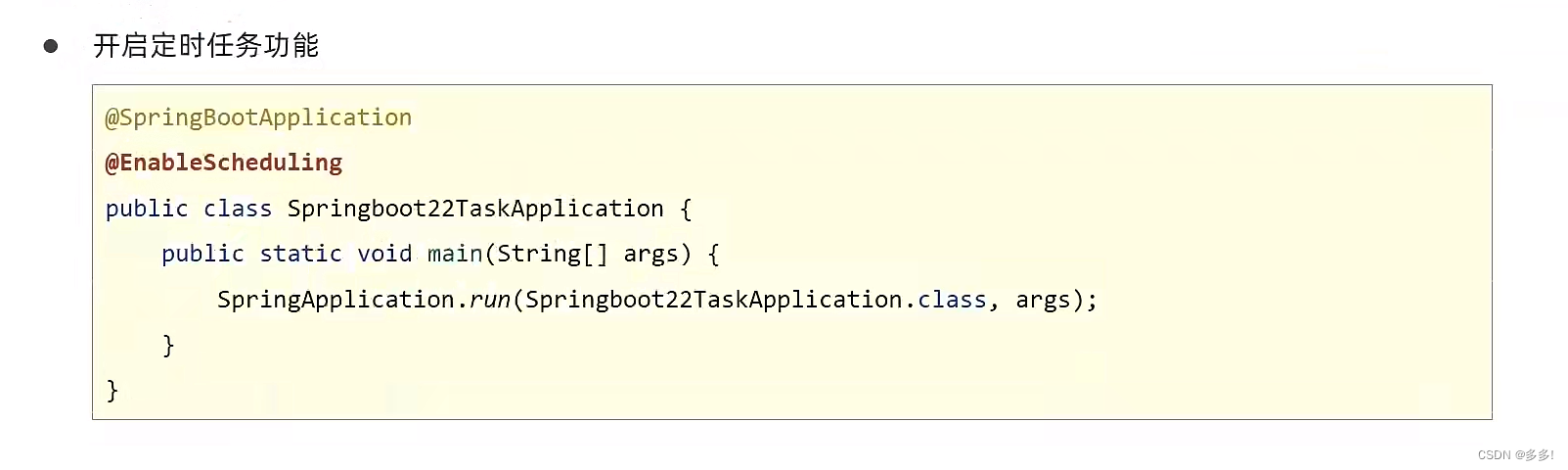
Scikit-Learn支持向量机回归
-
- 1、支持向量机回归
-
- 1.1、最大间隔与SVM的分类
- 1.2、软间隔最大化
- 1.3、支持向量机回归
- 1.4、支持向量机回归的优缺点
- 2、Scikit-Learn支持向量机回归
-
- 2.1、Scikit-Learn支持向量机回归API
- 2.2、支持向量机回归初体验
- 2.3、支持向量机回归实践(加州房价预测)
1、支持向量机回归
支持向量机(Support Vector Machine,SVM)算法既可以用于回归问题(SVR),也可以用于分类问题(SVC)。通常情况下,SVM用于分类问题,但后来也被扩展用于回归问题。SVM(回归)在机器学习知识结构中的位置如下:
1.1、最大间隔与SVM的分类
SVM是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,他的学习策略就是间隔最大化
如图所示,三条直线分别代表三个SVM分类器,请问哪一个分类器比较好?

凭直观感受答案应该是H3。首先H1不能把类别分开;H2可以,但分割线与最近的数据点只有很小的间隔,如果测试数据有一些噪声的话可能就会被H2错误分类(即对噪声敏感、泛化能力弱)。H3以较大间隔将它们分开,这样就能容忍测试数据的一些噪声,是一个泛化能力不错的分类器
对于支持向量机来说,数据点若是p维向量,我们用p−1维的超平面来分开这些点。但是可能有许多超平面可以把数据分类。最佳超平面的一个合理选择就是以最大间隔把两个类分开的超平面。因此,SVM选择能够使离超平面最近的数据点的到超平面距离最大的超平面
以上介绍的SVM只能解决线性可分的问题,为了解决更加复杂的问题,支持向量机学习方法由简至繁可分为三类:
-
线性可分SVM
当训练数据线性可分时,通过硬间隔(Hard Margin)最大化学习一个线性的分类器,即线性可分支持向量机(亦称作硬间隔支持向量机)
-
线性SVM
当训练数据不能线性可分但是可以近似线性可分时,通过软间隔(Soft Margin)最大化学习一个线性的分类器,即线性支持向量机(又称作软间隔支持向量机)
-
非线性SVM
当训练数据线性不可分时,通过使用核技巧(Kernel Trick)及软间隔最大化可以学习非线性支持向量机,等价于隐式地在高维特征空间中学习线性支持向量机
1.2、软间隔最大化
在实际应用中,完全线性可分(硬间隔)的情况非常少见。例如下面的分类图,我们没有办法找到一条直线,把空间划分为2个区域,因此,要对其进行切分,有以下两种方案:
1)仍然使用直线,不过不追求完全可分,适当包容一些分错的情况(线性SVM)

在这个过程中,我们会在模型中加入惩罚函数,尽量让分错的点不要太多。对分错点的惩罚函数就是这个点到其正确位置的距离
如上图所示,黄色、蓝色的直线分别为支持向量所在的边界,黑色的线为决策函数,那些绿色的线表示分错的点到其相应的决策面的距离,这样我们可以在原函数上面加上一个惩罚函数,并且带上其限制条件为:

上式为在线性可分问题的基础上加上的惩罚函数部分,当 x i x_i xi在正确一边的时候, ε i \varepsilon_i εi=0,R为全部的样本点的数目,C是惩罚系数
- 当C很大的时候,分错的点就会更少,但是过拟合的情况可能会比较严重
- 当C很小的时候,分错的点可能会很多,不过可能由此得到的模型也会不太正确
C越小对误分类的惩罚越小,C越大对误分类的惩罚越大,当C取正无穷时就变成了硬间隔优化。C越小越容易欠拟合,C越大越容易过拟合。实际应用中我们也会调整和选择合适的C值
2)用曲线将其完全分开,即非线性的决策边界(非线性SVM)

如果我们要处理的分类问题更加复杂,甚至不能像上面一样近似线性可分,这种情况下找到的超平面分错的程度太高,是不可接受的
对于这样的问题,解决的方案是将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分,然后再运用SVM求解。这个映射的函数称为核函数

更多关于软间隔与硬间隔、SVM的损失函数、核函数以及SVM分类的介绍详见文章:传送门
1.3、支持向量机回归
支持向量机回归的核心思想是通过最小化预测误差来拟合数据,并且在拟合过程中保持一个边界(间隔),使得大部分数据点都落在这个边界之内。SVR与分类问题中的支持向量机(SVC)类似,但其目标是拟合数据而不是分离数据
在SVC中,在数据集线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的数据点称为支持向量(Support Vector)

即所有在直线 ω X \omega X ωX+ b b b= 1 1 1和直线 ω X \omega X ωX+ b b