前言
在Java应用的开发和运维过程中,JVM的性能调优是一项至关重要的工作。随着业务的增长和复杂度的提升,线上问题排查、内存监控、参数优化以及压力测试成为每一位开发者和运维人员必须面对的挑战。
本篇文章将带您走进JVM性能调优的世界,通过系统讲解线上问题的快速定位与解决、JVM内存的实时监控与分析、关键参数的精细调优策略以及如何进行有效的压力测试,让您掌握一套完整的JVM调优方法论。
一.JVM监控命令
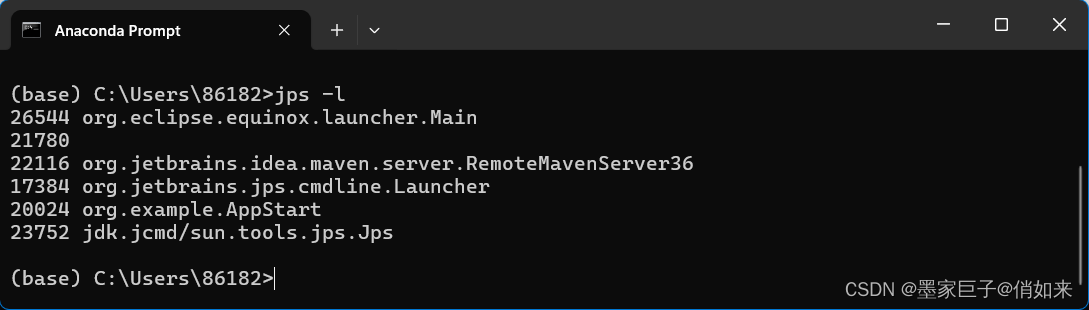
1.查看进程:jps
jps(Java Virtual Machine Process Status Tool)是Java开发工具包(JDK)中的一个命令行工具,用于列出当前运行的Java虚拟机(JVM)进程以及它们的主要类名或JAR文件名。这对于诊断JVM进程、确定哪些Java应用程序正在运行以及它们的进程ID(PID)等非常有用。
语法格式:jps [options] [hostid]
- options:可选的命令行参数,用于指定要显示的信息。
- hostid:可选的参数,用于指定要查询的远程主机。如果省略,则默认为本地主机。
常用选项:
- -l:显示主类名或JAR文件名。
- -m:显示传递给主方法的参数(如果存在)。
- -q:只显示进程ID,不显示其他信息。
- -v:显示传递给JVM的参数。
- -V:显示通过标志文件(如果存在)和命令行传递给JVM的参数。
- -J:将指定的参数传递给底层JVM实例。例如,-J-Xms512m 会设置JVM的初始堆大小为512MB(但通常,这个选项不会与jps一起使用,因为它更多是用于像jinfo、jmap等其他JVM工具)。
示例 :列出当前系统上所有运行的Java进程及其进程ID:
2.查看堆信息:jmap
jmap是Java Development Kit (JDK)自带的一个工具,主要用于生成Java堆转储文件(Heap Dump)和查看Java堆的详细信息。它帮助开发人员分析和调试Java应用程序在运行时产生的内存问题。
查看堆信息:jmap -heap <pid>:显示进程ID为的Java应用程序的堆使用情况。
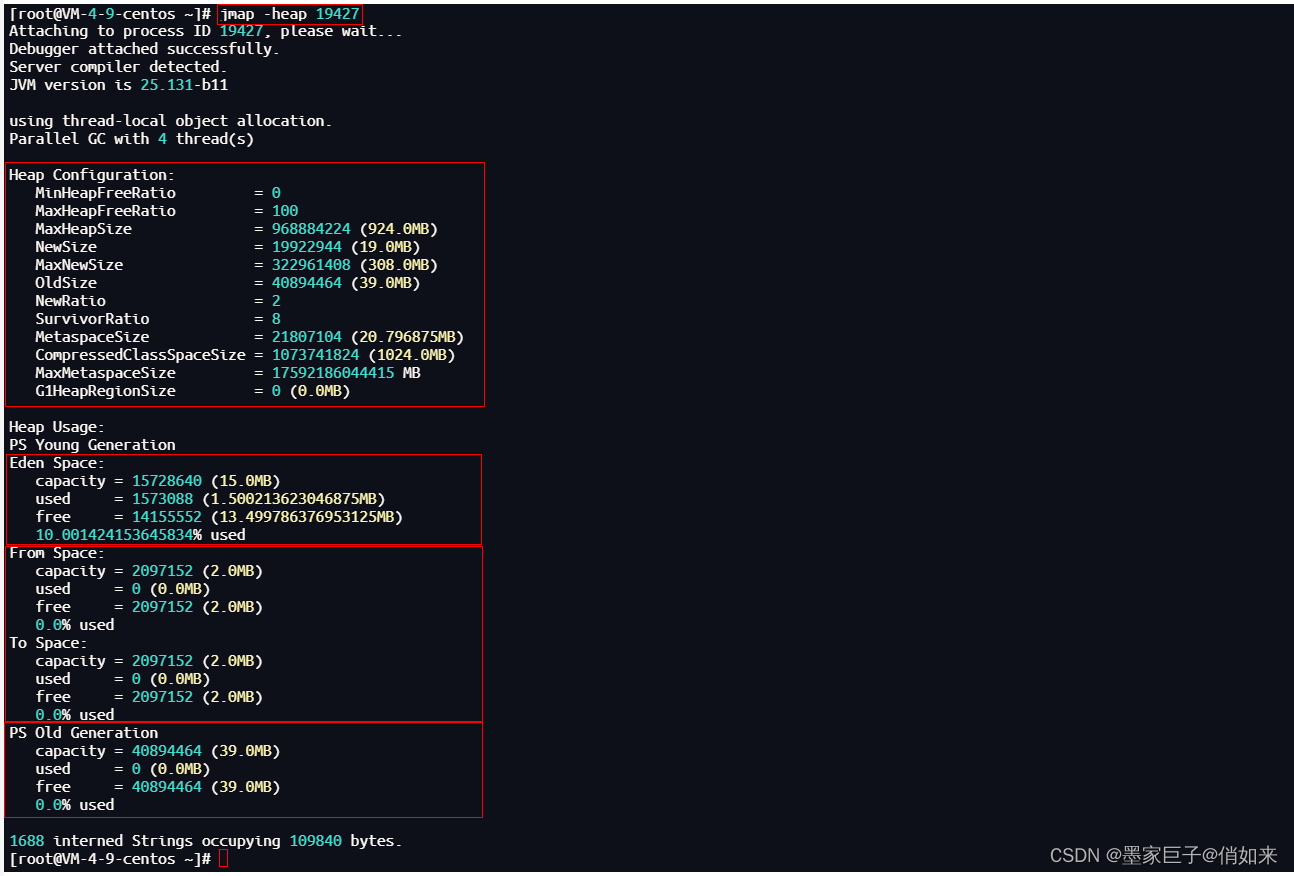
- 堆的配置信息
- 年轻代的内存情况
- 幸存区的内存情况
- 老年代的内存情况
对象的统计信息:jmap -histo <pid>:获取进程ID为的Java应用程序中对象的统计信息。它将显示不同类的对象数量以及每个对象的内存使用情况。如果要转文件可以通过: jmap -histo <pid> > log.txt
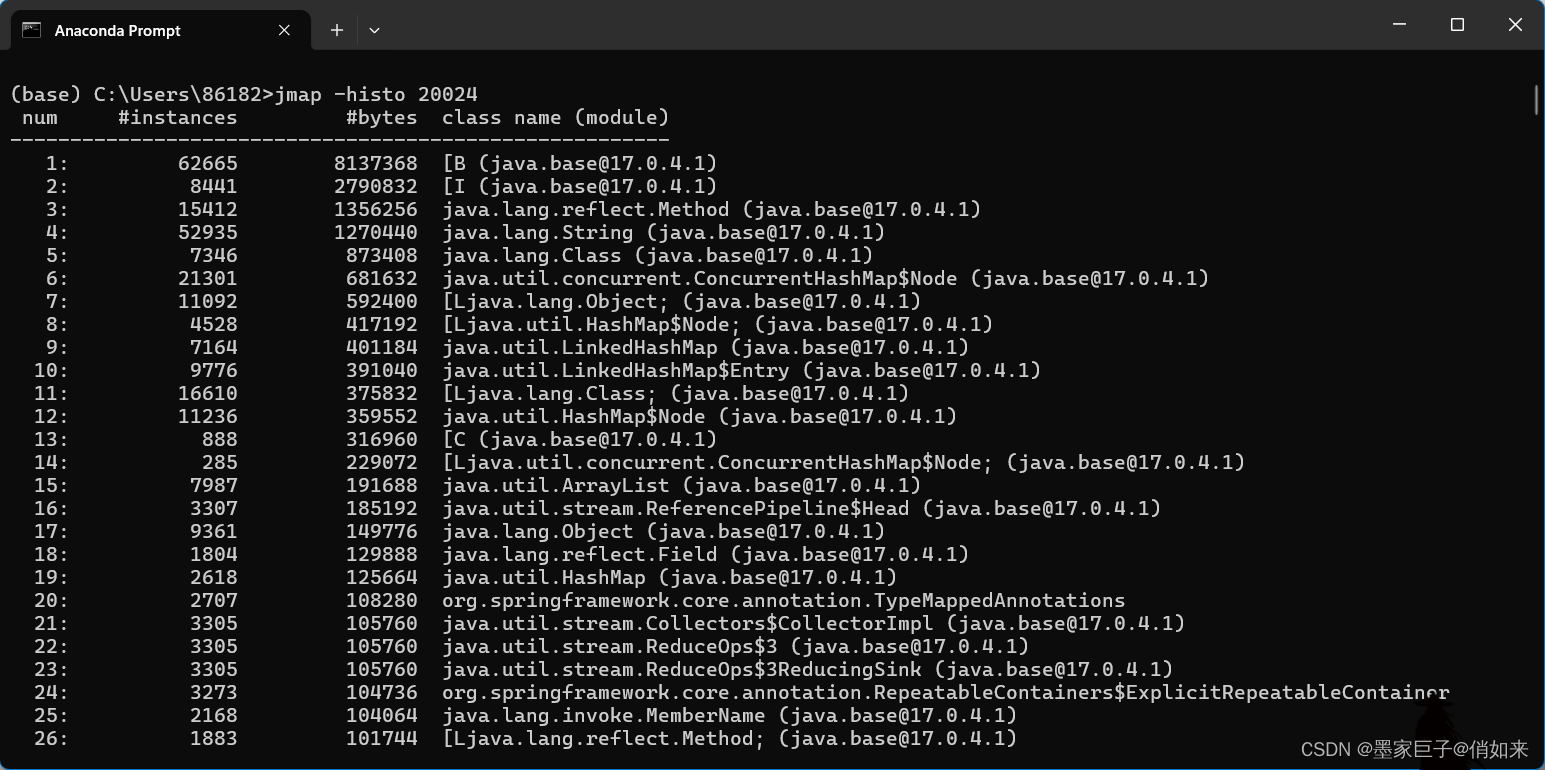
- num:序号
- instances:实例数量
- bytes:占用空间大小
- class name:类名称,[C 代表 char[],[S 代表 short[],[I 代表 int[],[B 代表 byte[],[I 代表 int[]
导出堆转储文件:jmap -dump:file=<file_path> <pid>:将堆快照导出到指定的文件路径<file_path>。是进程ID,指定要导出堆快照的Java应用程序。案例:jmap ‐dump:format=b,file=xxxxx.hprof pid
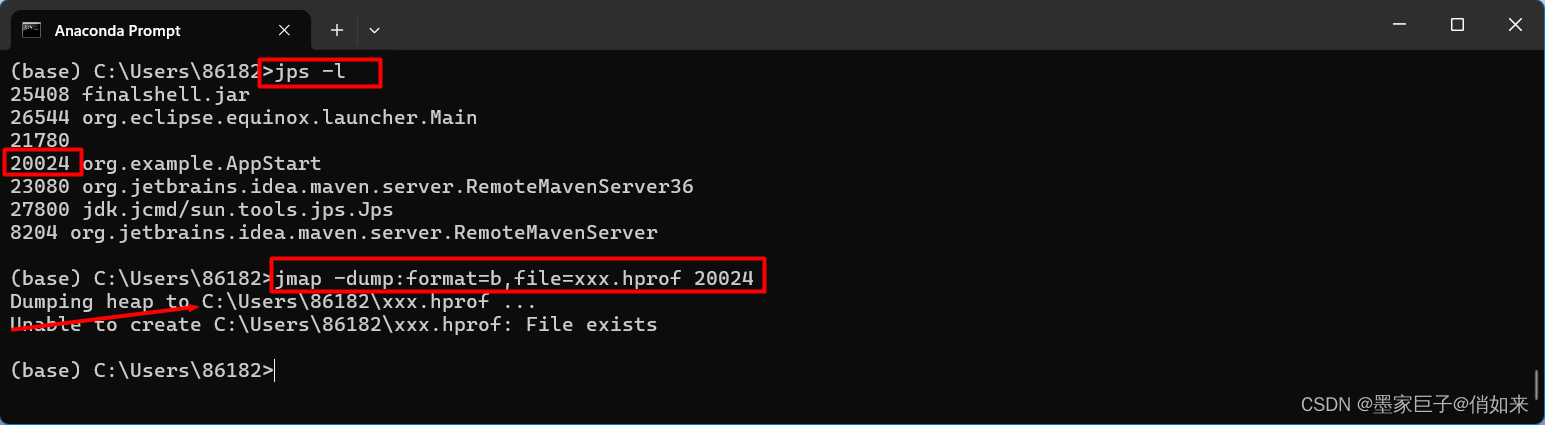
jstack用于打印出给定的Java进程ID(pid)、core文件或远程调试服务的Java堆栈信息。
3.查看线程快照:jstack , 解决死锁
jstack [option] pid 用于打印出给定的Java进程ID(pid)、core文件或远程调试服务的Java堆栈信息。我们可以通过它来生成线程快照以定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
下面是通过jstack [option] pid 分析死锁场景 比如我有一死锁的代码如下
public class DeadLockTest {
static Object lock = new Object();
static Object lock2 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + ":lock执行了...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (lock2) {
System.out.println(Thread.currentThread().getName() + ":lock2 执行了...");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (lock2) {
System.out.println(Thread.currentThread().getName() + ":lock2执行了...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + ":lock执行了...");
}
}
});
t1.start();
t2.start();
}
}
上面代码我们使用2个线程互相抢锁,程序运行起来之后就会出现死锁情况,要排查这个问题先通过jps 查看进程ID

然后通过 jstack pid 查看线程快照 ,该命令可以看到每个线程的执行情况,比如:
- Thread-xxx" : 线程名
- prio=5 : 优先级=5
- tid=xxx : 线程id
- nid=0x2d64 : 线程对应的本地线程标识nid
- java.lang.Thread.State: BLOCKED : 线程状态
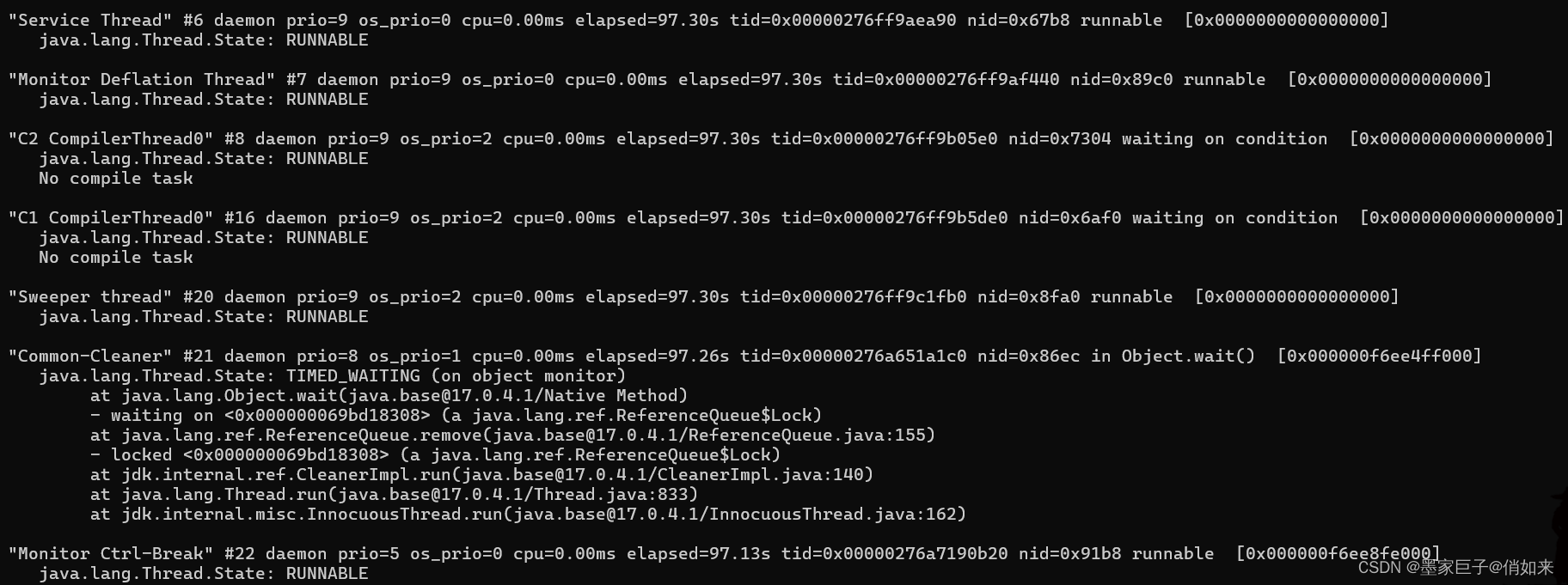
对于死锁的情况我们翻到最后面,它可以直接告诉我们哪个线程出现了死锁的情况并指出在哪一行出现的死锁
4.查看线程快照:jstack ,解决CPU飚高
在生产环境中我们经常遇到CPU忽然飚高的问题,也可以通过jstack快速定位,一般 CPU 飚高是代码出现大量循环或者进行着复杂的计算。排查的核心思路是 :
- 先定位是
哪个进程占用CPU最高,可以直接通过jps拿到进程ID - 定位到进程后再去定位进程中种的哪个线程占用CPU资源最多,从而再通过线程快照找到耗CPU的代码
第一步:直接使用 jps得到进程后

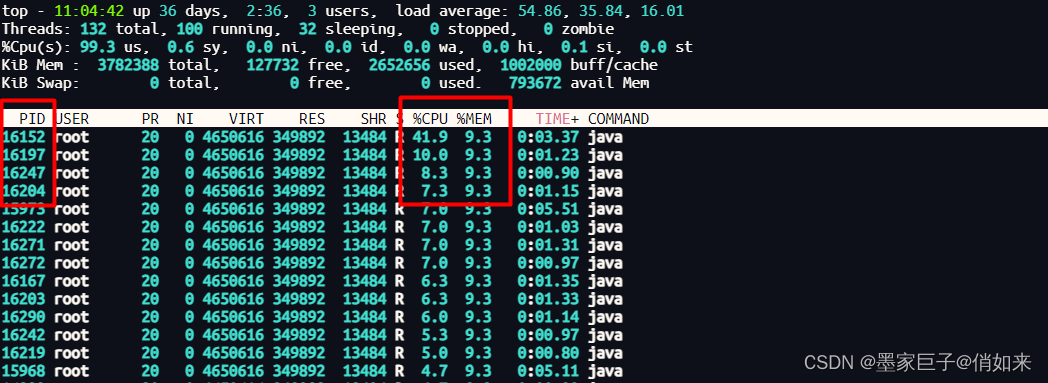
使用 top -p 进程ID 查看,显示你的java进程的内存情况,pid是你的java进程号,如下

第二步:按大写的 H ,列出进程中的每个线程情况,找到最耗内存和CPU的线程ID
第三步:把线程ID转为 16进制 ,使用:printf "%x\n" 线程ID(百度:在线转换) ,因为在JVM中是以16进制表示线程ID的
printf "%x\n" 16152
第四步:执行 jstack 进程ID|grep -A 10 线程ID,得到线程堆栈信息中 当前 线程所在行的后面10行,从堆栈中可以发现导致cpu飙高的调用方法
jstack 15918 | grep -A 10 3f18
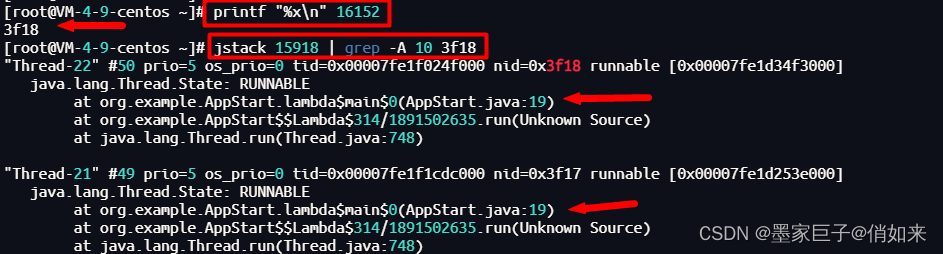
定位到代码之后,我们就可以找到对应的代码进行分析问题原因了。这里总结一下步骤
1. jps -l :查看进程
2. top -p 进程ID -> 按 H : 查看线程的CPU排名
3. printf "%x\n" 线程ID : 获取线程ID的16进制
4. jstack 进程ID|grep -A 20 线程ID : 定义CPU飚高的线程代码
5.查看Java参数:Jinfo
jinfo [option] pid查看正在运行的Java应用程序的扩展参数,这对于调试 Java 应用程序或分析 JVM 的运行时环境非常有用。
案例:查看 Java 进程的所有 JVM 参数
[root@VM-4-9-centos ~]# jps
14144 Jps
12699 jar
[root@VM-4-9-centos ~]# jinfo -flags 12699
效果如下:可以看到垃圾回收器,初始堆,最大堆,新生代,老年代等区域大小

查看 Java 进程的所有系统属性
[root@VM-4-9-centos ~]# jinfo -sysprops 12699
...
Attaching to process ID 12699, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.131-b11
java.runtime.name = Java(TM) SE Runtime Environment
java.vm.version = 25.131-b11
sun.boot.library.path = /usr/local/jdk1.8.0_131/jre/lib/amd64
java.vendor.url = http://java.oracle.com/
java.vm.vendor = Oracle Corporation
path.separator = :
file.encoding.pkg = sun.io
java.vm.name = Java HotSpot(TM) 64-Bit Server VM
sun.os.patch.level = unknown
sun.java.launcher = SUN_STANDARD
user.country = US
user.dir = /root
6.垃圾回收监控 jstat
jstat主要用于监控 Java 虚拟机(JVM)的各种运行状态信息,能够实时地监控 Java 应用程序的资源使用情况和性能,包括类加载、内存、垃圾收集、即时编译等方面的信息。 jstat常用的选项如下
- -class:显示加载的类数量及所占空间。
- -compiler:显示 VM 实时编译的数量等信息。
- -gc:显示垃圾收集的次数及时间。
- -gccapacity:显示 VM 内存中三代(young/old/perm)对象的使用和占用大小。
- -gcutil:统计垃圾收集信息的百分比。
- -gccause:显示最近一次 GC 的统计和原因。
- -gcnew 和 -gcold:分别显示年轻代和老年代对象的信息。
- -printcompilation:显示 JVM 编译方法统计。
最常用的是jstat -gc pid 500 10 查看GC情况 ,每500毫秒打印一次,一共打印10次,通过观察EU(eden区的使用)来估算每秒eden大概新增多少对象,如果系统负载不高,可以把频率换成1分钟,甚至10分钟来观察整体情况。注意,一般系统可能有高峰期和日常期,所以需要在不同的时间分别估算不同情况下对象增长速率。
[root@VM-4-9-centos ~]# jps
12699 jar
29183 Jps
[root@VM-4-9-centos ~]# jstat -gc 12699 500 10
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
2048.0 2048.0 0.0 0.0 15360.0 1843.4 39936.0 0.0 4480.0 774.5 384.0 75.9 0 0.000 0 0.000 0.000
解释
- S0C:第一个幸存区的大小,单位KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
案例:显示某进程的 JVM 的各个代容量和使用情况:jstat -gccapacity pid
[root@VM-4-9-centos ~]# jps
27350 Jps
27022 jar
[root@VM-4-9-centos ~]# jstat -gccapacity 27022
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
19456.0 315392.0 19456.0 2048.0 2048.0 15360.0 39936.0 630784.0 39936.0 39936.0 0.0 1056768.0 4480.0 0.0 1048576.0 384.0 0 0
[root@VM-4-9-centos ~]#
每一列的含义如下:
-
NGCMN:新生代最小容量。
-
NGCMX:新生代最大容量。
-
NGC:当前新生代容量。
-
S0C:第一个幸存者区的容量。
-
S1C:第二个幸存者区的容量。
-
EC:伊甸园区的容量。
-
OGCMN:老年代最小容量(仅在Java 8及以前版本显示)。
-
OGCMX:老年代最大容量(仅在Java 8及以前版本显示)。
-
OGC:当前老年代容量(仅在Java 8及以前版本显示)。
-
OC:老年代容量(在Java 8及以后版本显示)。
-
MCMN:最小元数据容量(只在Java 8及以后版本显示)。
-
MCMX:最大元数据容量(只在Java 8及以后版本显示)。
-
MC:当前元数据容量(只在Java 8及以后版本显示)。
-
CCSMN:最小压缩类空间大小(只在Java 8及以后版本显示)。
-
CCSMX:最大压缩类空间大小(只在Java 8及以后版本显示)。
-
CCSC:当前压缩类空间大小(只在Java 8及以后版本显示)。
-
YGC:新生代垃圾回收次数。
-
YGCT:新生代垃圾回收消耗时间。
-
FGC:老年代垃圾回收次数。
-
FGCT:老年代垃圾回收消耗时间。
-
GCT:总垃圾回收消耗时间。
二.JVM可视化工具
1.JConsole和Jvisualvm
如果对JVM的监控命令比较熟悉那么在调试线上问题的时候可以在linux环境直接使用命令进行排错,非常的方便。那么对于命令不熟悉的同学来说排查问题就比较繁琐了,JVM还提供了可视化工具帮助我们更加方便的去调试JVM。JConsole和Jvisualvm
通过cmd命令行输入 jconsole 弹出如下界面
JConsole实际上是通过JMX(Java Management Extensions)去连接一个运行中的Java程序,以获取里面的信息。而JMX想要实现远程访问,需要启动一个JMX的连接端口。因此,在启动Java应用时,需要指定一些参数来开启JMX的远程访问功能。这些参数包括:
- -Djava.rmi.server.hostname=远程服务器IP地址:指定JMX服务器的主机名或IP地址。
- -Dcom.sun.management.jmxremote.port=端口号:指定JMX服务器的端口号。例如,可以使用1099或自定义的端口号。
- -Dcom.sun.management.jmxremote.ssl=false:禁用SSL加密(如果需要启用SSL,请设置为true并配置相应的SSL证书)。
- -Dcom.sun.management.jmxremote.authenticate=false:禁用JMX认证(如果需要启用认证,请设置为true并配置相应的认证和授权文件)。
注意:在生产环境中,为了安全起见,通常建议启用SSL加密和JMX认证
java -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=3214 -Dcom.sun.management.jmxremote.hostname=101.35.235.40 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar your-application.jar
然后使用JConsole和Jvisualvm就可以进行远程连接了,在连接时,需要提供正确的主机名、端口号和用户名和密码(如果需要的话)。
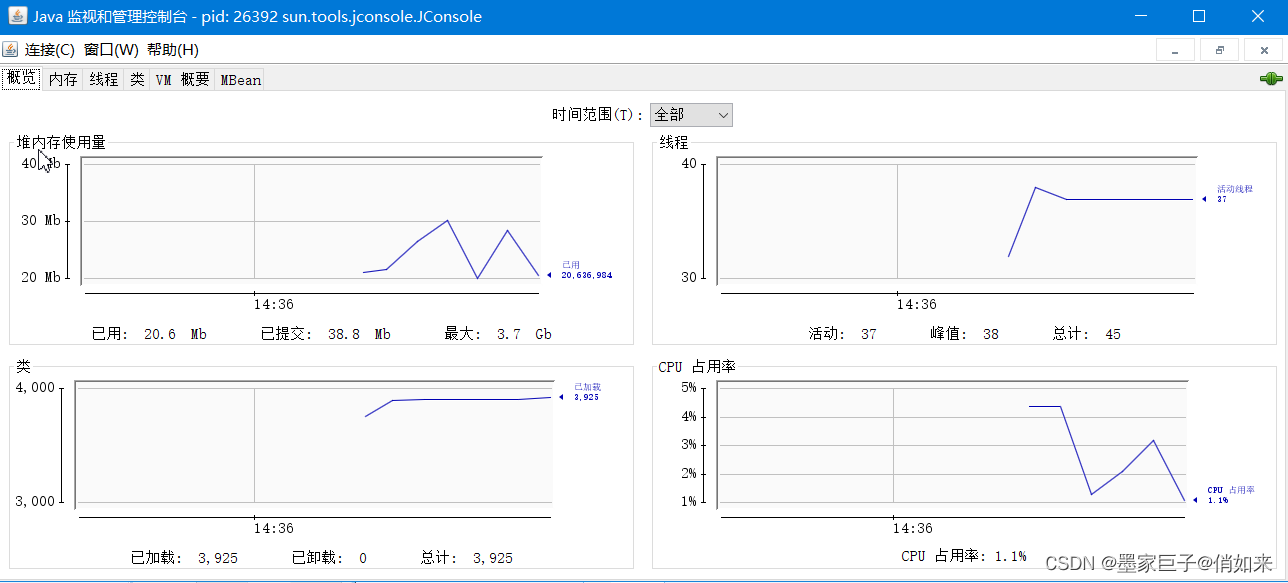
选择一个java进程点击进去,进入后可以看到内存的情况,类加载情况,线程情况等等。
JVM提供的另一款JVM工具是Jvisualvm,同样使用cmd执行命令Jvisualvm ,左边本地菜单下是java进程,选择一个进程后右边可以看到堆,类加载情况,现成情况等
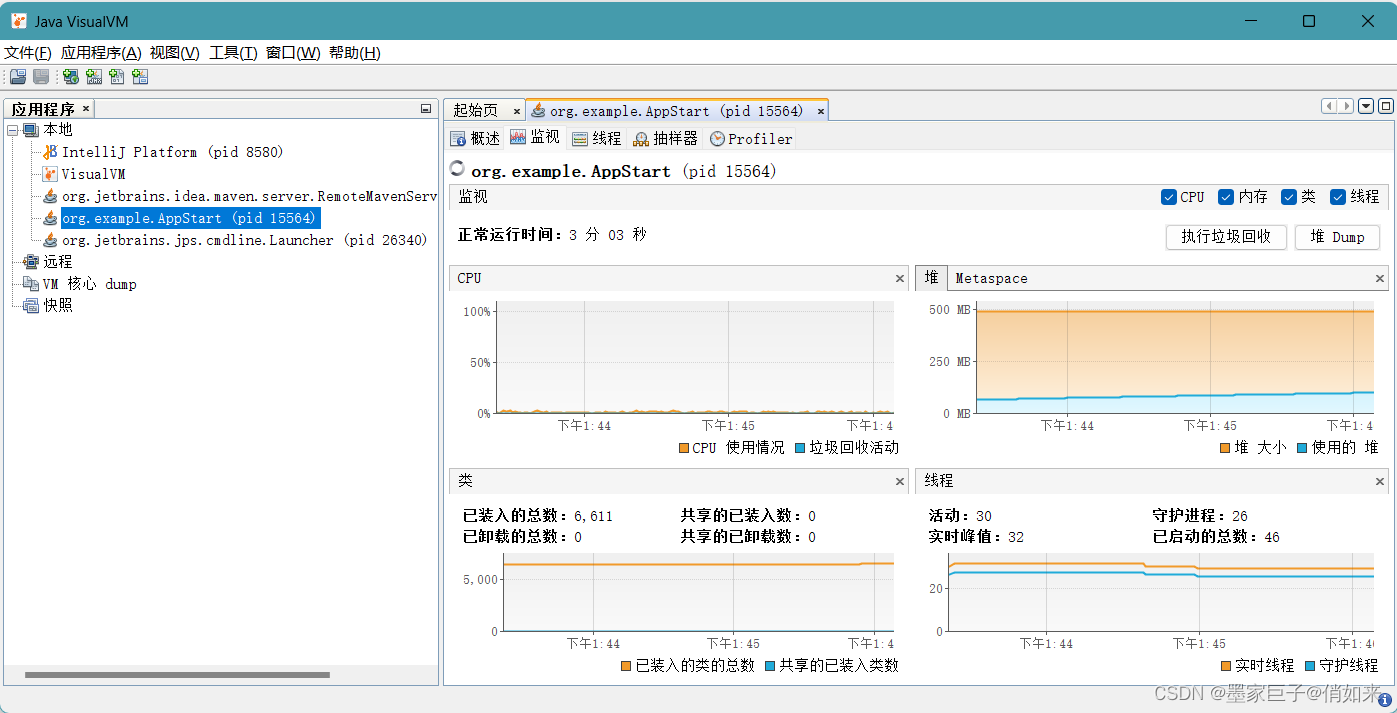
- 在监视面板中可以监视到:CPU,堆,类,线程的执行情况,
堆 Dump按钮可以下载堆快照,类似于jmap -dump命令 - 在线程面板中可以看到线程执行情况,点击
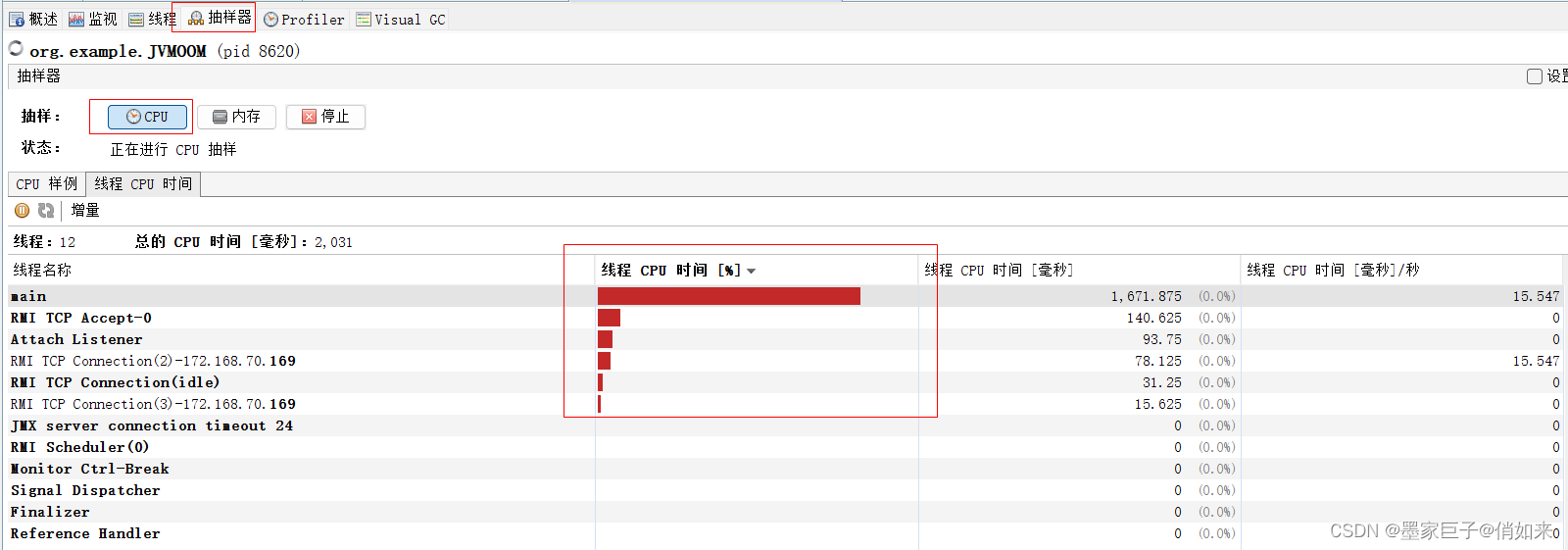
线程 Dump可以查看线程快照,如同jstack命令 - 在抽样器 - CPU - 线程CPU时间中可以看到线程消耗CPU的耗时情况,从而定位出那个线程
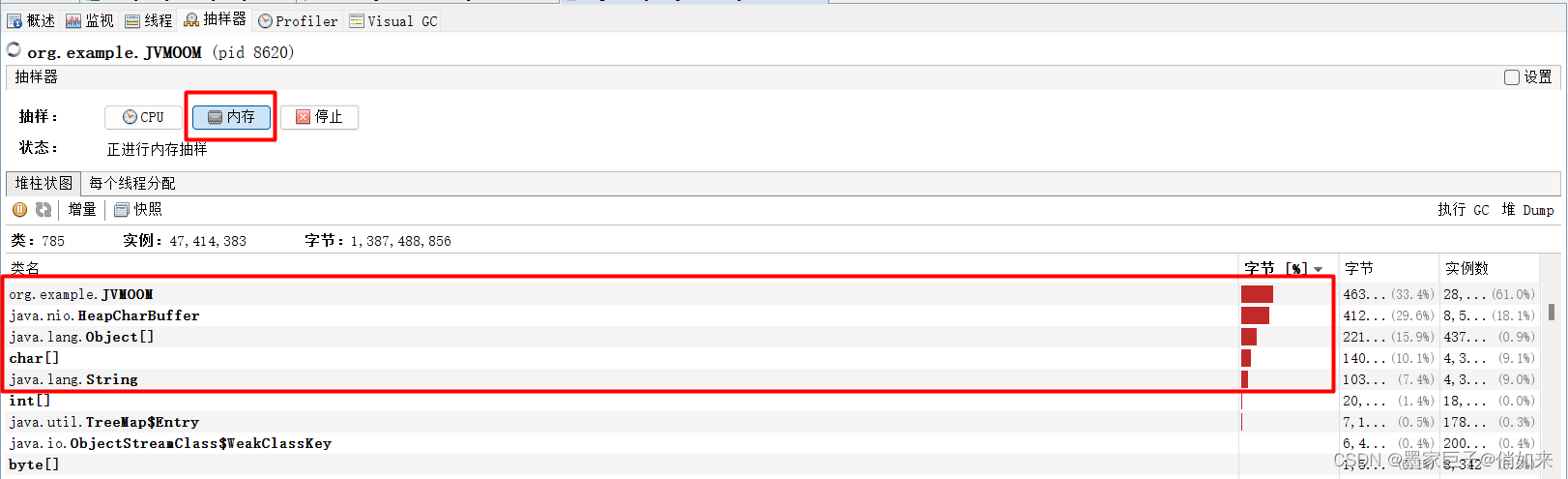
- 在内存一栏中可以定位出哪个实例最消耗内存
2.jvisualvm安装GC插件
自带的jvisualvm没有监视GC垃圾回收功能,我们需要额外安装插件:
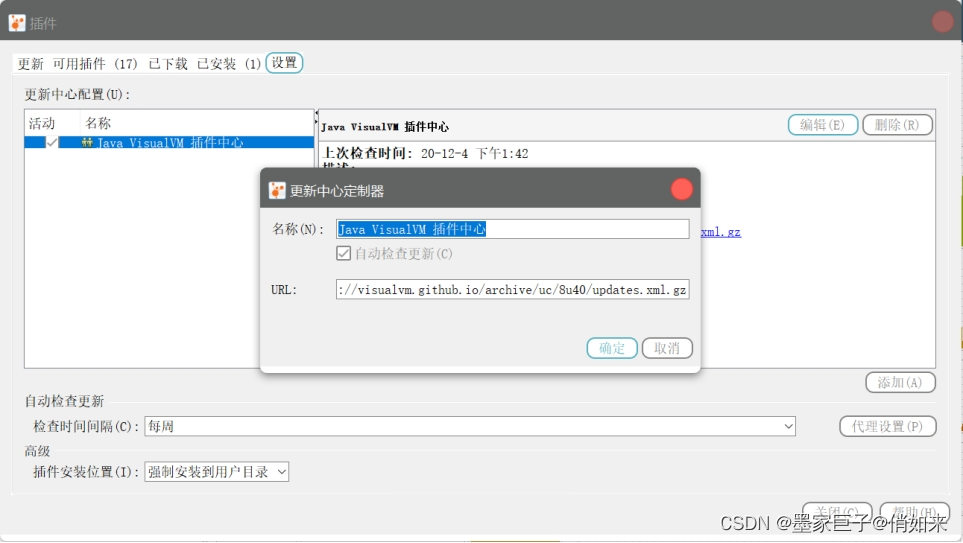
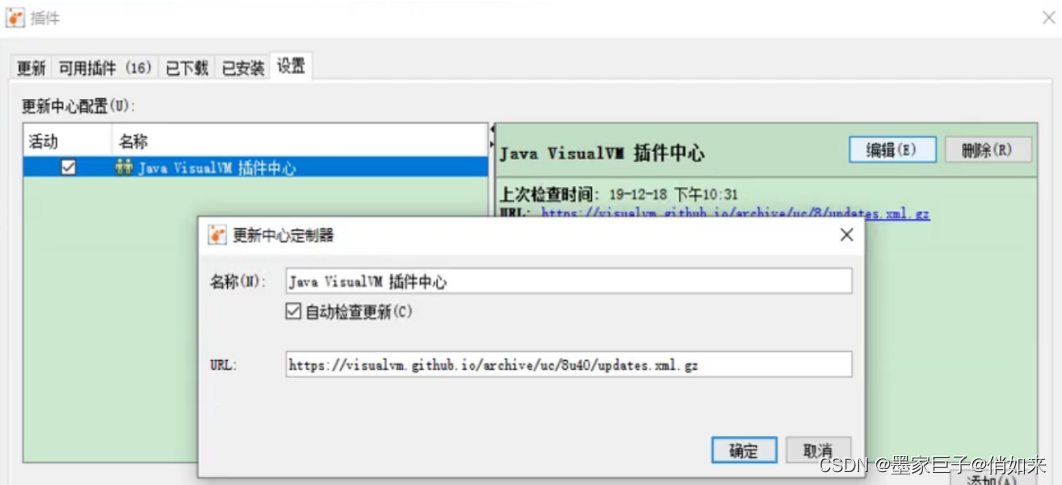
打开工具 -> 插件 -> 选择“可用插件”页 : 我们在这里安装一个Visual GC,方便我们看到内存回收以及各个分代的情况 . 打上勾之后点击安装,就是常规的next以及同意协议等 ,网络不是很稳定,有时候可能需要多尝试几次。可以在设置中修改插件中心地址:
根据如下步骤修改地址:找到插件中心 http://visualvm.github.io/pluginscenters.html
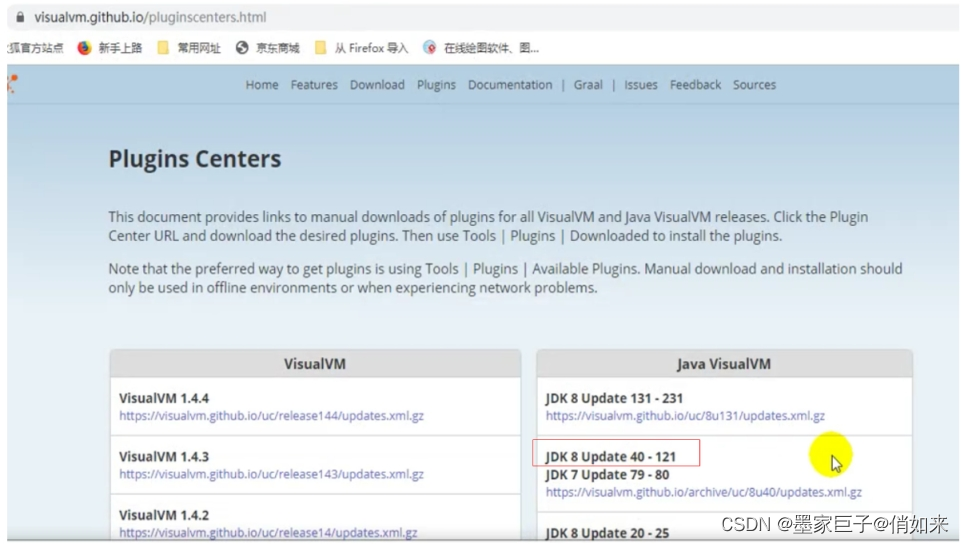
找到对应的JDK版本:http://visualvm.github.io/archive/uc/8u40/updates.html,复制插件地址:在设置中修改URL
然后选择GC插件进行安装
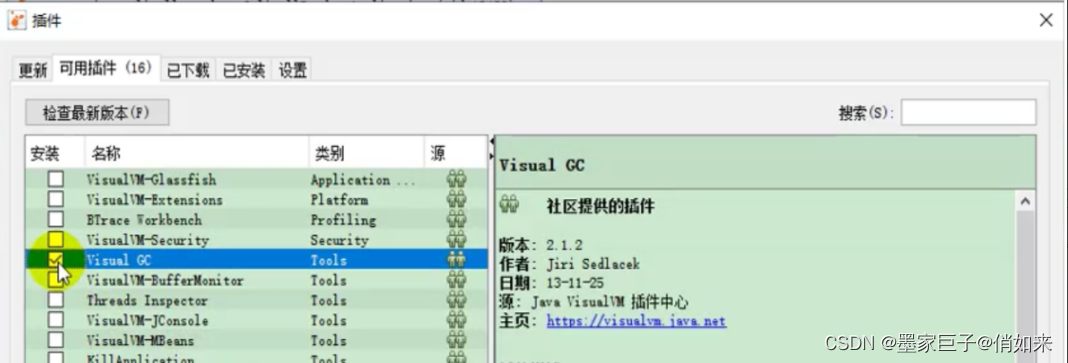
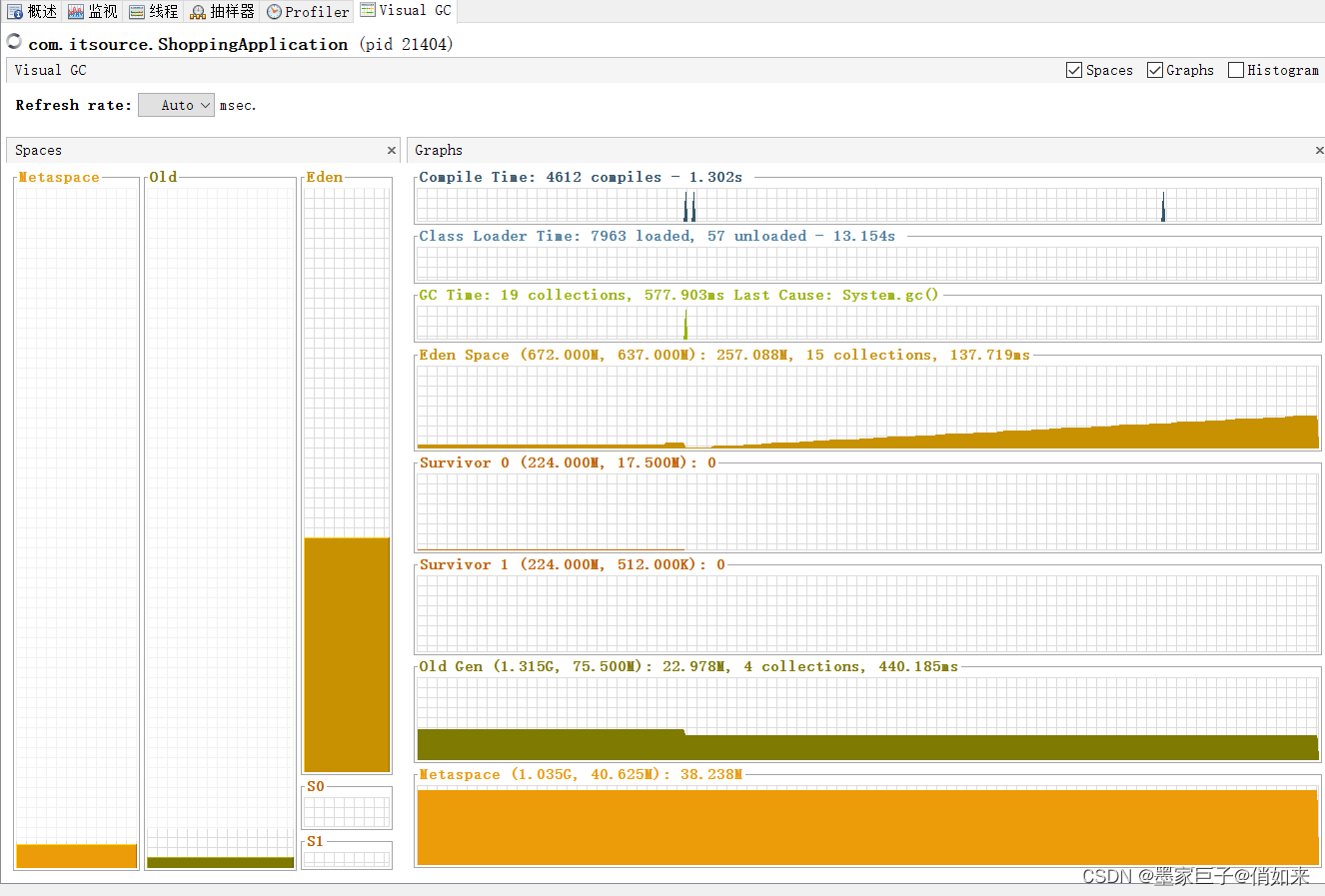
然后再 可用插件中 找到 Visual GC ,安装完成后我们将当前监控页关掉,再次打开,就可以看到Profiler后面多了一个Visual GC页。
3.定位OOM内存溢出
内存溢出一般出现内存满了,但是GC之后依然无法给新的对象分配内存的情况下,出现这种情况要么是内存大小分配不合理,要么是算法问题导致大批量对象或者大对象的创建,然后这些对象生命周期又比较长,导致一直GC不掉把内存沾满。下面我们模拟一个堆内存异常OOM的场景
public class JVMOOM {
byte[] bs = new byte[10*1024*1024];
public static void main(String[] args){
List<Object> list = new ArrayList();
int i = 0 ;
while (true){
System.out.println(i++);
list.add(new JVMOOM());
}
}
}
执行一会儿就会出现OOM异常
Exception in thread “main” java.lang.OutOfMemoryError: Java heap space
at org.example.JVMOOM.main(JVMOOM.java:11)
针对这个问题JVM提供了一个参数可以在OOM时把堆快照Dump下来,需要做如下JVM配置
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:/dump.hprof
拿到 hprof 快照文件后就可以对dump文件进行分析了。找到Jvisualvm的文件菜单 - 装入 - 找到刚才dump下来的快照文件 - 文件类型要选择 hprof
进去之后我们可以看到OOM的快照代码
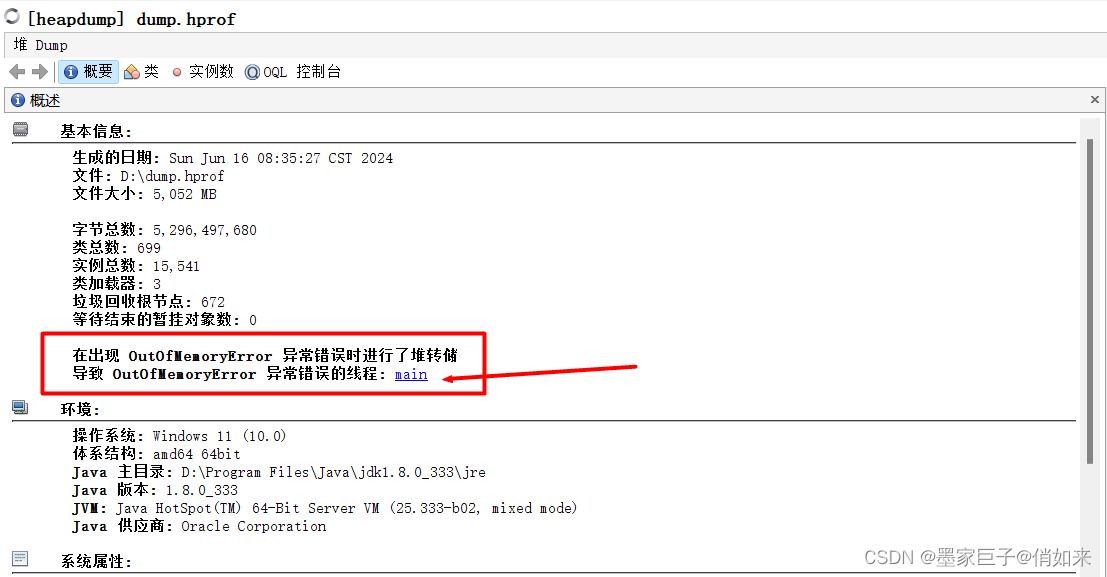
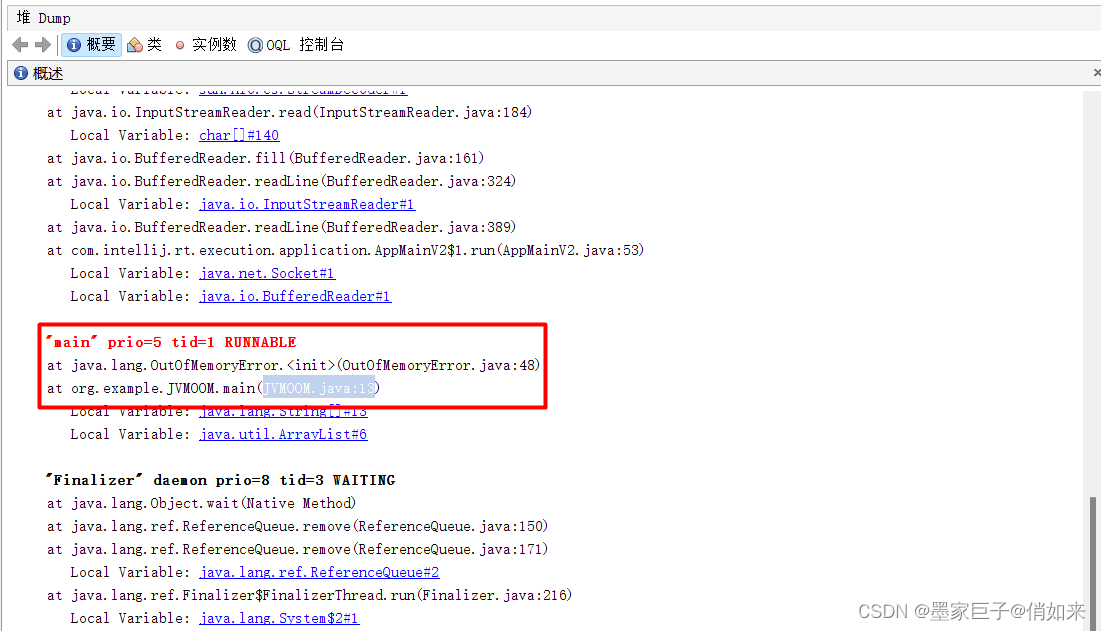
意思是在main线程出现了OOM问题,点击进去可以快速定位到出现问题的代码,定位到代码后就可以针对性排查问题了
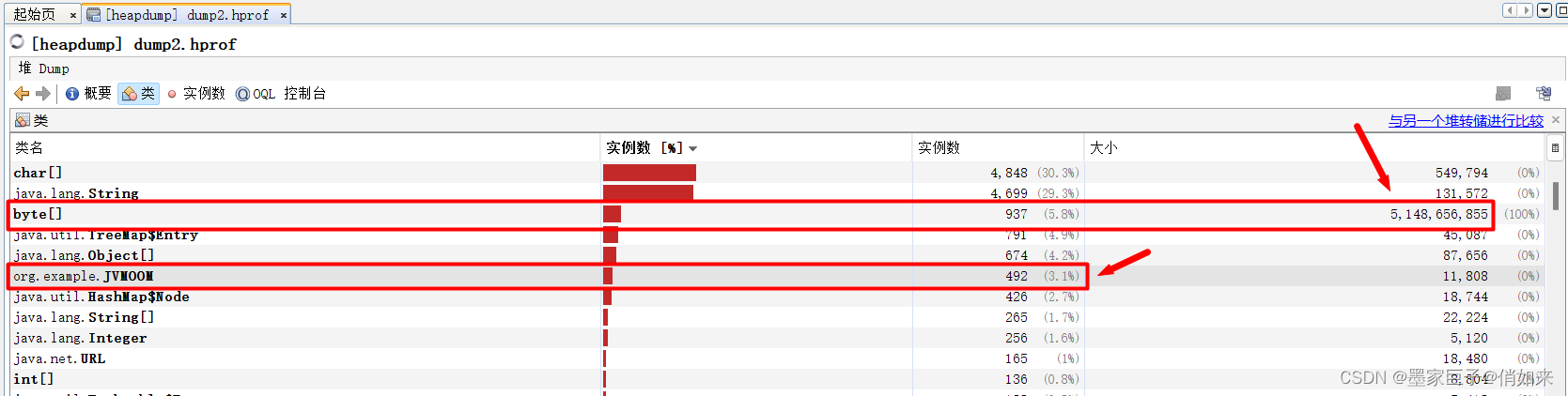
另外我们可以在 类 那一栏看到各个实例的数量和大小,快速定位到有问题的实例,如下
三.案例实战
1.高并发JVM实战
现在我们来模拟一个高并发下单场景,在一台2核4G的机器上,我们按照每秒1000的QPS进行压测。我的JVM设置如下
-Xms2048M -Xmx2048M -Xss1M -XX:SurvivorRatio=8
- 堆大小:2G
- 栈大小:1M
- 新生代比例:8:1:1
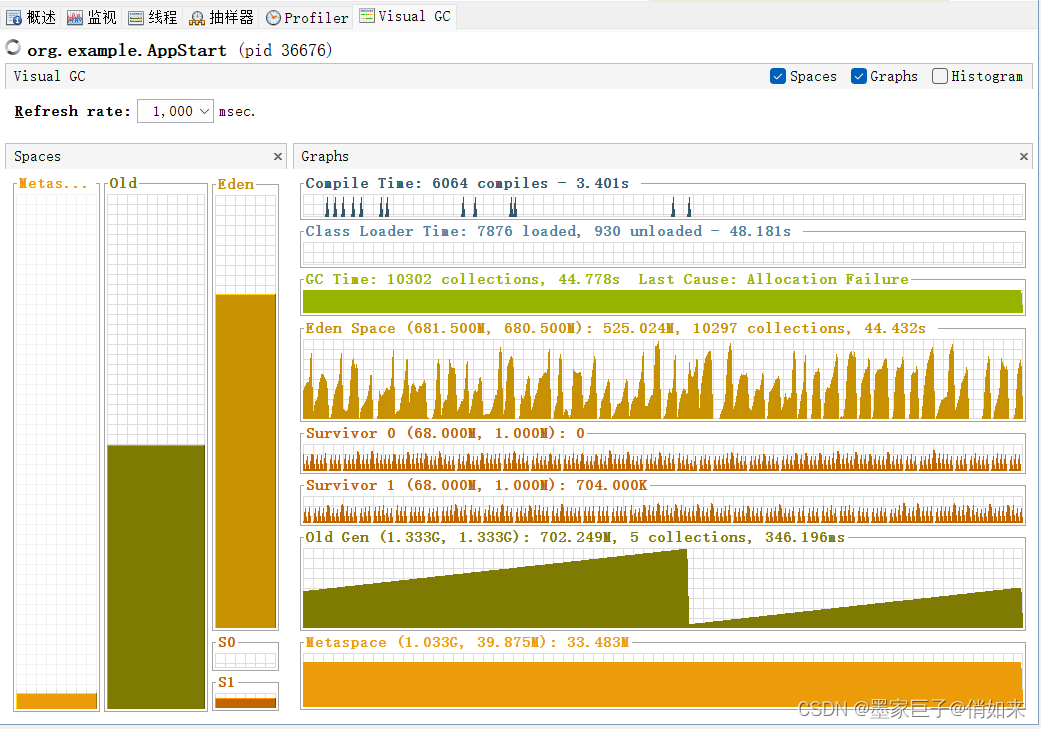
通过JvisualVM监控内存分配如下 :老年代:1.333G ,伊甸区:681M,幸存区:68M。
然后我们可以编写了一个简单的Web应用模拟下单请求,这里我创建了一个Order对象,模拟一个订单1KB,然后,一个下单接口会创建很多对象,如:订单,积分,优惠券等,那么我们放大20倍,那就是20KB,同时还会有其他业务执行也在消耗内存再放大10倍,那就是200KB。
@PostMapping("/order/create")
public String createOrder() {
Order order = null;
//放大20 * 10 倍
for (int i = 0 ; i< 200 ; i++){
//1个Order 1KB
order = new Order();
}
try {
//模拟业务耗时
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "success";
}
这个时候如果产生高并发,日活1亿,日均50W单峰值的时候,平均每秒1000单,假如3台机器工作,每台机器能处理:333单/s ,那么每台机器平均每秒在堆中会产生: 333 * 200KB = 66600KB 也就是接近 66M。
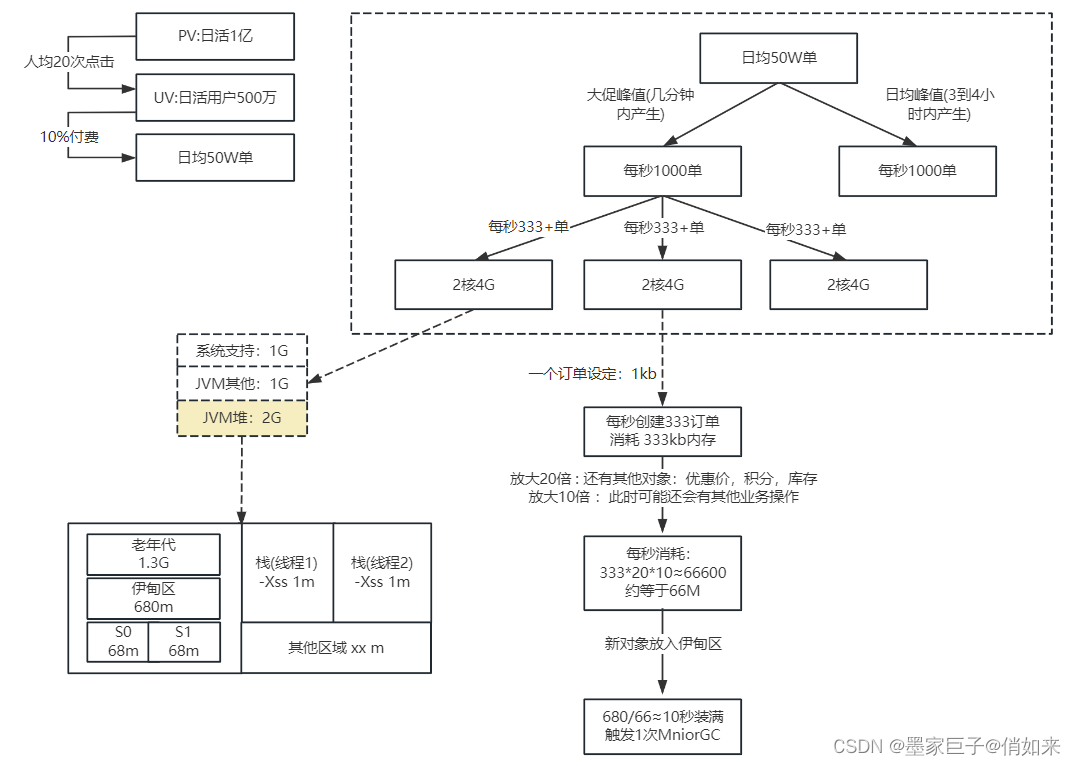
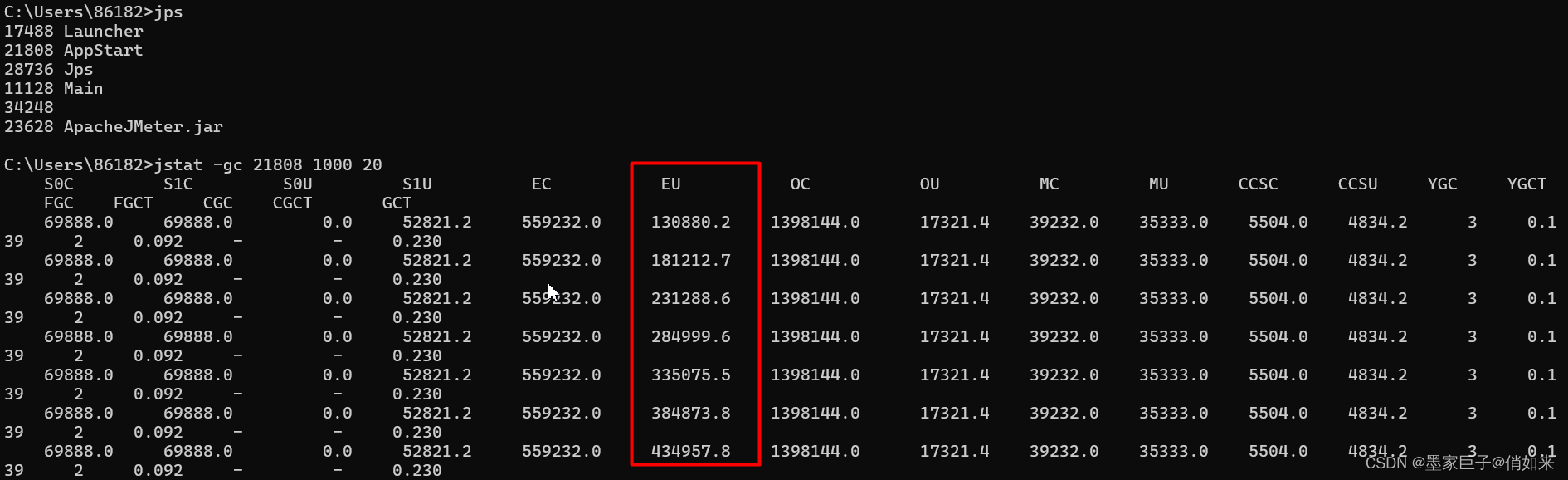
按照这样的预测QPS来进行推测,那么在300+/s的QPS下,每10S就会把堆装满然后触发MniorGC,通过Jemeter压测效果差不多,我们可以通过 jstat -gc pid 1000 20来查看每秒伊甸区会产生多少M的对象 ,差不多50-70M的样子
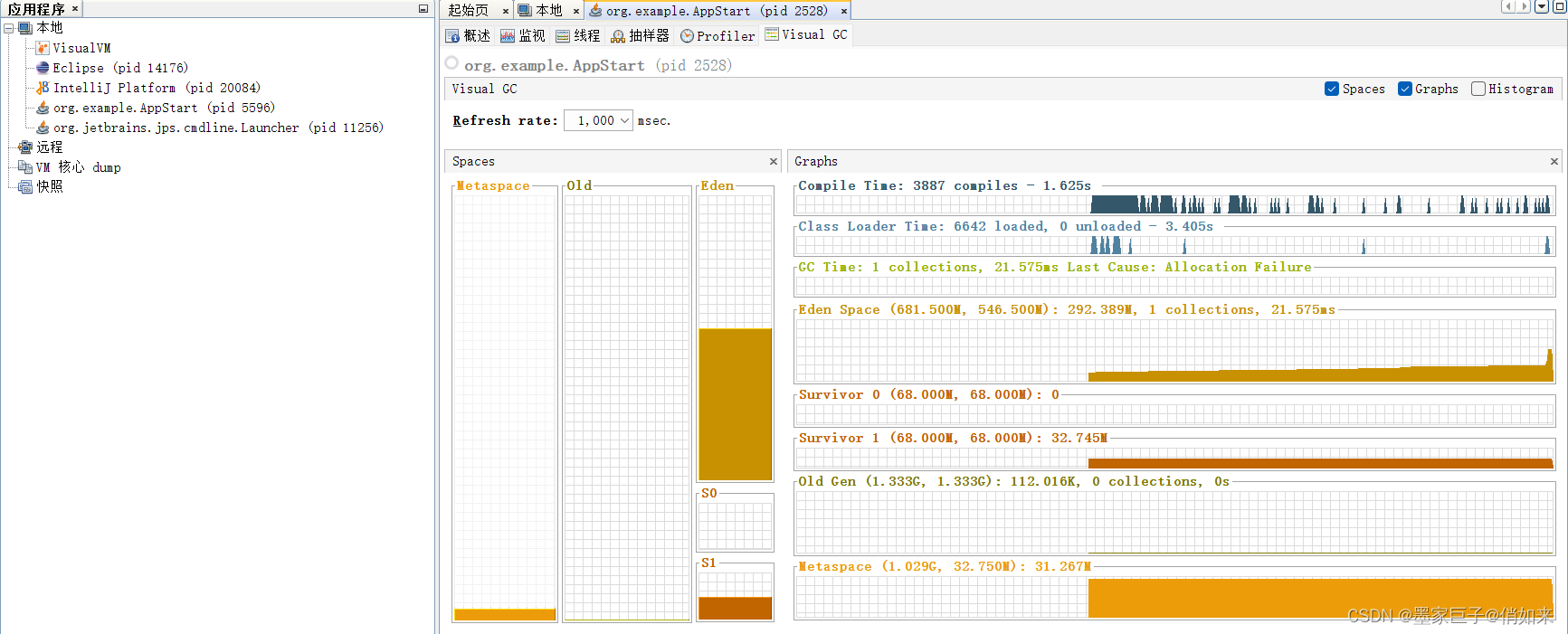
也可以通过JvisualVM可视化来查看
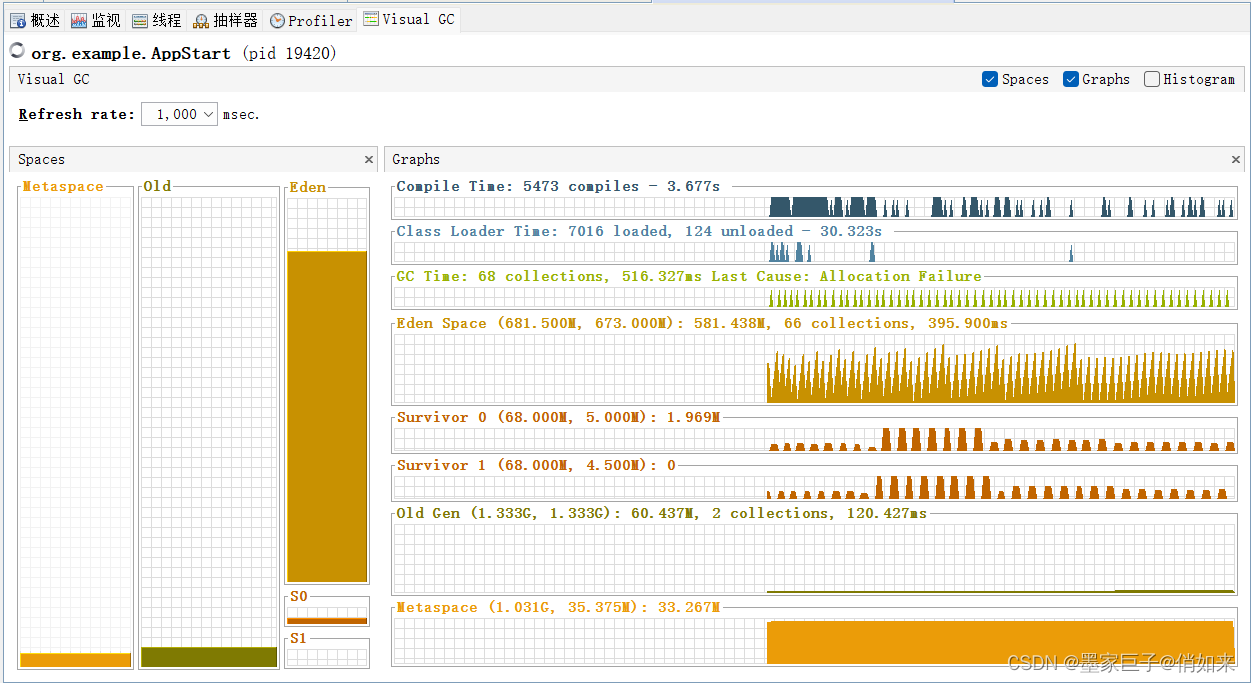
这样的配置有什么问题呢,我们可以分析一下
- 平均10S伊甸园被装满,触发MinorGC,存活的对象会进入幸存区
- 最坏的情况,在垃圾回收的时候,一批对象(66M)还没成为垃圾,那么由于幸存区只有68M,超过了S幸存区的50%,那么会导致这批对象直接进入老年代(动态年龄判断机制)
- 也就是说最坏的情况,每隔 10S就会移动66M到老年代,而老年代只有1.3G:这样算下来可能可能每4分钟左右老联代就会被装满,然后触发full GC,太过于频繁
这个因为之前已经大概知道Young GC的频率,假设是每5分钟一次,那么可以执行命令 jstat -gc pid 1000 10 ,观察每次结果eden,survivor和老年代使用的变化情况,在每次gc后eden区使用一般会大幅减少,survivor和老年代都有可能增长,这些增长的对象就是每次Young GC后存活的对象,同时还可以看出每次Young GC后进去老年代大概多少对象,从而可以推算出老年代对象增长速率。
上面整个过程只是理论情况,实际情况还需要通过JVM监视工具具体监控具体分析,能掌握到优化思路即可
2.JVM调优实战
而优化JVM就是要减少Full GC,因为他太耗时了,那么如何才能减少Full GC呢,根据上面的案例可以给出一个优化思路:其实简单来说就是尽量让每次Young GC后的存活对象小于Survivor区域的50%,都留存在年轻代里。尽量别让对象进入老年代。尽量减少Full GC的频率,避免频繁Full GC对JVM性能的影响。要减少Full GC 那么就要尽可能的减少对象进入老年代,在伊甸区或者幸存区就完成回收。那么我们可以选择调大幸存区,
- 减少对象由幸存区进入老年代的GC次数(默认15次),比如:修改为5次GC后未被回收的对象就进入老年代,这样可能把幸存区的内存释放出来,减少触发动态年龄判断机制
- 对于大对象直接进入老年代(参数-XX:PretenureSizeThreshold) 可以根据业务情况设置,比如:1m,一般很少有大于1M的对象。不恰当地设置PretenureSizeThreshold可能会导致老年代过早地填满,从而触发更频繁的Full GC,这可能会影响应用程序的性能。因此,在调整这个参数时,最好根据你的应用程序的特性和需求进行仔细的测试和调优。
- 对于JDK8默认的垃圾回收器是-XX:+UseParallelGC(年轻代)和-XX:+UseParallelOldGC(老年代),如果内存较大(超过4个G,只是经验值),系统对停顿时间比较敏感,我们可以使用ParNew+CMS(-XX:+UseParNewGC -XX:+UseConcMarkSweepGC)
- 有条件的情况下:适当增加内存大小,对于上面的QPS来说
4G内存的机器还是比较勉强的,实际是不合理的,可以升级到8G内存
在无法调大整体内存的情况下,我们可以适当挪动一些内存到新生代,从而调大幸存区
- -Xmn1024M :调大新生代大小 ,这样的话幸存区区也相应的变大了
-Xms2048M -Xmx2048M -Xmn1024M -Xss1M -XX:SurvivorRatio=6
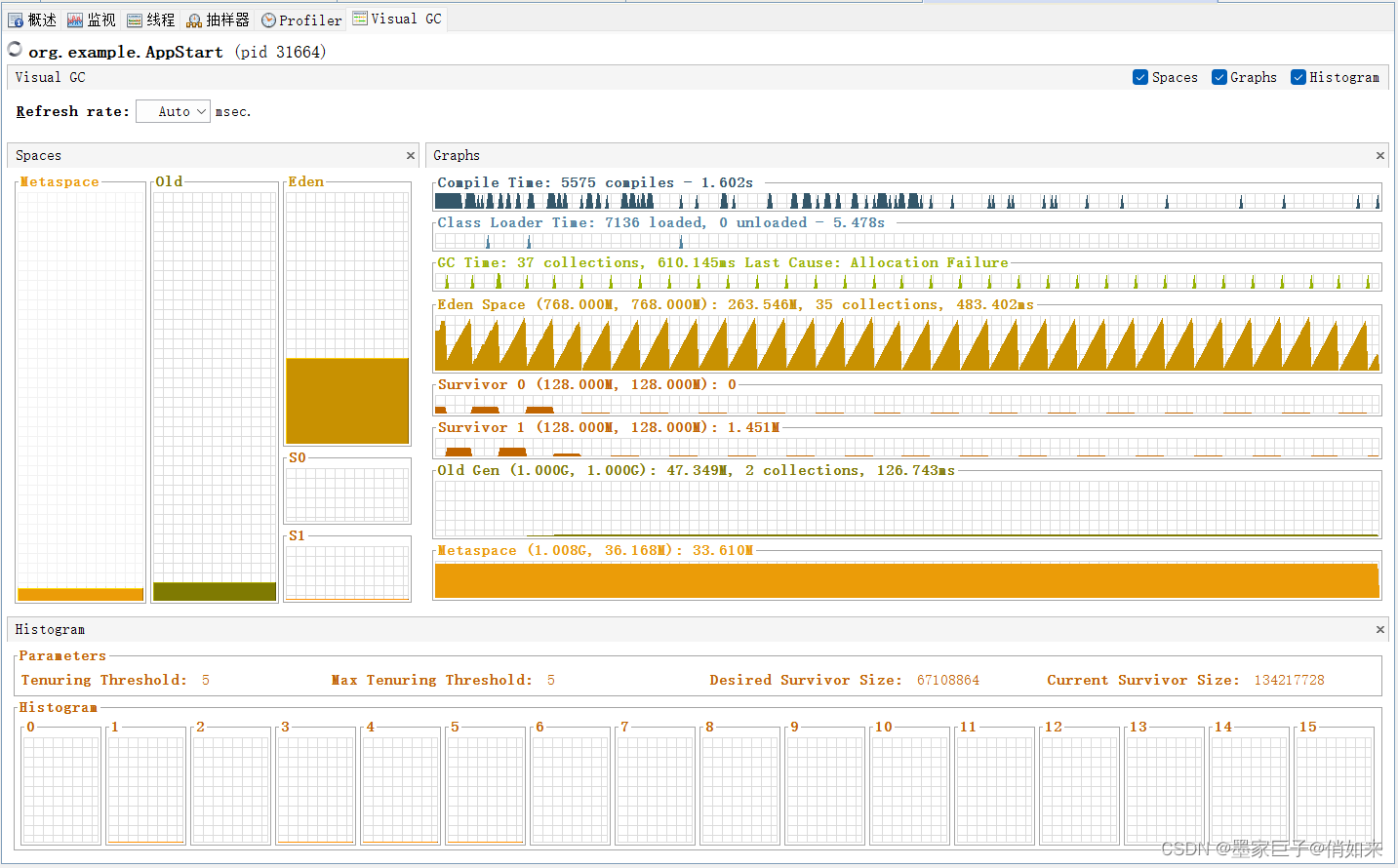
如果能够把内存调大的情况下,比如:8G,我们直接分配4到5G给内存,修改参数如下
- 把堆设置到3G到4G
- 新生代设置为2G,这样的话幸存区可以扩大到:200M以上。也可以通过:SurvivorRatio=6修改幸存区大小比例的方式,把伊甸区的内存分一点给幸存区,但是这个动作会加快MniorGC。
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:SurvivorRatio=8
这样的话一批对象60M,幸存区200M,那么不会轻易触发动态年龄判断机制,那么就不会出现大批量的对象进入老年代,然后设置一下分代年龄,以及使用CMS垃圾回收器
-XX:MaxTenuringThreshold=5
-XX:PretenureSizeThreshold=1M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=92
-Xms3072M
-Xmx3072M
-Xmn2048M
-Xss1M
-XX:SurvivorRatio=8
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=3
- MaxTenuringThreshold=5 : 新生代对象5次GC未被回收就进入老年代
- PretenureSizeThreshold=1M :对象大小超过1M直接进入老年代。这有助于减少新生代到老年代的晋升次数,从而提高性能
- UseParNewGC:使用ParNew垃圾收集器作为新生代的垃圾收集器
- UseConcMarkSweepGC :CMS是一个老年代的垃圾收集器,以最短用户线程停顿著称
- CMSInitiatingOccupancyFraction=92 :这个参数定义了老年代使用率达到多少时,CMS收集器开始运行。在这里,当老年代使用率达到92%时,CMS会开始执行
- UseCMSCompactAtFullCollection:在进行完整的CMS垃圾收集(即老年代满时)后,对老年代进行压缩。这有助于减少内存碎片。
- CMSFullGCsBeforeCompaction=3 :在进行多少次完整的CMS垃圾收集后,再执行一次压缩。在这里,数字是3,意味着在连续进行3次完整的CMS垃圾收集后,会执行一次压缩。
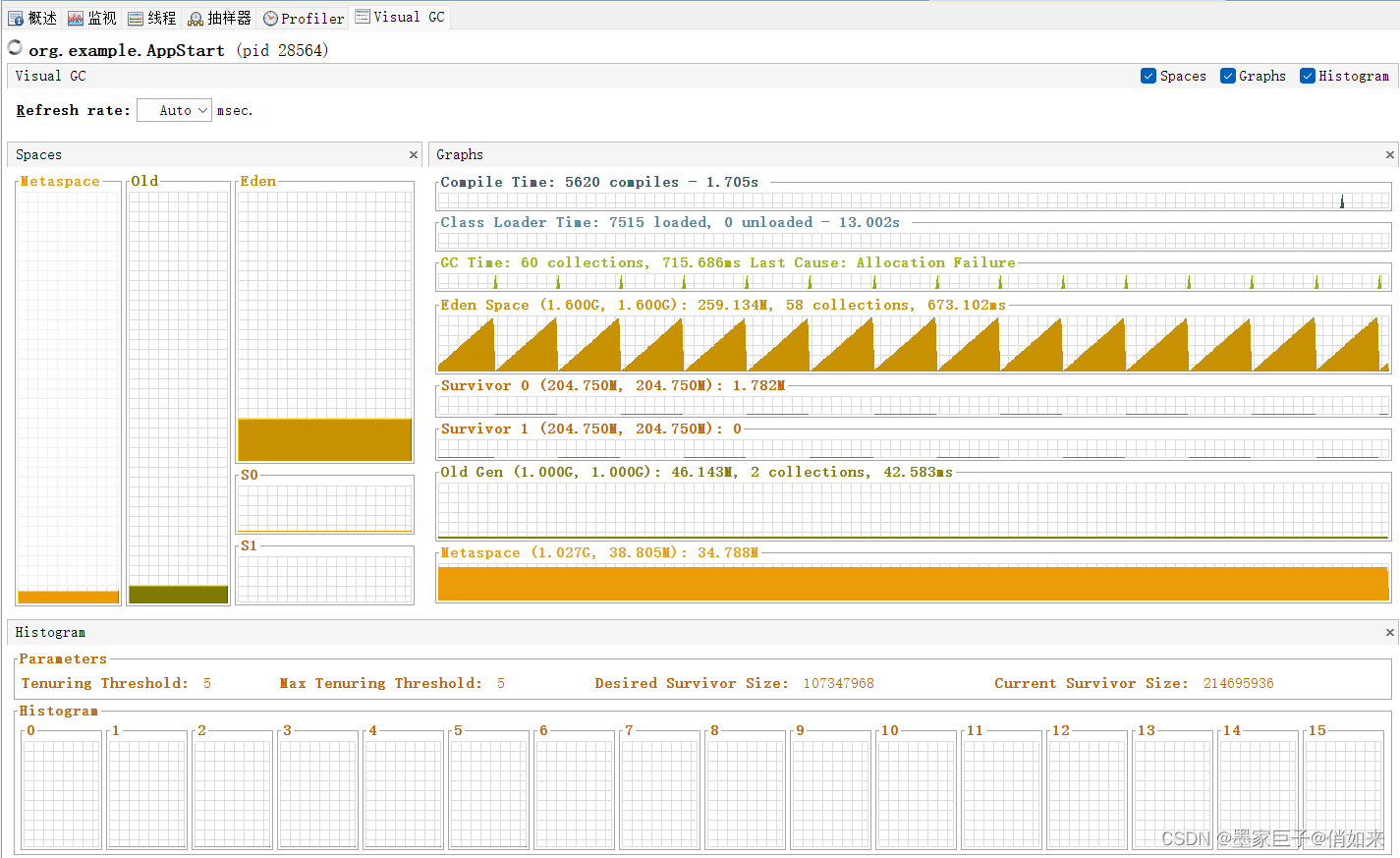
压测效果:Full GC次数大大减少跑了几个小时,1次Full GC都没有发生,因为增加了内存,MinorGC次数也减少了。
3.思路总结
JVM调优一个很大的原则就是避免频繁的Full GC,导致Full GC的情况有下面这几种
- 大量生命周期较长的对象进入了老年代导致老年代内存不够造成Full GC,这种情况比如:对象通过集合或者Map来装,而集合长时间不被销毁,如:缓存。这种情况需要控制缓存大小和缓存淘汰策略。
- 动态年龄判断,由于一批对象的大小超过幸存区50%,那么这批对象会提前进入老年代不一定会等到15次GC后才进入,这样会导致大批的对象进入老年代导致Full GC,这种情况需要适当调大幸存区大小,以及分代年龄,减少大批量对象因为动年龄判断从而进入老年代
- 如果系统一次性加载过多数据进内存,生成许多大对象,这些大对象在新生代空间不足时会直接转入老年代,从而导致Full GC的频繁触发。需要适当修改大对象的阈值
- 当系统承载高并发请求或处理数据量过大时,可能导致Young GC后存活对象过多,且Survivor区内存分配不合理或过小,从而导致对象频繁进入老年代,进而频繁触发Full GC。需要合理分配幸存区大小。或增加内存
- Metaspace(永久代)加载类过多:Metaspace用于存储类的元数据,如果加载的类过多,可能导致Metaspace空间不足,进而触发Full GC。需要扩大永久代大小
- 在某些情况下,代码中可能误调用了System.gc()方法,这会请求JVM执行Full GC,虽然JVM可能会忽略这个请求,但在某些情况下确实会触发Full GC。可以禁用掉该功能。
- 随着JVM的运行,堆内存中的对象会被创建和销毁,这可能导致内存碎片化。为了整理碎片化的内存,JVM可能会触发Full GC。可以适当把内存碎片化整理的时间间隔调大。
4.GC日志分析
对于java应用我们可以通过一些配置把程序运行过程中的gc日志全部打印出来,然后分析gc日志得到关键性指标,分析GC原因,调优JVM参数。打印GC日志方法,在JVM参数里增加参数,%t 代表时间
‐Xloggc:./gc‐%t.log ‐XX:+PrintGCDetails
‐XX:+PrintGCDateStamps
‐XX:+PrintGCTimeStamps
‐XX:+PrintGCCause
‐XX:+UseGCLogFileRotation
‐XX:NumberOfGCLogFiles=10
‐XX:GCLogFileSize=100M
-
-Xloggc:./gc-%t.log : 这个参数用于指定GC日志文件的路径和名称。其中%t是一个占位符,代表当前时间(通常是JVM启动的时间),这样每次JVM启动时都会生成一个带有时间戳的新日志文件。
-
-XX:+PrintGCDetails: 这个参数用于在GC日志中打印详细的GC活动信息。包括每次GC前后的堆内存使用情况、各个内存区域(如新生代、老年代、永久代/元空间)的详细使用情况等。
-
-XX:+PrintGCDateStamps:在GC日志的每一行前面打印日期和时间戳。这样你可以更准确地知道GC活动发生的时间。
-
-XX:+PrintGCTimeStamps:在GC日志的每一行前面打印GC事件的时间戳(从JVM启动到GC事件开始的时间)。这可以帮助你分析GC事件的频率和持续时间。
-
-XX:+PrintGCCause:在GC日志中打印触发GC的原因。例如,可能是“System.gc()”调用、内存分配失败、元空间不足等。
-
-XX:+UseGCLogFileRotation:启用GC日志文件的轮换。当日志文件达到指定的大小时,JVM会自动开始写入一个新的日志文件,而不是覆盖旧的日志文件。
-
-XX:NumberOfGCLogFiles=10:指定保留的GC日志文件的最大数量。在这个例子中,最多保留10个日志文件。当第11个日志文件需要创建时,JVM会删除最旧的日志文件。
-
-XX:GCLogFileSize=100M:设置每个GC日志文件的大小限制为100MB。当日志文件达到这个大小限制时,JVM会开始写入一个新的日志文件。
加入JVM参数后,启动成功,打印的GC日志格式如下
Memory: 4k page, physical 24883448k(12036668k free), swap 33009912k(19403520k free)
CommandLine flags: -XX:-BytecodeVerificationLocal -XX:-BytecodeVerificationRemote -XX:GCLogFileSize=104857600 -XX:InitialHeapSize=209715200 -XX:InitialTenuringThreshold=5 -XX:+ManagementServer -XX:MaxHeapSize=209715200 -XX:MaxNewSize=104857600 -XX:MaxTenuringThreshold=5 -XX:NewSize=104857600 -XX:NumberOfGCLogFiles=10 -XX:PretenureSizeThreshold=1048576 -XX:+PrintGC -XX:+PrintGCCause -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=6 -XX:ThreadStackSize=1024 -XX:TieredStopAtLevel=1 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseGCLogFileRotation -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
2024-06-19T08:39:45.449+0800: 1.032: [GC (Allocation Failure) [PSYoungGen: 76800K->8865K(89600K)] 76800K->8881K(192000K), 0.0085676 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
2024-06-19T08:39:45.632+0800: 1.214: [GC (Metadata GC Threshold) [PSYoungGen: 55908K->10208K(89600K)] 55924K->10232K(192000K), 0.0083475 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
2024-06-19T08:39:45.641+0800: 1.223: [Full GC (Metadata GC Threshold) [PSYoungGen: 10208K->0K(89600K)] [ParOldGen: 24K->9569K(102400K)] 10232K->9569K(192000K), [Metaspace: 20666K->20666K(1067008K)], 0.0207821 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
2024-06-19T08:39:46.101+0800: 1.683: [GC (Allocation Failure) [PSYoungGen: 76800K->7552K(89600K)] 86369K->17193K(192000K), 0.0038638 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2024-06-19T08:39:46.458+0800: 2.041: [GC (Allocation Failure) [PSYoungGen: 84352K->12779K(89600K)] 93993K->23087K(192000K), 0.0058587 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
2024-06-19T08:39:46.810+0800: 2.393: [GC (Allocation Failure) [PSYoungGen: 89579K->12788K(89600K)] 99887K->28794K(192000K), 0.0125838 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
2024-06-19T08:39:46.842+0800: 2.424: [GC (Allocation Failure) [PSYoungGen: 82034K->12794K(89600K)] 98040K->78259K(192000K), 0.0606478 secs] [Times: user=0.41 sys=0.00, real=0.06 secs]
2024-06-19T08:39:46.922+0800: 2.504: [GC (Allocation Failure) --[PSYoungGen: 89594K->89594K(89600K)] 155059K->191994K(192000K), 0.1499811 secs] [Times: user=0.98 sys=0.02, real=0.15 secs]
2024-06-19T08:39:47.072+0800: 2.654: [Full GC (Ergonomics) [PSYoungGen: 89594K->17756K(89600K)] [ParOldGen: 102400K->102040K(102400K)] 191994K->119796K(192000K), [Metaspace: 32521K->32521K(1079296K)], 2.6382554 secs] [Times: user=18.56 sys=0.02, real=2.64 secs]
2024-06-19T08:39:49.735+0800: 5.318: [Full GC (Ergonomics) [PSYoungGen: 76800K->50969K(89600K)] [ParOldGen: 102040K->102033K(102400K)] 178840K->153002K(192000K), [Metaspace: 32543K->32543K(1079296K)], 2.8759363 secs] [Times: user=23.52 sys=0.11, real=2.88 secs]
...
2024-06-19T08:39:45.449+0800: 1.032: [GC (Allocation Failure) [PSYoungGen: 76800K->8865K(89600K)] 76800K->8881K(192000K), 0.0085676 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] :
出现 :[GC (Allocation Failure) 代表是新生代的GC,[Full GC (Ergonomics) :是老年代的GC, [Full GC (Metadata GC Threshold) :元空间出发的GC , 从左到右分别代表
- 2024-06-19T08:39:45.449+0800:能够打印这个时间是因为设置了‐XX:+PrintGCDateStamps参数。打印日志输出的时间
- 1.032 : 从jvm启动直到垃圾收集发生所经历的时间。这个时间是因为设置了‐XX:+PrintGCTimeStamps参数
- (Allocation Failure):触发GC的原因是,给Young Gen内存分配失败导致的
- [PSYoungGen: 76800K->8865K(89600K)] 提供了新生代空间的信息,PSYoungGen,表示新生代使用的是多线程垃圾收集器Parallel Scavenge。然后是新生代收集前的空间占用 -> 收集后的空间占用(总大小)
- 76800K->8881K(192000K) ,0.0085676 secs:表示整个堆收集前和收集后的占用大小,以及堆的总大小 ,以及垃圾收集过程所消耗的时间
- [Times: user=0.02 sys=0.00, real=0.01 secs] :CPU使用情况,分别代表:user是用户模式垃圾收集消耗的cpu时间,sys是消耗系统态cpu时间 ,real:是指垃圾收集器消耗的实际时间
通过GC日志我们能够直观的分析出哪种GC比较多,比如 Full GC (Metadata GC Threshold) 比较多,那么就是元空间不够导致Full GC了,需要扩大元空间。 Full GC (Ergonomics) :比较多那就是频繁的Full GC,需要按照上面说的思路去排查了。
如果GC日志很多很多看起来会比较费劲不直观,我们可以借助一些功能来帮助我们分析,这里推荐一个gceasy(https://gceasy.io),可以上传gc文件,然后他会利用可视化的界面来展现GC情况。
文章就写到这把,如果对你有所帮助请给个好评