揭秘高效存储模型与数据结构底层实现
- 【专栏简介】
- 【技术大纲】
- 【专栏目标】
- 【目标人群】
- 1. Redis爱好者与社区成员
- 2. 后端开发和系统架构师
- 3. 计算机专业的本科生及研究生
- 链表
- 使用场景
- List(列表)和 链表的关系
- 链表的实现
- 链表的节点
- list的源码实现
- 结构模型分析
- list和listNode和逻辑结构
- 链表结构的特性
- 其余方法介绍和说明
- 函数介绍说明
- 核心方法源码分析(adlist.c)
- 头文件引入
- listCreate:创建一个新的空链表
- listRelease:释放整个列表
- listEmpty:移除所有的元素,但是不释放自己本身
- listAddNodeHead:插入新节点到表头
- listAddNodeTail:插入新节点到表尾
- listLinkNodeHead:将新节点添加到链表
- listDelNode:从链表中删除给定的节点
- listUnlinkNode:列表中解除该节点的链接
- 最后总结
- 源码来源
- 链表节点
- 列表结构
【专栏简介】
随着数据需求的迅猛增长,持久化和数据查询技术的重要性日益凸显。关系型数据库已不再是唯一选择,数据的处理方式正变得日益多样化。在众多新兴的解决方案与工具中,Redis凭借其独特的优势脱颖而出。
【技术大纲】
为何Redis备受瞩目?原因在于其学习曲线平缓,短时间内便能对Redis有初步了解。同时,Redis在处理特定问题时展现出卓越的通用性,专注于其擅长的领域。深入了解Redis后,您将能够明确哪些任务适合由Redis承担,哪些则不适宜。这一经验对开发人员来说是一笔宝贵的财富。

在这个专栏中,我们将专注于Redis的6.2版本进行深入分析和介绍。Redis 6.2不仅是我个人特别偏爱的一个版本,而且在实际应用中也被广泛认为是稳定性和性能表现都相当出色的版本。
【专栏目标】
本专栏深入浅出地传授Redis的基础知识,旨在助力读者掌握其核心概念与技能。深入剖析了Redis的大多数功能以及全部多机功能的实现原理,详细展示了这些功能的核心数据结构和关键算法思想。读者将能够快速且有效地理解Redis的内部构造和运作机制,这些知识将助力读者更好地运用Redis,提升其使用效率。
将聚焦于Redis的五大数据结构,深入剖析各种数据建模方法,并分享关键的管理细节与调试技巧。
【目标人群】
Redis技术进阶之路专栏:目标人群与受众对象,对于希望深入了解Redis实现原理底层细节的人群。
1. Redis爱好者与社区成员
Redis技术有浓厚兴趣,经常参与社区讨论,希望深入研究Redis内部机制、性能优化和扩展性的读者。
2. 后端开发和系统架构师
在日常工作中经常使用Redis作为数据存储和缓存工具,他们在项目中需要利用Redis进行数据存储、缓存、消息队列等操作时,此专栏将为他们提供有力的技术支撑。
3. 计算机专业的本科生及研究生
对于学习计算机科学、软件工程、数据分析等相关专业的在校学生,以及对Redis技术感兴趣的教育工作者,此专栏可以作为他们的学习资料和教学参考。
无论是初学者还是资深专家,无论是从业者还是学生,只要对Redis技术感兴趣并希望深入了解其原理和实践,都是此专栏的目标人群和受众对象。
让我们携手踏上学习Redis的旅程,探索其无尽的可能性!
链表
链表具备出色的节点重排与顺序访问能力,并且能够通过灵活地增删节点来调整链表的长度,从而满足各种实际应用需求。作为一种重要的数据结构,链表在多种高级编程语言中得到了内置支持。然而,由于Redis所依赖的C语言并未内置链表数据结构,Redis团队便自行实现了链表功能。
使用场景
在Redis中,链表的应用场景十分广泛,特别是在处理列表键时。当列表键包含的元素数量较多,或元素本身较长(如字符串)时,Redis会选择使用链表作为其底层实现。这是因为链表能够高效地处理大量数据,并且在处理长字符串时具有优势,能够确保数据的完整性和处理速度。通过利用链表的这些特性,Redis在处理复杂数据结构时表现出色,为用户提供了稳定、高效的数据存储和访问体验。
List(列表)和 链表的关系
列表(List)的底层实现是一个链表,其中的每个节点保存了一个值。除了用于链表之外,发布与订阅、慢查询、监视器等功能也利用了链表。Redis服务器本身还利用链表来保存多个客户端的状态信息,并构建客户端输出缓冲区(output buffer)。
链表的实现
链表是有多个链表节点组成,这一设计使得链表节点的数据结构和功能得到了清晰和统一的定义,进而确保了链表操作的准确性和一致性。下图是一个多个listNode组成的双端链表:

通过采用这种标准化的结构表示,我们能够实现更加高效和可靠的链表管理,为后续的链表操作和应用提供了坚实的基础。
链表的节点
每个链表节点均通过adlist.h中定义的listNode结构来具体表示,如下图源码所示:

多个listNode通过其内部的prev和next指针相互连接,从而构成了一个双端链表。这种链表结构在源代码中的实现如下所示,通过灵活使用这些指针,我们能够实现在链表中向前或向后遍历的能力,增强了链表的灵活性和实用性。
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
这种设计不仅优化了链表的性能,同时也提高了链表操作的效率,使得我们可以更轻松地对其进行增删改查等操作。
list的源码实现
在Redis中,list数据结构并非仅由简单的listNode模型构成的单一链表结构。实际上,它结合了多种操作元素,形成了一个更为丰富和灵活的数据结构。通过采用adlist.h/list来持有和管理这个链表,Redis不仅实现了基本的链表操作,还加入了一系列优化和特性,如下面的源码所示:
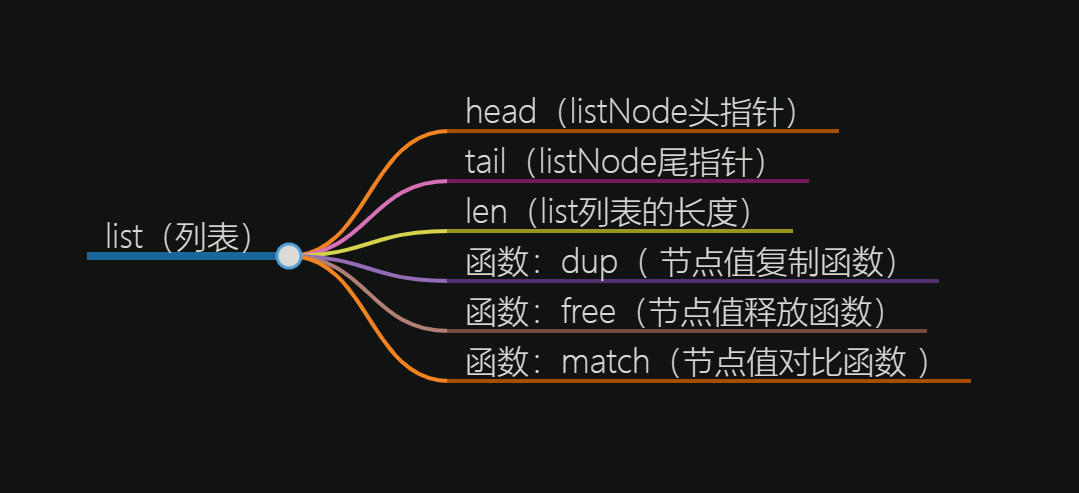
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
上面的list模型结构提供了更高效、更便捷的数据处理能力。这种设计不仅增强了链表的实用性,也为Redis的广泛应用提供了强大的支持。
结构模型分析
List结构精心设计了表头指针head和表尾指针tail来指明链表的起始与终结,同时配备了链表长度计数器len来快速获取链表中元素的数量。此外,为了满足多态链表的需求,List结构还引入了dup、free和match这三个类型特定的函数成员:
dup函数:它负责复制链表节点中存储的值,确保在链表复制或扩展时能够准确地复制数据。free函数:它负责释放链表节点中存储的值所占用的内存空间,防止内存泄漏,保持系统的稳定性。match函数:它用于比较链表节点中存储的值与给定的输入值是否相同,为链表元素的查找和比较操作提供了便利。
这三个函数的引入不仅丰富了List结构的功能,还提高了其灵活性和可扩展性,使得Redis的list数据结构能够应对各种复杂的应用场景。
list和listNode和逻辑结构
由list结构和listNode结构共同构筑的链表,展现出一种既严谨又灵活的数据组织形式。
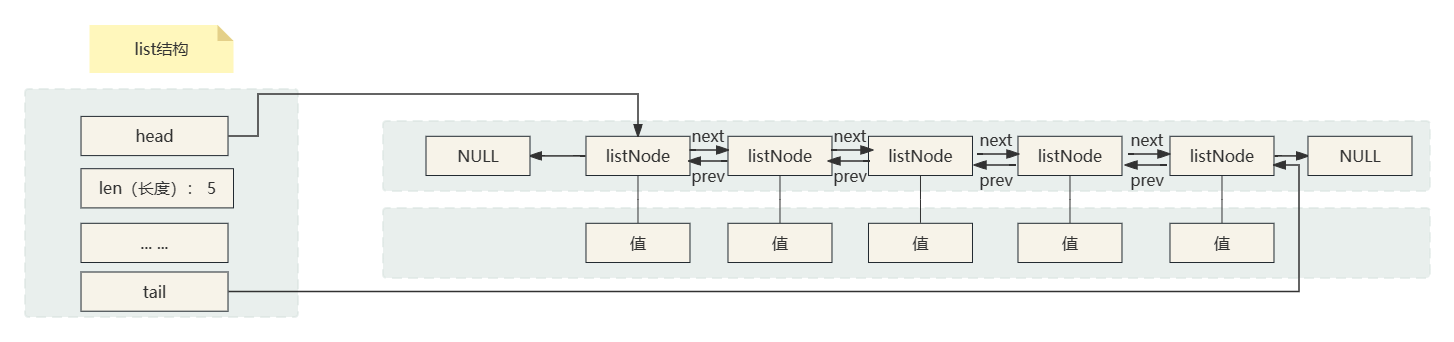
- list结构:链表的整体视图,包括表头指针、表尾指针以及长度计数器,为链表的操作和管理提供了便利。
- listNode结构:链表的基本组成单元,通过prev和next指针实现节点间的双向连接,形成了链表的骨架。
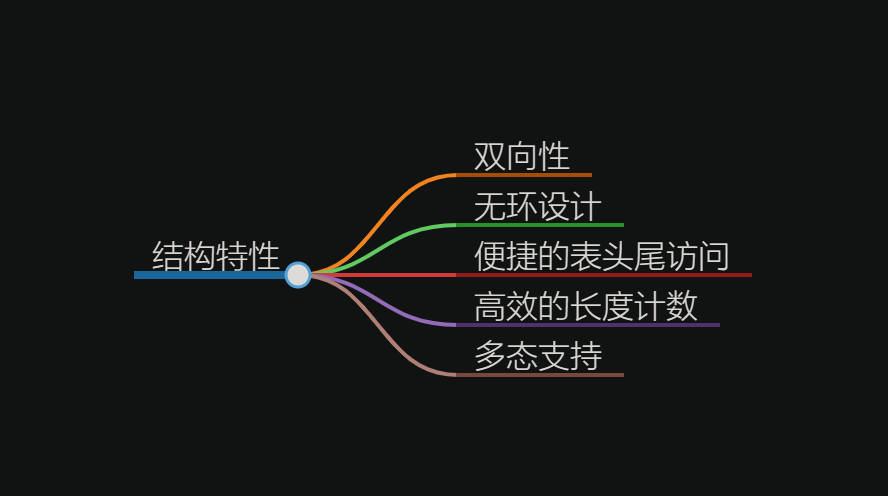
链表结构的特性
-
双向性:链表中的每个节点均配备prev和next指针,使得无论是查找某个节点的前驱节点还是后继节点,操作复杂度均保持在O(1)水平,极大地提升了链表的遍历效率。
-
无环设计:链表的表头节点的prev指针和表尾节点的next指针均指向NULL,这种设计确保了链表的访问始终有明确的终点,从而避免了循环引用导致的潜在问题。
-
便捷的表头尾访问:Redis链表通过list结构中的head和tail指针,使得程序能够直接定位到链表的起始和结束节点,获取表头节点和表尾节点的操作复杂度同样为O(1),大大简化了链表的操作流程。
-
高效的长度计数:list结构内置的len属性用于记录链表中的节点数量,这使得程序在需要获取链表长度时,无需遍历整个链表,即可直接获取结果,操作复杂度保持在O(1)。
-
多态支持:链表节点采用void*指针来存储节点值,同时,list结构提供了dup、free和match三个属性,允许用户为节点值设置类型特定的函数。这种设计使得Redis的链表能够灵活地保存和处理各种不同类型的值,实现了多态链表的功能。
其余方法介绍和说明
以下是关于相关方法的介绍,这些方法定义在adlist.h头文件中,如以下源码所示。但值得注意的是,.h头文件通常只包含函数的声明和定义概念,而真正的函数实现机制则位于adlist.c源文件中。
/* Functions implemented as macros */
#define listLength(l) ((l)->len)
#define listFirst(l) ((l)->head)
#define listLast(l) ((l)->tail)
#define listPrevNode(n) ((n)->prev)
#define listNextNode(n) ((n)->next)
#define listNodeValue(n) ((n)->value)
#define listSetDupMethod(l,m) ((l)->dup = (m))
#define listSetFreeMethod(l,m) ((l)->free = (m))
#define listSetMatchMethod(l,m) ((l)->match = (m))
#define listGetDupMethod(l) ((l)->dup)
#define listGetFreeMethod(l) ((l)->free)
#define listGetMatchMethod(l) ((l)->match)
/* Prototypes */
list *listCreate(void);
void listRelease(list *list);
void listEmpty(list *list);
list *listAddNodeHead(list *list, void *value);
list *listAddNodeTail(list *list, void *value);
list *listInsertNode(list *list, listNode *old_node, void *value, int after);
void listDelNode(list *list, listNode *node);
listIter *listGetIterator(list *list, int direction);
listNode *listNext(listIter *iter);
void listReleaseIterator(listIter *iter);
list *listDup(list *orig);
listNode *listSearchKey(list *list, void *key);
listNode *listIndex(list *list, long index);
void listRewind(list *list, listIter *li);
void listRewindTail(list *list, listIter *li);
void listRotateTailToHead(list *list);
void listRotateHeadToTail(list *list);
void listJoin(list *l, list *o);
void listInitNode(listNode *node, void *value);
void listLinkNodeHead(list *list, listNode *node);
void listLinkNodeTail(list *list, listNode *node);
void listUnlinkNode(list *list, listNode *node);
/* Directions for iterators */
#define AL_START_HEAD 0
#define AL_START_TAIL 1
#endif /* __ADLIST_H__ */
通过头文件和源文件的配合,我们得以清晰地划分函数的接口与实现,从而确保代码的可读性、可维护性和可重用性。在adlist.c中,每个函数的具体实现都详细描述了其功能机制,使得我们能够深入理解并应用这些函数。
函数介绍说明
| 方法 | 说明 |
|---|---|
list *listCreate(void); | 创建一个新的空链表,并返回链表的指针。 |
void listRelease(list *list); | 释放给定链表的内存,包括链表中的所有节点。 |
void listEmpty(list *list); | 清空给定链表中的所有节点,但不释放链表本身的内存。 |
list *listAddNodeHead(list *list, void *value); | 在链表的头部添加一个新节点,节点值为给定值,并返回更新后的链表指针。 |
list *listAddNodeTail(list *list, void *value); | 在链表的尾部添加一个新节点,节点值为给定值,并返回更新后的链表指针。 |
list *listInsertNode(list *list, listNode *old_node, void *value, int after); | 在给定旧节点之后(如果after为1)或之前(如果after为0)插入一个新节点,节点值为给定值,并返回更新后的链表指针。 |
void listDelNode(list *list, listNode *node); | 从链表中删除给定的节点。 |
listIter *listGetIterator(list *list, int direction); | 为链表创建一个迭代器,并返回迭代器的指针。迭代方向由direction参数指定。 |
listNode *listNext(listIter *iter); | 获取迭代器当前指向的下一个节点的指针。 |
void listReleaseIterator(listIter *iter); | 释放给定迭代器的内存。 |
list *listDup(list *orig); | 复制给定的链表,并返回新链表的指针。 |
listNode *listSearchKey(list *list, void *key); | 在链表中搜索具有给定键值的节点,并返回找到的节点的指针。如果未找到,则返回NULL。 |
listNode *listIndex(list *list, long index); | 根据给定的索引获取链表中的节点。如果索引超出范围,则返回NULL。 |
void listRewind(list *list, listIter *li); | 重置给定的迭代器,使其指向链表的头部。 |
void listRewindTail(list *list, listIter *li); | 重置给定的迭代器,使其指向链表的尾部。 |
void listRotateTailToHead(list *list); | 将链表的尾部节点移动到头部。 |
void listRotateHeadToTail(list *list); | 将链表的头部节点移动到尾部。 |
void listJoin(list *l, list *o); | 将另一个链表o的所有节点添加到链表l的尾部。 |
void listInitNode(listNode *node, void *value); | 初始化给定的链表节点,设置其值为给定值。 |
void listLinkNodeHead(list *list, listNode *node); | 将给定的节点链接到链表的头部。 |
void listLinkNodeTail(list *list, listNode *node); | 将给定的节点链接到链表的尾部。 |
void listUnlinkNode(list *list, listNode *node); | 从链表中取消链接给定的节点,但不释放节点的内存。 |
核心方法源码分析(adlist.c)
头文件引入
在C语言的代码中,预处理器指令部分起到了至关重要的作用。这部分代码完成了对三个头文件的引入,分别是:
#include <stdlib.h>
#include "adlist.h"
#include "zmalloc.h"
-
<stdlib.h>:这是C语言的标准库头文件,它包含了诸如内存管理、程序控制以及类型转换等功能的函数和宏定义。通过引入这个头文件,我们可以方便地使用malloc、free、exit等标准库函数,为程序提供基础且强大的支持。 -
"adlist.h":通过引入这个头文件,可以利用其中定义的数据结构、函数原型或宏,从而简化列表相关操作的实现。 -
"zmalloc.h":引入这个头文件后,可以使用其中提供的特定内存分配和释放机制,这些机制可能具有更好的错误处理、内存跟踪或其他高级功能,从而增强程序的健壮性和性能。
listCreate:创建一个新的空链表
- 时间复杂度:O(1)
下面的源码是创建新链表的函数listCreate的实现。该函数返回list指针类型,不接受任何参数。以下是对源码的详细注释和解释,帮助您清晰地了解源码的含义和实现原理。
// 创建新链表的函数,返回链表结构体的指针
list *listCreate(void)
{
// 声明了一个list结构体的指针list。struct list 应该是在adlist.h头文件中定义的,它定义了链表的结构。
struct list *list;
// 使用 zmalloc 函数为 list 结构体分配内存。zmalloc是Redis提供的内存分配函数,它在内存分配失败时会返回 NULL。sizeof(*list) 计算 list 指针所指向的结构体的大小。
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL; //如果内存分配失败,函数会返回 NULL。
// 这里初始化了链表的头指针 head 和尾指针 tail 为 NULL,并设置链表的长度 len 为 0。这表示新创建的链表是空的。
list->head = list->tail = NULL;
list->len = 0; // 初始长度为0
// 设置复制、释放和匹配函数为 NULL
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}
总结一下,listCreate 函数的主要功能是创建一个新的、空的链表,并返回其指针。如果内存分配失败,它会返回 NULL。当不再需要已创建的列表时,应使用
listRelease()函数来释放其占用的内存。在调用listRelease()之前,列表中每个节点的私有值需要由用户自行释放,或者可以通过listSetFreeMethod函数来设定一个自动释放这些私有值的方法。
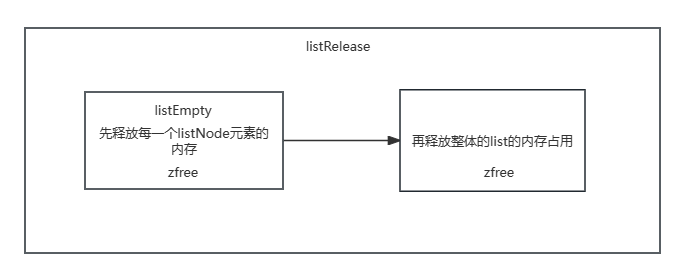
listRelease:释放整个列表
- 时间复杂度:O(N) ,N为链表长度
listRelease 函数具有高度的可靠性,它确保成功释放给定的链表及其所包含的所有节点,不会出现失败的情况。通过调用该函数,可以有效地回收链表占用的内存资源,确保程序的稳定运行。
/*
* Free the whole list.
* This function can't fail.
*/
void listRelease(list *list)
{
//传入的list指针是否为NULL。如果是NULL,函数会直接返回,不执行任何操作。
if (!list) // 避免了在空指针上执行操作,这可能会导致未定义行为或程序崩溃。
return;
// 调用listEmpty函数来释放链表中的所有节点,逐个释放每个节点所占用的内存。
listEmpty(list);
// 使用zfree函数来释放list结构体本身所占用的内存
zfree(list);
}
listEmpty:移除所有的元素,但是不释放自己本身
- 时间复杂度:O(1)
在深入探讨listRelease方法的实现时,我们注意到其中调用了listEmpty方法。为了更全面地理解整个链表的内存释放过程,接下来我们将仔细研究并分析listEmpty方法的实现原理和运行流程。下面的源码就是针对于实现原理和流程进行分析,有了对应的源码和注释,相信你可以从底层更加清晰的认识listEmpty的实现原理。
/* Remove all the elements from the list without destroying the list itself. */
void listEmpty(list *list)
{
// 获取链表的长度
unsigned long len;
// 定义当前节点和下一个节点的指针
listNode *current, *next;
// 将当前节点指针指向链表的头节点
current = list->head;
// 将链表长度赋值给len变量,方便后续遍历
len = list->len;
// 循环遍历链表,直到所有节点都被处理
while(len--) {
// 将下一个节点指针指向当前节点的下一个节点
next = current->next;
// 如果链表定义了释放节点值的函数,则调用该函数释放当前节点的值
if (list->free) list->free(current->value);
// 释放当前节点所占用的内存
zfree(current);
// 将当前节点指针指向下一个节点,准备处理下一个节点
current = next;
}
// 将链表的头节点和尾节点指针置为NULL,表示链表为空
list->head = list->tail = NULL;
// 将链表长度置为0,表示链表没有节点
list->len = 0;
}
listAddNodeHead:插入新节点到表头
- 时间复杂度:O(1)
函数的目的通过插入新节点到表头,我们根据需要修改链表的结构和内容。无论是将新节点添加到链表的开头,还是在特定节点的前后位置插入,都能轻松实现。同时,通过返回更新后的链表头节点指针,我们可以方便地访问和操作整个链表。
- 参数:
- list:指向列表的指针
- value:要添加到新节点的值(作为指针)
- 返回值:
- 成功时返回更新后的列表指针
- 出错时返回NULL
下面便是源码的分析和解释说明:
// 定义一个名为 listAddNodeHead 的函数,该函数接受一个指向 list 结构的指针和一个 void 类型的指针作为参数。
// 函数返回一个指向 list 结构的指针。
list *listAddNodeHead(list *list, void *value)
{
// 定义一个指向 listNode 结构的指针 node。
listNode *node;
// 使用 zmalloc 函数为 listNode 分配内存,并将返回的地址赋值给 node。
// 如果内存分配失败,zmalloc 会返回 NULL。
if ((node = zmalloc(sizeof(*node))) == NULL)
// 如果内存分配失败,则返回 NULL。
return NULL;
// 将传入的 value 赋值给新节点的 value 字段。
node->value = value;
// 调用 listLinkNodeHead 函数,将新节点添加到链表的头部。
listLinkNodeHead(list, node);
// 返回更新后的链表指针。
return list;
}
我们需要向给定的列表头部添加一个新节点,该节点包含特定的“值”。在此过程中,指针将作为关键参数进行传递。若在执行过程中遇到任何错误,函数将立即返回NULL,且不会执行任何对原列表的修改操作,以确保列表的完整性。一旦操作成功,函数将返回传递给它的原始“列表”指针,以便调用者能够继续利用更新后的列表。
listAddNodeTail:插入新节点到表尾
- 时间复杂度:O(1)
函数的目的通过插入新节点到表尾,我们根据需要修改链表的结构和内容。下面便是源码的分析和解释说明:
- 参数:
- list:指向列表的指针
- value:要添加到新节点的值(作为指针)
- 返回值:
- 成功时返回更新后的列表指针
- 出错时返回NULL
// 函数定义:将一个新节点添加到列表的尾部,并返回更新后的列表指针。
list *listAddNodeTail(list *list, void *value) {
// 声明一个指向listNode结构的指针node,用于存储新节点的地址
listNode *node;
// 使用zmalloc函数为新节点分配内存,并将返回的地址赋值给node
// 如果内存分配失败,zmalloc将返回NULL
if ((node = zmalloc(sizeof(*node))) == NULL)
// 如果内存分配失败,则返回NULL,不执行任何操作
return NULL;
// 将传入的value赋值给新节点的value字段
node->value = value;
// 调用listLinkNodeTail函数,将新节点添加到列表的尾部
listLinkNodeTail(list, node);
// 返回更新后的列表指针
return list;
}
在列表中的尾部添加一个全新的节点,这个新节点应持有指定的“Value”指针作为其内容。如果在执行过程中出现任何错误,函数将立即返回NULL,并且不会进行任何对原列表的修改,以确保列表的完整性。一旦操作成功完成,函数将返回传递给它的原始“list”指针,以便调用者能够继续利用更新后的列表。
listLinkNodeHead:将新节点添加到链表
- 时间复杂度:O(1)
将预先分配好的节点添加至列表的起始位置,实现节点的头部插入操作。
// 函数用于将一个节点链接到链表的头部
void listLinkNodeHead(list* list, listNode *node) {
// 如果链表为空(即长度为0)
if (list->len == 0) {
// 将新节点设置为链表的头节点和尾节点
list->head = list->tail = node;
// 因为链表只有一个节点,所以该节点的prev和next都指向NULL
node->prev = node->next = NULL;
} else {
// 如果链表不为空,那么将新节点的prev指向NULL(因为它是头部节点)
node->prev = NULL;
// 将新节点的next指向当前的头节点
node->next = list->head;
// 将当前头节点的prev指向新节点,形成双向链表的链接
list->head->prev = node;
// 将链表的头节点更新为新节点
list->head = node;
}
// 无论链表是否为空,都将链表的长度加1
list->len++;
}
-
链表为空的情况:
- 如果链表为空(
list->len == 0),说明之前没有节点,新节点不仅会成为头节点,也会成为尾节点。 - 将
list->head和list->tail都指向新节点node。 - 由于链表只有一个节点,该节点的
prev和next指针都应该指向NULL。
- 如果链表为空(
-
链表不为空的情况:
- 初始化新节点的
prev为NULL,因为它即将成为新的头节点。 - 将新节点的
next指向当前的头节点list->head。 - 更新当前头节点的
prev指针,使其指向新节点,确保双向链表的连接正确。 - 更新链表的头节点指针
list->head,使其指向新节点。
- 初始化新节点的
-
链表长度更新:
- 无论链表之前是否为空,在插入新节点后,链表的长度都会增加1,因此
list->len需要加1。
- 无论链表之前是否为空,在插入新节点后,链表的长度都会增加1,因此
listDelNode:从链表中删除给定的节点
- 时间复杂度:O(N),N为链表长度
从给定的列表中移除特定的节点,并释放该节点的内存。 若提供了自由回调函数,则利用该函数来释放节点所持有的值。 此函数确保执行成功,不会出现失败的情况。
// 函数定义:从列表中删除一个节点,并释放相关内存
void listDelNode(list *list, listNode *node)
{
// 调用listUnlinkNode函数,从列表中解除该节点的链接
listUnlinkNode(list, node);
// 如果列表的free字段不为空(即存在一个用于释放节点值的回调函数)
if (list->free)
// 调用该回调函数,释放节点中存储的值所占用的内存
list->free(node->value);
// 调用zfree函数,释放节点本身所占用的内存
zfree(node);
}
listUnlinkNode:列表中解除该节点的链接
- 时间复杂度:O(1)
从给定的列表中移除特定的节点,但保留其内存不被释放。这意味着节点仍然存在于内存中,只是不再与列表相关联。
// 函数定义:从双向链表中移除一个节点,但不释放其内存
void listUnlinkNode(list *list, listNode *node) {
// 如果该节点有前一个节点
if (node->prev) {
// 将前一个节点的next指针指向当前节点的下一个节点
node->prev->next = node->next;
} else {
// 否则,当前节点是头节点,将列表的头指针指向当前节点的下一个节点
list->head = node->next;
}
// 如果该节点有下一个节点
if (node->next) {
// 将下一个节点的prev指针指向当前节点的前一个节点
node->next->prev = node->prev;
} else {
// 否则,当前节点是尾节点,将列表的尾指针指向当前节点的前一个节点
list->tail = node->prev;
}
// 将当前节点的next和prev指针都设置为NULL,表示它已经从链表中移除
node->next = NULL;
node->prev = NULL;
// 减少列表的长度计数
list->len--;
}
通过执行此操作,您可以重新利用该节点,或者将其添加到其他列表中,而无需再次分配内存。此功能确保从列表中安全地移除节点,同时保持其内存完整性。
最后总结
由于篇幅过程,因此其他的函数就不一一列举了,在这里主要给大家介绍了以上这几个函数,因为它们属于较为核心以及重要的方法。如果大家希望作者完善和继续完成其他的函数还希望大家在评论区沟通和说明,我会努力完成和完善的,文章和学习不容易,希望大家多多支持、点赞和鼓励!
源码来源
链表是Redis实现各种功能的核心组件,诸如列表键的操作、发布订阅机制、慢查询跟踪以及监视器功能,都依赖链表的支持。
- adlist.c
- adlist.h
链表节点
链表节点的表示通过精心设计的listNode结构体来实现。每个节点不仅包含数据,还具备指向前一个节点和后一个节点的指针,使得Redis的链表成为双向链表,提供了更加灵活的遍历和操作方式。

列表结构
整个链表由list结构体代表,包含指向链表头节点和尾节点的指针,以及记录链表长度的信息。这种结构化的管理方式使得链表的操作更加高效和便捷。
注意,Redis的链表实现特别注重安全性。链表头节点的前置指针和链表尾节点的后置指针都指向
NULL,这种设计有效避免了链表中的环形结构,确保了链表操作的安全性和稳定性。