文章目录
- Spark RDD 转换算子
- 一、Value 类型
- 1、map (映射)
- 2、 mapPartitions (map优化缓冲流)
- (1)函数说明
- (2) 代码示例
- (2)小案例获取每个分区的最大值
- 3、 map 和 mapParitions 的区别
- 4、 mapParitionsWithIndex
- (1) 小案例只获取第二个分区的最大值
- (2)小案例获取每一个数据的分区来源
- 5、 flatMap (映射扁平)
- (1) 函数说明
- (2) 小案例将List(List(1,2),3,List(4,5)) 进行扁平化操作
- 6、glom (分区数据转换数组)
- (1) 函数说明
- (2) 小案例计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
- (3) 理解分区不变的含义
- 7、groupBy (分组)
- (1) 函数说明
- (2) 小案例将List("Hello","hive","hbase","Hadoop")根据单词首写字母进行分组
- (3) 小案例从服务器日志数据apache.log中获取每个时间段的访问量
- 8、filter (过滤)
- (1) 函数说明
- (2) 小案例从服务器日志数据apache.log中获取2015年5月17日的请求路径
- 9、sample (抽取数据)
- (1) 函数说明
- (2) 代码示例
- 10、distinct (去重)
- (1) 函数说明
- (2) 代码示例
- 11、coalesce (缩减分区)
- (1) 函数说明
- (2) 代码示例
- (3) 可以扩大分区吗?
- 12、reparition (扩大分区)
- 13、sortBy (排序)
- (1) 函数说明
- (2) 代码示例
- 二、双Value类型
- 1、函数说明
- 2 、代码示例
- 三、Key - Value 类型
- 1、partitionBy (重新分区)
- (1) 函数说明
- (2) 代码示例
- 2、reduceByKey (聚合)
- 3、groupByKey (分组)
- (1) 函数说明
- (2) 代码示例
- 4、reduceByKey 和 groupByKey的区别
- 5、aggregateByKey (聚合计算)
- (1) 函数说明
- (2) 代码示例
- (3) 小案例获取相同key的数据的平均值 => (a,3),(b,4)
- 6、foldByKey (聚合计算)
- (1) 函数说明
- (2) 代码示例
- 7、combineByKey (聚合计算)
- 8、join (连接两个数据源相同key数据)
- (1) 函数说明
- (2) 代码示例
- 9、leftOuterJoin 和 rightOuterJoin
- (1) 函数说明
- (2) 代码示例
- 10、cogroup (分组 + 连接)
- (1) 函数说明
- (2) 代码示例
- 四、案例实操
- 1) 数据准备
- 2) 需求描述
- 3) 需求分析
- 4) 功能实现
Spark RDD 转换算子
RDD 方法也叫做RDD算子,主要分为两类,第一类是用来做转换的,例如flatMap(),Map()方法,第二类是行动的,例如:collenct()方法,只有触发了作业才会被执行。

一、Value 类型
RDD 根据数据处理方式的不同将算子整体上分为Value类型,双Value类型和Key-value类型。
1、map (映射)
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//RDD 算子转换类型
class Spark01_RDD_Transform {
}
object Spark01_RDD_Transform{
def main(args: Array[String]): Unit = {
//配置信息
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD_zhuanhuan")
val context = new SparkContext(conf)
//TODO 算子 => map
val rdd = context.makeRDD(List(1, 2, 3, 4)) //基于内存创建一个RDD
// def hanshu(num:Int):Int = {
// num * 2
// }
//
// val value1 = rdd.map(hanshu)
// value1.collect().foreach(println)
val value = rdd.map(a => a * 2)
println(value.collect().foreach(println))
context.stop()
}
}
map 算子的小测试:从服务器日志数据 apache.log中获取用户请求URL资源的路径
思路:文件最右边的那个是文件的路径。可以使用map方法,里面split(" ")方法用空格分隔开,然后再使用takeRight()方法,取最右边的第一个元素,那就是文件的地址了
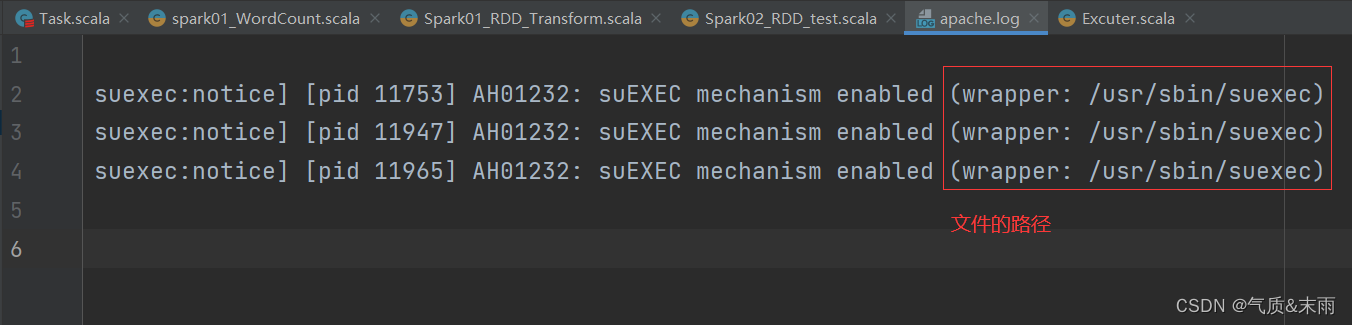
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//map 算子的小测试:从服务器日志数据 apache.log中获取用户请求URL资源的路径
class Spark02_RDD_test {
}
object Spark02_RDD_test{
def main(args: Array[String]): Unit = {
//配置信息
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD_zhuanhuan")
val context = new SparkContext(conf)
//TODO 算子 => map
val rdd = context.textFile("datas/apache.log")
//长的字符串
//短的字符串
val value = rdd.map(
a => a.split(" ").takeRight(1)//将文件按照空格隔开,然后拿最右边的那一个数据
)
value.collect().foreach(println)
context.stop()
}
}
map 分区数据执行顺序测试:
1、rdd的计算一个分区内的那么数据是一个一个执行逻辑
只有前面一个数据全部的逻辑执行完毕后,才会执行下一个数据
一个分区内的数据的执行是有序的,
2、不同分区数据计算是无序的
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//测试分区的执行的顺序
class Spark02_RDD_Transform_Par {
}
object Spark02_RDD_Transform_Par{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_Par")
val context = new SparkContext(conf)
//1、rdd的计算一个分区内的那么数据是一个一个执行逻辑
//只有前面一个数据全部的逻辑执行完毕后,才会执行下一个数据
//一个分区内的数据的执行是有序的,
//2、不同分区数据计算是无序的
val rdd = context.makeRDD(List(1,2,3,4),2)
val rddMap = rdd.map(num => {println("<<<"+num)}) //第一个map转换
val rddMap1 = rddMap.map(num=>{println("###"+num)}) //第二个map转换
//发现并行计算是没有顺序的
rddMap.collect().foreach(println) //第一个rddMap执行
rddMap1.collect().foreach(println) //第二个rddMap执行,然后查看他们输出的顺序
context.stop()
}
}
2、 mapPartitions (map优化缓冲流)
(1)函数说明
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是值可以进行任意的处理,哪怕是数据过滤。例如这里过滤掉等于2的数据。
val dataRDD1 = dataRDD.mapPartitions(
datas => {
datas.filter(_ == 2)
}
)
说明:
map 是一个一个执行的,类似于之前的字节流,所以效率肯定不高,所以需要一个像之前优化字节流的缓冲区那样的方法,所以有了mapParitions 方法,mapParitions 方法是将一个分区内的数据全部拿到之后,然后再进行map操作,那效率肯定就高得多。
注意:
mapPartitions:可以以分区为单位进行数据转换操作,但是会将整个分区的数据加载到内存中进行引用,如果处理完的数据是不会被释放掉,存在对象的引用,所以在内存比较小的情况下,数据量较大的情况下,容易出现内存溢出。
总结:两个方法的应用场景不同,如果内存足够那么mapPartitions方法肯定是效率更高的,但是mapPartitions方法存在对象引用,操作完之后内存不会被释放。要是内存小,数据量大的情况下那么最好使用map方法,因为是一条一条操作的,执行完之后内存就会被释放,没有对象引用,虽然效率会低一点,但是不会出错。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//map 是一个一个执行的,类似于之前的字节流,所以效率肯定不高
//所以需要一个像之前优化字节流的缓冲区那样的方法
//所以有了mapParitions 方法
class Spark02_RDD_Transform {
}
object Spark02_RDD_Transform{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_Par")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4), 2) //创建一个RDD
//TODO 算子 - mapPartitions
//mapPartitions:可以以分区为单位进行数据转换操作
//但是会将整个分区的数据加载到内存中进行引用
//如果处理完的数据是不会被释放掉,存在对象的引用
//所以在内存比较小的情况下,数据量较大的情况下,容易出现内存溢出。
//这个方法之所以高效,他是把一个分区内的数据全部拿到之后才开始做操作
//而不是一个一个的做操作
val mpRDD = rdd.mapPartitions(a => { //这这个方法执行底层是迭代器
println(">>>>>>>>>>")
a.map(_ * 2) //相当于先把一个分区内的数据聚合了,然后再进行map操作,这个效率就要高得多了
})
mpRDD.collect()foreach(println)
context.stop()
}
}
(2)小案例获取每个分区的最大值
首先创建RDD的时候,就设置好分区数。
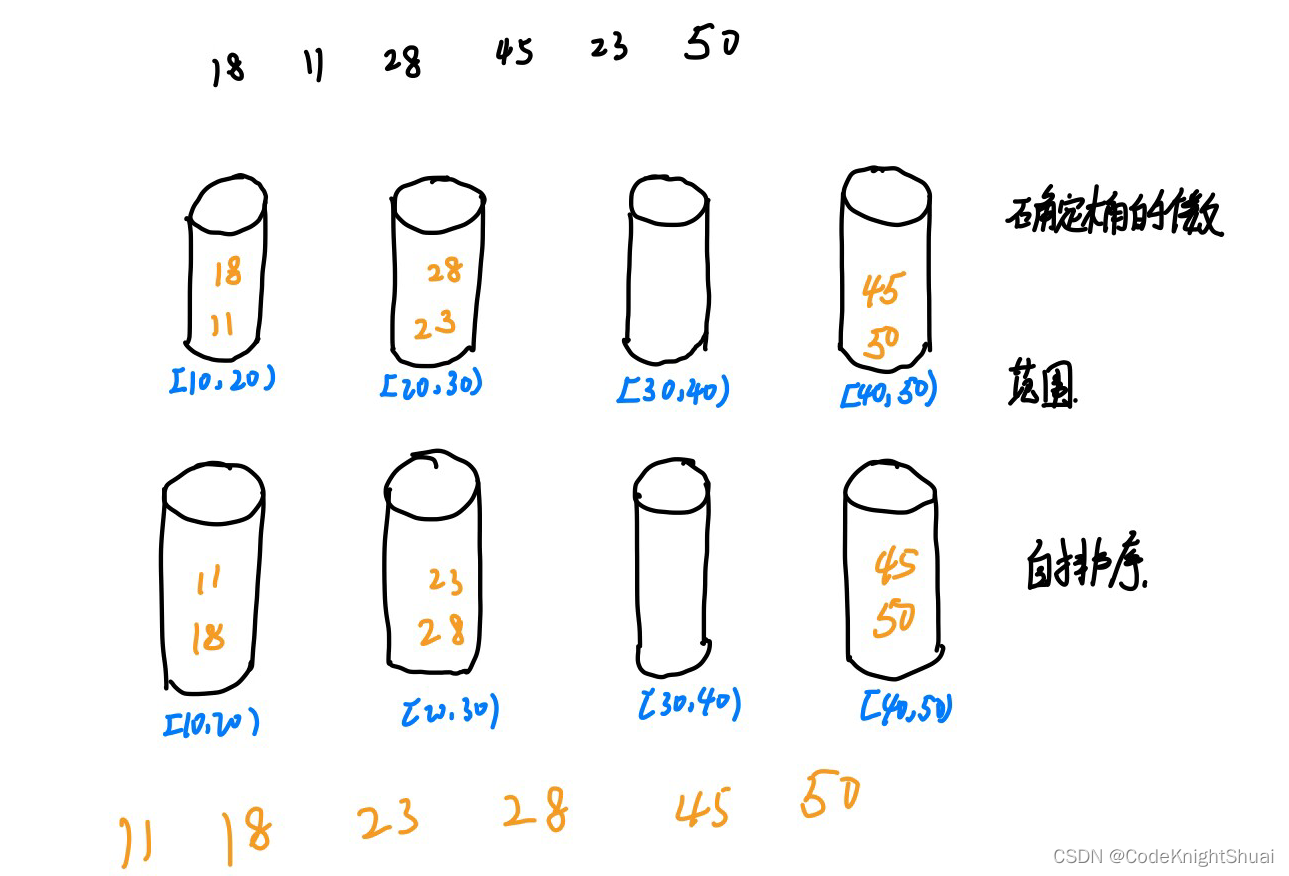
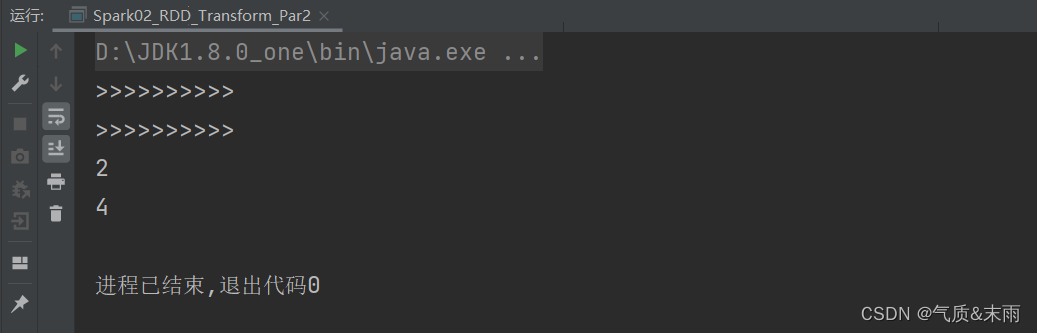
思路:因为mapPartitions方法是将待处理的数据以分区为单位发送到计算节点进行处理,所以我们可以直接用它直接按照每一个分区进行操作,然后直接max方法获取最大值。但是这里的难点在于,mapPartitions方法返回的是一个迭代器,而max方法返回的是一个Int类型的值,所以我们需要用List或者其他类型的集合都可以,给它包裹起来,然后用toIterator方法进行转换,例如List(a.max).toIterator。最后就可以得到每一个分区的最大值了,第一个分区1,2 第二个分区的数据3,4 所以最后输出的是2,4。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//案例:获取每个分区的最大值
class Spark02_RDD_Transform_Par2 {
}
object Spark02_RDD_Transform_Par2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_Par")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4), 2) //创建一个RDD
//TODO 算子 - mapPartitions
val mpRDD = rdd.mapPartitions(a => { //这这个方法执行底层是迭代器
println(">>>>>>>>>>")
List(a.max).toIterator //因为mapPartitions方法返回的是一个迭代器,a.max得到的是一个Int的数值
}) //所以我们的用列表,或者其他的集合都可以把他包起来,然后toIterator将它转换为迭代器就可以了
mpRDD.collect().foreach(println) //得到的结果应该是2和4,第一个分区1,2 第二个分区2,4
context.stop()
}
}
3、 map 和 mapParitions 的区别
数据处理角度:
Map 算子是分区内一个数据一个数的执行,类似于串行操作。而mapParitions算子是已分区为单位进行批处理操作。
功能的角度:
Map 算子主要目的是将数据源中的数据进行转换和改变。但是不会减少或增多数据。mapParitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据。
性能的角度:
Map 算子因为类似于串行操作,所以性能比较低,mapParitions 算子类似于批处理,所以性能较高。但是mapParitions 算子会长时间占用内容,那么这样会导致内存可能不够用,出现内存溢出的错误,所以在内存有限的情况下,不推荐使用,推荐使用map操作。
4、 mapParitionsWithIndex
函数说明:
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
(1) 小案例只获取第二个分区的最大值
就是跟mapParitions方法一样的,只是多了一个分区编号,可以指定操作哪一个分区。在某些时候非常有用,比如有两个分区,我只要第二个分区的最大值,第一个分区的数据不要。
思路:
里面第一个参数是分区的索引,第二个参数是迭代器也就是分区的所有数据。我们可以对分区进行判断,如果等于1说明就是第二个分区,我们直接返回那个迭代器,然后求的是第二个分区的最大值,我们再像刚刚一样用集合包起来,然后使用toIterator方法进行转换。然后如果不为1的话那么返回一个空的迭代器,Nil.iterator Nil 方法是空集合,空集合.迭代器,就是空迭代器。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//mapParitionsWithIndex 方法 比mapParitions多了一个分区编号
class Spark03_RDD_mapParitionsWithIndex {
}
object Spark03_RDD_mapParitionsWithIndex{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_Par")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4), 2) //创建一个RDD
//TODO 算子 - mapPartitionsWithIndex
//[1,2][3,4]
val mpRDD = rdd.mapPartitionsWithIndex(
(index,iter) => { //第一个参数是索引的编号,第二个参数是全部的数据,就是迭代器
if (index == 1){
List(iter.max).toIterator //因为我们只要第二个分区,第一个分区索引为0,第二个分区索引为1,如果1就直接返回迭代器
}else{
Nil.iterator //如果不是1,那么我们返回一个空的迭代器,Nil 空集合
}
}
)
mpRDD.collect().foreach(println)
context.stop()
}
}
(2)小案例获取每一个数据的分区来源
分为了4个分区
思路:
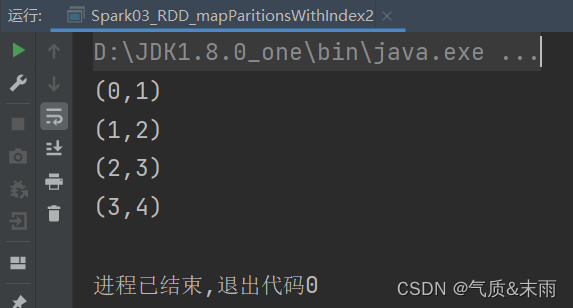
使用mapPartitionsWithIndex方法,第一个是索引第二个是迭代器,分区中的每一个数据,然后对迭代器进行map操作,映射,第一个参数是分区的索引,第二个参数是分区中的每个数据。就取出来了。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
获取每一个数据来自于哪一个分区
class Spark03_RDD_mapParitionsWithIndex2 {
}
object Spark03_RDD_mapParitionsWithIndex2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_Par")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4), 4) //创建一个RDD
//TODO 算子 - mapPartitionsWithIndex
//[1,2][3,4]
val mpRDD = rdd.mapPartitionsWithIndex(
(index,iter) => {
iter.map(
a => {
(index,a) //第一个是分区索引,第二个是每一个数据
}
)
}
)
mpRDD.collect().foreach(println)
context.stop()
}
}
5、 flatMap (映射扁平)
(1) 函数说明
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射。
(2) 小案例将List(List(1,2),3,List(4,5)) 进行扁平化操作
思路:
要是列表里面的数据类型都是一样的话,比如 List(List(1,2),List(4,5)),就是两个列表那么直接rdd.flatMap(a => a) 直接输出这个列表扁平化就完成了,非常简单,但是要是列表中不只是只有列表,比如List(List(1,2),3,List(4,5))里面有个3,他不是集合,数据类型不一样,这时候就要进行模式匹配了。首先匹配,如果是列表那么就直接输出列表,如果不是列表那么就List() 把它包裹起来,这不就变成列表了嘛,就可以对三个列表进行扁平化了。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class tset2 {
}
object tset2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//两个列表进行扁平化合并
val rdd:RDD[List[Int]] = context.makeRDD(List(List(1,2),List(4,5)))
val rddMap = rdd.flatMap(a => a)
rddMap.collect().foreach(println)
//单词进行扁平化,只有字符串类型的才有split(" ")方法
val rdd2 = context.makeRDD(List("Hello world", "Helllo Spark", "Hello Scala"))
val rddMap2 = rdd2.flatMap(_.split(" "))
rddMap2.collect().foreach(println)
println("===============")
val rdd3: RDD[Any] = context.makeRDD(List(List(1, 2), 3, List(4, 5)))
val rddFlatmap = rdd3.flatMap {
case list: List[_] => list //模式匹配。如果是集合类型的那么就返回这个集合
case list2 => List(list2) //如果不是集合的那么用集合把它包起来那不就是集合了嘛
}
rddFlatmap.collect().foreach(println)
context.stop()
}
}
6、glom (分区数据转换数组)
(1) 函数说明
将同一个分区的数直接转换为相同类型的内存数组进行处理,分区不变。
(2) 小案例计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
思路:
首先使用glom 方法,将同一个分区内的数据转换为数组,然后map方法里面array => array.max两个分区最大值获取出来,直接每个分区的最大值collect方法采集出来,然后sum方法求和。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.math.Ordering.ordered
// 小案例计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
class Spark04_RDD_glom2 {
}
object Spark04_RDD_glom2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
val rdd:RDD[Int] = context.makeRDD(List(1, 2, 3, 4),2)
val rddglom = rdd.glom() //将同一个分区的数组转换为数组处理,
val rddMap = rddglom.map(
array => { //然后输出按照分区,获取每一个分区的最大值
array.max
}
)
println(rddMap.collect().sum) //这里collect() 采集出来两个分区最大值,直接sum求和
context.stop()
}
}
(3) 理解分区不变的含义
7、groupBy (分组)
(1) 函数说明
将数据根据指定的规则进行分组,分区默认不变,但是数据会被打乱重新组合,我们将这样的组合称之为shuffle。极限情况下,数据可能被分在一个分区里面,一个组的数据在一个分区中,但是并不是说一个分区只有一个组。
注意:分区和分组没有必然的关系
val dataRDD = context.makeRDD(List(1,2,3,4),1)
val dataRDD1 = dataRDD.groupBy(_%2)
(2) 小案例将List(“Hello”,“hive”,“hbase”,“Hadoop”)根据单词首写字母进行分组
思路:直接对RDD中的单词使用groupBy(_charAt(0))方法进行分组,charAt(0)选择选择单词首字母
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//groupBy 算子:
/*
* 将数据根据指定的规则进行分组,分区默认不变,但是数据会被`打乱重新组合`,我们将这样的组合称之为`shuffle`。
* 极限情况下,数据可能被分在一个分区里面,`一个组的数据在一个分区中,但是并不是说一个分区只有一个组`。
* */
class Spark05_RDD_groupBy {
}
object Spark05_RDD_groupBy{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO RDD算子-groupBy
val rdd = context.makeRDD(List("Hello word","Hello Scala","Word","Scala","Spark"), 1)
val rddgroup = rdd.groupBy(_.charAt(0)) //按照字母的首字母进行排序,
val rdd2 = context.makeRDD(List(1,2,3,4),2)
def hanshu(num:Int):Int = { //这个是按照取余结果来分区的,都是为了显示写一块的
num % 2
}
val rddgroup2 = rdd2.groupBy(hanshu)
rddgroup.collect().foreach(println)
rddgroup2.collect().foreach(println)
context.stop()
}
}
(3) 小案例从服务器日志数据apache.log中获取每个时间段的访问量
8、filter (过滤)
(1) 函数说明
将函数根据指定的规则进行筛选过滤,符合条件的数据保留,不符合规则的数据丢弃。当数据进行筛选后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//filter 算子
class Spark06_RDD_filter {
}
object Spark06_RDD_filter{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO RDD算子-filetr
val rdd = context.makeRDD(List(1, 2, 3, 4, 5))
val rddfilter = rdd.filter(_%2!=0) //这是筛选只要奇数不要偶数
rddfilter.collect().foreach(println)
context.stop()
}
}
(2) 小案例从服务器日志数据apache.log中获取2015年5月17日的请求路径
思路:
首先textFile() 方法把文件给读取进来,然后在里面要进行筛选,首先使用split(" ")方法,用空格进行分割,然后直接用索引获取位置,然后startWith("10:39:24") 方法。里面是开始的位置。然后就筛选出来了。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//filter 小案例从服务器日志数据apache.log中获取2015年5月17日的请求路径
class Spark06_RDD_filter2 {
}
object Spark06_RDD_filter2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO RDD算子-filetr
val rdd = context.textFile("datas/apache.log")
val rddfilter = rdd.filter(
line => {
val datas = line.split(" ") //用空格分隔开,然后下面用索引获取
val time = datas(1)
time.startsWith("10:39:24") //startsWith 方法,启始的位置
}
)
rddfilter.collect().foreach(println)
context.stop()
}
}
9、sample (抽取数据)
(1) 函数说明
根据指定的规则从数据集中抽取数据。
(2) 代码示例
sample 算子需要传递三个参数:
1、第一个参数表示,抽取数据后是否将数据返回 true(放回),false(丢弃)
2、第二个参数表示:
如果抽取不放回的场合:数据源中每条数据被抽取的概率,基准值的概念
如果抽取放回的场合:表示数据源中的每条数据被抽取的可能次数
3、第三个参数表示,抽取数据时随机宣发的种子,如果不传入第三个参数,那么使用的是当前的系统时间
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//sample 算子
class Spark07_RDD_sample {
}
object Spark07_RDD_sample{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO RDD算子-sample
val rdd = context.makeRDD(List(1, 2, 3, 4,5,6,7,8,9,10)) //从这十个数据里面抽取数据
//sample 算子需要传递三个参数:
//1、第一个参数表示,抽取数据后是否将数据返回 true(放回),false(丢弃)
//2、第二个参数表示:
//如果抽取不放回的场合:数据源中每条数据被抽取的概率,基准值的概念
//如果抽取放回的场合:表示数据源中的每条数据被抽取的可能次数
//3、第三个参数表示,抽取数据时随机宣发的种子
//如果不传入第三个参数,那么使用的是当前的系统时间
val rddSample = rdd.sample(true,2) //表示第一次抽取到了2,那么第二次就抽取不到了
println(rddSample.collect().mkString(","))
context.stop()
}
}
那他有什么作用呢?用来抽奖吗?不是,为了处理数据倾斜的,当一个分区内有很多的数据,运行很慢,但是另外一个分区内没有数据,都无法进行工作,那么说明数据倾斜,这个时候就可以使用sample方法进行数据抽取,发现有一个数据出现了很多次数,那么就可以单独对他进行改善啥的。
10、distinct (去重)
(1) 函数说明
将数据集中重复的数据去重
val dataRDD = context.makeRDD(List(1,2,3,4,1,2))
val dataRDD1 = dataRDD.distinct() //对集合中的数据进行去重
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//distinct 算子:对重复数据进行去重
class Spark08_RDD_distinct {
}
object Spark08_RDD_distinct{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4, 1, 2,5,5,6,6,6))
val rddDistinct = rdd.distinct()
rddDistinct.collect().foreach(println)
context.stop()
}
}
11、coalesce (缩减分区)
(1) 函数说明
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率。
当spark程序中,存在过多的小任务的时候,可以通过coalesce方法,收缩合并分区,减少分区的个数,减少任务调度成本。
(2) 代码示例
注意:
coalesce 方法默认情况下不会将分区的数据打乱重新组合
这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜
如果想要让数据均衡,我们可以进行shuffle处理,
coalesce第二个参数就是shuffle 默认情况为false,输入true然后就可以保证两个分区的数据是均衡的了
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//coalesce 算子:
//根据数据量`缩减分区`,用于大数据集过滤后,提高小数据集的执行效率。
//当spark程序中,存在过多的小任务的时候,可以通过`coalesce`方法,收缩合并分区,减少分区的个数,减少任务调度成本。
class Spark09_RDD_coalesce {
}
object Spark09_RDD_coalesce{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO RDD 算子-coalesce
val rdd = context.makeRDD(List(1, 2, 3, 4,5,6), 3) //每个数据放一个分区
//coalesce 方法默认情况下不会将分区的数据打乱重新组合
//这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜
//如果想要让数据均衡,我们可以进行shuffle处理,
// coalesce第二个参数就是shuffle 默认情况为false,然后就可以保证两个分区的数据是均衡的了
val rddCoalesce = rdd.coalesce(2,true) //将4个分区缩减为2个分区
//rddCoalesce.collect().foreach(println)
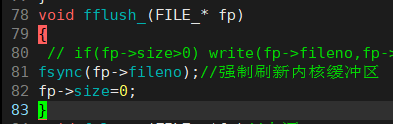
rddCoalesce.saveAsTextFile("output")
context.stop()
}
}
(3) 可以扩大分区吗?
coalesce 算子是可以扩大分区的,但是如果不进行shufflle 操作,是没有意义,不起作用,如果想要扩大分区的效果,需要使用shuffle操作。
12、reparition (扩大分区)
说明:
spark提供了一个简化的操作
缩减分区:coalesce,如果想要数据均衡可以使用shuffle
扩大分区:repartition,底层代码调用的就是coalesce,而且肯定采用shuffle
底层调用的是 coalesce 方法,然后肯定就为shuffle 为ture,所以缩减分区唷
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//coalesce 算子除了可以缩减分区,还可以扩大分区,扩大分区需要使用shuffle操作,不然没有任何意义
class Spark09_RDD_coalesce2 {
}
object Spark09_RDD_coalesce2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO RDD 算子-coalesce
val rdd = context.makeRDD(List(1, 2, 3, 4,5,6), 2) //每个数据放一个分区
//想要扩大分区需要使用shuffle操作,不然不会起作用
//spark提供了一个简化的操作
//缩减分区:coalesce,如果想要数据均衡可以使用shuffle
//扩大分区:repartition,底层代码调用的就是coalesce,而且肯定采用shuffle
//val rddcCoalesce = rdd.coalesce(3, true)
val rddcCoalesce = rdd.repartition(3)
rddcCoalesce.saveAsTextFile("output")
context.stop()
}
}
13、sortBy (排序)
(1) 函数说明
sortBy 方法可以根据指定的规则对数据源中的数据进行排序,默认为true升序,false是降序,第二个参数可以改变排序的方式,sortBy默认情况下不会改变分区,但是中间会存在shuffle操作。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//sortBy 算子
class Spark10_RDD_sortBy {
}
object Spark10_RDD_sortBy{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO RDD 算子-sortBy
val rdd = context.makeRDD(List(("1",1),("11",2),("2",3)),2) //分区数量是没有改变的,
//sortBy 方法可以根据指定的规则对数据源中的数据进行排序,默认为true升序,false是降序
//第二个参数可以改变排序的方式
//sortBy默认情况下不会改变分区,但是中间会存在shuffle操作
val rddSortBy = rdd.sortBy(num => num._1.toInt,false) //按照元组的key来进行排
rddSortBy.collect().foreach(println)
context.stop()
}
}
二、双Value类型
两个数据源之间的关联操作,我们称之为双值类型。
双value的算子就那么几个,而且比较简单,所以就直接写到一起了。
1、函数说明
交集 intersection() 方法,并集 union() 方法,差集 subtract() 方法,在scala差集是diff方法。拉链zip方法。
注意:
交集,并集,差集要求两个数据源类型保持一致,比如一个集合是Int类型的数字,而另外一个集合是String 类型的字符串,这样就不行。拉链操作,两个数据源的数据类型可以不一致。
拉链操作注意事项:
拉链就是将两个集合中的数据一一对应起来,返回一个二元组的形式。要注意的是两个数据源的分区要一致,比如两个集合,第一个集合两个分区,第二个集合三个分区,这样报错。两个数据源要求分区中数据数量保持一致,比如第一个数据源中五条数据,第二个集合中六条数据,这样也不行,在scala里面这样是可以的,后面那个数据只是没拉上,但是spark里面不行。
2 、代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//双Value类型的算子,就只有那么几个,差集并集,拉链,那几个操作,所以写在一起了
class Spark11_RDD_TwoValue {
}
object Spark11_RDD_TwoValue{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-双value类型
//交集,并集,差集要求两个数据源类型保持一致
//拉链操作,两个数据源的数据类型可以不一致
val rdd1 = context.makeRDD(List(1, 2, 3, 4))
val rdd2 = context.makeRDD(List(2, 5, 4, 6))
val rddsort = rdd2.sortBy(num => num)
rddsort.collect().foreach(println)
println("=================")
//交集
val rdd3 = rdd1.intersection(rdd2) //intersection 方法求两个集合的交集
rdd3.collect().foreach(println)
println("===============")
//并集
val rdd4 = rdd1.union(rdd2).distinct() //union 是并集,但是两个集合有重复的数据,都输出不好看,distinct去重
rdd4.collect().foreach(println)
println("=================")
//差集
val rdd5 = rdd1.subtract(rdd2) //subtract 方法差集,scala里面差集是diff
rdd5.collect().foreach(println) //以左边集合为基准,右边那个集合没有的数据就是差集
println("=================")
//拉链 将两个集合中的数据一一对应起来,然后返回一个二元组
val rdd6 = rdd1.zip(rdd2)
val rdd7 = context.makeRDD(List("hello scala","spark","hadoop","flink"))
val rdd8 = rdd1.zip(rdd7)
rdd8.collect().foreach(println)
rdd6.collect().foreach(println)
context.stop()
}
}
三、Key - Value 类型
1、partitionBy (重新分区)
(1) 函数说明
将数据按照指定的Partitioner重新进行分区。Spark默认分区器是HashPartitioner。
partitionBy() 根据指定的分区规则对数据进行重分区,比如集合中的数据1,2,3,4,分为两个分区是1,2 3,4,是均匀分的,但是我们不想,我们想奇数一个分区,偶数一个分区。所以用partitionBy()方法进行重新分区。
(2) 代码示例
说明:
Spark 默认提供了一个分区器HashPartitioner 把他传入进去就行了。
一共有三个分区器,HashPartitioner,RangePartitioner,PythonPartitioner。RangePartitioner基本是用来排序的,PythonPartitioner是有访问权限的,我们不能直接访问。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import scala.math.Integral.Implicits.infixIntegralOps
//partitionBy 算子:将数据按照指定的`Partitioner`重新进行分区。Spark默认分区器是HashPartitioner。
class Spark12_RDD_partitionBy {
}
object Spark12_RDD_partitionBy{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-(Key - Value类型)
val rdd = context.makeRDD(List(1, 2, 3, 4))
val mapRDD = rdd.map((_,1)) //因为这是键值类型的方法,所以要先用map转换一下
//Spark 默认提供了一个分区器HashPartitioner 把他传入进去就行了
//一共有三个分区器,HashPartitioner,RangePartitioner,PythonPartitioner
//RangePartitioner基本是用来排序的,PythonPartitioner我们不能直接访问
val rddpar = mapRDD.partitionBy(new HashPartitioner(2)).saveAsTextFile("output") //转换成键值类型的才能使用这个方法
context.stop()
}
}
2、reduceByKey (聚合)
可以将数据按照相同的Key对Value进行聚合。
说明:
scala语言中一般的聚合操作都是两两聚合,spark是基于scala开发的,所以他的聚合也是两两聚合,比如[1,2,3] 先是 1 + 2 然后得到结果又去加3所以是两两聚合,reduceByKey 中如果key的数据只有一个的话,是不会参与计算的,直接返回,比如 b只有一个。
注意:
reduceByKey 的分区内和分区间的计算规则相同。比如举个例子,之前有个案例先求分区内的最大值,然后分区间最大值求和,意思是先先求出每个分区的最大值,然后第二个计算规则是求和,这个时候就不能用reduceByKey了,因为他的分区内和分区间的计算规则是相同的。下面有一个方法arrreagteByKey可以解决这个问题
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
//reduceByKey 算子:可以将数据按照相同的Key对Value进行聚合。
class Spark13_RDD_reduceByKey {
}
object Spark13_RDD_reduceByKey{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-(Key - Value类型: reduceByKey)
//直接写kv类型的,难得转换了
val rdd = context.makeRDD(List(("a",1),("a",2),("a",3),("b",4)))
//reduceByKey: 相同的key的数据进行value数据的聚合操作
//scala语言中一般的聚合操作都是两两聚合,spark是基于scala开发的,所以他的聚合也是两两聚合
//比如[1,2,3] 先是 1 + 2 然后得到结果又去加3所以是两两聚合
//reduceByKey 中如果key的数据只有一个的话,是不会参与计算的,比如 b只有一个
val rdd2 = rdd.reduceByKey(_ + _)
rdd2.collect().foreach(println)
context.stop()
}
}
3、groupByKey (分组)
(1) 函数说明
将分区的数据直接转换为相同类型的内存数据进行后续处理。
groupByKey: 将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组。
元组中的第一个元素就是key,元组中的第二个元素就是相同key的value的集合。
注意:
groupBy 和 groupByKey 的区别在于,首先groupByKey() 是固定用key来进行分组的,而groupBy() 不一定。然后我们ByKey了那就是把value独立出来了,意思是value就不用管了反正就是用key进行分组,而groupBy 是整体拿来分组。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//groupByKey: 将分区的数据直接转换为相同类型的内存数据进行后续处理。
class Spark14_RDD_groupByKey {
}
object Spark14_RDD_groupByKey{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-(Key - Value类型: groupByKey)
//直接写kv类型的,难得转换了
val rdd = context.makeRDD(List(("a",1),("a",2),("a",3),("b",4)))
//groupByKey: 将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组
// 元组中的第一个元素就是key
// 元组中的第二个元素就是相同key的value的集合
val rddGroup = rdd.groupByKey()
rddGroup.collect().foreach(println)
context.stop()
}
}
4、reduceByKey 和 groupByKey的区别
从shuffle的角度:
reduceByKey 和 groupByKey 都存在shuffle的操作,但是reduceByKey可以在shuffle前对分区内相同的key的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能高。
从功能的角度:
reduceByKey其实包含分组和聚合的功能。groupByKey只能分组,不能聚合,所以在分组聚合的场景下,推荐使用reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用groupByKey
5、aggregateByKey (聚合计算)
(1) 函数说明
将数据根据不同的规则进行分区内计算和分区间计算。
说明:
aggregateByKey 存在函数的柯里化,有两个参数列表:
第一个参数列表,需要传递一个参数,表示为初始值,主要用于当碰见第一个key的时候,和value进行分区内计算。
第二个参数列表需要传递2个参数,第一个参数表示分区内计算规则,第二个参数表示分区间的计算规则。
注意:aggregateByKey最终的返数据结果应该和初始值的类型保持一致。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//aggregateByKey 算子:将数据根据`不同的规则`进行分区内计算和分区间计算。
class Spark15_RDD_aggregateByKey {
}
object Spark15_RDD_aggregateByKey{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-(Key - Value类型: aggregateByKey)
val rdd = context.makeRDD(List(("a",1),("a",2),("a",3),("a",4)),2)
// (a,[1,2,]) (a,[3,4]) 主要是求分区内的最大值,然后进行求和
// (a,2) (a,4)
// (a,6)
//aggregateByKey 存在函数的柯里化,有两个参数列表
//第一个参数列表,需要传递一个参数,表示为初始值
// 主要用于当碰见第一个key的时候,和value进行分区内计算
//第二个参数列表需要传递2个参数
// 第一个参数表示分区内计算规则
// 第二个参数表示分区间的计算规则
val rddagg = rdd.aggregateByKey(0)(
(x,y) => math.max(x,y),// 第一个参数就是求分区内的最大值,用math.max方法把参数传入进去直接求
(x,y) => x + y // 两个分区的最大值都已经算出来了,第二个参数就是直接进行聚合
)
rddagg.collect().foreach(println)
context.stop()
}
}
(3) 小案例获取相同key的数据的平均值 => (a,3),(b,4)
aggregateByKey最终的返数据结果应该和初始值的类型保持一致。特别注意这一点
思路:
首先,我们想要求的是每一个key的数据的平均值,aggregateByKey方法初始值应该设置为一个二元组(0,0)初始值都设置为0,第一个0是用于key的数据计算的初始值,比如(a,1),(a,2),(a,3) 这个1,2,3就是要进行计算的,第二个0是a出现的次数,比如这里a有三次。然后第二个参数列表,第一个是分区内计算,第二个是分区间计算,两个分区间相同的key出现次数进行相加,然后第二个是两个分区相同key的数据进行相加。下面算平均值,使用mapValues()方法用于key不变,对value进行转换,模式匹配,用相同key的数据,除以key出现的次数,得到的就是平均值。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//小案例获取相同key的数据的平均值 => (a,3),(b,4)
class Spark15_RDD_aggregateByKey2 {
}
object Spark15_RDD_aggregateByKey2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-(Key - Value类型: aggregateByKey)
val rdd = context.makeRDD(List(
("a",1),("a",2),("b",3),
("b",4),("b",5),("a",6))
,2)
//aggregateByKey最终的返数据结果应该和初始值的类型保持一致。特别注意这一点
val newRdd:RDD[(String,(Int,Int))] = rdd.aggregateByKey((0,0))( //初始值就写一个元组(0,0)
(t,v) => { //第一个0是表示1,2,6等用于计算的初始值,第二个0是表示相同key出现的次数
//第一个参数是分区内的计算 t是后面这个tuple(0,0) v是key
(t._1 + v,t._2+1) //t._1 表示的是tuple中的key的数据,t._2 表示的是key的出现次数
},(t1,t2) => {
(t1._1 + t2._1,t1._2 + t2._2) //这是分区间的计算,两个分区相同的key相加,第二个参数出现的次数相加
}
)
val result = newRdd.mapValues { //用所有a的值除以a出现的次数,就是平均值了
case (num, count) => num / count //第一个是key,的每一个值累加1+2+6 第二个是出现了三次a 3
} //用于key不变。只对value转换的时候
result.collect().foreach(println)
context.stop()
}
}
6、foldByKey (聚合计算)
(1) 函数说明
如果聚合计算时,分区内和分区间计算规则相同,spark提供了简便的方法,foldByKey()()和aggregateByKey方法基本一样,也是函数柯里化,有两个参数列表,第一个参数列表一个参数,初始值。第二个参数列表也只有一个参数,因为分区内和分区间的计算规则相同。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
//foldByKey 算子:如果聚合计算时,分区内和分区间计算规则相同,spark提供了简便的方法
class Spark15_RDD_foldByKey {
}
object Spark15_RDD_foldByKey{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-(Key - Value类型: aggregateByKey)
val rdd = context.makeRDD(List(("a",1),("a",2),("a",3),("a",4)),2)
val rddfold = rdd.foldByKey(0)(_ + _) //直接一个初始值,一个计算规则就出来了
rddfold.collect().foreach(println)
context.stop()
}
}
7、combineByKey (聚合计算)
这个也是和aggregateByKey算子很相似的,只是说没有了初始值概念,把第一个数据做转换然后把第一个数据当做初始值。然后其他地方的操作都一样了。
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//combineByKey 算子:这个也是和`aggregateByKey`算子很相似的,只是说没有了初始值概念,
// 把第一个数据做转换然后把第一个数据当做初始值。
class Spark16_RDD_combineByKey {
}
object Spark16_RDD_combineByKey{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//TODO 算子-(Key - Value类型: combineByKey)
val rdd = context.makeRDD(List(
("a",1),("a",2),("b",3),
("b",4),("b",5),("a",6))
,2)
//把第一个数据做转换然后把第一个数据当做初始值。然后其他的都一样
val result: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
result.mapValues{
case (num,count) => num/count
}.collect().foreach(println)
context.stop()
}
}
8、join (连接两个数据源相同key数据)
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素连接在一起的(K,(V,W))的RDD。
(1) 函数说明
join: 两个不同数据源的数据,相同的key的value会连接在一起。形成元组。如果两个数据源中key没有匹配上,那么数据不会出现在结果中。如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低。所以说使用join要谨慎。不大推荐使用,非要用的话想一想能不能使用其他的方式代替join。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//RDD Join 算子:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素连接在一起的(K,(V,W))的RDD。
class Spark17_RDD_join {
}
object Spark17_RDD_join{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = context.makeRDD(List(
("a", 1), ("b", 2), ("c", 3),("a",6)
))
val rdd2 = context.makeRDD(List( //两个数据源
("a", 4), ("b", 5), ("c", 6),("d",7),("d",8),("a",8)
))
//join: 两个不同数据源的数据,相同的key的value会连接在一起。形成元组
// 如果两个数据源中key没有匹配上,那么数据不会出现在结果中
// 如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积
// 数据量会几何性增长,会导致性能降低,
val joinRDD = rdd1.join(rdd2) //join将相同key的数据连接到一个组里面
joinRDD.collect().foreach(println)
context.stop()
}
}
9、leftOuterJoin 和 rightOuterJoin
(1) 函数说明
类似于SQL语句的左外连接。因为比较简单少所以左连接和外连接写一起。跟join不一样。join是要是两个数据源没有相同的key,比如只有rdd1有(“e”,1),而rdd2没得e,那么这个e是不会输出出来的,但是左外连接就是以左边那个表为基准。就算下面那个表么得但是还是会输出出来,右外连接也是一样的道理,以右边那个表为基准。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//leftOuterJoin,rightOuterJoin:左外连接和右外连接,因为比较简单所以写在一起
class Spark18_RDD_leftOuterJoin_rightOuterJoin {
}
object Spark18_RDD_leftOuterJoin_rightOuterJoin{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = context.makeRDD(List(
("a", 1), ("b", 2), ("c", 3),("a",6),("e",1)
))
val rdd2 = context.makeRDD(List( //两个数据源
("a", 4), ("b", 5), ("c", 6),("d",7),("d",8),("a",8)
))
val joinRDD = rdd1.rightOuterJoin(rdd2) //join将相同key的数据连接到一个组里面
joinRDD.collect().foreach(println)
context.stop()
}
}
10、cogroup (分组 + 连接)
(1) 函数说明
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD。
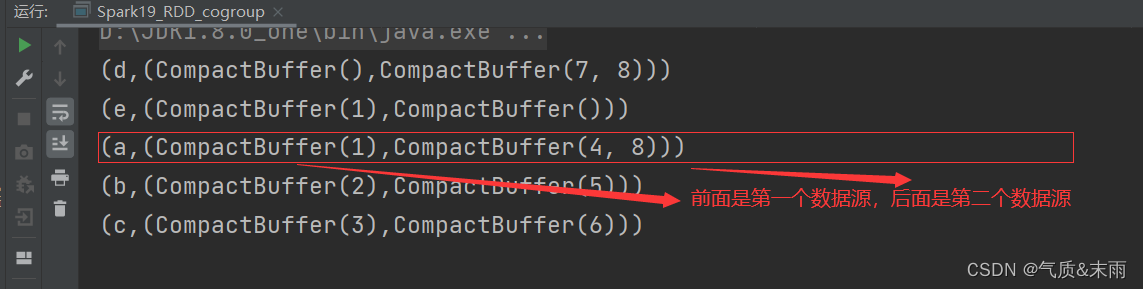
cogroup:connect(连接) + group(分组) 是先进行分组,然后进行连接。相当于是两个数据源,第一个数据源中相同key的数据分到一个组中,然后第二个数据源中相同的key的数据分到一个组中,然后给他们。装到一个大的元组里面,第一个元素是key,然后第二个元素是一个小元组,然后把两个分组装到里面,输出出来。
(2) 代码示例
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//cogroup 算子:在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD。
class Spark19_RDD_cogroup {
}
object Spark19_RDD_cogroup{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = context.makeRDD(List(
("a", 1), ("b", 2), ("c", 3),("a",6),("e",1)
))
val rdd2 = context.makeRDD(List( //两个数据源
("a", 4), ("b", 5), ("c", 6),("d",7),("d",8),("a",8)
))
//cogroup: connect(连接) + group(分组) 是先分组然后再连接
val cgRDD: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
cgRDD.collect().foreach(println)
context.stop()
}
}
四、案例实操
1) 数据准备
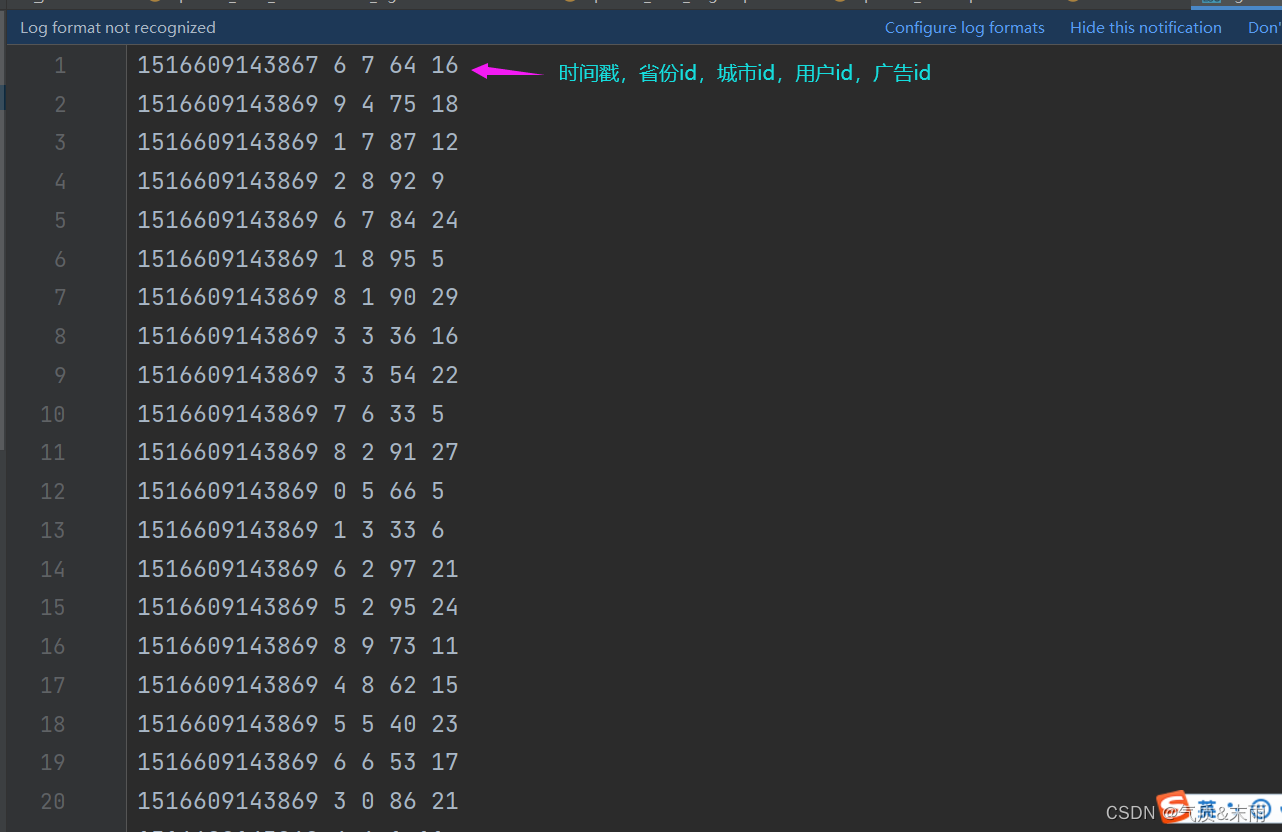
agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分割。
2) 需求描述
统计出每一个省份每个广告被点击数量排行的Top3。
3) 需求分析
因为这样总结的时候看的不是那么清楚,写的时候把类型返回出来就看的明白了。
大概有七步:
1、把准备好数据读取出来
使用textFile("")方法创建RDD。
2、结构转换,将数据按行读取,然后用空格分割字段,把多余的不需要的字段给剔除
使用map(line => { val datas = line.split(" ") //按空格分割 //把省份和广告这个整体当做索引,然后分组 (datas(1),datas(4),1) //将结构转换为这样,分割好之后只需要省份和广告 })
3、把结构转换好之后,按照索引聚合
使用reduceByKey(_ + _),这样就按照省份和广告,把点击次数集合好了
4、聚合好之后,需要再次进行转换
map{ //之前是省份和广告在一个分组里面,现在后面两个放在一起了 case ((pri,ad),sum) => (pri,(ad,sum)) //((省份,广告),sum) => (省份,(广告,sum)) }
5、再次转换好之后,然后对省份进行分组
使用groupBykey()方法,直接就分好了,因为key就是省份
6、按照省份分好组之后,进行排序
mapValue( iter => { //因为上一步返回的结果是一个可迭代集合,使用不了sortBy方法 iter.toList.sortBy(_._2).reverse.take(3) //toList方法转换,sortby默认是升序reverse倒转,然后取排名前三 } )
7、采集数据打印到控制台
collect().foreach(println) //将完成的结果打印到控制台
4) 功能实现
package com.atguigu.bigdata.spark.core.wc.operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class test5 {
}
object test5{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val context = new SparkContext(conf)
//1、准备好原始数据 时间戳,省份,城市,用户,广告,中间字段使用空格分割
val rdd = context.textFile("datas/agent.log")
//2、转换结构,便于统计,多余的不需要的数据也给剔除了
val mapRDD = rdd.map(
line => {
val datas = line.split(" ") //先按行用空格把字段给分割开。
((datas(1), datas(4)), 1) //要转换成这个样子((省份,广告),1) 吧省份和广告这个整体当做索引
}
)
//3、转换好之后进行,进行分组聚合
val reduceRDD = mapRDD.reduceByKey(_ + _) // 用reduceBykey 按照key进行聚合
//4、聚合好之后再次转换,转换成(省份,(广告,sum)) 把广告和统计好的数据放在一起
val newMapRDD: RDD[(String, (String, Int))] = reduceRDD.map { //用模式匹配比较方便
case ((pri, ad), sum) => (pri, (ad, sum)) //转换为这样
}
//5、将转换之后的数据按照省份进行分组
val groupRDD: RDD[(String, Iterable[(String, Int)])] = newMapRDD.groupByKey()
//6、分组之后就要进行组内排序了,排序用不到key省份,直接用mapValue方法快捷
val result = groupRDD.mapValues(
iter => {//因为上面返回的是一个可迭代的集合,不能那个使用sortBy方法,我们需要toList转换然后才可以用
iter.toList.sortBy(num => num._2).reverse.take(3) //然后根据元组的第二个也就是广告的点击数排序,默认是升序reverse整成降序take(3)取前三
}
)
//7、采集数据打印到控制台
result.collect().foreach(println)
context.stop()
}
}