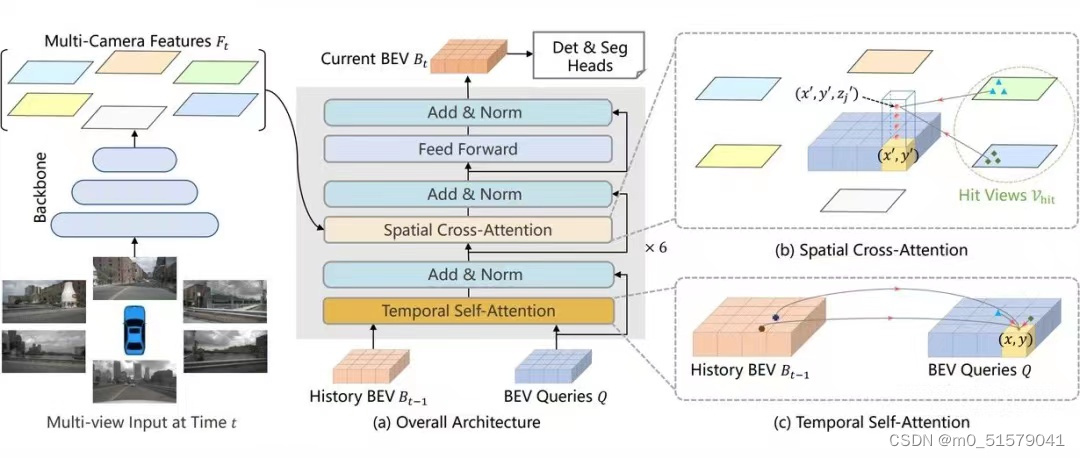
大家好,在PyTorch中进行高级张量操作时,开发者经常面临这样的问题,如何根据一个索引张量从另一个张量中选取元素。
例如有一个包含数千个特征的大规模数据集,需要根据特定的索引模式快速提取信息。本文将介绍三种索引选择方法来解决这类问题。
1 torch.index_select
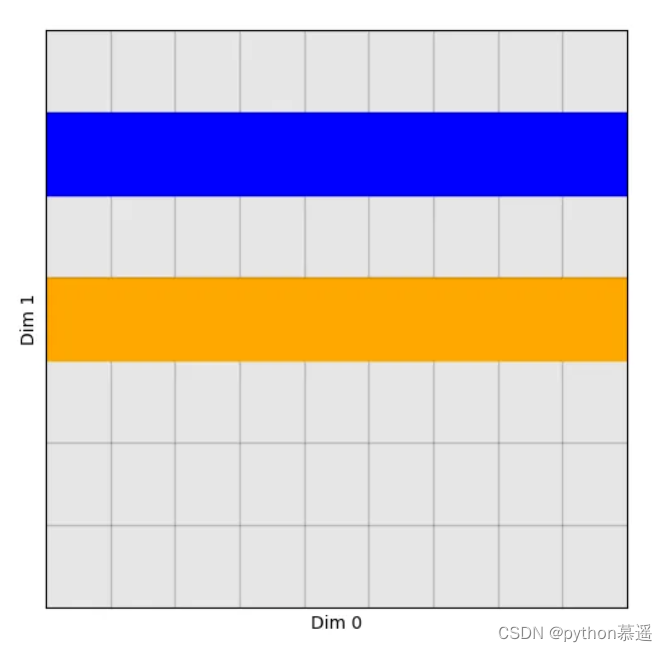
torch.index_select函数通过在指定的维度上进行元素选择,同时在其他维度上保持元素不变。也就是说,在目标维度上根据索引张量来挑选元素,而其他维度的元素则原封不动。为了更直观地理解这一概念,来看一个2D张量的示例,这里将沿着维度1进行元素的选择:
num_picks = 2
values = torch.rand((len_dim_0, len_dim_1))
indices = torch.randint(0, len_dim_1, size=(num_picks,))
# [len_dim_0, num_picks]
picked = torch.index_select(values, 1, indices)
由此得到的张量形状为[len_dim_0, num_picks]:对于维度0上的每个元素,都从维度1中选取了相同的元素。将其形象化:
现在迈入三维张量的世界,这样更贴近机器学习与数据科学的实际需求。
设想一个三维张量,其维度为[batch_size, num_elements, num_features]:num_elements表示每个批次中的项目数,每个项目具有num_features个特征。这种张量结构所有元素都是以批量方式处理的。
import torch
batch_size = 16
num_elements = 64
num_features = 1024
num_picks = 2
values = torch.rand((batch_size, num_elements, num_features))
indices = torch.randint(0, num_elements, size=(num_picks,))
# [batch_size, num_picks, num_features]
picked = torch.index_select(values, 1, indices)
若更倾向于通过代码来理解index_select的功能,以下是使用简单的for循环来模拟该功能实现的示例:
picked_manual = torch.zeros_like(picked)
for i in range(batch_size):
for j in range(num_picks):
for k in range(num_features):
picked_manual[i, j, k] = values[i, indices[j], k]
assert torch.all(torch.eq(picked, picked_manual))
2 torch.gather
torch.gather函数在功能上与torch.index_select相似,但提供了更为灵活的元素选择方式。
在torch.gather中,选择的元素不仅取决于索引张量,还受到其他维度的影响。以机器学习项目为例,可以针对每个批次和每个特征,根据条件从元素维度中选取不同的元素,实现这一点是通过使用另一个张量来指定索引。
在实际应用中,这种用法非常普遍,比如在决策树中根据特定条件选择节点。
每个节点由一组特征定义,可以创建一个索引矩阵,将选定的元素放置在批次维度上,并在特征维度上复制这些值。这样,对于每个批次索引,都可以基于特定条件选择不同的元素,尽管在我们的示例中,这些条件仅与批次索引相关,但也可以根据特征索引来确定。
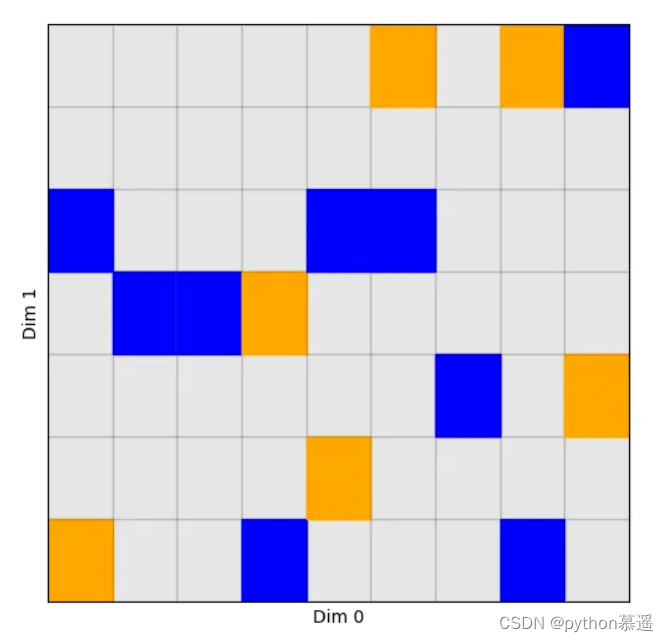
为了更清楚地理解这一点,再次从二维(2D)示例开始,逐步展示如何使用torch.gather来实现这种灵活的索引选择。
num_picks = 2
values = torch.rand((len_dim_0, len_dim_1))
indices = torch.randint(0, len_dim_1, size=(len_dim_0, num_picks))
# [len_dim_0, num_picks]
picked = torch.gather(values, 1, indices)
直观来看,torch.gather的元素选择呈现出与torch.index_select不同的模式。不同于后者沿直线进行选择,torch.gather根据维度0上的每个索引,在维度1中挑选出不同的元素:
接下来进入三维世界,并展示如何用Python代码来实现类似的选择机制:
import torch
batch_size = 16
num_elements = 64
num_features = 1024
num_picks = 5
values = torch.rand((batch_size, num_elements, num_features))
indices = torch.randint(0, num_elements, size=(batch_size, num_picks, num_features))
picked = torch.gather(values, 1, indices)
picked_manual = torch.zeros_like(picked)
for i in range(batch_size):
for j in range(num_picks):
for k in range(num_features):
picked_manual[i, j, k] = values[i, indices[i, j, k], k]
assert torch.all(torch.eq(picked, picked_manual))
3 torch.take
在三个函数中,torch.take的工作原理最为简单明了。它首先将输入张量视为一维数组,然后根据指定的索引从中选取元素。
例如,对于一个4行5列的张量,如果使用torch.take并选取索引6和19,实际上获取的是这个张量在一维化之后位于第6个位置和第19个位置的元素,分别对应于原始二维结构中的第2行第2列和最后一行最后一列的元素。
2D示例:
num_picks = 2
values = torch.rand((len_dim_0, len_dim_1))
indices = torch.randint(0, len_dim_0 * len_dim_1, size=(num_picks,))
# [num_picks]
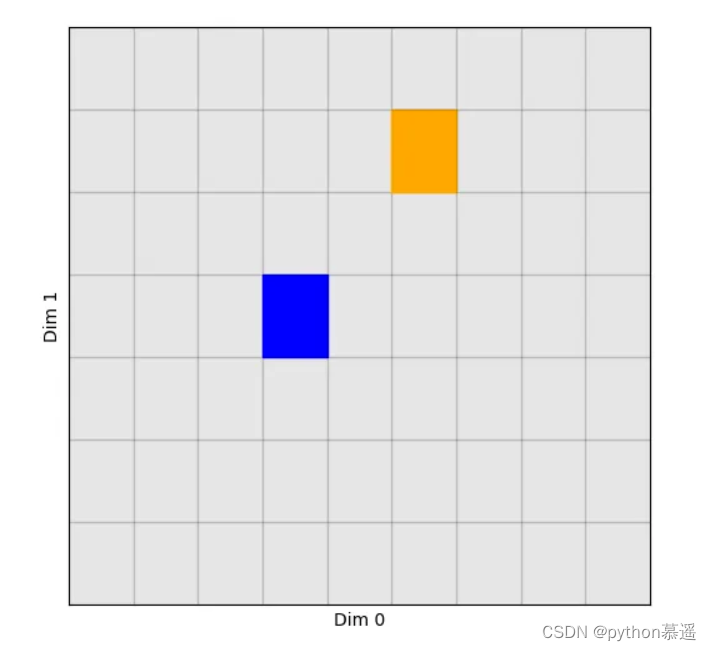
picked = torch.take(values, indices)
现在得到了两个元素:
接下来探讨三维张量的索引选择及其实现。索引张量不受固定形状的限制,可以是任意形状。根据这个索引张量进行的元素选择,其结果也将遵循这种形状,确保输出与索引张量的维度结构一致。
import torch
batch_size = 16
num_elements = 64
num_features = 1024
num_picks = (2, 5, 3)
values = torch.rand((batch_size, num_elements, num_features))
indices = torch.randint(0, batch_size * num_elements * num_features, size=num_picks)
# [2, 5, 3]
picked = torch.take(values, indices)
picked_manual = torch.zeros(num_picks)
for i in range(num_picks[0]):
for j in range(num_picks[1]):
for k in range(num_picks[2]):
picked_manual[i, j, k] = values.flatten()[indices[i, j, k]]
assert torch.all(torch.eq(picked, picked_manual))本文介绍了Pytorch中的三种常见选择方法:torch.index_select、torch.gather和torch.take。可以使用这些方法,根据不同的条件从张量中选取或索引特定的元素。
对于每种方法,都先通过简单的二维(2D)示例引入,并直观地展示了选择结果。接着,进入更为复杂且实际的三维(3D)应用场景,演示了如何在形状为[batch_size, num_elements, num_features]的张量中进行元素选择——这种情况在机器学习项目中十分常见。