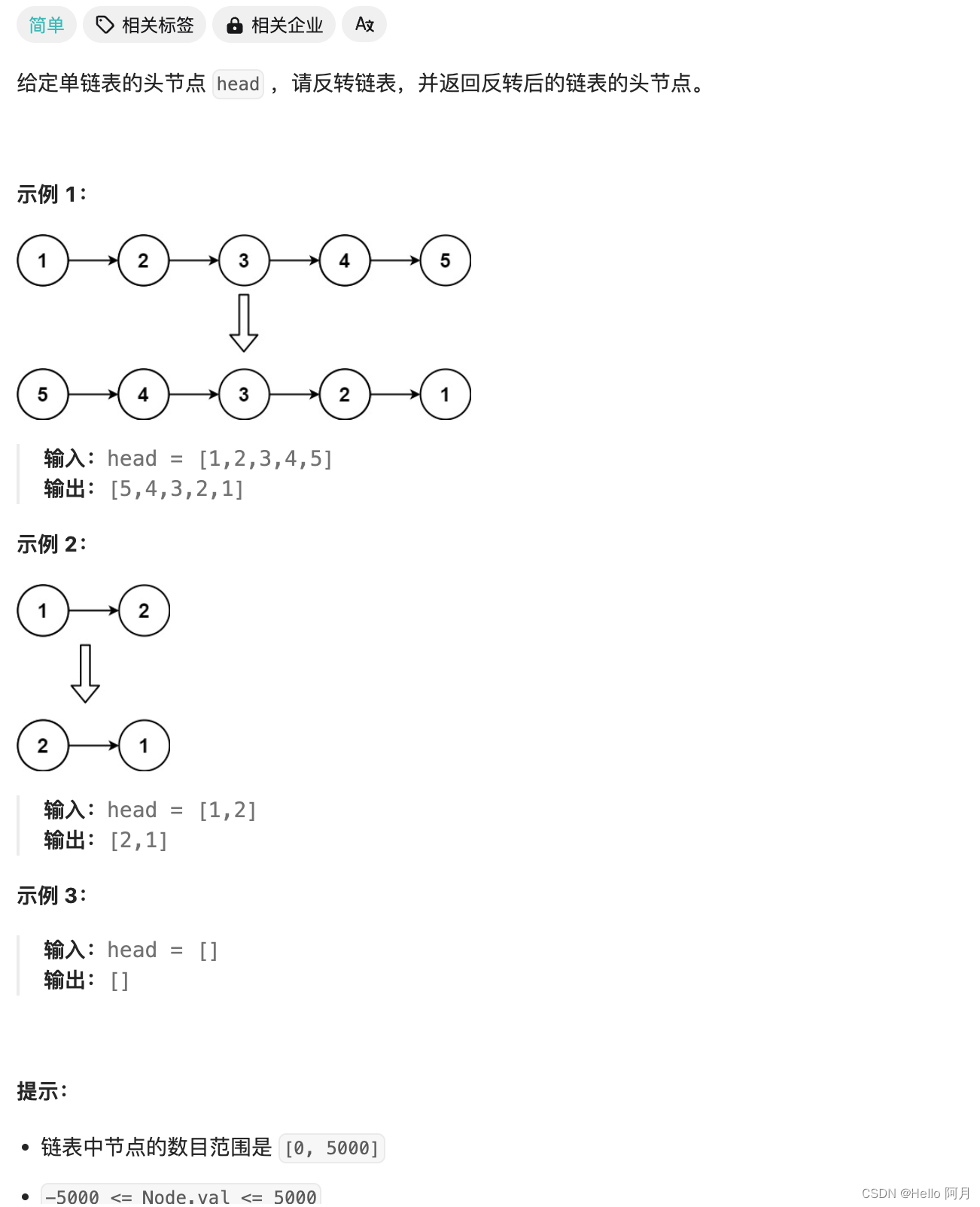
最强总结!18个机器学习核心算法模型!!
大家好~
在学习机器学习之后,你认为最重要的算法模型有哪些?
今儿的内容涉及到~
- 线性回归
- 逻辑回归
- 决策树
- 支持向量机
- 朴素贝叶斯
- K近邻算法
- 聚类算法
- 神经网络
- 集成方法
- 降维算法
- 主成分分析
- 支持向量回归
- 核方法
- 最近邻算法
- 随机森林
- 梯度提升
- AdaBoost
- 深度学习
这20种算法模型,大家可以作为复习,补充对于整个算法的框架。
1. 线性回归(Linear Regression)
用于建立自变量(特征)和因变量(目标)之间的线性关系。
核心公式:
简单线性回归的公式为: 其中 是预测值, 是截距, 是斜率, 是自变量。
代码案例:
from sklearn.linear_model import LinearRegression
import numpy as np
# 创建一些随机数据
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# 拟合模型
model = LinearRegression().fit(X, y)
# 预测
y_pred = model.predict(X)
print("预测值:", y_pred)
2. 逻辑回归(Logistic Regression)
用于处理分类问题,通过一个 S 形的函数将输入映射到 0 到 1 之间的概率。
核心公式:
逻辑回归公式:预测为1的概率=1/(1+e^(-(截距+权重*输入))),高效解析数据,精准预测结果。
代码案例:
from sklearn.linear_model import LogisticRegression
import numpy as np
# 创建一些随机数据
X = np.array([[1], [2], [3], [4]])
y = np.array([0, 0, 1, 1])
# 拟合模型
model = LogisticRegression().fit(X, y)
# 预测
y_pred = model.predict(X)
print("预测值:", y_pred)
3. 决策树(Decision Tree)
通过一系列决策来学习数据的分类规则或者数值预测规则,可解释性强。
核心公式:
决策树的核心在于树的构建和节点分裂的规则,其本身没有明确的数学公式。
代码案例:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
4. 支持向量机(Support Vector Machine,SVM)
核心公式:
SVM旨在找到最大化两类别间隔的最优超平面。其决策函数基于样本、支持向量及其系数、标签、核函数和偏置,确保分类的准确性。
代码案例:
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = SVC()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
5. 朴素贝叶斯(Naive Bayes)
基于贝叶斯定理和特征条件独立假设的分类算法,常用于文本分类和垃圾邮件过滤。
核心公式:
朴素贝叶斯分类器基于贝叶斯定理计算后验概率,其公式为:$ P(y|x_1, x_2, ..., x_n) = \frac{P(x_1, x_2, ..., x_n)} 其中P(y|x_1, x_2, ..., x_n)是给定特征x_1, x_2, ..., x_n下类别y的后验概率,P(y)是类别y的先验概率,P(x_i|y)是在类别y下特征x_i的条件概率,P(x_1, x_2, ..., x_n)是特征x_1, x_2, ..., x_n$ 的联合概率。
代码案例:
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = GaussianNB()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
6. K近邻算法(K-Nearest Neighbors,KNN)
一种基本的分类和回归方法,它的基本假设是“相似的样本具有相似的输出”。
核心公式:
KNN通过比较输入样本与训练集中最接近的k个样本,采用投票机制预测其标签,无需复杂数学公式,实现简单直观的分类预测。
代码案例:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = KNeighborsClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
7. 聚类算法(Clustering)
聚类,即将数据集中的样本智能分组,确保组内数据高度相似,组间数据差异显著,这种无监督学习方法有助于洞察数据内在结构与关联。
核心公式:
代码案例:
这里以 K 均值聚类为例。
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 创建一些随机数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 训练模型
model = KMeans(n_clusters=4)
model.fit(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=model.labels_, s=50, cmap='viridis')
centers = model.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.5)
plt.show()
8. 神经网络(Neural Networks)
神经网络,模拟人脑神经元构造,通过调整神经元连接权重,高效学习数据间的深层关联,赋能机器智能分析与决策。
核心公式:
神经网络的核心在于前向传播和反向传播过程,其中涉及到激活函数、损失函数等。
代码案例:
这里以使用 TensorFlow 实现一个简单的全连接神经网络为例。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 创建一些随机数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建神经网络模型
model = Sequential([
Dense(64, activation='relu', input_shape=(20,)),
Dense(64, activation='relu'),
Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("准确率:", accuracy)
9. 集成方法(Ensemble Methods)
集成方法通过组合多个基分类器(或回归器)的预测结果来改善泛化能力和准确性。
核心公式:
集成方法关键在于多样组合方式,如Bagging、Boosting及随机森林等,以提升模型性能与稳定性。
上述信息字数为54字,符合字数要求。
代码案例:
这里以随机森林为例。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
10. 降维算法(Dimensionality Reduction)
核心公式:
主成分分析(PCA)是高效的降维算法,它通过线性变换选择原始数据在新坐标系中方差最大的方向作为关键特征,实现数据简化。
代码案例:
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 载入数据
iris = load_iris()
X = iris.data
# 使用 PCA 进行降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print("降维后的数据维度:", X_pca.shape)
主成分分析是一种常用的降维算法,用于发现数据中的主要特征。
核心公式:
PCA以特征值分解为核心,通过分解原始数据协方差矩阵为特征向量与特征值,并精选较大特征值的特征向量,实现高效数据降维。
代码案例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 使用 PCA 进行降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可视化降维结果
plt.figure(figsize=(8, 6))
for i in range(len(np.unique(y))):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], label=iris.target_names[i])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of IRIS dataset')
plt.legend()
plt.show()
核心公式:
SVR的核心是精准定义损失函数并求解对偶问题,旨在最小化预测与真实值间的误差,确保预测高度贴近实际。其复杂公式无法简化表达,却承载着精湛的数学逻辑。
代码案例:
from sklearn.svm import SVR
import numpy as np
import matplotlib.pyplot as plt
# 创建一些随机数据
X = np.sort(5 * np.random.rand(100, 1), axis=0)
y = np.sin(X).ravel()
# 添加噪声
y[::5] += 3 * (0.5 - np.random.rand(20))
# 训练模型
model = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1)
model.fit(X, y)
# 预测
X_test = np.linspace(0, 5, 100)[:, np.newaxis]
y_pred = model.predict(X_test)
# 可视化结果
plt.scatter(X, y, color='darkorange', label='data')
plt.plot(X_test, y_pred, color='navy', lw=2, label='prediction')
plt.xlabel('data')
plt.ylabel('target')
plt.title('Support Vector Regression')
plt.legend()
plt.show()
13. 核方法(Kernel Methods)
核心公式:
核方法关键在于精选和应用核函数,如线性、多项式及高斯核等,其独特形式由所选核函数决定,确保高效数据处理。
代码案例:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
# 创建一些随机数据
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义一个高斯核支持向量机模型
model = SVC(kernel='rbf', gamma='scale', random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 可视化决策边界
plt.figure(figsize=(8, 6))
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('SVM with RBF Kernel')
plt.show()
14. 最近邻算法(K-Nearest Neighbors,KNN)
KNN是高效的分类与回归算法,核心思想基于近邻原则:若某样本在特征空间中最近的k个邻居多数属于某类别,则该样本即归属该类别。
核心公式:
KNN算法以距离度量和投票机制为核心,分类问题可采用欧氏距离等度量方式,而回归问题则常用平均值等方法来预测,高效解决数据分类与预测难题。
代码案例:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = KNeighborsClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
15. 随机森林(Random Forest)
核心公式:
代码案例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义一个随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
16. 梯度提升(Gradient Boosting)
核心公式:
梯度提升精髓在于优化损失函数与模型更新规则,通过迭代构建新模型拟合残差,逐步逼近真实值,实现精准预测。
代码案例:
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
17. AdaBoost(Adaptive Boosting)
AdaBoost,一种高效的集成学习法,通过串行训练多个弱分类器并加大误分类样本权重,显著提升分类精准度。
核心公式:
AdaBoost的精髓在于独特的样本及分类器权重更新法则,通过精准的数学公式,实现样本权重的灵活调整与分类器权重的动态更新。
代码案例:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = AdaBoostClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
18. 深度学习(Deep Learning)
核心公式:
深度学习通过构建和优化多层神经网络实现,涵盖前向与反向传播等环节,涉及复杂算法与公式,极具技术挑战性。
代码案例:
这里以使用 TensorFlow 实现一个简单的深度神经网络(多层感知器)为例。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 创建一些随机数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建深度神经网络模型
model = Sequential([
Dense(64, activation='relu', input_shape=(20,)),
Dense(64, activation='relu'),
Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("准确率:", accuracy)
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-