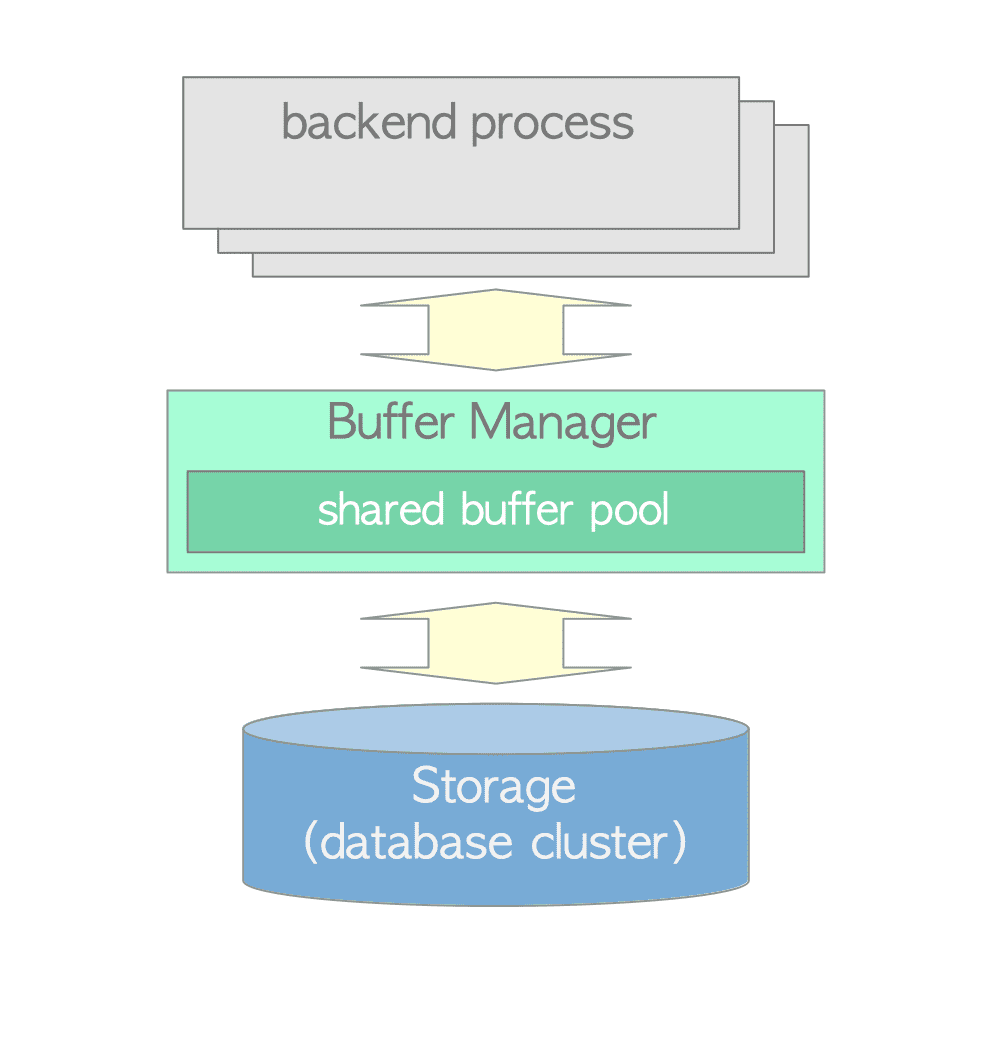
这里我们分析一下PG数据库缓冲区的代码。缓冲区是十分重要的,对数据库的性能和稳定性有着直接的影响。缓冲区是数据库SQL计算层与外部存储(磁盘)交互的关键。数据页的落盘与读取,都要经过缓冲区。
README
src/backend/storage/buffer/README
PG中的缓冲区设计,考虑的很多设计点其实和应用程序中其他缓冲区的设计考虑点很多是相同的,比如缓冲区的大小,缓冲区的淘汰策略,如何提高缓冲区的命中率,这些问题很多都是缓冲区设计时需要面对的通用的问题。我们看一下数据库中的缓冲区是如何设计的。
- 缓冲区初始化
- 读写缓冲区,读数据页,如果命中,引用计数加1,返回,如果没命中,则需要读磁盘中的页到缓冲区中,此时需要先在缓冲区分配一个空间,如果有空闲空间,直接取空闲空间,如果没有空闲空间,需要通过淘汰策略淘汰一个数据页。
- 淘汰策略。(时钟扫描算法)
缓冲区管理器
我们知道,实现一个缓冲区,可以用link-hashtabke,缓冲区,实际上就是一个哈希表,只不过实现的形式各有不同。在哈希表中,要确定key,value,在PG中,缓冲区存储页数据,其key要能够定位唯一的页,需要<表空间,数据库,表,forknumber,块号>,来定位一个页,其value,就是数据页。
typedef struct buftag
{
RelFileNode rnode; /* physical relation identifier */
ForkNumber forkNum;
BlockNumber blockNum; /* blknum relative to begin of reln */
} BufferTag;
typedef struct RelFileNode
{
Oid spcNode; /* tablespace */
Oid dbNode; /* database */
Oid relNode; /* relation */
} RelFileNode;
当数据库后端进程需要读取数据页时,会向缓冲区管理器发送一个请求,以buftag的形式请求一个数据页。如果命中,缓冲区管理器会返回一个buffer_id,这个槽位存储了请求的数据页数据,后端进程读取该槽位的数据页数据。
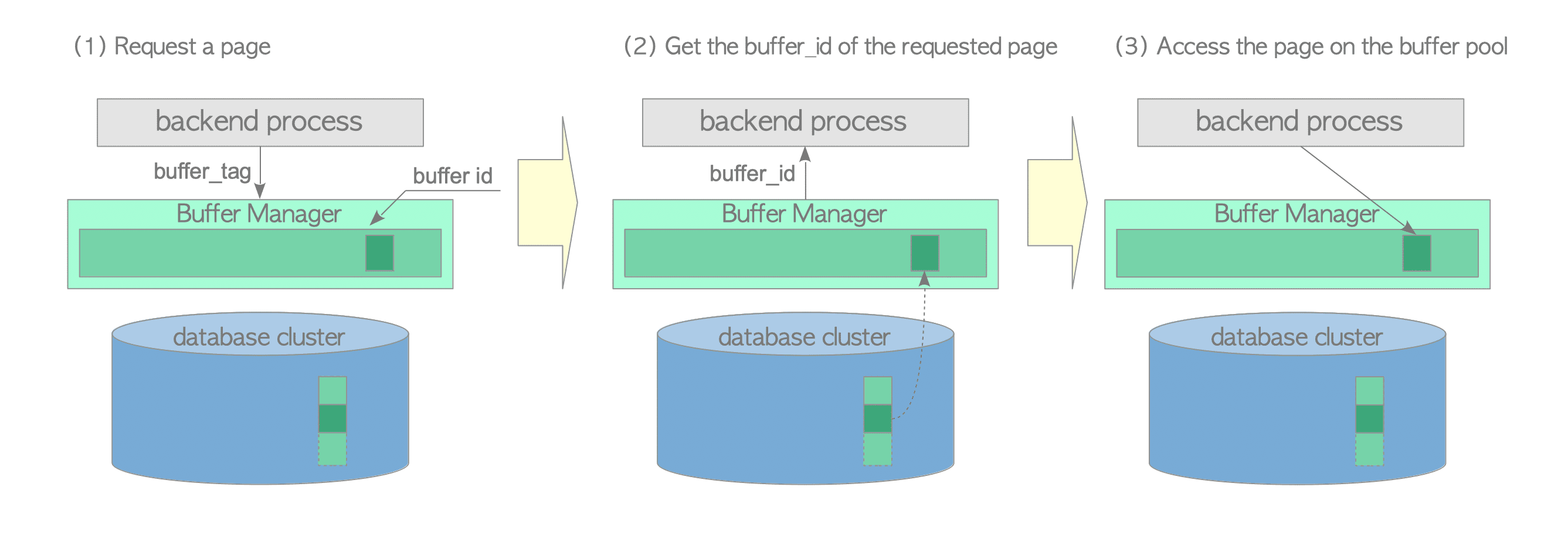
上面提到了缓冲区管理器,我们看一下它是什么?缓冲区管理器包含3层:buffer table、 buffer descriptors、 buffer pool。
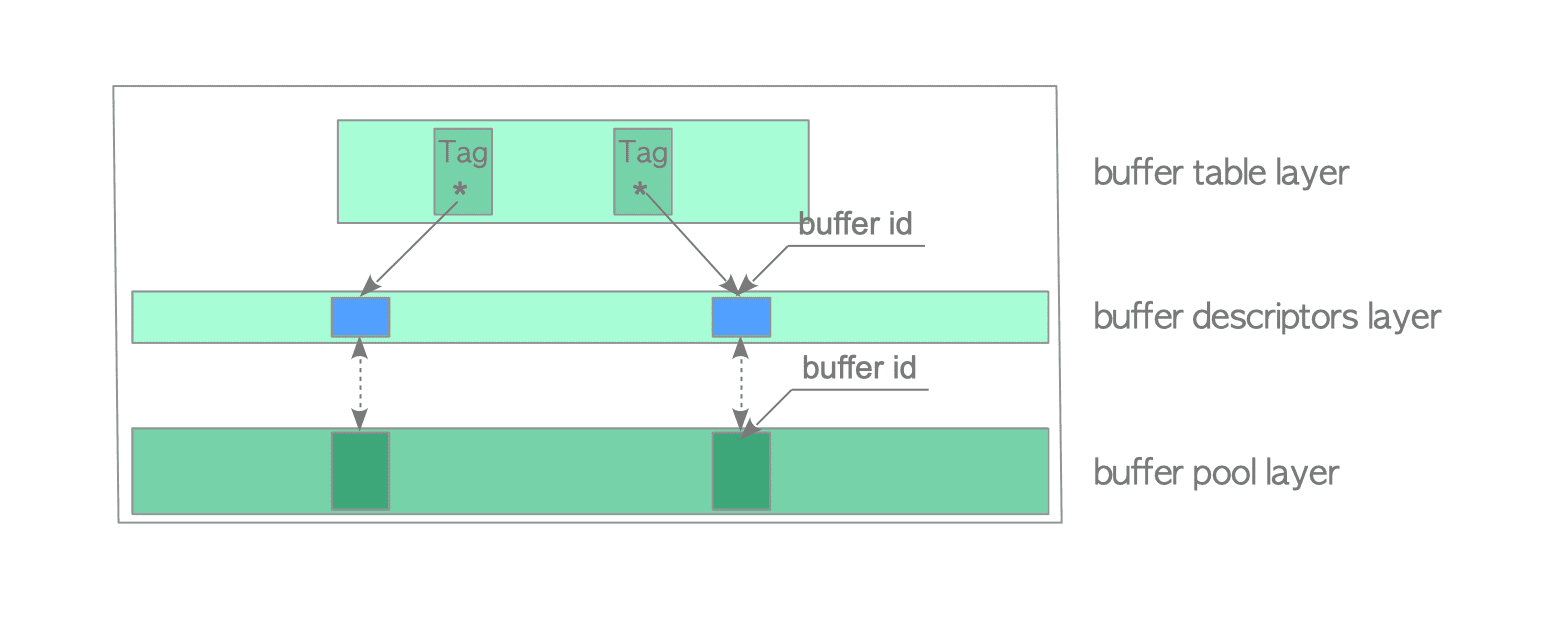
- buffer pool(缓冲池): 是一个数组,存储页数据,每个槽位对应一个buffer_id
- buffer descriptor(缓冲区描述符): 是一个数组,存储buffer描述符,每个描述符对应一个缓冲池中的槽位。
typedef struct BufferDesc
{
BufferTag tag; /* ID of page contained in buffer */
int buf_id; /* buffer's index number (from 0) */
/* state of the tag, containing flags, refcount and usagecount */
pg_atomic_uint32 state; // 10 bit flags | 4 bit usage count | 18 bit refcount
int wait_backend_pgprocno; /* backend of pin-count waiter */
int freeNext; /* link in freelist chain */
LWLock content_lock; /* to lock access to buffer contents */
} BufferDesc;
- buffer table(缓冲表):是一个哈希表,存储buffer_tags与buffer_ids的对应关系。
/* entry for buffer lookup hashtable */
typedef struct
{
BufferTag key; /* Tag of a disk page */
int id; /* Associated buffer ID */
} BufferLookupEnt;
读缓冲区
读缓冲区的相关流程如下:
Buffer ReadBuffer(Relation reln, BlockNumber blockNum)
--> ReadBufferExtended(reln, MAIN_FORKNUM, blockNum, RBM_NORMAL, NULL);
--> ReadBuffer_common(RelationGetSmgr(reln), reln->rd_rel->relpersistence,forkNum, blockNum, mode, strategy, &hit);
--> BufferAlloc(smgr, relpersistence, forkNum, blockNum, strategy, &found);
--> INIT_BUFFERTAG(newTag, smgr->smgr_rnode.node, forkNum, blockNum); /* create a tag so we can lookup the buffer */
--> BufTableHashCode(&newTag); // 哈希函数输入buftag,输出哈希值
--> get_hash_value(SharedBufHash, (void *) tagPtr);
--> buf_id = BufTableLookup(&newTag, newHash); // 根据buftag,查找缓冲表,获得bug_id,如果命中的话,如果找不到,返回-1
--> hash_search_with_hash_value(SharedBufHash,(void *) tagPtr,hashcode,HASH_FIND,NULL);
// 如果命中,返回,如果没有命中,继续执行
--> StrategyGetBuffer(strategy, &buf_state); // 获取一个空闲可用的buffer,返回bufferdesc, 默认策略是NULL
--> GetBufferFromRing(strategy, buf_state);
--> BufTableInsert(&newTag, newHash, buf->buf_id); // 将新获取的buf_id,插入到缓冲表中
--> smgrread(smgr, forkNum, blockNum, (char *) bufBlock); // 从磁盘读到buffer
命中的情况,先构造buftag,再根据哈希函数输入buftag,输出哈希值,根据哈希值从哈希表中查找buf_id,如果命中,则buf_id值大于0,然后pin住该页,使之不能被淘汰掉,否则会影响读页,修改BufferDesc->state值,refcount+1,usage+1。
// 通过buffer获取数据页
Page page = BufferGetPage(buf);
static Buffer ReadBuffer_common(SMgrRelation smgr, char relpersistence, ForkNumber forkNum,
BlockNumber blockNum, ReadBufferMode mode, BufferAccessStrategy strategy, bool *hit)
{
BufferDesc *bufHdr;
Block bufBlock;
bool found;
// ...
if (isLocalBuf)
{
// ...
} else {
bufHdr = BufferAlloc(smgr, relpersistence, forkNum, blockNum, strategy, &found);
}
/* if it was already in the buffer pool, we're done */
if (found) // 如果缓冲区命中
{
if (!isExtend)
{
// ...
return BufferDescriptorGetBuffer(bufHdr); // 返回buffer
}
}
}
static BufferDesc *BufferAlloc(SMgrRelation smgr, char relpersistence, ForkNumber forkNum,
BlockNumber blockNum,BufferAccessStrategy strategy,bool *foundPtr)
{
BufferTag newTag; /* identity of requested block */
uint32 newHash; /* hash value for newTag */
LWLock *newPartitionLock; /* buffer partition lock for it */
BufferTag oldTag; /* previous identity of selected buffer */
uint32 oldHash; /* hash value for oldTag */
LWLock *oldPartitionLock; /* buffer partition lock for it */
uint32 oldFlags;
int buf_id;
BufferDesc *buf;
bool valid;
uint32 buf_state;
/* create a tag so we can lookup the buffer */
INIT_BUFFERTAG(newTag, smgr->smgr_rnode.node, forkNum, blockNum);
/* determine its hash code and partition lock ID */
newHash = BufTableHashCode(&newTag); // 哈希函数输入buftag,输出哈希值
newPartitionLock = BufMappingPartitionLock(newHash);
/* see if the block is in the buffer pool already */
LWLockAcquire(newPartitionLock, LW_SHARED);
buf_id = BufTableLookup(&newTag, newHash); // 根据buftag,查找缓冲表,获得bug_id,如果命中的话,如果找不到,返回-1
if (buf_id >= 0)
{
/* Found it. Now, pin the buffer so no one can steal it from the
* buffer pool, and check to see if the correct data has been loaded
* into the buffer. */
buf = GetBufferDescriptor(buf_id);
valid = PinBuffer(buf, strategy); // pin住
/* Can release the mapping lock as soon as we've pinned it */
LWLockRelease(newPartitionLock);
// ...
return buf;
}
// ...
}
没有命中的情况: 需要先尝试淘汰页,再从磁盘读取页到缓冲区槽位,然后根据缓存区槽位返回对应的buf_id,
static Buffer ReadBuffer_common(SMgrRelation smgr, char relpersistence, ForkNumber forkNum,
BlockNumber blockNum, ReadBufferMode mode, BufferAccessStrategy strategy, bool *hit)
{
BufferDesc *bufHdr;
Block bufBlock;
bool found;
// ...
if (isLocalBuf)
{
// ...
} else {
bufHdr = BufferAlloc(smgr, relpersistence, forkNum, blockNum, strategy, &found);
}
/* if it was already in the buffer pool, we're done */
if (found) // 如果缓冲区命中
{
if (!isExtend)
{
// ...
return BufferDescriptorGetBuffer(bufHdr); // 返回buffer
}
}
// 如果没有命中缓冲区
bufBlock = isLocalBuf ? LocalBufHdrGetBlock(bufHdr) : BufHdrGetBlock(bufHdr);
if (isExtend)
{
/* new buffers are zero-filled */
MemSet((char *) bufBlock, 0, BLCKSZ);
/* don't set checksum for all-zero page */
smgrextend(smgr, forkNum, blockNum, (char *) bufBlock, false);
// ...
}
else
{
/* Read in the page, unless the caller intends to overwrite it and just wants us to allocate a buffer. */
if (mode == RBM_ZERO_AND_LOCK || mode == RBM_ZERO_AND_CLEANUP_LOCK)
MemSet((char *) bufBlock, 0, BLCKSZ);
else
{ // 从磁盘读到buffer中
smgrread(smgr, forkNum, blockNum, (char *) bufBlock);
// ...
}
}
return BufferDescriptorGetBuffer(bufHdr);
}
static BufferDesc *BufferAlloc(SMgrRelation smgr, char relpersistence, ForkNumber forkNum,
BlockNumber blockNum,BufferAccessStrategy strategy,bool *foundPtr)
{
BufferTag newTag; /* identity of requested block */
uint32 newHash; /* hash value for newTag */
LWLock *newPartitionLock; /* buffer partition lock for it */
BufferTag oldTag; /* previous identity of selected buffer */
uint32 oldHash; /* hash value for oldTag */
LWLock *oldPartitionLock; /* buffer partition lock for it */
uint32 oldFlags;
int buf_id;
BufferDesc *buf;
bool valid;
uint32 buf_state;
/* create a tag so we can lookup the buffer */
INIT_BUFFERTAG(newTag, smgr->smgr_rnode.node, forkNum, blockNum);
/* determine its hash code and partition lock ID */
newHash = BufTableHashCode(&newTag); // 哈希函数输入buftag,输出哈希值
newPartitionLock = BufMappingPartitionLock(newHash);
/* see if the block is in the buffer pool already */
LWLockAcquire(newPartitionLock, LW_SHARED);
buf_id = BufTableLookup(&newTag, newHash); // 根据buftag,查找缓冲表,获得bug_id,如果命中的话,如果找不到,返回-1
if (buf_id >= 0)
{
// 命中
}
// 没有命中, 先尝试淘汰一个数据页获取空闲buffer
/* Loop here in case we have to try another victim buffer */
for (;;)
{
// ...
/* Select a victim buffer. The buffer is returned with its header spinlock still held!*/
buf = StrategyGetBuffer(strategy, &buf_state);
/* Pin the buffer and then release the buffer spinlock */
PinBuffer_Locked(buf);
/* If the buffer was dirty, try to write it out. */
if (oldFlags & BM_DIRTY)
{
/* We need a share-lock on the buffer contents to write it out */
if (LWLockConditionalAcquire(BufferDescriptorGetContentLock(buf), LW_SHARED))
{
/*
* If using a nondefault strategy, and writing the buffer
* would require a WAL flush, let the strategy decide whether
* to go ahead and write/reuse the buffer or to choose another
* victim. We need lock to inspect the page LSN, so this
* can't be done inside StrategyGetBuffer.
*/
if (strategy != NULL)
{
XLogRecPtr lsn;
/* Read the LSN while holding buffer header lock */
buf_state = LockBufHdr(buf);
lsn = BufferGetLSN(buf);
UnlockBufHdr(buf, buf_state);
if (XLogNeedsFlush(lsn) &&StrategyRejectBuffer(strategy, buf))
{
/* Drop lock/pin and loop around for another buffer */
LWLockRelease(BufferDescriptorGetContentLock(buf));
UnpinBuffer(buf, true);
continue; // 尝试淘汰其他页
}
}
// 如果淘汰的是脏页,则需要刷盘
FlushBuffer(buf, NULL);
LWLockRelease(BufferDescriptorGetContentLock(buf));
ScheduleBufferTagForWriteback(&BackendWritebackContext, &buf->tag);
}
else
{
/* Someone else has locked the buffer, so give it up and loop back to get another one. */
UnpinBuffer(buf, true);
continue;
}
}
// ...
}
else
{
/* if it wasn't valid, we need only the new partition */
LWLockAcquire(newPartitionLock, LW_EXCLUSIVE);
/* remember we have no old-partition lock or tag */
oldPartitionLock = NULL;
/* keep the compiler quiet about uninitialized variables */
oldHash = 0;
}
/*
* Try to make a hashtable entry for the buffer under its new tag.
* This could fail because while we were writing someone else
* allocated another buffer for the same block we want to read in.
* Note that we have not yet removed the hashtable entry for the old
* tag.
*/
buf_id = BufTableInsert(&newTag, newHash, buf->buf_id); // 将新获取的buf_id,插入到缓冲表中
if (buf_id >= 0)
{
/*
* Got a collision. Someone has already done what we were about to
* do. We'll just handle this as if it were found in the buffer
* pool in the first place. First, give up the buffer we were
* planning to use.
*/
UnpinBuffer(buf, true);
/* Can give up that buffer's mapping partition lock now */
if (oldPartitionLock != NULL &&
oldPartitionLock != newPartitionLock)
LWLockRelease(oldPartitionLock);
/* remaining code should match code at top of routine */
buf = GetBufferDescriptor(buf_id);
valid = PinBuffer(buf, strategy);
/* Can release the mapping lock as soon as we've pinned it */
LWLockRelease(newPartitionLock);
*foundPtr = true;
if (!valid)
{
/*
* We can only get here if (a) someone else is still reading
* in the page, or (b) a previous read attempt failed. We
* have to wait for any active read attempt to finish, and
* then set up our own read attempt if the page is still not
* BM_VALID. StartBufferIO does it all.
*/
if (StartBufferIO(buf, true))
{
/*
* If we get here, previous attempts to read the buffer
* must have failed ... but we shall bravely try again.
*/
*foundPtr = false;
}
}
return buf;
}
/*
* Need to lock the buffer header too in order to change its tag.
*/
buf_state = LockBufHdr(buf);
/*
* Somebody could have pinned or re-dirtied the buffer while we were
* doing the I/O and making the new hashtable entry. If so, we can't
* recycle this buffer; we must undo everything we've done and start
* over with a new victim buffer.
*/
oldFlags = buf_state & BUF_FLAG_MASK;
if (BUF_STATE_GET_REFCOUNT(buf_state) == 1 && !(oldFlags & BM_DIRTY))
break;
UnlockBufHdr(buf, buf_state);
BufTableDelete(&newTag, newHash);
if (oldPartitionLock != NULL &&
oldPartitionLock != newPartitionLock)
LWLockRelease(oldPartitionLock);
LWLockRelease(newPartitionLock);
UnpinBuffer(buf, true);
}
/*
* Okay, it's finally safe to rename the buffer.
*
* Clearing BM_VALID here is necessary, clearing the dirtybits is just
* paranoia. We also reset the usage_count since any recency of use of
* the old content is no longer relevant. (The usage_count starts out at
* 1 so that the buffer can survive one clock-sweep pass.)
*
* Make sure BM_PERMANENT is set for buffers that must be written at every
* checkpoint. Unlogged buffers only need to be written at shutdown
* checkpoints, except for their "init" forks, which need to be treated
* just like permanent relations.
*/
buf->tag = newTag;
buf_state &= ~(BM_VALID | BM_DIRTY | BM_JUST_DIRTIED |
BM_CHECKPOINT_NEEDED | BM_IO_ERROR | BM_PERMANENT |
BUF_USAGECOUNT_MASK);
if (relpersistence == RELPERSISTENCE_PERMANENT || forkNum == INIT_FORKNUM)
buf_state |= BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE;
else
buf_state |= BM_TAG_VALID | BUF_USAGECOUNT_ONE;
UnlockBufHdr(buf, buf_state);
if (oldPartitionLock != NULL)
{
BufTableDelete(&oldTag, oldHash);
if (oldPartitionLock != newPartitionLock)
LWLockRelease(oldPartitionLock);
}
LWLockRelease(newPartitionLock);
/*
* Buffer contents are currently invalid. Try to obtain the right to
* start I/O. If StartBufferIO returns false, then someone else managed
* to read it before we did, so there's nothing left for BufferAlloc() to
* do.
*/
if (StartBufferIO(buf, true))
*foundPtr = false;
else
*foundPtr = true;
return buf;
}
淘汰策略
缓冲区最重要的指标是命中率,提高命中率,必然要选择合适的淘汰策略,尽量将最近最低频率使用的数据页淘汰出去。当然,淘汰也是有限制的,比如正在访问的页不能被淘汰(pin住了)。这里涉及到怎么衡量使用频率的问题。对此,其实这里的state(10 bit flags | 4 bit usage count | 18 bit refcount ),就包含refcount以及usagecount计数。通过usagecount计数来衡量使用频率。
typedef struct BufferDesc
{
BufferTag tag; /* ID of page contained in buffer */
int buf_id; /* buffer's index number (from 0) */
/* state of the tag, containing flags, refcount and usagecount */
pg_atomic_uint32 state; // 10 bit flags | 4 bit usage count | 18 bit refcount
int wait_backend_pgprocno; /* backend of pin-count waiter */
int freeNext; /* link in freelist chain */
LWLock content_lock; /* to lock access to buffer contents */
} BufferDesc;
具体的淘汰策略,在PG中选择的是时钟扫描算法。
refcount: 引用计数,保存当前访问相应页面的Postgres进程数,也被称为钉数。usagecount: 使用计数,保持相应页面加载至相应缓冲池后的访问次数。
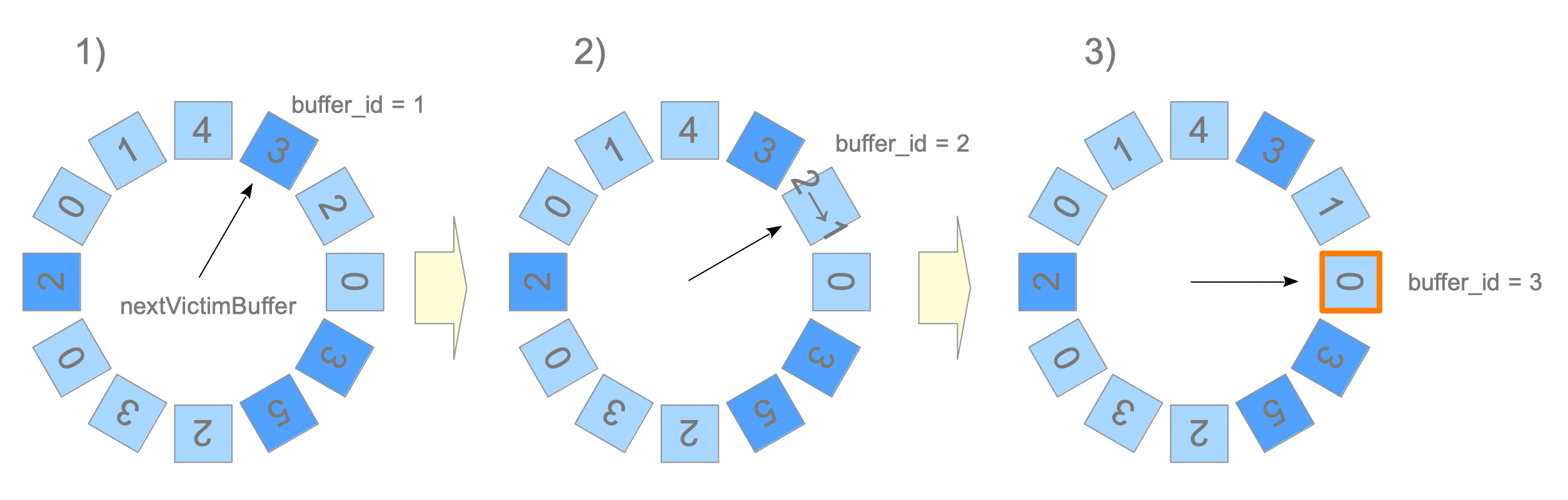
当需要淘汰掉一个页面时,选择淘汰哪一个呢? 我们将缓冲区描述符作为一个循环列表,nextVictimBuffer是一个uint32型变量,总是指向某个缓冲区描述符并按顺时针顺序旋转。
typedef struct
{
/* Spinlock: protects the values below */
slock_t buffer_strategy_lock;
/*
* Clock sweep hand: index of next buffer to consider grabbing. Note that
* this isn't a concrete buffer - we only ever increase the value. So, to
* get an actual buffer, it needs to be used modulo NBuffers.
*/
pg_atomic_uint32 nextVictimBuffer;
int firstFreeBuffer; /* Head of list of unused buffers */
int lastFreeBuffer; /* Tail of list of unused buffers */
/*
* NOTE: lastFreeBuffer is undefined when firstFreeBuffer is -1 (that is,
* when the list is empty)
*/
/*
* Statistics. These counters should be wide enough that they can't
* overflow during a single bgwriter cycle.
*/
uint32 completePasses; /* Complete cycles of the clock sweep */
pg_atomic_uint32 numBufferAllocs; /* Buffers allocated since last reset */
/*
* Bgworker process to be notified upon activity or -1 if none. See
* StrategyNotifyBgWriter.
*/
int bgwprocno;
} BufferStrategyControl;
首先获取nextVictimBuffer指向的缓冲区描述符,如果缓冲区描述符没有被钉住,那么检查描述符的usagecount,如果值为0,则选择该描述符对应的槽位的页进行淘汰。如果不是0,则将值减1,继续遍历下一个描述符,一直到找到淘汰页。
/*
* StrategyGetBuffer
*
* Called by the bufmgr to get the next candidate buffer to use in
* BufferAlloc(). The only hard requirement BufferAlloc() has is that
* the selected buffer must not currently be pinned by anyone.
*
* strategy is a BufferAccessStrategy object, or NULL for default strategy.
*
* To ensure that no one else can pin the buffer before we do, we must
* return the buffer with the buffer header spinlock still held.
*/
BufferDesc *StrategyGetBuffer(BufferAccessStrategy strategy, uint32 *buf_state)
{
BufferDesc *buf;
int bgwprocno;
int trycounter;
uint32 local_buf_state; /* to avoid repeated (de-)referencing */
// ...
/*
* We count buffer allocation requests so that the bgwriter can estimate
* the rate of buffer consumption. Note that buffers recycled by a
* strategy object are intentionally not counted here.
*/
pg_atomic_fetch_add_u32(&StrategyControl->numBufferAllocs, 1);
// 首先检查freelist中是否还有空闲空间,如果有,直接获取下一个free buffer,如果没有,则需要进入时钟扫描算法淘汰逻辑。
if (StrategyControl->firstFreeBuffer >= 0)
{
while (true)
{
/* Acquire the spinlock to remove element from the freelist */
SpinLockAcquire(&StrategyControl->buffer_strategy_lock);
if (StrategyControl->firstFreeBuffer < 0)
{
SpinLockRelease(&StrategyControl->buffer_strategy_lock);
break;
}
// 直接从freelist中获取free buffer
buf = GetBufferDescriptor(StrategyControl->firstFreeBuffer);
Assert(buf->freeNext != FREENEXT_NOT_IN_LIST);
/* Unconditionally remove buffer from freelist */
StrategyControl->firstFreeBuffer = buf->freeNext;
buf->freeNext = FREENEXT_NOT_IN_LIST;
// ...
}
}
// 如果没有空闲页了,则需要执行时钟扫描算法淘汰掉一个页
/* Nothing on the freelist, so run the "clock sweep" algorithm */
trycounter = NBuffers;
for (;;)
{
buf = GetBufferDescriptor(ClockSweepTick()); // 相当于环形缓冲描述符数组
/*
* If the buffer is pinned or has a nonzero usage_count, we cannot use
* it; decrement the usage_count (unless pinned) and keep scanning.
*/
local_buf_state = LockBufHdr(buf);
if (BUF_STATE_GET_REFCOUNT(local_buf_state) == 0)
{
if (BUF_STATE_GET_USAGECOUNT(local_buf_state) != 0)
{
local_buf_state -= BUF_USAGECOUNT_ONE; // usagecount != 0, 则减1
trycounter = NBuffers;
}
else
{
/* Found a usable buffer */
if (strategy != NULL)
AddBufferToRing(strategy, buf);
*buf_state = local_buf_state;
return buf; // 发现usagecount==0, 淘汰该页
}
}
else if (--trycounter == 0)
{
/*
* We've scanned all the buffers without making any state changes,
* so all the buffers are pinned (or were when we looked at them).
* We could hope that someone will free one eventually, but it's
* probably better to fail than to risk getting stuck in an
* infinite loop.
*/
UnlockBufHdr(buf, local_buf_state);
elog(ERROR, "no unpinned buffers available");
}
UnlockBufHdr(buf, local_buf_state);
}
}
// 相当于环形缓冲描述符数组
/* ClockSweepTick - Helper routine for StrategyGetBuffer()
*
* Move the clock hand one buffer ahead of its current position and return the
* id of the buffer now under the hand. */
static inline uint32 ClockSweepTick(void)
{
uint32 victim;
/*
* Atomically move hand ahead one buffer - if there's several processes
* doing this, this can lead to buffers being returned slightly out of
* apparent order.
*/
victim =
pg_atomic_fetch_add_u32(&StrategyControl->nextVictimBuffer, 1);
if (victim >= NBuffers)
{
uint32 originalVictim = victim;
/* always wrap what we look up in BufferDescriptors */
victim = victim % NBuffers;
/*
* If we're the one that just caused a wraparound, force
* completePasses to be incremented while holding the spinlock. We
* need the spinlock so StrategySyncStart() can return a consistent
* value consisting of nextVictimBuffer and completePasses.
*/
if (victim == 0)
{
uint32 expected;
uint32 wrapped;
bool success = false;
expected = originalVictim + 1;
while (!success)
{
/*
* Acquire the spinlock while increasing completePasses. That
* allows other readers to read nextVictimBuffer and
* completePasses in a consistent manner which is required for
* StrategySyncStart(). In theory delaying the increment
* could lead to an overflow of nextVictimBuffers, but that's
* highly unlikely and wouldn't be particularly harmful.
*/
SpinLockAcquire(&StrategyControl->buffer_strategy_lock);
wrapped = expected % NBuffers;
success = pg_atomic_compare_exchange_u32(&StrategyControl->nextVictimBuffer,
&expected, wrapped);
if (success)
StrategyControl->completePasses++;
SpinLockRelease(&StrategyControl->buffer_strategy_lock);
}
}
}
return victim;
}
缓冲区初始化
要创建一个缓冲区,首先要初始化,面临的第一个问题就是创建多大的缓冲区,大小是否可动态调整,
main(int argc, char *argv[])
--> PostmasterMain(argc, argv);
--> reset_shared(); // Set up shared memory and semaphores.
--> CreateSharedMemoryAndSemaphores(); // Creates and initializes shared memory and semaphores.
--> CalculateShmemSize(&numSemas); // Calculates the amount of shared memory and number of semaphores needed.
--> add_size(size, BufferShmemSize());
--> PGSharedMemoryCreate(size, &shim);
--> InitShmemAccess(seghdr);
--> InitBufferPool(); // 初始化缓冲池
// 1. 初始化buffer descriptor
--> ShmemInitStruct("Buffer Descriptors",NBuffers * sizeof(BufferDescPadded),&foundDescs);
// 2. 初始化buffer pool
--> ShmemInitStruct("Buffer Blocks", NBuffers * (Size) BLCKSZ, &foundBufs);
--> StrategyInitialize(!foundDescs);
// 3. 初始化 buffer table
--> InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS);
--> ShmemInitHash("Shared Buffer Lookup Table", size, size, &info, HASH_ELEM | HASH_BLOBS | HASH_PARTITION);
--> hash_create(name, init_size, infoP, hash_flags);
缓冲区初始化,分配空间
void InitBufferPool(void)
{
bool foundBufs,foundDescs,foundIOCV,foundBufCkpt;
/* Align descriptors to a cacheline boundary. */
BufferDescriptors = (BufferDescPadded *) // 缓冲区描述符
ShmemInitStruct("Buffer Descriptors",
NBuffers * sizeof(BufferDescPadded),
&foundDescs);
BufferBlocks = (char *) // 缓冲池,存放数据页
ShmemInitStruct("Buffer Blocks",
NBuffers * (Size) BLCKSZ, &foundBufs);
// ...
}
/*
* Initialize shmem hash table for mapping buffers
* size is the desired hash table size (possibly more than NBuffers)
*/
void InitBufTable(int size)
{
HASHCTL info;
/* assume no locking is needed yet */
/* BufferTag maps to Buffer */
info.keysize = sizeof(BufferTag);
info.entrysize = sizeof(BufferLookupEnt);
info.num_partitions = NUM_BUFFER_PARTITIONS;
// 哈希表
SharedBufHash = ShmemInitHash("Shared Buffer Lookup Table",
size, size,
&info,
HASH_ELEM | HASH_BLOBS | HASH_PARTITION);
}
计算Buffer大小,引入shared_buffer配置参数。
int NBuffers = 1000; // GUC参数shared_buffer的值
/*
* BufferShmemSize
*
* compute the size of shared memory for the buffer pool including
* data pages, buffer descriptors, hash tables, etc.
*/
Size
BufferShmemSize(void)
{
Size size = 0;
/* size of buffer descriptors */
size = add_size(size, mul_size(NBuffers, sizeof(BufferDescPadded)));
/* to allow aligning buffer descriptors */
size = add_size(size, PG_CACHE_LINE_SIZE);
/* size of data pages */
size = add_size(size, mul_size(NBuffers, BLCKSZ));
/* size of stuff controlled by freelist.c */
size = add_size(size, StrategyShmemSize());
/* size of I/O condition variables */
size = add_size(size, mul_size(NBuffers,
sizeof(ConditionVariableMinimallyPadded)));
/* to allow aligning the above */
size = add_size(size, PG_CACHE_LINE_SIZE);
/* size of checkpoint sort array in bufmgr.c */
size = add_size(size, mul_size(NBuffers, sizeof(CkptSortItem)));
return size;
}