L-MTL(Large Multi-Task Learning)Models 是一种大规模多任务学习模型,通过结合 Mixture of Experts(MMoE)框架与 Transformer 模型,实现对 TTS(Text-to-Speech)系统中多个评估指标的全面平衡评价。
1 L-MTL Models 的基本架构和工作机制

- 说明了 L-MTL 的评价指标如何构建,通过减少模型复杂度,保持核心评价标准,同时利用多任务学习和专家网络来支持各种评估任务。
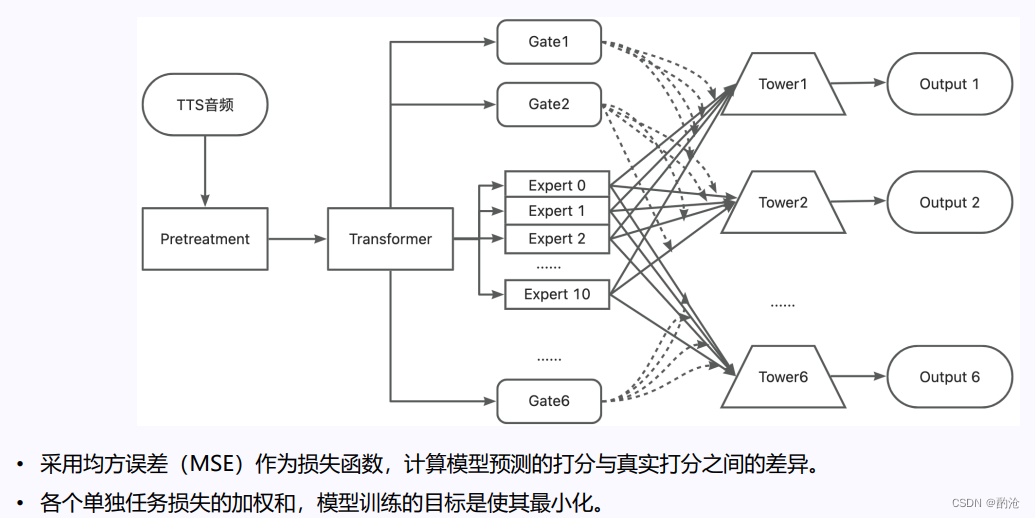
- 描绘了 L-MTL 的内部工作机制,包括预处理、Transformer 特征提取、多专家网络选择和任务塔网络输出。每个组件协同工作,确保模型能够动态适应和处理复杂的 TTS 评估任务。
L-MTL Models 提供了一种高效、灵活的 TTS 评估解决方案,通过多任务学习和 Mixture of Experts 框架,实现了对语音信号的细致分析和评估。这个架构通过特征提取、专家选择和动态任务分配,实现了跨层级的综合代码覆盖分析和评价能力。
2 L-MTL Models 架构
2.1 模型评价指标(Model Evaluation Metrics)
图中显示了 L-MTL 模型的多维度评价指标,用于评估 TTS 系统的各个方面。主要包括:
- 发音准确性:整合多音字、中英混合、符号、数字的准确性。
- 音质:整体清晰度、杂音、混音等。
- 韵律:整合轻重音、高低音、语速、停顿等。
- 情感:语音中表达的情感。
- 口语化:自然流畅程度。
- 音色:声音的独特性和一致性。
2.2 指标聚合和架构
- 指标聚合:将相关性高的二级指标替换为一级指标,减少模型复杂度的同时,维持核心评价标准。
- 架构:L-MTL 使用 MMoE(Mixture of Experts)框架结合 Transformer 特征提取,为每个相关的评估任务提供支持。
2.3 多任务学习模型(L-MTL Models)
- L-MTL Models:大规模多任务学习模型。
- MMoE(Mixture of Experts)框架:动态确定最适合处理特定评估任务的专家网络。
2.4 Transformer
在 L-MTL 中,Transformer 结构用于从 TTS 音频信号中提取丰富的特征,准确捕捉语音信号的微妙变化。其工作流程如下:
-
输入(TTS 音频):
- 原始 TTS 音频输入到预处理模块。
-
预处理(Pretreatment):
- 对音频数据进行处理,如降噪、标准化等。
-
Transformer:
- 使用 Transformer 提取特征,捕捉音频数据中的复杂模式。
2.5 Mixture of Experts (MMoE) 框架
MMoE 框架:结合多个专家(Experts),通过门控机制(Gates)选择最适合的专家来处理特定任务。详细结构如下:
-
Gates:
- Gate1, Gate2, … Gate6:门控网络决定将输入分配给哪些专家。每个 Gate 选择不同的专家组合,以优化特定任务。
-
Experts:
- Expert 0, Expert 1, … Expert 10:不同的专家网络,擅长处理特定类型的任务。
- 通过不同专家的特长,模型能够动态适配不同任务的需求。
-
Towers:
- Tower1, Tower2, … Tower6:塔网络,用于整合专家网络的输出,生成每个任务的最终输出。
2.6 输出(Outputs)
每个塔网络输出具体的任务结果,如音质评价、韵律分析等。这些输出被用来评估 TTS 系统的整体性能。
2.7 损失函数
- 均方误差(MSE):用于计算模型预测得分与实际得分之间的差异,目标是最小化模型训练过程中的损失。
3 工作机制
3.1 细节捕捉
- 特征提取:结合 Transformer 架构,L-MTL 能够从音频信号中提取丰富的特征。
3.2 智能任务分配
- 动态分配:MMoE 框架中,门控机制动态选择专家处理特定任务,提高模型的准确性。
3.3 知识共享
- 共享知识:不同任务间能够共享学习到的知识,提升模型整体的效率和泛化能力。
3.4 模型灵活性
- 模块化设计:L-MTL 的模块化设计使得模型易于扩展和定制,适应不同的 TTS 评价需求和研究方向。