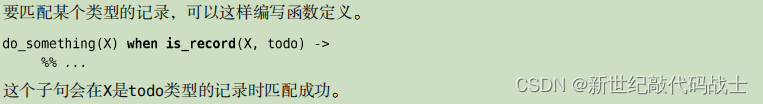两种数据容器:元组、列表
part 2 chapter5 记录与映射组
记录
记录其实就是元组的另一种形式。通过使用记录,可以给元组里的各个元素关联一个名称 。
映射
映射组是键
值对 的关联性集合。
通过记录命名元组里的项
记录的产生背景:
对于小型元组而言,记住各个元素代表什么几乎不成问题,但当元组包含大量元素时,给各个元素命名就更方便了。一旦命名了这些元素,就可以通过名称来指向它们,而不必记住它们在元组里的具体位置。
定义一个记录(text默认是undefined)
语法:
-record(recored name(atom),{key(atom)=val,key=val,...})
todo:记录名
共享相同记录定义的方式:文件包含,类似c语言的.h文件
创建一个记录的实例
#todo{}.
X=#todo{status=weak,who=tsj,text="i am sleepy"}.
复制一个记录
X1=X#todo{}.
匹配某个类型的记录
shell中撤销记录的定义
rf(record name)
映射组
创建映射组
op是=> 或 :=
键与值是有效的erlang类型
映射组在系统内部是作为有序集合存储 的,打印时总是使用各键排序后的顺序
=>更新与添加 (总是成功)
:=更新(键不存在则更新失败)
tips:使用映射组的最佳方式是在首次定义某个键时总是使用
Key => Val
,而在修改具体某个键
的值时都使用
Key := Val
。
映射组模式匹配
key(bounded)=>val (unbounded)
#{born=>B}=Henry8.
在函数的头部使用包含模式的映射组,前提是映射组里所有的键都是已知的
注意:#{H=>N}=#{},模式匹配失败
映射组排序
映射组在比较时首先会比大小(Size),然后再按照键(Key)的排序比较键和值
先Size后Key
映射组的输出与读取
输出:
io:format
里的
~p
选项输出
读取:用
io:read
或
file:consult
读取
chapter6 顺序程序的错误处理 异常什么时候发生?
异常错误发生于系统遇到内部错误时
在代码里显式调用throw(Exception)、exit(Exception)或error(Exception)触发。
显示生成一个错误?
异常的捕捉(异常发生了如何处理)
用 try...catch 捕捉异常错误
工作方式:
首先执行FuncOrExpessionSeq。如果执行过程没有抛出异 常错误,那么函数的返回值就会与Pattern1(以及可选的关卡Guard1)、Pattern2等模式进行 匹配,直到匹配成功。如果能匹配,那么整个try...catch的值就通过执行匹配模式之后的表达 式序列得出。
如果FuncOrExpressionSeq在执行中抛出了异常错误,那么ExPattern1等捕捉模式就会与
它进行匹配,找出应该执行哪一段表达式序列。ExceptionType是一个原子(throw、exit和error
其中之一),它告诉我们异常错误是如何生成的。如果省略了 ExceptionType,就会使用默认值
throw。
注:after代码一定会被执行,但是值不会返回
用 catch 捕捉异常错误
异常错误如果发生在catch语句里,就会被转换成一个描述此错误的{'EXIT', ...}元组。
捕捉一切可能的异常错误
栈跟踪
可以调用erlang:get_stacktrace()来找到最近的栈跟踪信息。
chapter7 二进制型与位语法
二进制型
二进制型(
binary
)是一种数据结构 ,它被设计成用一种节省空间的方式来保存大批量的原
始数据
二进制型的编写和打印形式是双小于号与双大于号之间的一列整数或字符串
在二进制型里使用整数时,它们必须属于
0
至
255
这个范围。
如果某个二进制型的内容是可打印的字符串,
shell
就会将这个二进制型打印成字符串,否则就打印成一列整数。
位语法
位语法是一种表示法,用于从二进制数据里提取或加入单独的位或者位串。
假设要把三个变量(
X
、
Y
和
Z
)打包进一个
16
位的内存区域。
M=<<X:3,Y:7,Z:6>>
打包和解包 16 位颜色
打包
为什么shell打印<<23,180>>?
Red=2 :00010 Green=61:111101 Blue=20:10100
23:00010111
180:10110100
解包
位语法表达式
用来构建二进制型或位串
Size的值指明了片段的大小
TypeSpecifierList(类型指定列表)是一个用连字符分隔的列表,形式为End-Sign
Type-Unit。前面这些项中的任何一个都可以被省略,各个项也可以按任意顺序排列。如果省略
了某一项,系统就会使用它的默认值。
End可以是big | little | native
Sign可以是signed|unsigned
Type可以是integer|float|binary|bytes|bitstring|bits|utf8|utf16|utf32 默认值是integer
Unit的写法是unit:1|2|…256
位串:处理位级数据
在
Erlang
里,最小可寻址的存储单元是
1 位 ,位串里各个独立的位序列可以直接访问,无
需任何移位和掩码操作。
chapter8 Erlang 顺序编程补遗
apply
内置函数
apply(Mod, Func, [Arg1, Arg2, ..., ArgN])
会将模块
Mod
里的
Func
函数应用到Arg1, Arg2, ... ArgN
这些参数上
等价于 Mod:Func(Arg1,Arg2...)
数字-->整数、浮点数
优先级相同:从左往右求值
使用(),()内表达式优先级最高
属性
-module
模块声明
-import 导入函数,在本模块内调用这些函数不用加模块名
-export
([Name1/Arity1, Name2/Arity2, ...]).
导出当前模块里的
Name1/Arity1
和
Name2/Arity2
等函数
-compile(options)
添加
Options
到编译器选项列表中
-vsn
指定模块的版本号。
使用
数
module_info/0
和
module_info/1获取模块属性
原子
true
和
false
具有特殊的含义,可以用来表示布尔值。
B1
和
B2
都必须是布尔值或者执行结果为布尔值的表达式
动态代码载入
每当调用
someModule:someFunction(...)
时,调用的总是最新版模块里的最新版函数,哪怕当代码在模块里运行时重新编译了该模块也是如此
。
在任一时刻,
Erlang
允许一个模块的两个版本同时运行:当前版和旧版。
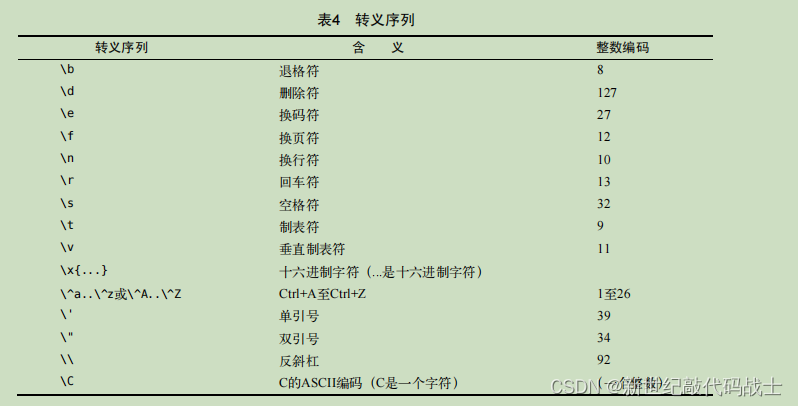
转义序列
在
Erlang
里,任何可以执行并生成一个值 的事物都被称为
表达式
(
expression
)。
包含文件
-include(Filename)
Filename
含一个绝对或相对路径
包含库的头文件
-include_lib(Filename)
宏
$ 写法
$C
这种写法代表了
ASCII
字符
C
的整数代码。因此,
$a
是
97
的简写,
$1
是
49
的简写
每个
Erlang
进程都有一个被称为
进程字典
(
process dictionary
)(即map)的私有数据存储区域
使用BIF对进程字典做操作
创建独一无二的标签,把它存放在数据里并在后面用于比较是否相等
_VarName
这种特殊语法代表一个常规变量(
normal variable),而不是匿名变量。
注意:
一般来说,当某个变量在子句里只使用了一次时,编译器会生成一 个警告
下划线变量有两种主要的用途。
命名一个我们不打算使用的变量。例如,相比
open(File, _)
,
open(File, _Mode)
这
种写法能让程序的可读性更高。
用于调试。举个例子,假设编写如下代码: