本文分享BEV感知方案中,具有代表性的方法:BEVFormer。
它基于Deformable Attention,实现了一种融合多视角相机空间特征和时序特征的端到端框架,适用于多种自动驾驶感知任务。
主要由3个关键模块组成:
BEV Queries Q:用于查询得到BEV特征图
Spatial Cross-Attention:用于融合多视角空间特征
Temporal Self-Attention:用于融合时序BEV特征
基本思想:使用可学习的查询Queries表示BEV特征,查找图像中的空间特征和先前BEV地图中的时间特征。
推荐学习路径:
DETR→Deformable DETR→BEVFormer。
Bevformer核心三点
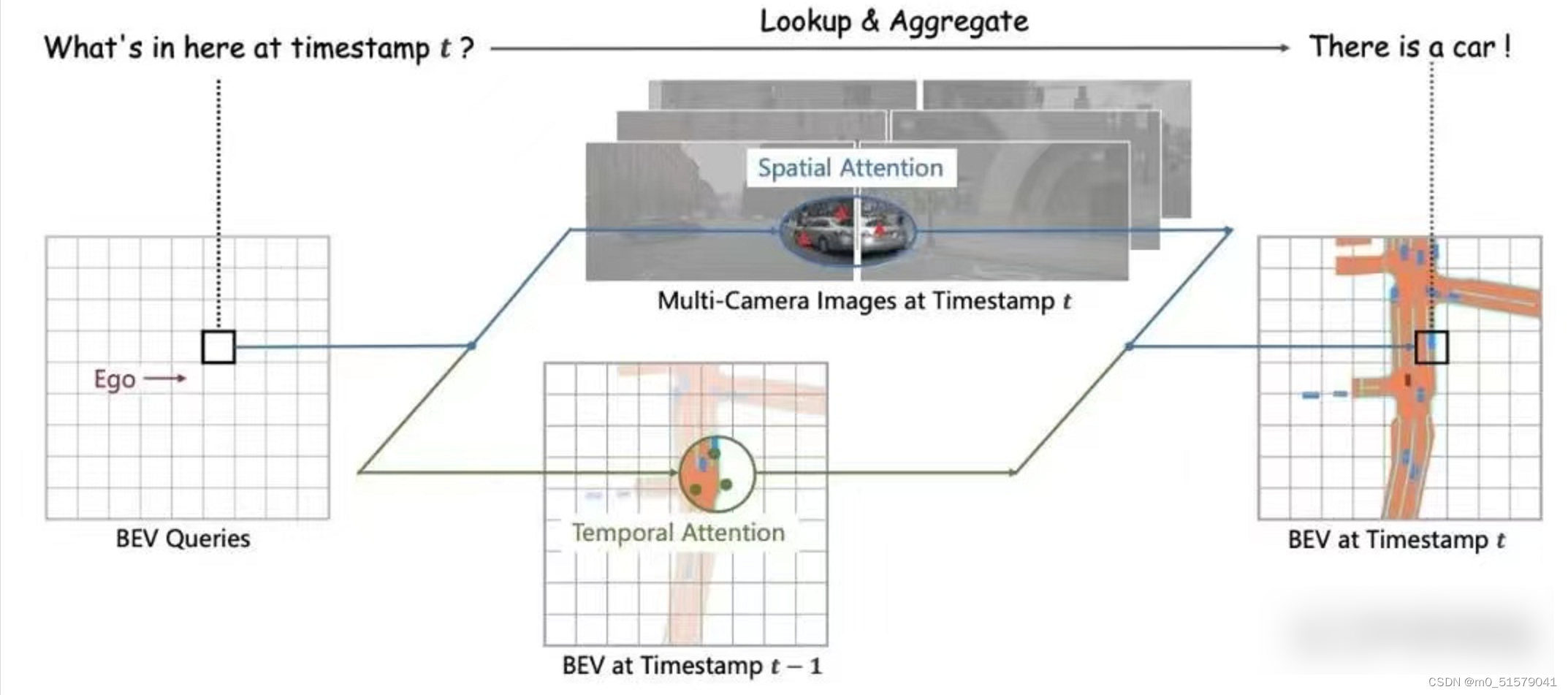
(1)BEVquery:任务是要建立平面中的点与BEV空间下点的关系,设BEV空间是一个HWC的序列。BEV中每个处理的点称为BEV query,维度为1×C,位置为Pxy。每个BEV中的点在现实中都有对应。
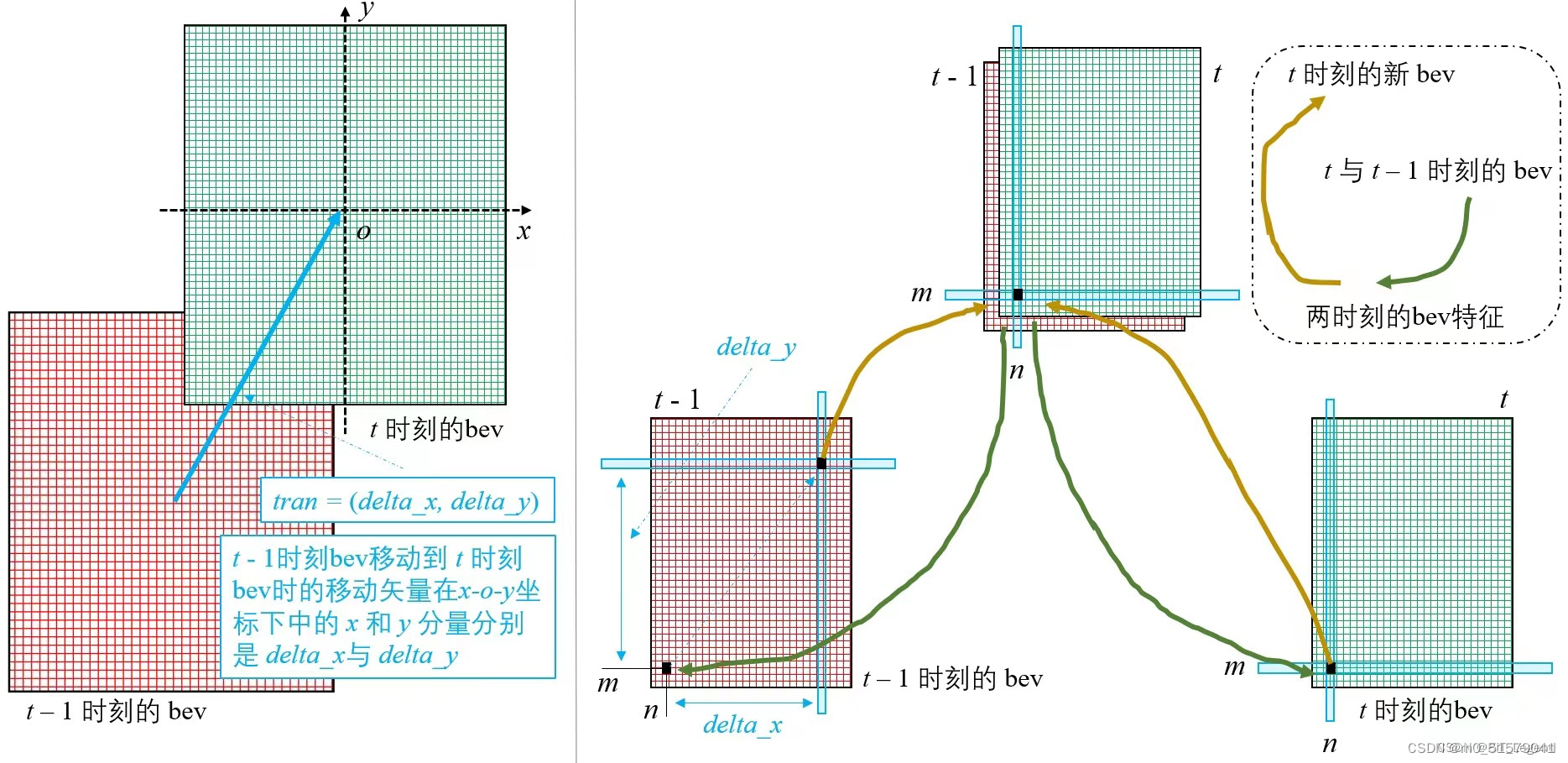
(2)时间自注意力:通过时间注意力将t-1时刻的特征和t时刻特征融合,加强t时刻的输入。其中,网络会自主学习其中的一些 特征对齐,时间补偿,运动补偿。
(3)空间交叉注意力:再通过spatial cross- attention,将多个相机的特征融合到BEV空间下。
Bevformer结构组成
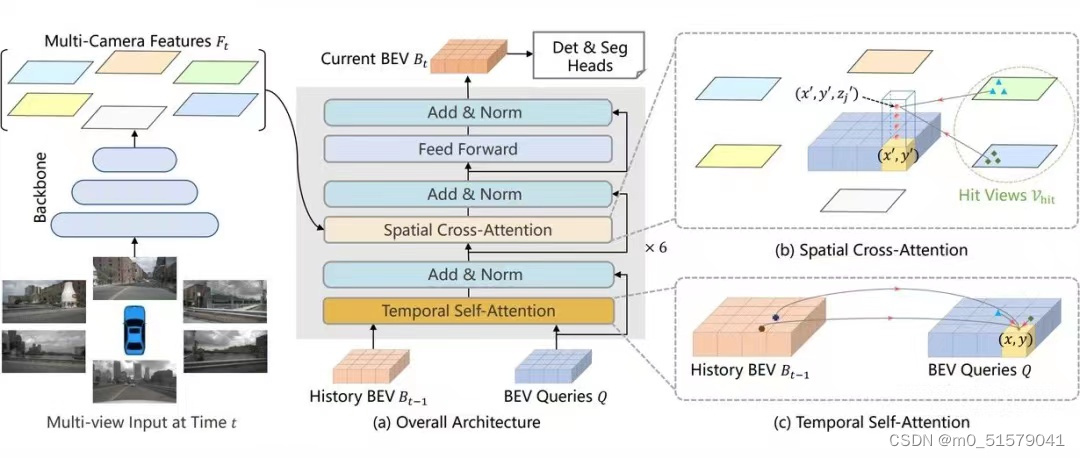
如上图所示,BEVFormer由如下三个部分组成:
backbone:用于从6个角度的环视图像中提取多尺度的multi-camera feature
BEV encoder:该模块主要包括Temporal self-Attention 和 Spatial Cross-Attention两个部分。
Spatial Cross-Attention结合多个相机的内外参信息对对应位置的multi-camera feature进行query,从而在统一的BEV视角下将multi-camera feature进行融合。
Temporal self-Attention将History BEV feature和 current BEV feature通过 self-attention module进行融合。
通过上述两个模块,输出同时包含多视角和时序信息的BEV feature进一步用于下游3D检测和分割任务
Det&Seg Head:用于特定任务的task head