这示例它实现了一个基于LangGraph的系统,用于处理文档检索和生成答案的过程。
好的,我会按照Markdown格式完整翻译并保留文件结构和格式:
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraph tavily-python
CRAG
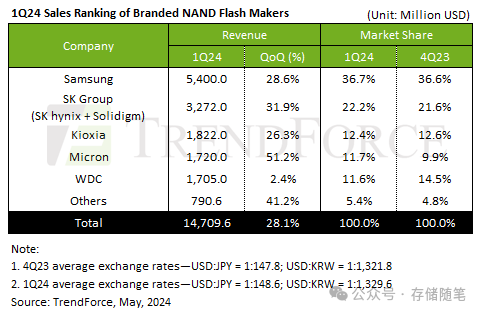
Corrective-RAG 是一篇最新的论文,介绍了一种有趣的主动 RAG 方法。
该框架根据问题对检索到的文档进行评分:
-
正确的文档 -
- 如果至少有一个文档超过了相关性的阈值,则继续生成。
- 在生成之前,它会进行知识细化。
- 这会将文档分成“知识条带”。
- 它对每个条带进行评分,并过滤掉无关的条带。
-
含糊或错误的文档 -
- 如果所有文档都低于相关性阈值或评分器不确定,则框架会寻找额外的数据源。
- 它会使用网络搜索来补充检索。
- 论文中的图表还表明,这里使用了查询重写。
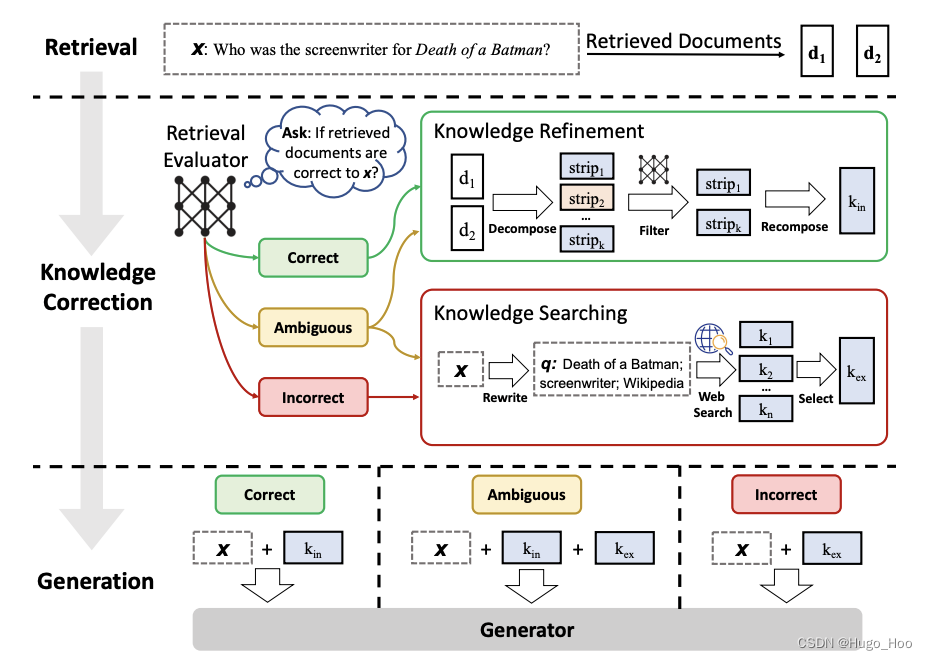
论文链接:https://arxiv.org/pdf/2401.15884.pdf
让我们使用 LangGraph 从头开始实现这一点。
我们可以做一些简化:
- 作为初步尝试,让我们跳过知识细化阶段。如果需要,可以将其添加回节点中。
- 如果任何文档不相关,我们选择使用网络搜索来补充检索。
- 我们将使用 Tavily Search 进行网络搜索。
- 我们将使用查询重写来优化网络搜索查询。
设置 TAVILY_API_KEY。
检索器
让我们索引3篇博客文章。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
状态
我们将定义一个图。
我们的状态将是 dict 。
我们可以从任何图形节点 state[‘keys’] 访问它。
from typing import Dict, TypedDict
from langchain_core.messages import BaseMessage
class GraphState(TypedDict):
"""
Represents the state of an agent in the conversation.
Attributes:
keys: A dictionary where each key is a string and the value is expected to be a list or another structure
that supports addition with `operator.add`. This could be used, for instance, to accumulate messages
or other pieces of data throughout the graph.
"""
keys: Dict[str, any]
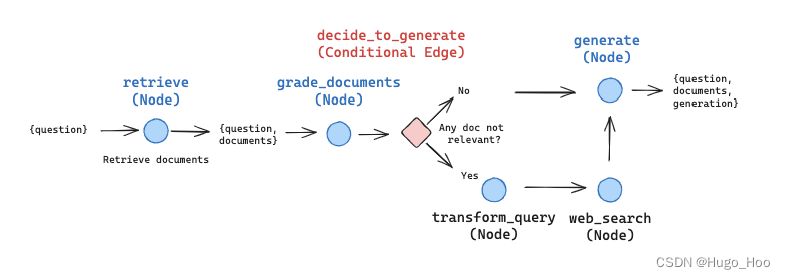
节点和边
每个 node 将简单地修改 state 。
每个 edge 将选择接下来调用哪个 node 。
它将遵循上面显示的图表。
import json
import operator
from typing import Annotated, Sequence, TypedDict
# 导入langchain相关模块
from langchain import hub
from langchain.output_parsers import PydanticOutputParser
from langchain.output_parsers.openai_tools import PydanticToolsParser
from langchain.prompts import PromptTemplate
from langchain.schema import Document
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.vectorstores import Chroma
from langchain_core.messages import BaseMessage, FunctionMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.runnables import RunnablePassthrough
from langchain_core.utils.function_calling import convert_to_openai_tool
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langgraph.prebuilt import ToolInvocation
### 节点函数 ###
def retrieve(state):
"""
检索文档
参数:
state (dict): 代理当前状态,包括所有键。
返回:
dict: 在状态中添加新的键'documents',包含检索到的文档。
"""
print("---RETRIEVE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = retriever.invoke(question)
return {"keys": {"documents": documents, "question": question}}
def generate(state):
"""
生成回答
参数:
state (dict): 代理当前状态,包括所有键。
返回:
dict: 在状态中添加新的键'generation',包含生成的回答。
"""
print("---GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# 提示模板
prompt = hub.pull("rlm/rag-prompt")
# 大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0, streaming=True)
# 后处理函数
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 链
rag_chain = prompt | llm | StrOutputParser()
# 运行
generation = rag_chain.invoke({"context": documents, "question": question})
return {
"keys": {"documents": documents, "question": question, "generation": generation}
}
def grade_documents(state):
"""
判断检索到的文档是否与问题相关。
参数:
state (dict): 代理当前状态,包括所有键。
返回:
dict: 在状态中添加新的键'filtered_documents',包含相关的文档。
"""
print("---CHECK RELEVANCE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# 数据模型
class grade(BaseModel):
"""相关性检查的二进制评分。"""
binary_score: str = Field(description="相关性评分 'yes' 或 'no'")
# 大语言模型
model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True)
# 工具
grade_tool_oai = convert_to_openai_tool(grade)
# 绑定工具和强制调用的语言模型
llm_with_tool = model.bind(
tools=[convert_to_openai_tool(grade_tool_oai)],
tool_choice={"type": "function", "function": {"name": "grade"}},
)
# 解析器
parser_tool = PydanticToolsParser(tools=[grade])
# 提示模板
prompt = PromptTemplate(
template="""你是一个评分员,评估检索到的文档与用户问题的相关性。\n
这是检索到的文档:\n\n {context} \n\n
这是用户的问题:{question} \n
如果文档包含与用户问题相关的关键词或语义,请评为相关。\n
给出一个 'yes' 或 'no' 的二进制评分,表示文档是否与问题相关。""",
input_variables=["context", "question"],
)
# 链
chain = prompt | llm_with_tool | parser_tool
# 评分
filtered_docs = []
search = "No" # 默认不进行网络搜索来补充检索
for d in documents:
score = chain.invoke({"question": question, "context": d.page_content})
grade = score[0].binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
search = "Yes" # 进行网络搜索
continue
return {
"keys": {
"documents": filtered_docs,
"question": question,
"run_web_search": search,
}
}
def transform_query(state):
"""
转换查询以生成更好的问题。
参数:
state (dict): 代理当前状态,包括所有键。
返回:
dict: 保存新的问题。
"""
print("---TRANSFORM QUERY---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# 创建一个提示模板,包含格式指令和查询
prompt = PromptTemplate(
template="""你正在生成一个优化检索的问题。\n
查看输入并试图推理其潜在的语义意图。\n
这是初始问题:
\n ------- \n
{question}
\n ------- \n
生成一个改进的问题:""",
input_variables=["question"],
)
# 评分员
model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True)
# 链
chain = prompt | model | StrOutputParser()
better_question = chain.invoke({"question": question})
return {"keys": {"documents": documents, "question": better_question}}
def web_search(state):
"""
使用Tavily进行网络搜索。
参数:
state (dict): 代理当前状态,包括所有键。
返回:
state (dict): 将网络搜索结果附加到文档中。
"""
print("---WEB SEARCH---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
tool = TavilySearchResults()
docs = tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"keys": {"documents": documents, "question": question}}
### 边函数 ###
def decide_to_generate(state):
"""
决定是生成回答还是重新生成问题。
参数:
state (dict): 代理当前状态,包括所有键。
返回:
dict: 在状态中添加新的键'filtered_documents',包含相关的文档。
"""
print("---DECIDE TO GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
filtered_documents = state_dict["documents"]
search = state_dict["run_web_search"]
if search == "Yes":
# 所有文档已被过滤
# 我们将重新生成一个新的查询
print("---DECISION: TRANSFORM QUERY and RUN WEB SEARCH---")
return "transform_query"
else:
# 我们有相关文档,所以生成回答
print("---DECISION: GENERATE---")
return "generate"
import pprint
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# 定义节点
workflow.add_node("retrieve", retrieve) # 检索
workflow.add_node("grade_documents", grade_documents) # 评分文档
workflow.add_node("generate", generate) # 生成
workflow.add_node("transform_query", transform_query) # 转换查询
workflow.add_node("web_search", web_search) # 网络搜索
# 构建图
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search")
workflow.add_edge("web_search", "generate")
workflow.add_edge("generate", END)
# 编译
app = workflow.compile()
# 运行
inputs = {"keys": {"question": "Explain how the different types of agent memory work?"}}
for output in app.stream(inputs):
for key, value in output.items():
pprint.pprint(f"Output from node '{key}':")
pprint.pprint("---")
pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint.pprint("\n---\n")
# 对不在上下文中的问题进行修正
inputs = {"keys": {"question": "What is the approach taken in the AlphaCodium paper?"}}
for output in app.stream(inputs):
for key, value in output.items():
pprint.pprint(f"Output from node '{key}':")
pprint.pprint("---")
pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint.pprint("\n---\n")
扩展知识点:
- LangChain:是一个用于构建语言模型应用的Python库,提供了文本分割、文档加载、向量存储、嵌入和检索等功能。
- Tavily Search:是一个网络搜索引擎,可以用于补充检索过程中的数据源。
- RecursiveCharacterTextSplitter:用于将长文本分割成更小的块,以便更好地处理和索引。
- Chroma:是一个向量数据库,可以存储和检索文档的嵌入表示。
- OpenAIEmbeddings:使用OpenAI的模型来生成文档的嵌入表示。
- StateGraph:是一个用于构建和执行状态图的类,状态图是一种用于控制流程的有向图。
总结:
本文介绍了一个使用LangGraph实现的系统,该系统通过文档检索、文档评估、问题转换和网络搜索等步骤,来生成针对特定问题的答案。系统的核心是一个状态图,它定义了各个节点和边,通过这些节点和边来控制整个检索和生成流程。代码中使用了多个库,包括langchain、langchain_community、langchain_openai等,这些库为系统提供了文本分割、文档加载、向量存储、嵌入和检索等功能。


![[C#] opencvsharp对Mat数据进行序列化或者反序列化以及格式化输出](https://img-blog.csdnimg.cn/direct/7e848dc343ca4053ae5f3c8fa879b1fd.png)