创建网络
- 首先通过命令创建一个网络
docker network create es-net
- 然后查看网络
[root@Docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
4e315f5e3ae7 bridge bridge local
a501a9f3b4ee es-net bridge local
ebca66b02e8c host host local
d411c33133f8 none null local
安装包
挂载es镜像
docker load -i es.tar
查看容器是否挂载成功
[root@Docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
rabbitmq 3.13-management d267434c554e 3 months ago 251MB
hello-world latest d2c94e258dcb 13 months ago 13.3kB
seataio/seata-server 1.5.2 f6a5368b6720 23 months ago 186MB
nacos/nacos-server v2.1.0-slim 49addbd025a1 2 years ago 322MB
mysql latest 3218b38490ce 2 years ago 516MB
kibana 7.12.1 cf1c9961eeb6 3 years ago 1.06GB
elasticsearch 7.12.1 41dc8ea0f139 3 years ago 851MB
运行es容器
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
- 查看是否安装完成

挂载kibana镜像
docker load -i kibana.tar
查看镜像是否挂载成功
[root@Docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
rabbitmq 3.13-management d267434c554e 3 months ago 251MB
hello-world latest d2c94e258dcb 13 months ago 13.3kB
seataio/seata-server 1.5.2 f6a5368b6720 23 months ago 186MB
nacos/nacos-server v2.1.0-slim 49addbd025a1 2 years ago 322MB
mysql latest 3218b38490ce 2 years ago 516MB
kibana 7.12.1 cf1c9961eeb6 3 years ago 1.06GB
elasticsearch 7.12.1 41dc8ea0f139 3 years ago 851MB
运行kibana容器
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
安装完成后,直接访问5601端口,即可看到控制台页面:
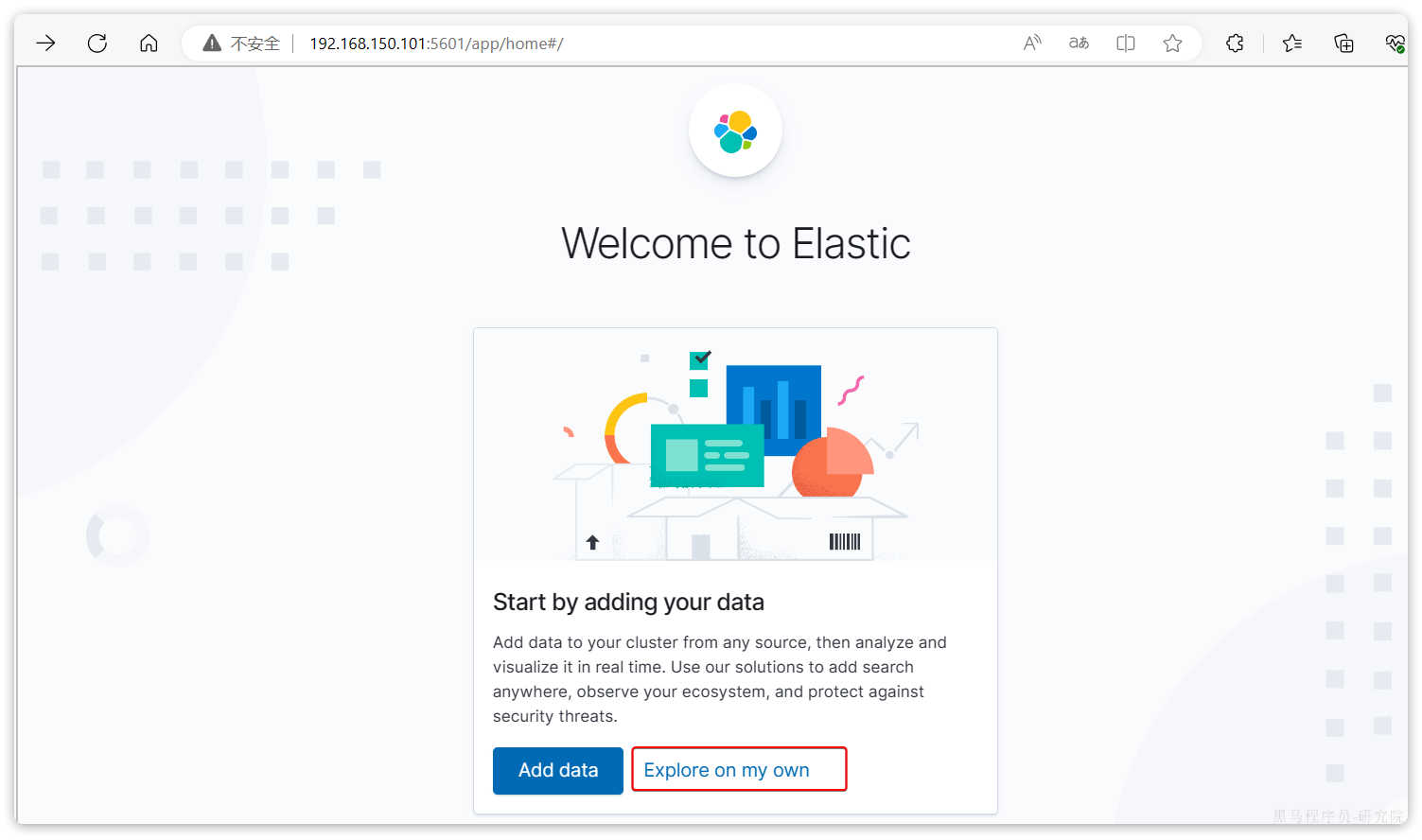
选择Explore on my own之后,进入主页面:
然后选中Dev tools,进入开发工具页面:
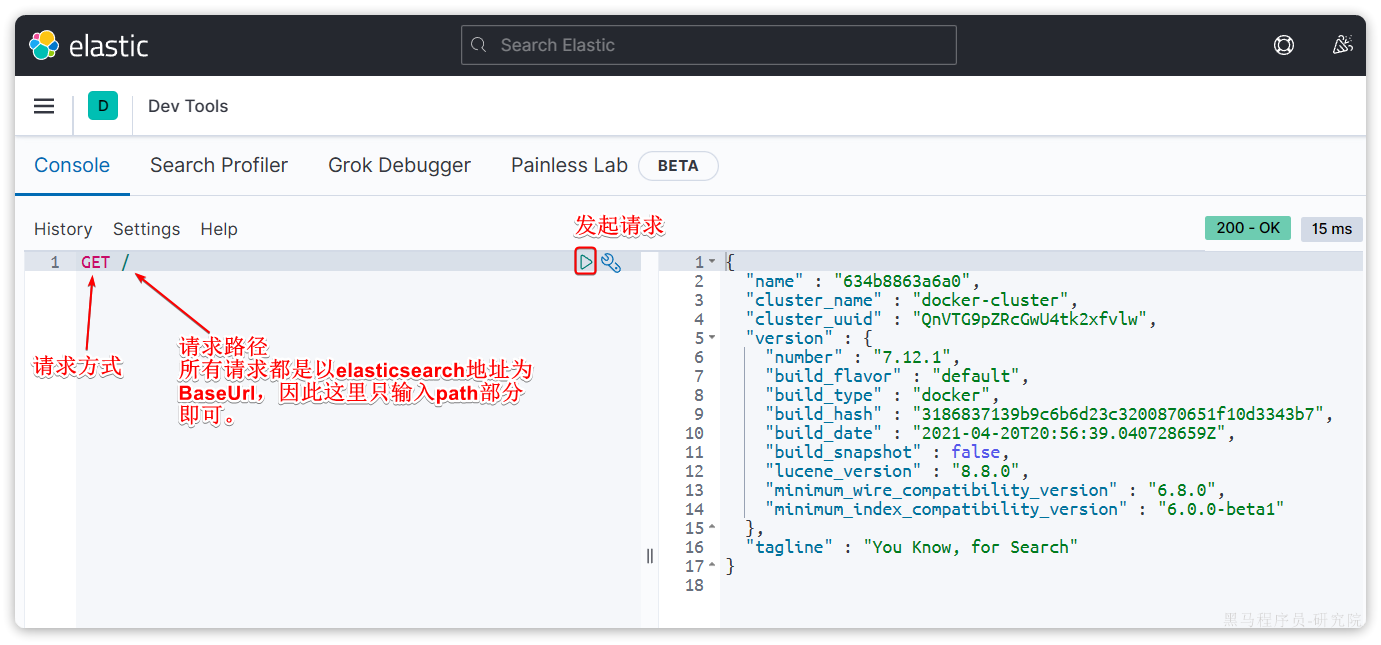
安装ik分词器
- 在线安装
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
然后重启es容器:
docker restart es
- 离线安装
查看之前安装的Elasticsearch容器的plugins数据卷目录:
[root@Docker ~]# docker volume inspect es-plugins
[
{
"CreatedAt": "2024-06-18T19:26:45+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
[root@Docker ~]#
可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
最后,重启es容器:
docker restart es
基本概念
- 文档和字段
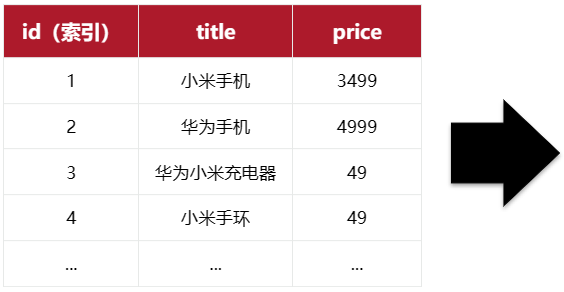
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "华为小米充电器",
"price": 49
}
{
"id": 4,
"title": "小米手环",
"price": 299
}
因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
- 索引和映射
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等:

所有文档都散乱存放显然非常混乱,也不方便管理。因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:
商品索引
{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "三星手机",
"price": 3999
}
用户索引
{
"id": 101,
"name": "张三",
"age": 21
}
{
"id": 102,
"name": "李四",
"age": 24
}
{
"id": 103,
"name": "麻子",
"age": 18
}
订单索引
{
"id": 10,
"userId": 101,
"goodsId": 1,
"totalFee": 294
}
{
"id": 11,
"userId": 102,
"goodsId": 2,
"totalFee": 328
}
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束
- mysql与elasticsearch
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
- 使用IK分词器
IK分词器包含两种模式:- ik_smart:智能语义切分
- ik_max_word:最细粒度切分
- 标准分词器:
POST /_analyze
{
"analyzer": "standard",
"text": "Elasticsearch官方提供的标准分词器"
}
- 结果如下:
{
"tokens" : [
{
"token" : "elasticsearch",
"start_offset" : 0,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "官",
"start_offset" : 13,
"end_offset" : 14,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "方",
"start_offset" : 14,
"end_offset" : 15,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "提",
"start_offset" : 15,
"end_offset" : 16,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "供",
"start_offset" : 16,
"end_offset" : 17,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "的",
"start_offset" : 17,
"end_offset" : 18,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "标",
"start_offset" : 18,
"end_offset" : 19,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "准",
"start_offset" : 19,
"end_offset" : 20,
"type" : "<IDEOGRAPHIC>",
"position" : 7
},
{
"token" : "分",
"start_offset" : 20,
"end_offset" : 21,
"type" : "<IDEOGRAPHIC>",
"position" : 8
},
{
"token" : "词",
"start_offset" : 21,
"end_offset" : 22,
"type" : "<IDEOGRAPHIC>",
"position" : 9
},
{
"token" : "器",
"start_offset" : 22,
"end_offset" : 23,
"type" : "<IDEOGRAPHIC>",
"position" : 10
}
]
}
- IK分词器:ik_smart
POST /_analyze
{
"analyzer": "ik_smart",
"text": "ik提供的标准分词器ik_smart模式"
}
- 结果如下:
{
"tokens" : [
{
"token" : "ik",
"start_offset" : 0,
"end_offset" : 2,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "提供",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "的",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "标准",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "分词器",
"start_offset" : 7,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "ik_smart",
"start_offset" : 10,
"end_offset" : 18,
"type" : "LETTER",
"position" : 5
},
{
"token" : "模式",
"start_offset" : 18,
"end_offset" : 20,
"type" : "CN_WORD",
"position" : 6
}
]
}
- IK分词器:ik_max_word
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "ik提供的标准分词器ik_max_word模式"
}
- 结果
{
"tokens" : [
{
"token" : "ik",
"start_offset" : 0,
"end_offset" : 2,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "提供",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "的",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "标准分",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "标准",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "分词器",
"start_offset" : 7,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "分词",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "器",
"start_offset" : 9,
"end_offset" : 10,
"type" : "CN_CHAR",
"position" : 7
},
{
"token" : "ik_max_word",
"start_offset" : 10,
"end_offset" : 21,
"type" : "LETTER",
"position" : 8
},
{
"token" : "ik",
"start_offset" : 10,
"end_offset" : 12,
"type" : "ENGLISH",
"position" : 9
},
{
"token" : "max",
"start_offset" : 13,
"end_offset" : 16,
"type" : "ENGLISH",
"position" : 10
},
{
"token" : "word",
"start_offset" : 17,
"end_offset" : 21,
"type" : "ENGLISH",
"position" : 11
},
{
"token" : "模式",
"start_offset" : 21,
"end_offset" : 23,
"type" : "CN_WORD",
"position" : 12
}
]
}
分词器的作用是什么?
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
索引库操作
- Index就类似数据库表,Mapping映射就类似表的结构。我们要向es中存储数据,必须先创建Index和Mapping
- Mapping映射属性
- Mapping是对索引库中文档的约束,常见的Mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}
对应的每个字段映射(Mapping):
| 字段名 | | 字段类型 | 类型说明 | 是否
参与搜索 | 是否
参与分词 | 分词器 |
| — | — | — | — | — | — | — |
| age | | integer | 整数 | | | —— |
| weight | | float | 浮点数 | | | —— |
| isMarried | | boolean | 布尔 | | | —— |
| info | | text | 字符串,但需要分词 | | | IK |
| email | | keyword | 字符串,但是不分词 | | | —— |
| score | | float | 只看数组中元素类型 | | | —— |
| name | firstName | keyword | 字符串,但是不分词 | | | —— |
| | lastName | keyword | 字符串,但是不分词 | | | —— |
- 索引库的CRUD
- 创建索引库和映射
- 基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
- 基本语法:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
# PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "false"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
}
}
}
}
- 查询索引库
- 基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
- GET /索引库名
- 基本语法:
- 修改索引库
- 倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
- 虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
PUT /heima/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}
- 删除索引库
- 语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
DELETE /索引库名
- 文档操作
有了索引库,接下来就可以向索引库中添加数据了。
Elasticsearch中的数据其实就是JSON风格的文档。操作文档自然保护增、删、改、查等几种常见操作,我们分别来学习。
- 新增文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
}
POST /heima/_doc/1
{
"info": "程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
- 查询
GET /{索引库名称}/_doc/{id}
GET /heima/_doc/1
- 删除文档
DELETE /{索引库名}/_doc/id值
DELETE /heima/_doc/1
- 修改文档
- 修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 全量修改是覆盖原来的文档,其本质是两步操作:
- 根据指定的id删除文档
- 新增一个相同id的文档
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
- 局部修改:修改文档中的部分字段
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}
- 批处理
批处理采用POST请求,基本语法如下:
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
其中:
- index代表新增操作
- _index:指定索引库名
- _id指定要操作的文档id
- { "field1" : "value1" }:则是要新增的文档内容
- delete代表删除操作
- _index:指定索引库名
- _id指定要操作的文档id
- update代表更新操作
- _index:指定索引库名
- _id指定要操作的文档id
- { "doc" : {"field2" : "value2"} }:要更新的文档字段
批量新增:
POST /_bulk
{"index": {"_index":"heima", "_id": "3"}}
{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"heima", "_id": "4"}}
{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}
批量删除:
POST /_bulk
{"delete":{"_index":"heima", "_id": "3"}}
{"delete":{"_index":"heima", "_id": "4"}}
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 局部修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}