论文:HRVDA: High-Resolution Visual Document Assistant
代码:暂无
出处:中国科学技术大学 | 腾讯优图
贡献点:
- 作者提出了高分辨率视觉文档助手 HRVDA,能直接处理高分辨率图像输入
- 作者提出了内容过滤机制和指令过滤机制,用于过滤无用的 visual token,加速模型训练和推理,让大分辨率输入成为可能
- 作者收集了一个丰富的以文档为中心的指令微调数据集,用于提升模型在文档理解上的能力
一、背景
现有的 MLLM 模型虽然也可以用于文档理解,如理解表格、图表等,也就是有一定的文本和视觉信息之间关系的捕捉能力
但是由于下面两个原因,导致 MLLM 的能力受限:
- 输入图像分辨率低:当前的很多模型都使用低分辨率的输入,如 224x224,这种大小适合于自然图像的理解,但对于文档数据来说就太小了
- 如果直接增加图像分辨率会产生大量的 visual tokens,这将占用大型语言模型(LLMs)的有限输入容量,并导致相当大的训练成本和推理延迟[17]。
- 以CLIP的图像编码器[23, 51]为例,一个1536 × 1536的图像被划分为16 × 16的块,会产生 9216 个 visual token,这超出了许多现有开源LLMs(如LLaMA-2 [62])的上下文长度 4096。而且在计算复杂度上随着块序列长度也会呈二次增长。
- 指令微调的文档相关的数据较少:
- 通用多模态大型语言模型(MLLMs)缺乏面向文档的视觉指令调优[40],导致对文档图像的理解不完整。与普通图像不同,文档图像具有独特的布局和结构信息,其中字体、风格和颜色对于理解内容具有重要意义[45, 56]。
基于上面两个问题,作者提出了 HRVDA(HighResolution Visual Document Assistant),该模型采用内容过滤机制和指令过滤模块,分别用于过滤掉与内容无关的 visual token 和与指令无关的 visual token。
为什么要过滤呢:
- 与内容无关的视觉标记会贡献大量冗余信息,而文档图像中包含文本、表格、图表和其他文档内容的区域通常提供最有价值的信息。如图1所示,这些区域内的像素仅占整个图像的一小部分[45]。为了减少空白背景标记的数量,我们提出的内容过滤机制基于一个内容检测器,可以从文档图像中提取关键特征。保守估计,这种方法在实践中过滤掉了大约50%的与内容无关的标记,从而在不影响性能的情况下显著减少了30%的训练和推理延迟。
- 与指令无关的视觉标记是指不在指令关注区域内的部分。在传统的文档理解任务中,例如信息提取,面向文档的指令通常依赖于局部区域生成答案[30, 49]。因此,作者设计了一个指令过滤模块,以进一步过滤与指令无关的视觉标记,并显著减少LLM的工作负载。
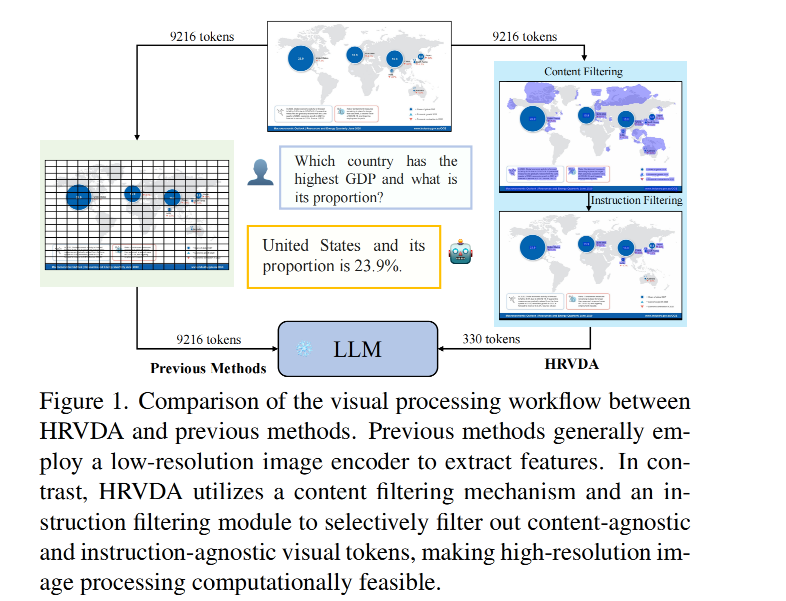
为了提高 HRVDA 的文档理解能力,作者构建了一个面向文档的视觉指令调优数据集。该数据集涵盖了文档领域内广泛的任务,包括信息提取、文本识别和视觉问答。它还包含各种场景,如表格、图表、自然图片和网页截图。此外,作者使用 ChatGPT [47] 生成了多样化的指令模板,从而增强模型的泛化能力。
实验结果显示,在多个面向文档的数据集上,HRVDA 的 OCR-free 文档理解能力超越了当前最先进的多模态大型语言模型如 mPLUG-DocOwl [68] 和 UReader [69]。
2、文档理解任务一般有下面两大类:
- OCR-dependent 方法:通常依赖于外部 OCR 接口从文档图像中提取文本内容和坐标信息 [19, 32, 50, 72]。例如,LayoutLM系列 [29, 66, 67] 利用多模态预训练将图像布局特征与文本特征结合起来。DocFormer [2] 通过精心设计的任务进行无监督预训练,以促进多模态交互。UDOP [60] 利用文档中的空间关系,将图像、文本和布局模态统一成一个统一且连贯的表示。这些方法通常面临增加计算成本和错误累积的问题 [8]。
- OCR-free 方法:以端到端的方式直接从图像中提取结构化文本。这种方法简化了信息处理过程,加快了推理速度,并且最近在视觉文档理解(VDU)社区中获得了很大关注 [18, 38]。例如,Donut [33] 和 Dessurt [21] 都利用 Swin Transformer 来提取图像特征,然后通过解码器模型(如BART)和图像特征之间的交叉注意力操作,以自回归方式生成文本。SeRum [9] 更进一步通过选择性区域集中来增强生成的精度和速度。
多模态语言模型(Multimodal Language Models,MLLMs)根据模态对齐的方法可以分为两类:
-
基于查询的方法:基于查询的方法涉及使用一组可学习的查询标记(query tokens),通过交叉注意力机制从图像中提取信息。
这种方法的核心思想是用查询标记作为桥梁,将文本和图像特征联系起来。如Flamingo [1] 和 BLIP-2 [37],通过引入可学习的查询标记来从图像中提取有用的信息。
通过引入可学习的查询标记,在一定程度上实现了文本和图像特征的结合,但在细粒度任务中表现有限
优点:这种方法能够有效地将文本和图像特征结合起来,通过交叉注意力机制进行信息提取。
缺点:由于这种方法本质上引入了一个文本监督信号来提取图像特征,因此不适合细粒度的预测任务。此外,它可能在处理复杂的多模态任务时表现不佳。
-
基于投影的方法:直接将视觉标记(visual tokens)映射到大型语言模型(LLM)的输入空间。使得模型能够全面感知图像信息,提供了一个更有前景的方法用于多模态学习。
这种方法使LLM能够直接感知和处理图像信息,从而实现更高效的多模态学习。
如 LLaVA [40] 这个模型使用一个简单的线性层来投影图像特征,使得这些特征可以与LLM的输入空间对齐。
LLaMA-Adapter [74] 这个模型应用了一个轻量级适配器模块,目的是对齐视觉标记和文本标记,从而实现更好的多模态融合。
优点:这种方法允许LLM直接感知整个图像,从而提供了一个更有前景的视角用于有效的多模态学习。这种直接映射的方法通常能够更好地捕捉复杂的视觉信息,并且在处理细粒度任务时表现更佳。
缺点:尽管这种方法在理论上更具优势,但实际应用中可能需要更多计算资源和优化技巧,以确保映射过程高效且准确。
二、方法

整体结构如图 2 所示,包括 4 个模块:
- 内容检测器:将图像划分为一系列图像块儿后,被转换为一系列的 visual token,这些 token 通过 content detector 进行处理,以评估每个 token 包含重要信息的概率,内容过滤机制就是依据这些概率来啊选择 visual token,移除与内容无关的 token
- 图像编码器:将有用的 token 通过图像 encoder 进行特征提取
- 指令过滤模块:将图像编码特征和指令特征经过自注意力机制进行融合,后面会跟一个两层 MLP 用于分类这些特征,丢弃与指令无关的视觉标记
- LLM:将过滤后的 visual token 和 指令一起送入 LLM,进行结果的输出
2.1 内容过滤
在 Transformer 结构中,高分辨率的图像一般都被切分后转换为长的 token 序列,这对计算资源有很大的要求,也带来了大量的计算量
对于文档数据,其有一个特性就是包含大量的空白背景区域,所以作者提出的内容过滤机制包含两个模块:
-
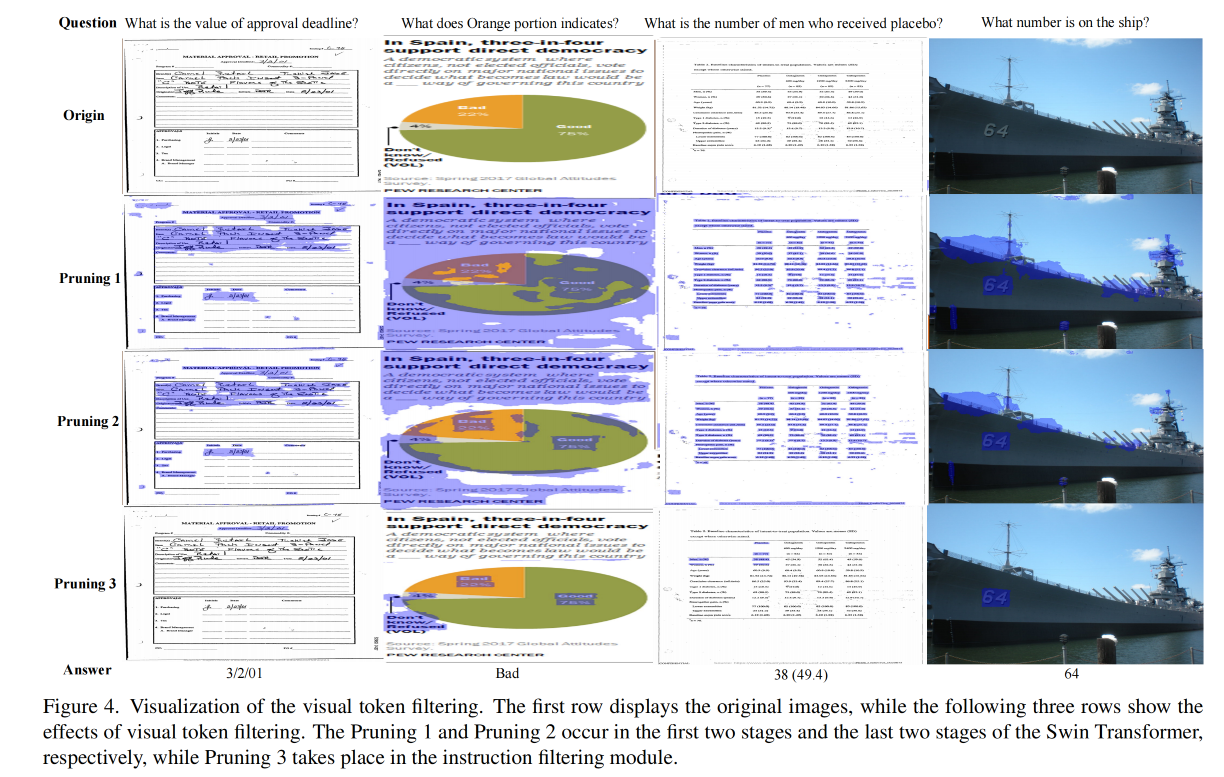
内容检测器:可以用于识别每个 token 是否包含重要内容,也就是是否包含文本、表格、图表元素等,可以使用 MLP 分类器来实现、或者 DETR 检测器来实现、或者分割网络来实现。作者使用了一个浅层的 PSENet,是一个基于分割的检测器,能够定位任何形状的文本。且内容检测器采用的高召回策略,只要包含内容的 token 都会被召回。
对于训练好的内容检测器,作者使用一个阈值来判断是否保留,大于阈值则概率被设置为 1。利用这个概率,如果一个窗口内没有任何标记被认为包含内容,那么该窗口将跳过注意力计算,直接传递到下一个块,从而实现计算加速。
-
图像编码器:作者使用 Swin Transformer 来作为图像编码器
2.2 指令过滤
以文档为中心的指令非常精确,一般都会指向图中某些特定的部分,所以其他没被指向的 visual token 可以被过滤
现有方法的局限性:
- BLIP-2中 的 Q-Former 模块和 mPLUG-owl 中的 Visual Abstractor 模块使用可学习的查询向量来提取有价值的信息。
- 但这些方法会无意中减少视觉信息的表示能力,使得它不太适合用于需要细粒度预测的任务。
- 这些查询向量主要依赖文本作为监督信号,但图像的文本描述往往不足以提供准确的表示。
- 实验发现,对于高分辨率图像,大约需要500个查询向量才能保持性能不显著下降。这表明这种方法在处理速度上并没有优势。
指令过滤模块:
- 输入:visual vector 和 instruction vector 连接起来后作为输入
- 模块构成:一个 Transformer layer,用于对两个 vector 进行融合,如公式 4 所示,SA 是自注意力层,FFN 是前馈层,然后将融合后的 visual 特征 V’ 输入一个 2 层 MLP 用于分类,判断 visual token 是否和指令有关
- 输出:概率
- 如何判断是否需要过滤:使用一个阈值来判断
2.3 视觉指令微调

微调任务:
为了增强 HRVDA 在视觉文档理解中的泛化能力,作者将各种文档任务组织成指令格式。
在这项工作中,主要关注以下任务,表 1 展示了一些基本示例:
- 文档分类(DC)
- 信息提取(IE)
- 视觉问答(VQA)
- 光学字符识别(OCR)
- 视觉定位(VG)
- 图像描述(IC)
- 表格重建(TR)
为了多样化 prompt 的范围,作者为每个任务手动制作了 10 个提示模板。随后,使用 ChatGPT [47] 生成 50 个类似的提示,这些提示随后由人类专家审核,以确保它们与预期含义一致。附加模板可以在附录B.1中找到。

指令数据资源:
作者收集了大量的真实世界和合成数据集。
真实世界数据集包括 IIT-CDIP [27]、CORD [49]、SROIE [30]、DocVQA [45]、InfographicsVQA [46]、DeepForm [7]、Kleister Charity [57]、WikiTableQuestions [5]、TabFact [16]、ChartQA [15]、TextVQA [56]、TextCaps [55]、VisualMRC [59]、PubTabNet [76]等。
鉴于开源数据的有限性,在这项工作中应用了大量的数据合成方法,如 SynthText [26]、Synth90K [31] 和 SynthDoG [33]。更多细节见附录B.2。
2.4 训练策略
为了实现 visual token 过滤并增强模型对指令的理解能力,作者使用了 4 阶段训练的方法
- stage 1:训练 content detector,作者使用了一个额外的 OCR 工具和一个检测网络来得到文本、表格、图表等信息的坐标,这些坐标会用做 PSENet 的监督信号,来指导该 token 是否包含内容
- stage 2:预训练 image encoder
- stage 3:训练指令过滤模块,对于具有固定布局的数据,使用高过滤阈值。对于布局多变的数据,使用低过滤阈值。
- stage 4:使用 LoRA 来微调 LLM
三、效果
3.1 任务和数据集
在视觉文档理解中,信息提取和面向文本的视觉问答是具有挑战性的任务
信息提取:涉及从文档中提取结构化的键值对数据。本文使用了两个最常用的数据集进行评估,即 CORD [49] 和 SROIE [30]。这些数据集都是扫描的收据图像,并且具有良好的图像质量。报告的 F1 得分是精度和召回率的加权调和平均值。
面向文本的视觉问答是一项高度通用的任务,能够通过适当的提示解决各种问题。作者在一系列公开可用的数据集上评估 HRVDA,包括DocVQA [45]、InfoVQA [46]、TextVQA [56]、ChartQA [15]、DeepForm [7]、KLC [57]、WTQ [5]、TableFact [16]、VisualMRC [59] 和 TextCaps [55]。
根据之前工作的方法,报告了不同的指标,包括 ANLS、CIDEr、准确性和F1得分。详细描述可以在附录B.2中找到。
3.2 效果对比
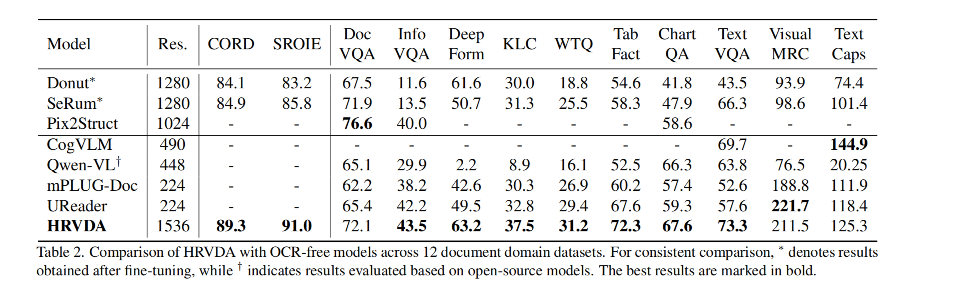
作者和 OCR-Free 的方法进行了下面的对比,共在 12 个数据集上进行了对比,本文方法在 9 个上都是最优的,这得益于视觉预训练(阶段2)。
下面的这些方法可以分为两个大类:
- 第一类:使用 cross-attention 来融合 image 和 text,使用高分辨率图像时计算也比较高效,但需要特定任务的微调
- 第二类:使用 LLM 有很强的理解能力,但难以直接处理高分辨率的图像
在视觉问答任务中,理解问题至关重要,特别是在包含大量自然场景元素的数据集中[56]。第一类中的解码器在语义分析能力方面有限,这阻碍了它们达到最佳性能。以往的多模态学习模型(MLLMs)受到低分辨率图像输入导致的视觉信息失真限制,也无法达到理想效果。HRVDA 模型直接处理高分辨率图像输入,最大限度地减少视觉信息丢失,从而显著提升性能。
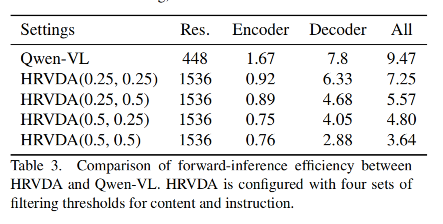
在效率评上作者使用 Qwen-VL 作为基线,并在 Tesla V100 GPU 上评估前向推理延迟。
HRVDA在各种过滤阈值下的速度明显快于Qwen-VL。如表3所示,当两个阈值都设为0.5时,HRVDA将运行时间减少了61%。由于 GPU 内存使用的限制,没有进一步提高分辨率。