为了整篇文章的完整性,给出文章剩余部分的翻译。这篇博客没有公式推导部分。
4 Experiments
我们在所有实验中设置 T = 1000 T=1000 T=1000,以使采样过程中神经网络评估的次数与之前的工作 [53, 55] 相匹配。我们将前向过程的方差设置为从 β 1 = 1 0 − 4 \beta_1=10^{-4} β1=10−4 到 β T = 0.02 \beta_T=0.02 βT=0.02 线性增加的常数。这些常数被选择为相对于缩放到 [ − 1 , 1 ] [-1,1] [−1,1] 的数据较小,确保逆过程和前向过程具有大致相同的函数形式,同时将 x T \mathbf{x}_T xT 的信噪比保持在尽可能小的范围内(在我们的实验中 L T = L_T= LT= D K L ( q ( x T ∣ x 0 ) ∥ N ( 0 , I ) ) ≈ 每维 1 0 − 5 D_{\mathrm{KL}}\left(q\left(\mathbf{x}_T \mid \mathbf{x}_0\right) \| \mathcal{N}(\mathbf{0}, \mathbf{I})\right) \approx 每维 10^{-5} DKL(q(xT∣x0)∥N(0,I))≈每维10−5 比特)。
为了表示逆过程,我们使用一个类似于未掩码 PixelCNN++ [52, 48] 的 U-Net 主干,整个过程中使用组归一化 [66]。参数在时间上是共享的,使用 Transformer 正弦位置嵌入 [60] 指定时间。我们在 16 × 16 16 \times 16 16×16 特征图分辨率上使用自注意力机制 [63, 60]。详情见附录 B。
4.1 Sample quality

表 1 显示了 CIFAR10 上的 Inception 分数、FID 分数和负对数似然(无损代码长度)。我们的 FID 得分为 3.17,我们的无条件模型比文献中的大多数模型(包括类条件模型)实现了更好的样本质量。我们的 FID 分数是根据训练集计算的,这是标准做法;当我们针对测试集进行计算时,得分为 5.24,这仍然优于文献中的许多训练集 FID 得分。
我们发现,使用真实变分下界训练模型在代码长度上比使用简化目标更好,这与预期一致,但后者在样本质量上表现最佳。具体请参见图1中的 CIFAR10 和 CelebA-HQ 256 × 256 256 \times 256 256×256 样本,图3 和 图4 中的 LSUN 256 × 256 256 \times 256 256×256 样本 [71],更多内容见附录 D。

图 3:LSUN 教堂样本。 FID=7.89

图 4:LSUN 卧室样品。 FID=4.90
4.2 Reverse process parameterization and training objective ablation
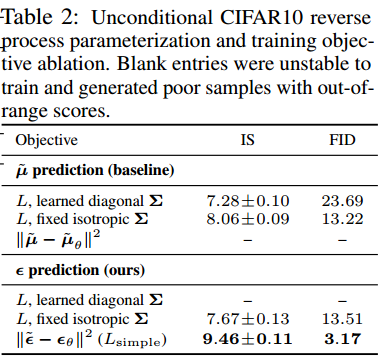
在表2中,我们展示了逆过程参数化和训练目标(第3.2节)对样本质量的影响。我们发现,基线选项预测 μ ~ \tilde{\boldsymbol{\mu}} μ~ 仅在真实变分下界训练时效果良好,而不是在未加权的均方误差上进行训练,这是一种类似于公式(14)的简化目标。我们还发现,通过在变分下界中引入参数化的对角 Σ θ ( x t ) \boldsymbol{\Sigma}_\theta\left(\mathbf{x}_t\right) Σθ(xt) 来学习逆过程方差,会导致训练不稳定和样本质量下降,而固定方差则效果更好。我们提出的预测 ϵ \epsilon ϵ 方法,在使用固定方差的变分下界训练时,表现与预测 μ ~ \tilde{\boldsymbol{\mu}} μ~ 差不多,但在使用我们的简化目标训练时,表现要好得多。
4.3 Progressive coding
表 1 还显示了我们的 CIFAR10 模型的代码长度。训练和测试之间的差距最多为每个维度 0.03 位,这与其他基于可能性的模型报告的差距相当,表明我们的扩散模型没有过拟合(有关最近邻可视化,请参阅附录 D)。尽管如此,虽然我们的无损码长优于基于能量的模型和使用退火重要性采样的分数匹配报告的大估计[11],但它们与其他类型的基于可能性的生成模型[7]不具有竞争力。
由于我们的样本质量依然很高,我们得出结论,扩散模型具有使其成为优秀有损压缩器的归纳偏置。将变分下界项 L 1 + ⋯ + L T L_1+\cdots+L_T L1+⋯+LT 视为码率,将 L 0 L_0 L0 视为失真,我们的 CIFAR10 模型在最高质量样本下的码率为 1.78 \mathbf{1.78} 1.78 bits/dim,失真为 1.97 b i t s / d i m \mathbf{1.97} \mathrm{bits} / \mathrm{dim} 1.97bits/dim,相当于在0到255的范围内均方根误差为0.95。超过一半的无损码长描述了不可察觉的失真。
逐步有损压缩。我们可以通过引入逐步有损编码进一步探讨模型的率失真行为,这种编码形式类似于公式(5):参见算法3和4,它们假设访问某种过程,例如最小随机编码
[
19
,
20
]
[19,20]
[19,20],可以使用大约
D
K
L
(
q
(
x
)
∥
p
(
x
)
)
D_{\mathrm{KL}}(q(\mathbf{x}) \| p(\mathbf{x}))
DKL(q(x)∥p(x)) bits 来传输样本
x
∼
q
(
x
)
\mathbf{x} \sim q(\mathbf{x})
x∼q(x),适用于任何
p
p
p 和
q
q
q 分布,其中只有
p
p
p 是预先提供给接收者的。当应用于
x
0
∼
q
(
x
0
)
\mathbf{x}_0 \sim q\left(\mathbf{x}_0\right)
x0∼q(x0) 时,算法3和4按顺序传输
x
T
,
…
,
x
0
\mathbf{x}_T, \ldots, \mathbf{x}_0
xT,…,x0,使用的总期望码长等于公式(5)。接收者在任何时刻
t
t
t,都有完全可用的部分信息
x
t
\mathbf{x}_t
xt,并可以逐步估计:
x
0
≈
x
^
0
=
(
x
t
−
1
−
α
ˉ
t
ϵ
θ
(
x
t
)
)
/
α
ˉ
t
\mathbf{x}_0 \approx \hat{\mathbf{x}}_0 = \left(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t\right)\right) / \sqrt{\bar{\alpha}_t}
x0≈x^0=(xt−1−αˉtϵθ(xt))/αˉt
根据公式(4)。(随机重构
x
0
∼
p
θ
(
x
0
∣
x
t
)
\mathbf{x}_0 \sim p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_t\right)
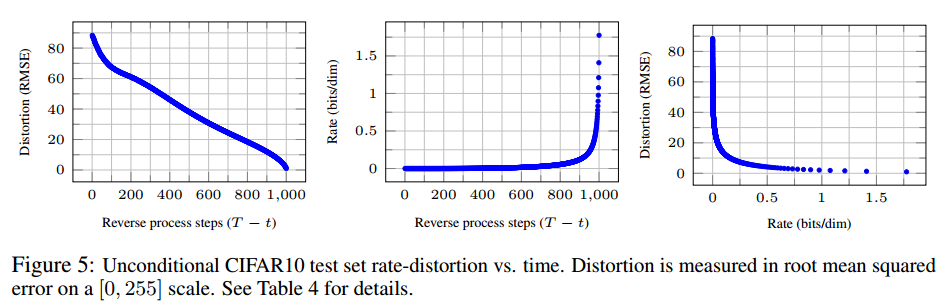
x0∼pθ(x0∣xt) 也是有效的,但我们在此不考虑,因为它使得失真更难评估。)图5展示了在 CIFAR10 测试集上的率失真图。在每个时刻
t
t
t,失真计算为均方根误差
∥
x
0
−
x
^
0
∥
2
/
D
\sqrt{\left\|\mathbf{x}_0 - \hat{\mathbf{x}}_0\right\|^2 / D}
∥x0−x^0∥2/D,码率计算为截至时刻
t
t
t 为止接收到的累积比特数。失真在率失真图的低码率区域急剧下降,这表明大多数比特确实分配给了不可察觉的失真。

渐进生成。我们还进行了渐进无条件生成过程,该过程由随机比特的渐进解压缩组成。换句话说,我们通过使用算法2从逆过程中进行采样来预测逆过程的结果, x ^ 0 \hat{\mathbf{x}}_0 x^0。 图6和图10展示了逆过程中 x ^ 0 \hat{\mathbf{x}}_0 x^0的样本质量。大尺度图像特征首先出现,而细节最后出现。 图7显示了具有各种 t t t值的冻结 x t \mathbf{x}_t xt的随机预测 x 0 ∼ p θ ( x 0 ∣ x t ) \mathbf{x}_0 \sim p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_t\right) x0∼pθ(x0∣xt)。当 t t t较小时,除了细节之外的所有内容都被保留,当 t t t较大时,只有大尺度特征被保留。也许这些是概念压缩的提示[18]。


注意,可变分界(5)可以重写为:
L
=
D
K
L
(
q
(
x
T
)
∥
p
(
x
T
)
)
+
E
q
[
∑
t
≥
1
D
K
L
(
q
(
x
t
−
1
∣
x
t
)
∥
p
θ
(
x
t
−
1
∣
x
t
)
)
]
+
H
(
x
0
)
(
16
)
L=D_{\mathrm{KL}}\left(q\left(\mathbf{x}_T\right) \| p\left(\mathbf{x}_T\right)\right)+\mathbb{E}_q\left[\sum_{t \geq 1} D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right) \| p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)\right)\right]+H\left(\mathbf{x}_0\right) \quad(16)
L=DKL(q(xT)∥p(xT))+Eq[t≥1∑DKL(q(xt−1∣xt)∥pθ(xt−1∣xt))]+H(x0)(16)
(见附录A推导)。现在考虑将扩散过程长度
T
T
T设置为数据的维度,定义正向过程使得
q
(
x
t
∣
x
0
)
q\left(\mathbf{x}_t \mid \mathbf{x}_0\right)
q(xt∣x0)将所有概率质量放在
x
0
\mathbf{x}_0
x0上,其中前
t
t
t个坐标被掩盖(即
q
(
x
t
∣
x
t
−
1
)
q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right)
q(xt∣xt−1)掩盖第
t
t
t个坐标),将
p
(
x
T
)
p\left(\mathbf{x}_T\right)
p(xT)设置为将所有质量放在空白图像上,并且为了论证的目的,假设
p
θ
(
x
t
−
1
∣
x
t
)
p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)
pθ(xt−1∣xt)是一个完全表达式的条件分布。通过这些选择,
D
K
L
(
q
(
x
T
)
∥
p
(
x
T
)
)
=
0
D_{\mathrm{KL}}\left(q\left(\mathbf{x}_T\right) \| p\left(\mathbf{x}_T\right)\right)=0
DKL(q(xT)∥p(xT))=0,并且最小化
D
K
L
(
q
(
x
t
−
1
∣
x
t
)
∥
p
θ
(
x
t
−
1
∣
x
t
)
)
D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right) \| p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)\right)
DKL(q(xt−1∣xt)∥pθ(xt−1∣xt))会训练
p
θ
p_\theta
pθ以不改变坐标
t
+
1
,
…
,
T
t+1, \ldots, T
t+1,…,T并且预测在给定
t
+
1
,
…
,
T
t+1, \ldots, T
t+1,…,T的情况下第
t
t
t个坐标。因此,使用这种特定扩散来训练
p
θ
p_\theta
pθ就是在训练一个自回归模型。
因此,我们可以将高斯扩散模型(2)解释为一种具有广义位排序的自回归模型,这种位排序无法通过重新排列数据坐标来表达。先前的研究表明,这种重新排序会引入对样本质量有影响的归纳偏差,因此我们推测高斯扩散模型具有类似的作用,也许效果更好,因为与掩盖噪声相比,高斯噪声可能更自然地添加到图像中。此外,高斯扩散长度不限于等于数据维度;例如,我们使用 T = 1000 T=1000 T=1000,这比我们实验中 32 × 32 × 3 32 \times 32 \times 3 32×32×3或 256 × 256 × 3 256 \times 256 \times 3 256×256×3图像的维度要小。高斯扩散可以缩短以实现快速采样,或者延长以实现模型的表现力。
4.4 Interpolation
我们可以在潜空间中使用 q q q 作为随机编码器插值源图像 x 0 , x 0 ′ ∼ q ( x 0 ) \mathbf{x}_0, \mathbf{x}_0^{\prime} \sim q\left(\mathbf{x}_0\right) x0,x0′∼q(x0),得到 x t , x t ′ ∼ q ( x t ∣ x 0 ) \mathbf{x}_t, \mathbf{x}_t^{\prime} \sim q\left(\mathbf{x}_t \mid \mathbf{x}_0\right) xt,xt′∼q(xt∣x0),然后通过逆过程将线性插值的潜在 x ‾ t = ( 1 − λ ) x 0 + λ x 0 ′ \overline{\mathbf{x}}_t=(1-\lambda) \mathbf{x}_0+\lambda \mathbf{x}_0^{\prime} xt=(1−λ)x0+λx0′ 解码成图像空间,即 x ‾ 0 ∼ p ( x 0 ∣ x ‾ t ) \overline{\mathbf{x}}_0 \sim p\left(\mathbf{x}_0 \mid \overline{\mathbf{x}}_t\right) x0∼p(x0∣xt)。实际上,我们使用逆过程来消除线性插值源图像的破坏版本,如图8(左侧)所示。我们固定了不同 λ \lambda λ 值的噪声,因此 x t \mathbf{x}_t xt 和 x t ′ \mathbf{x}_t^{\prime} xt′ 保持不变。图8(右侧)显示了 CelebA-HQ 256 × 256 256 \times 256 256×256 原始图像 ( t = 500 ) (t=500) (t=500) 的插值和重建。逆过程产生了高质量的重建图像,以及在姿势、肤色、发型、表情和背景等属性上平滑变化的合理插值,但不包括眼镜。较大的 t t t 导致更粗糙和更多样化的插值,在 t = 1000 t=1000 t=1000 时产生新样本(附录图9)。

5 Related Work
尽管扩散模型可能类似于流 [ 9 , 46 , 10 , 32 , 5 , 16 , 23 ] [9,46,10,32,5,16,23] [9,46,10,32,5,16,23]和变分自编码器 [ 33 , 47 , 37 ] [33,47,37] [33,47,37],但扩散模型设计为 q q q没有参数,顶层潜变量 x T \mathbf{x}_T xT与数据 x 0 \mathbf{x}_0 x0的互信息几乎为零。我们的 ϵ \epsilon ϵ-prediction逆过程参数化建立了扩散模型与在多个噪声水平上使用退火Langevin动力学进行采样的去噪分数匹配之间的联系[55,56]。然而,扩散模型允许直接评估对数似然,训练过程明确地使用变分推断训练Langevin动力学采样器(详情见附录C)。该联系还有反向推论,即某种加权形式的去噪分数匹配与通过变分推断训练类似Langevin采样器是相同的。学习马尔可夫链的转移算子的其他方法包括注入训练[2]、变分回推[15]、生成随机网络[1]等 [ 50 , 54 , 36 , 42 , 35 , 65 ] [50,54,36,42,35,65] [50,54,36,42,35,65]。
由于知道得分匹配与基于能量的建模之间的联系,我们的工作可能对其他关于基于能量的模型的最新研究 [ 67 − 69 , 12 , 70 , 13 , 11 , 41 , 17 , 8 ] [67-69,12,70,13,11,41,17,8] [67−69,12,70,13,11,41,17,8]具有影响。我们的速率失真曲线是在一个变分界评估中随时间计算的,这让人联想到在一个退火重要性采样运行中可以根据失真惩罚计算速率失真曲线[24]。我们的渐进解码论点可以在卷积DRAW和相关模型 [ 18 , 40 ] [18,40] [18,40]中看到,并且可能导致更一般的设计用于自回归模型的子尺度排序或采样策略 [ 38 , 64 ] [38,64] [38,64]。
6 Conclusion
我们使用扩散模型提供了高质量的图像样本,并且我们发现了扩散模型和变分推理之间的联系,用于训练马尔可夫链、去噪分数匹配和退火朗之万动力学(以及扩展的基于能量的模型)、自回归模型和渐进有损模型压缩。由于扩散模型似乎对图像数据具有出色的归纳偏差,因此我们期待研究它们在其他数据模式中的实用性以及作为其他类型的生成模型和机器学习系统的组件。
Broader Impact
我们在扩散模型方面的工作与其他类型深度生成模型的现有工作具有相似的范围,例如改善 GAN、流、自回归模型等样本质量的努力。我们的论文代表了使扩散模型成为该技术系列中普遍有用的工具的进展,因此它可能有助于放大生成模型已经(并将)对更广泛的世界产生的影响。
不幸的是,有许多众所周知的生成模型的恶意使用。样本生成技术可用于出于政治目的制作知名人物的虚假图像和视频。虽然假图像是在软件工具可用之前很久就手动创建的,但像我们这样的生成模型使这个过程变得更容易。幸运的是,CNN 生成的图像目前存在允许检测的细微缺陷[62],但生成模型的改进可能会使检测变得更加困难。生成模型还反映了训练它们的数据集中的偏差。由于许多大型数据集是通过自动化系统从互联网收集的,因此很难消除这些偏差,尤其是当图像未标记时。如果在这些数据集上训练的生成模型的样本在整个互联网上激增,那么这些偏见只会进一步强化。
另一方面,扩散模型可能对数据压缩有用,随着数据分辨率的提高和全球互联网流量的增加,这对于确保广大受众访问互联网可能至关重要。我们的工作可能有助于对未标记的原始数据进行表征学习,以实现从图像分类到强化学习的大量下游任务,并且扩散模型也可能适用于艺术、摄影和音乐的创造性用途。