicat与本地数据库进行增删查改操作。首先使用SQL(结构化查询语言)与本地数据库进行交互。
安装好后可以输入密码,再输入命令“show databases;”,即可查看本地MySQL的suo’you’的所有数据库。

在Navicat中首先新建一个名为“mydatabase”的数据库,然后新建查询,输入以下代码即可在mydatabase数据库中创建一个表。
SQL代码:
use mydatabase;
create table student (
id INT,
name VARCHAR(100),
age INT
);
DESC student;
INSERT INTO student (id, name, age) VALUES (5, 'Cheney',18);
select * from student;

建立了一个名为‘student’的表:

2.使用pymysql对本地数据库进行交互
代码示例:
import pymysql # 该Python库允许与MySQL数据库进行交互
# try:
# except Exception :print("查询失败")
# 获取一个数据库连接,注意如果是UTF-8类型的,需要制定数据库
'''
使用pymysql.connect方法创建与MySQL数据库的连接,具体参数包括:
host='localhost':数据库服务器地址
user='root':数据库用户名
passwd='xxxx':用户密码,是自己设定的
db='mydatabase':要连接的数据库名
port=3306:数据库服务器的端口号
charset='utf8':使用的字符集类型,这里指定为UTF-8
'''
conn=pymysql.connect(host='localhost',user='root',passwd='111111',db='mydatabase',port=3306,charset='utf8')
cur=conn.cursor() # 获取一个游标,游标对象用于在数据库上执行操作,可以通过游标来执行SQL语句
cur.execute('select * from student') # 使用游标的execute方法执行一个SQL查询,这里查询student表的所有数据。
data=cur.fetchall() # fetchall方法获取查询结果的所有行,返回一个元组列表,每个元组代表一行数据
for d in data : # 遍历查询结果,每次循环处理一行数据。d[0]、d[1] 和 d[2] 分别代表每行数据的第一个(ID)、第二个(用户名)和第三个(年龄)元素。由于ID和年龄可能是整数类型,所以使用str函数将它们转换为字符串,以便可以与其他字符串一起打印
print("ID: "+str(d[0])+'用户名:'+d[1]+'年龄'+str(d[2]))
cur.close() # 关闭游标
conn.close() # 释放数据库资源
运行结果:


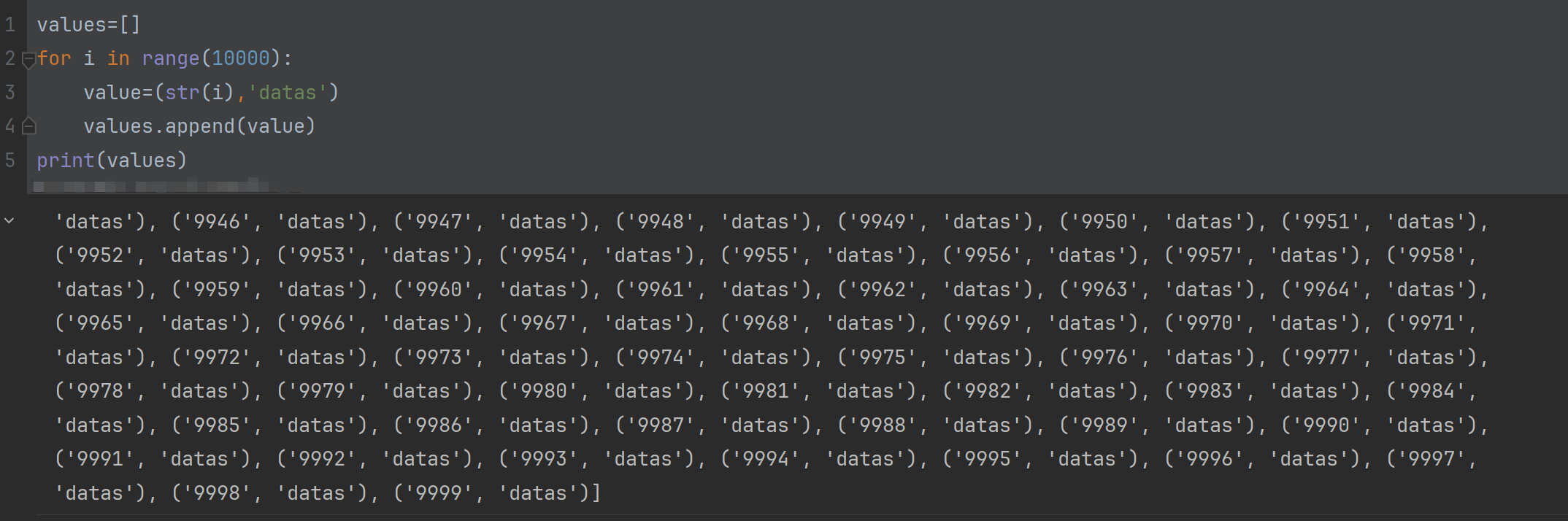
下面的代码展示如何使用循环和列表操作来批量生成数据结构,并存储在列表中。这种方法在处理大量数据生成或批量初始化数据时非常有用。
代码示例:
values=[] # 初始化空列表
for i in range(10000): # 生成一个从0到9999的整数序列
value=(str(i),'datas') # 每次循环中当前循环的索引i将被转换为字符串(str(i)),然后与字符串 'datas' 一起创建一个元组。这个元组包含两个元素:一个是字符串形式的索引,另一个是固定的字符串
values.append(value) # 将创建的元组添加到列表
print(values)
运行结果:
以上内容总结自网络,整理不易,如有帮助欢迎转发,我们下次再见!




![【计算机网络】[第4章 网络层][自用]](https://img-blog.csdnimg.cn/direct/45e73d08c6614a32b73427f3ff22e7c7.png)