Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强
总时长 104:45:00 共408P
此文章包含第364p-第p365的内容
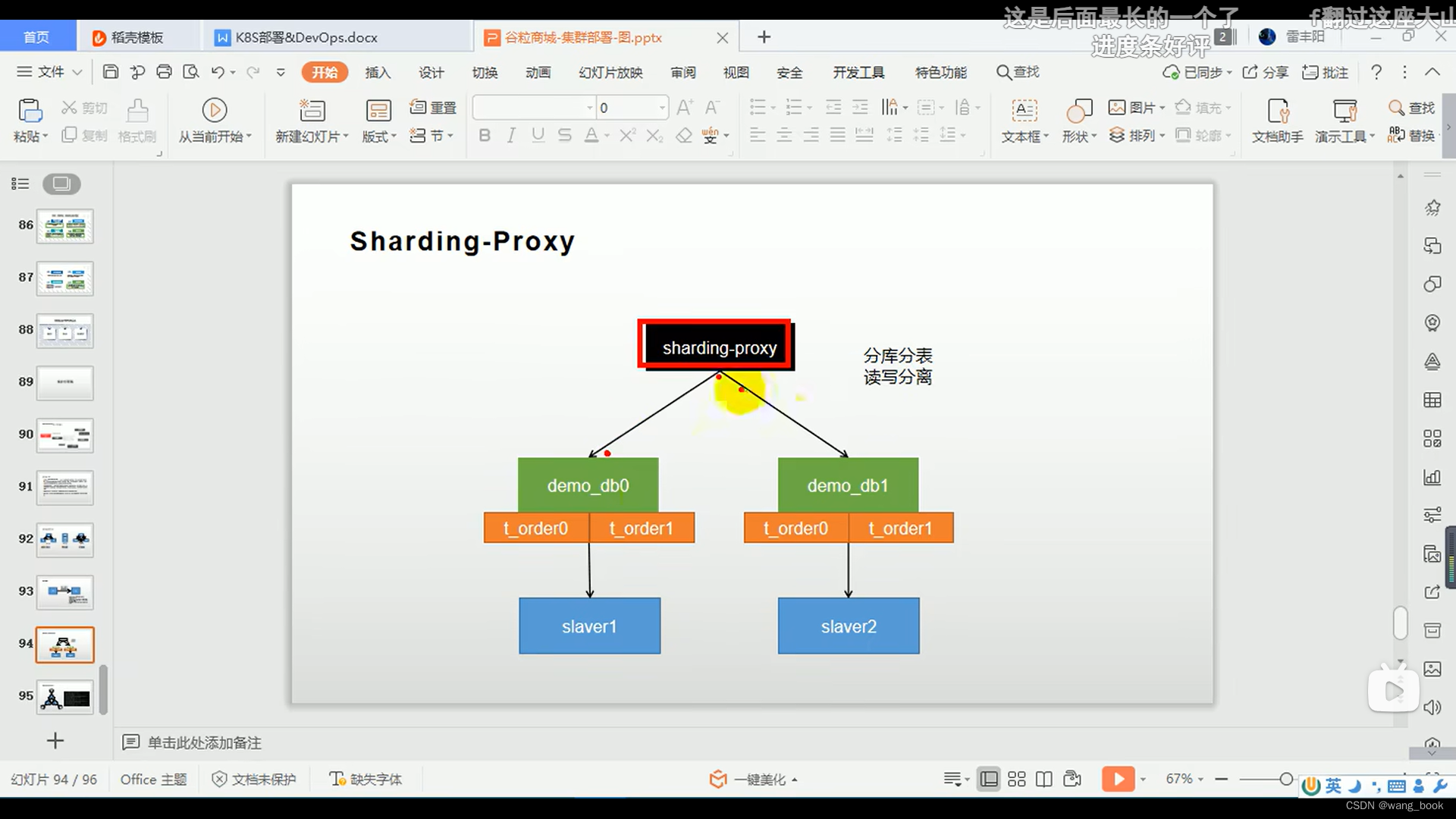
分库分表
这种基本无人用
shardingSphere
shard(碎片)
sphere (球)
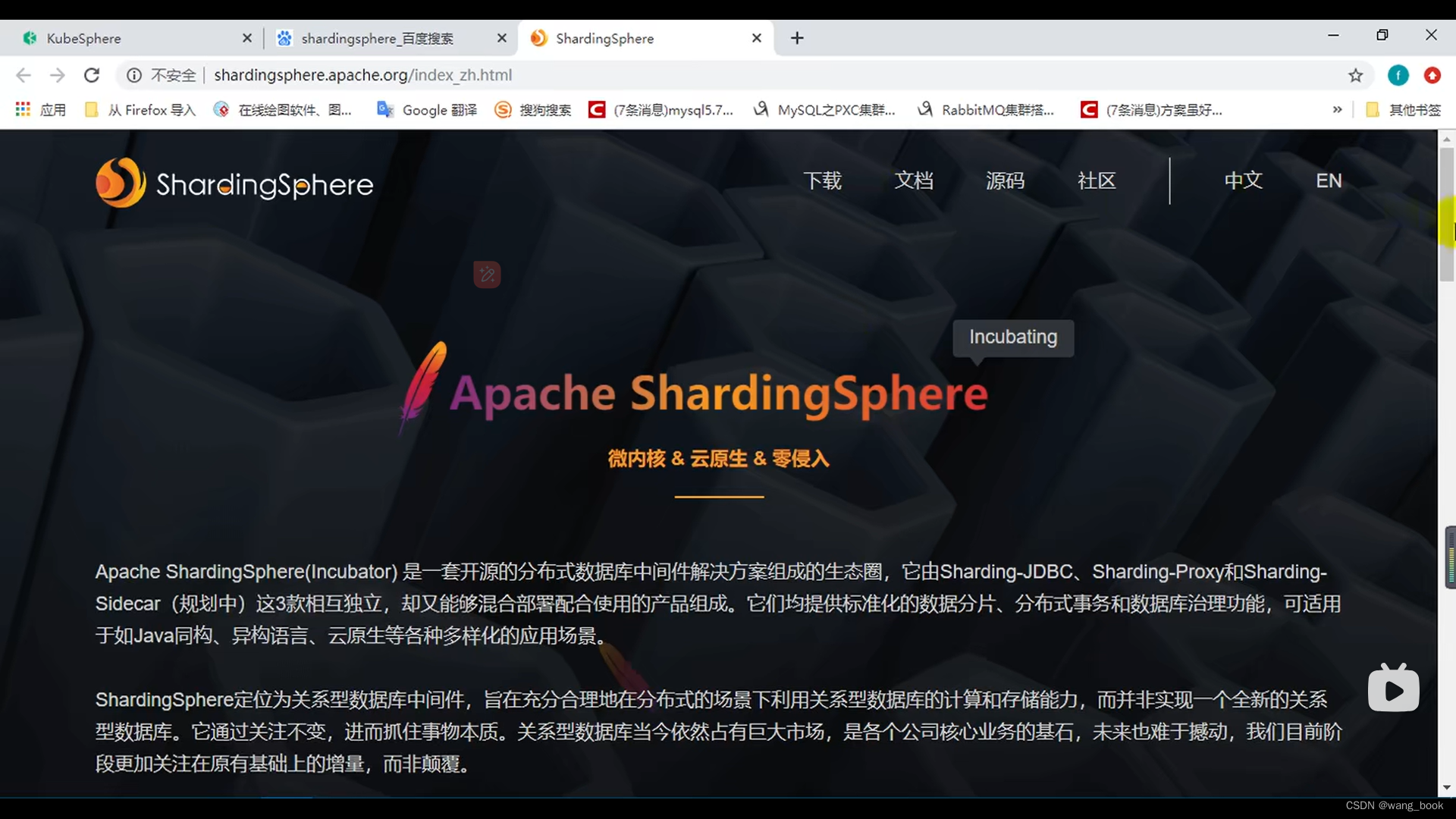
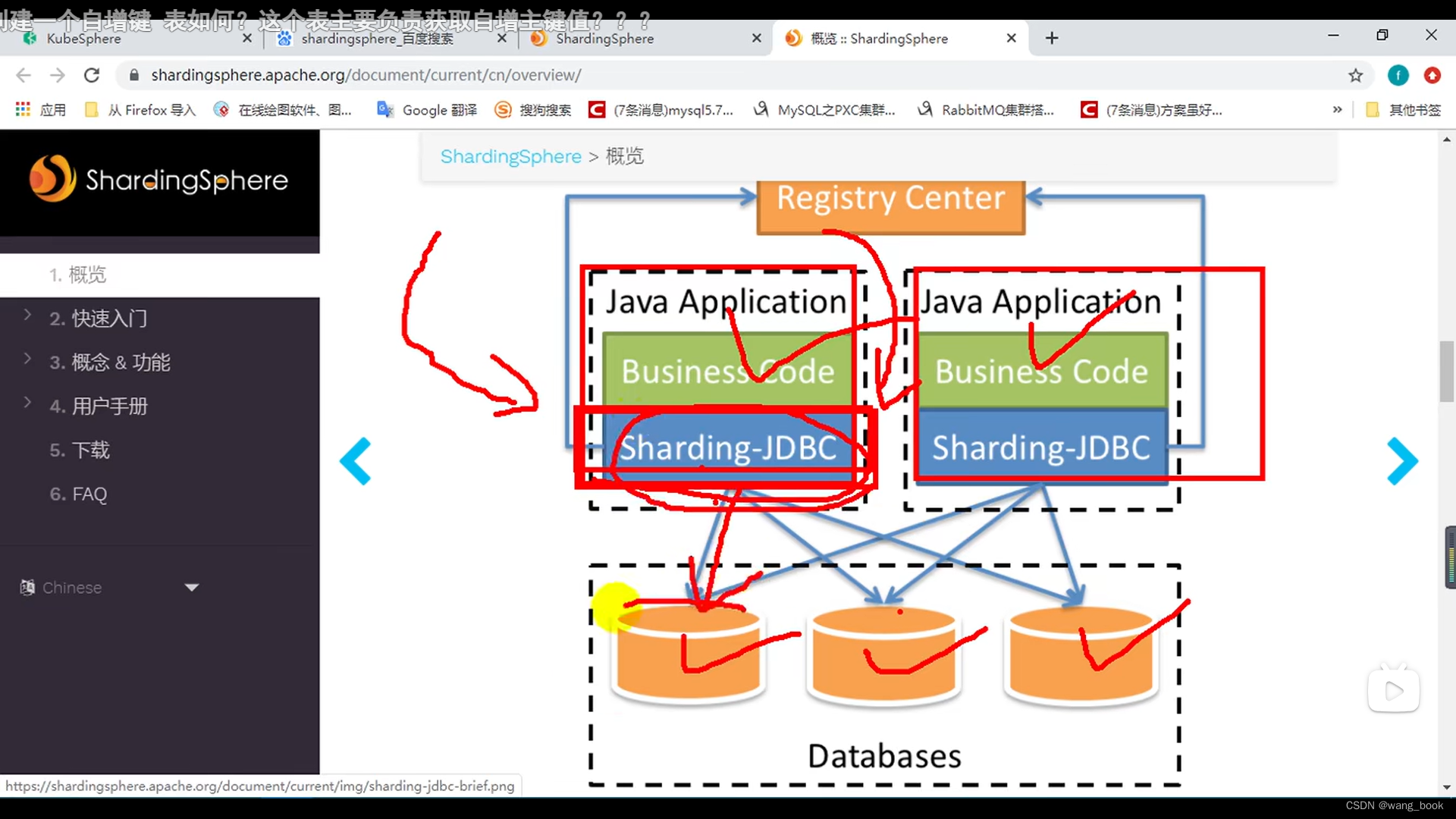
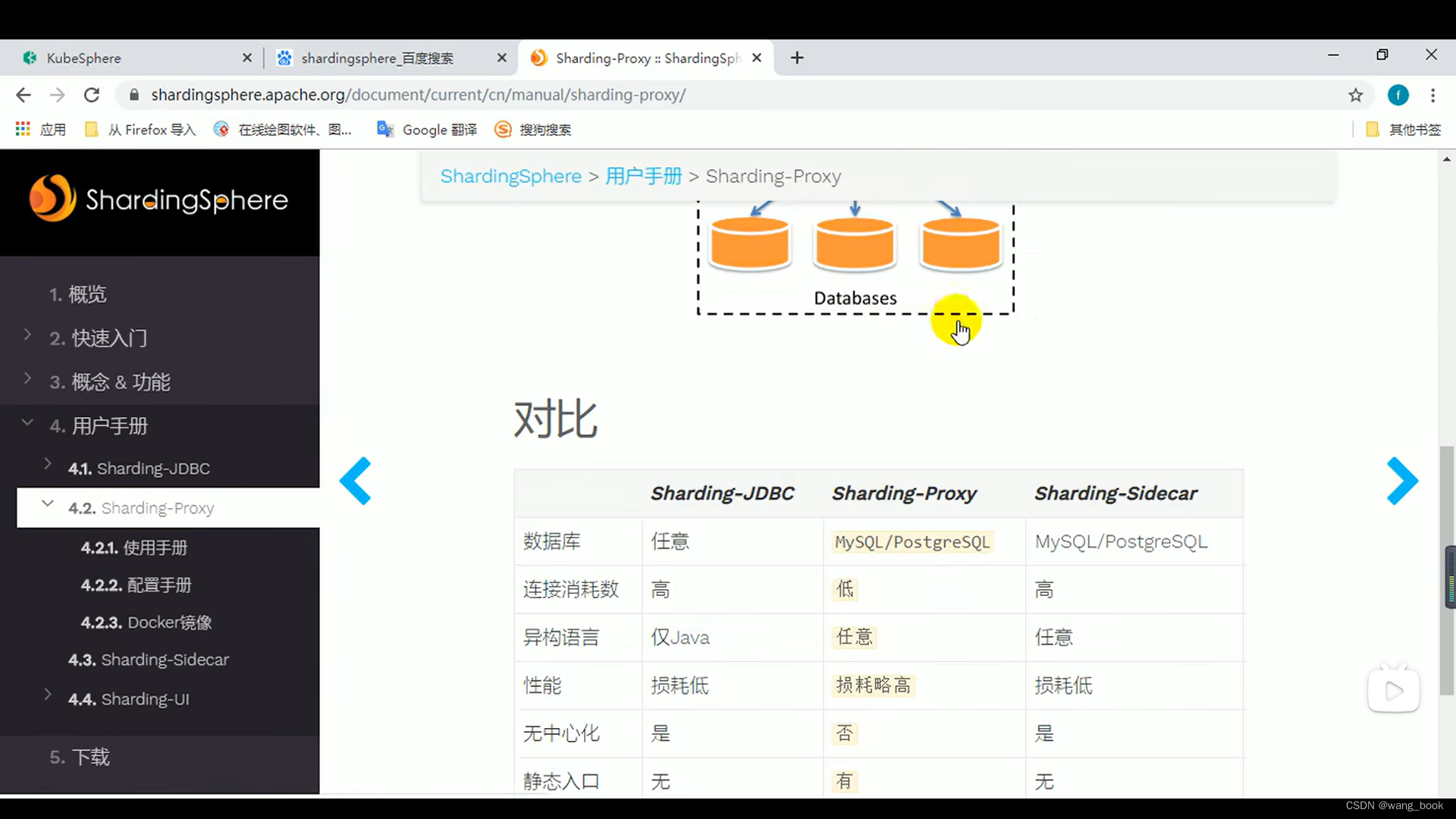
sharding-JDBC
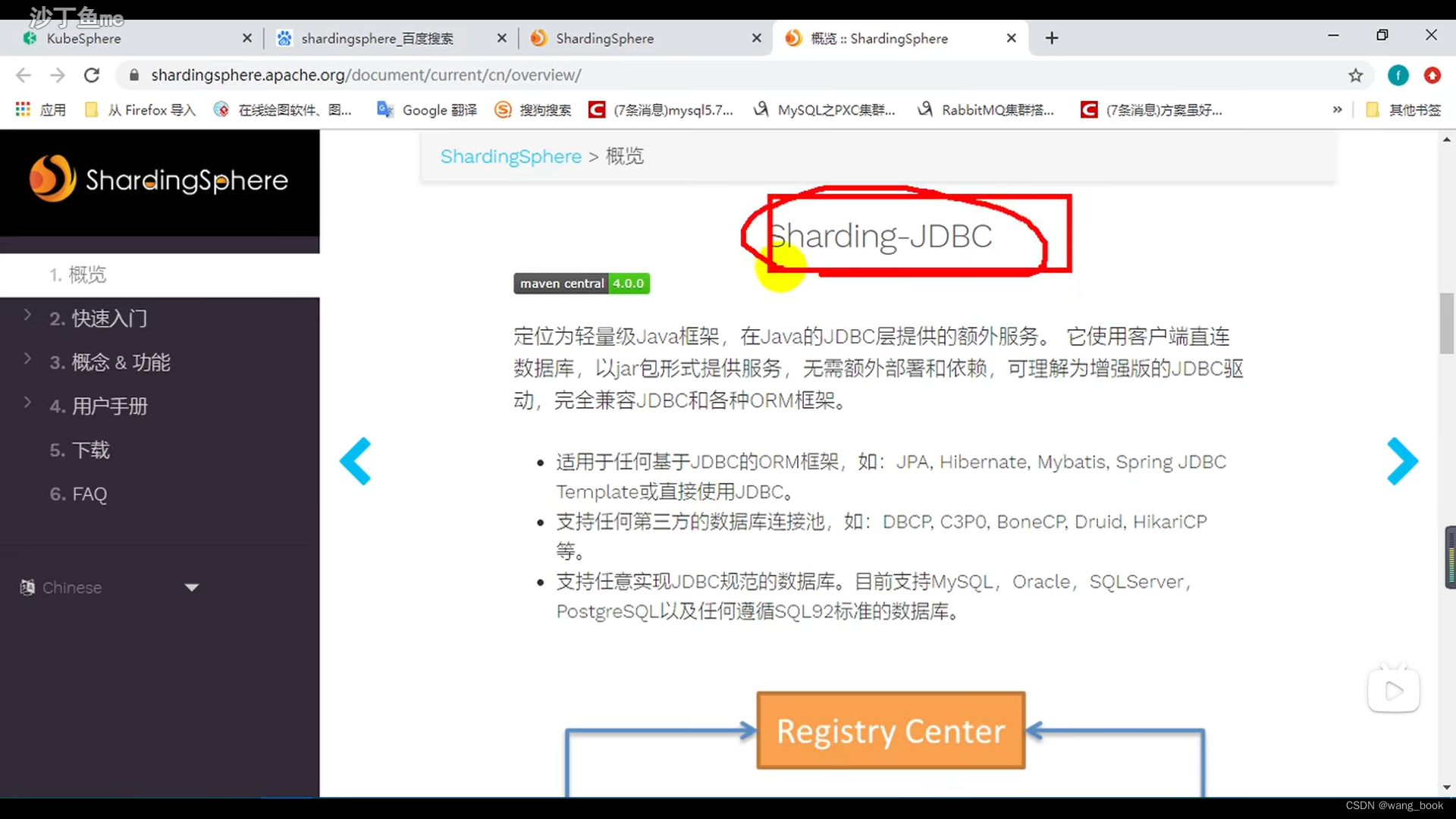
sharding-JDBC 继承我们的连接池 ,
使用方法 导入依赖 然后配置我们的分库分表策略就行
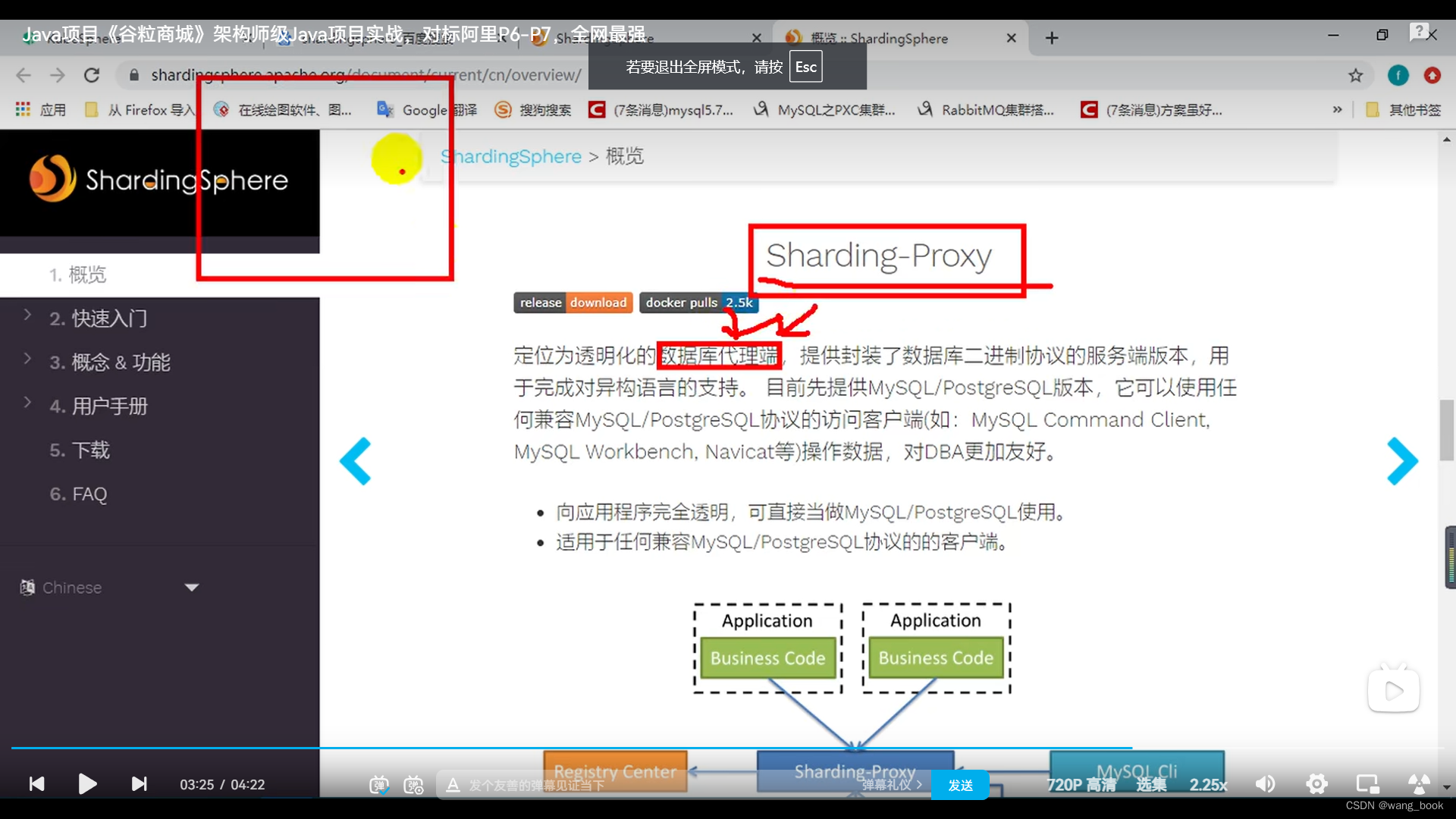
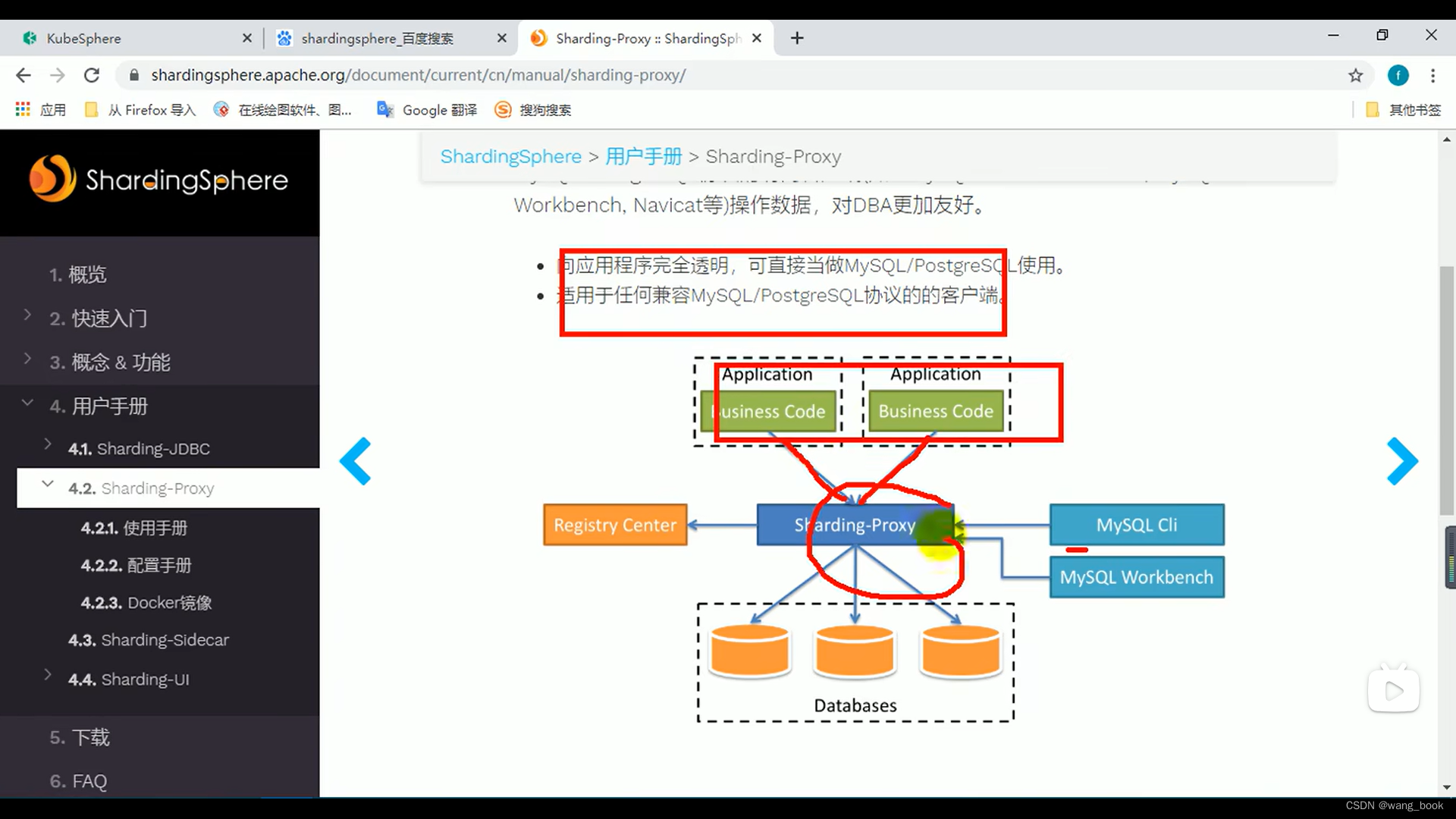
sharding-proxy
代理端
假装自己是一个数据库 我们的业务代码连向它就行 它相当于一个中间件来连接数据库 ,在它的内部来进行分库分表
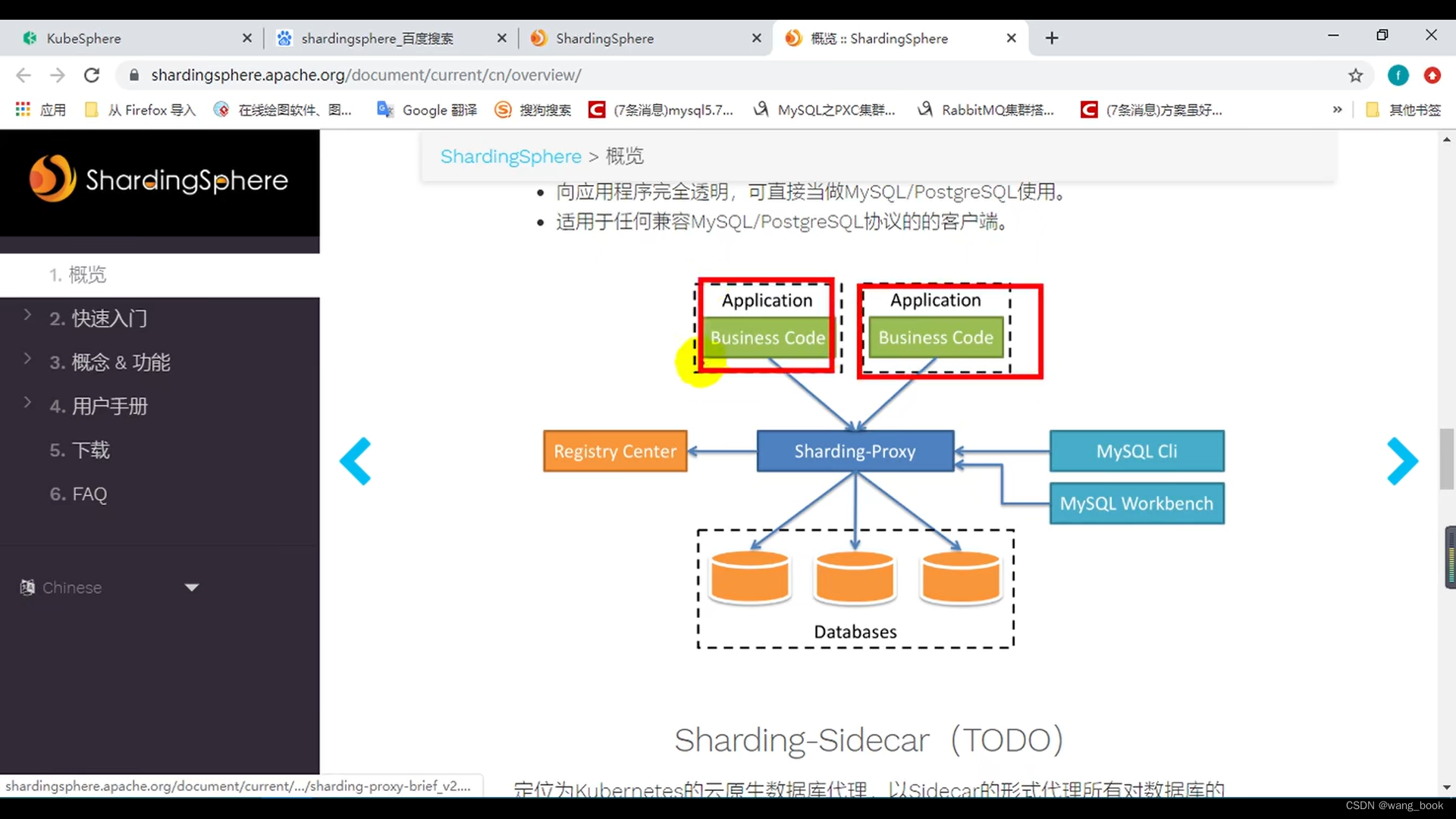
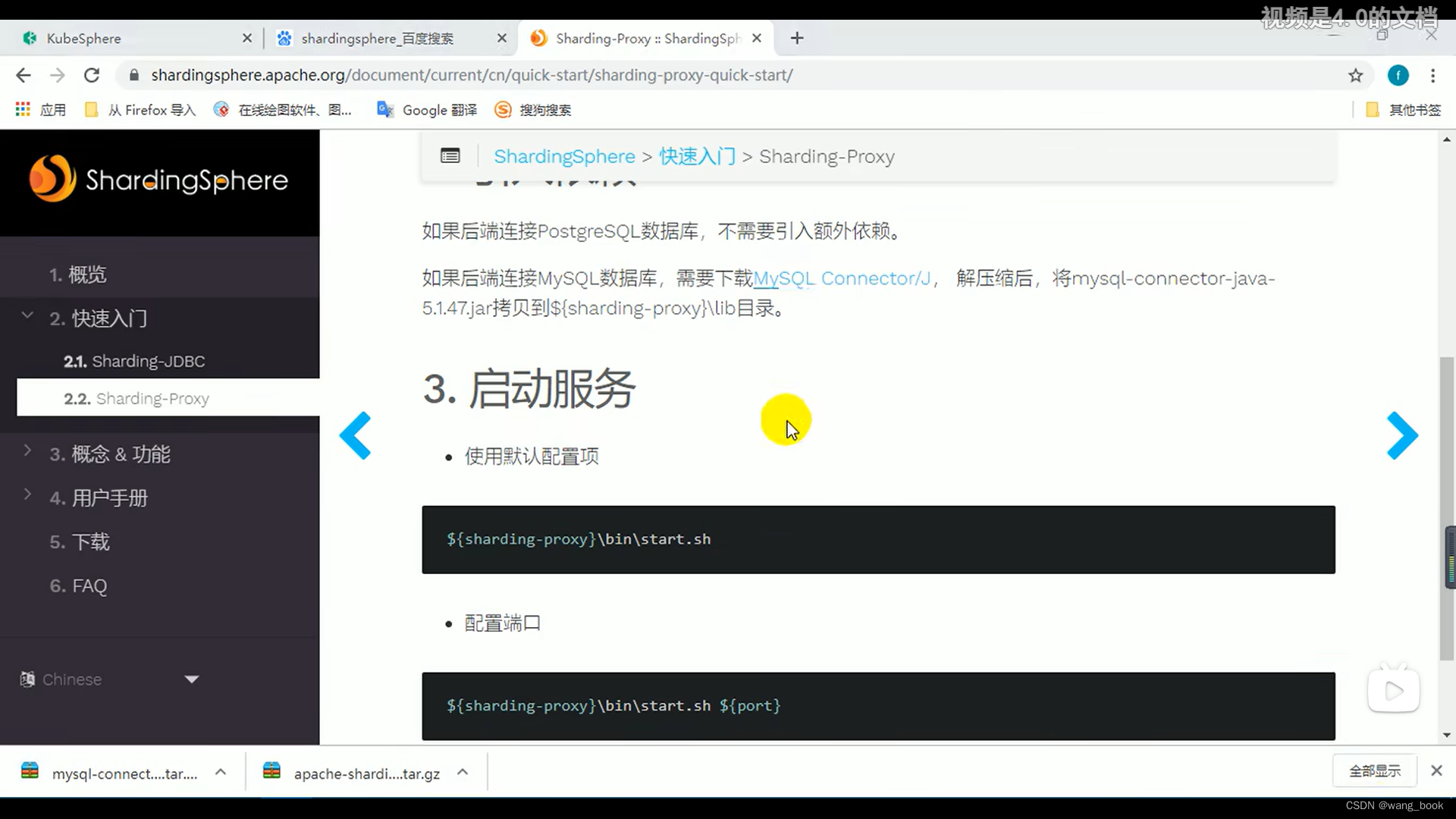
使用proxy
下载压缩包
分片规则
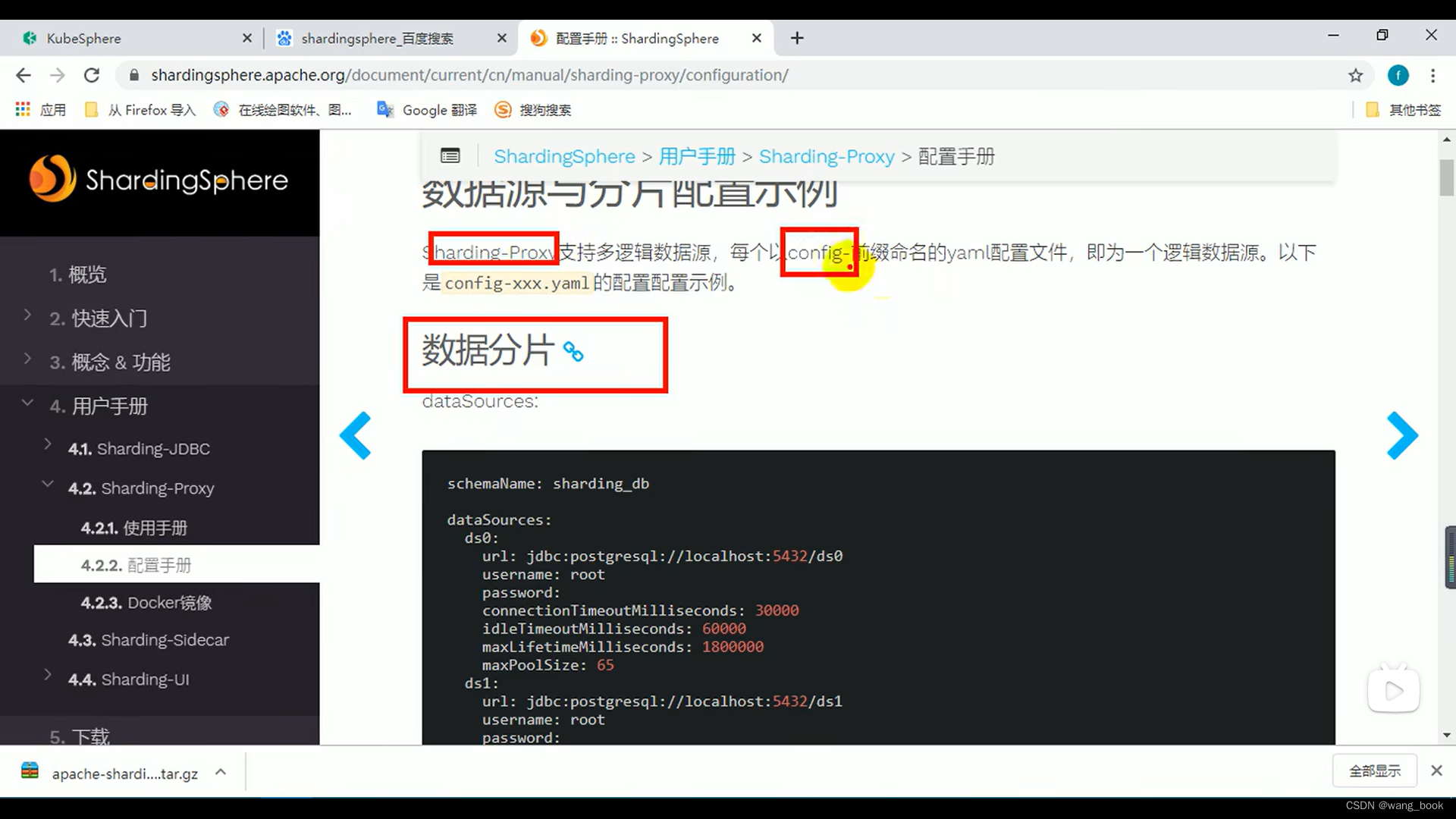
定义了两个数据源
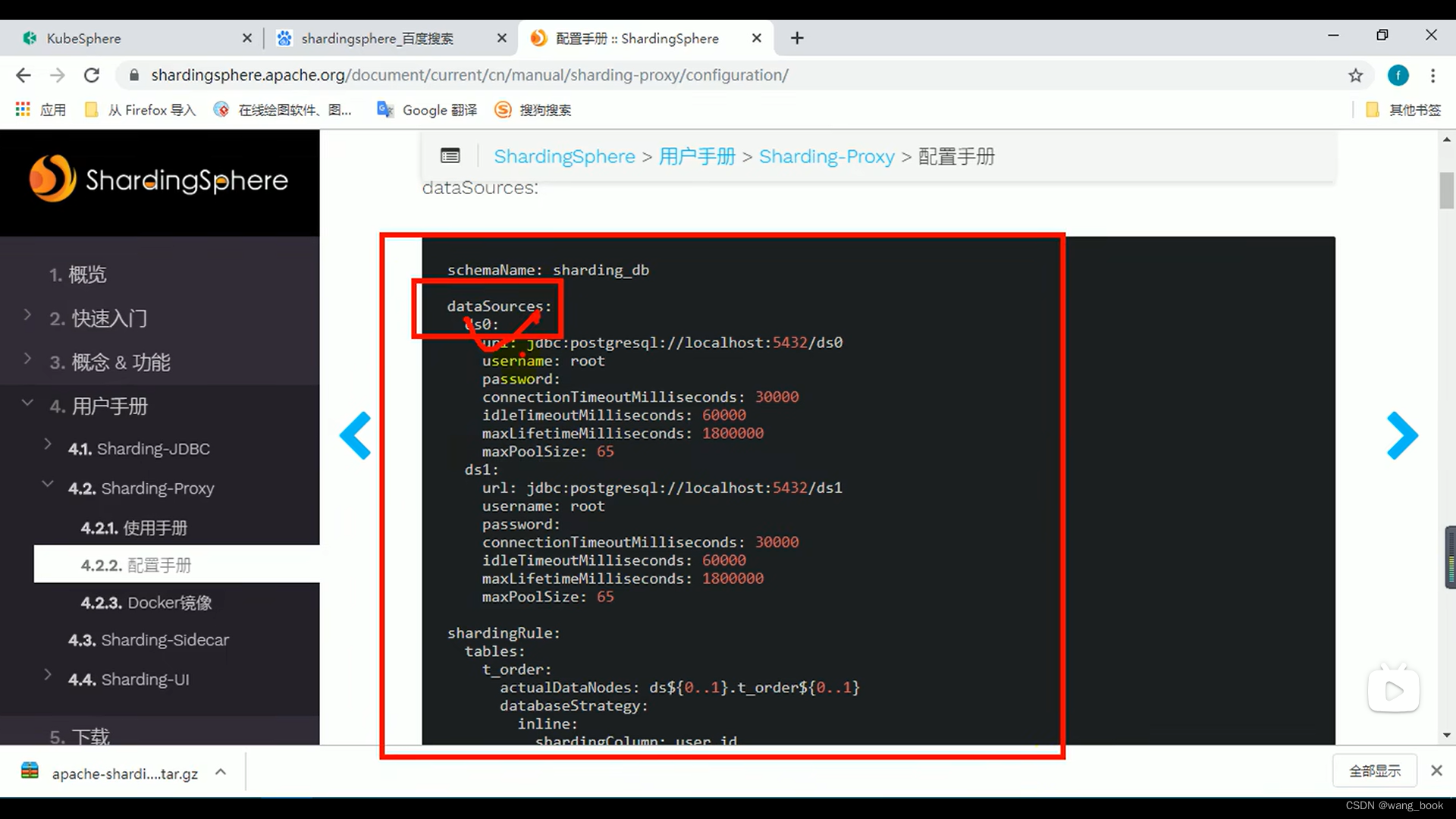
定义分库分表规则
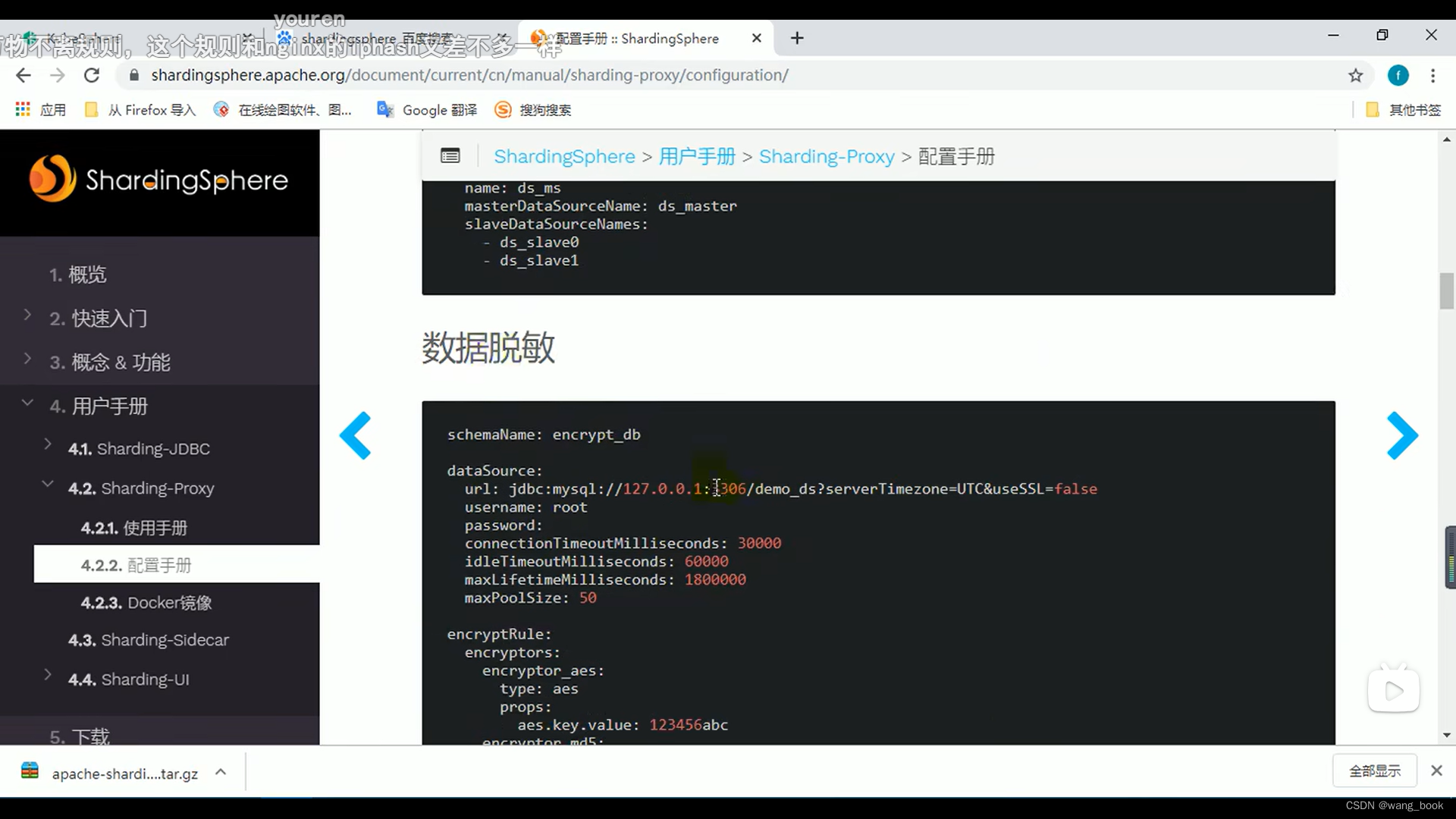
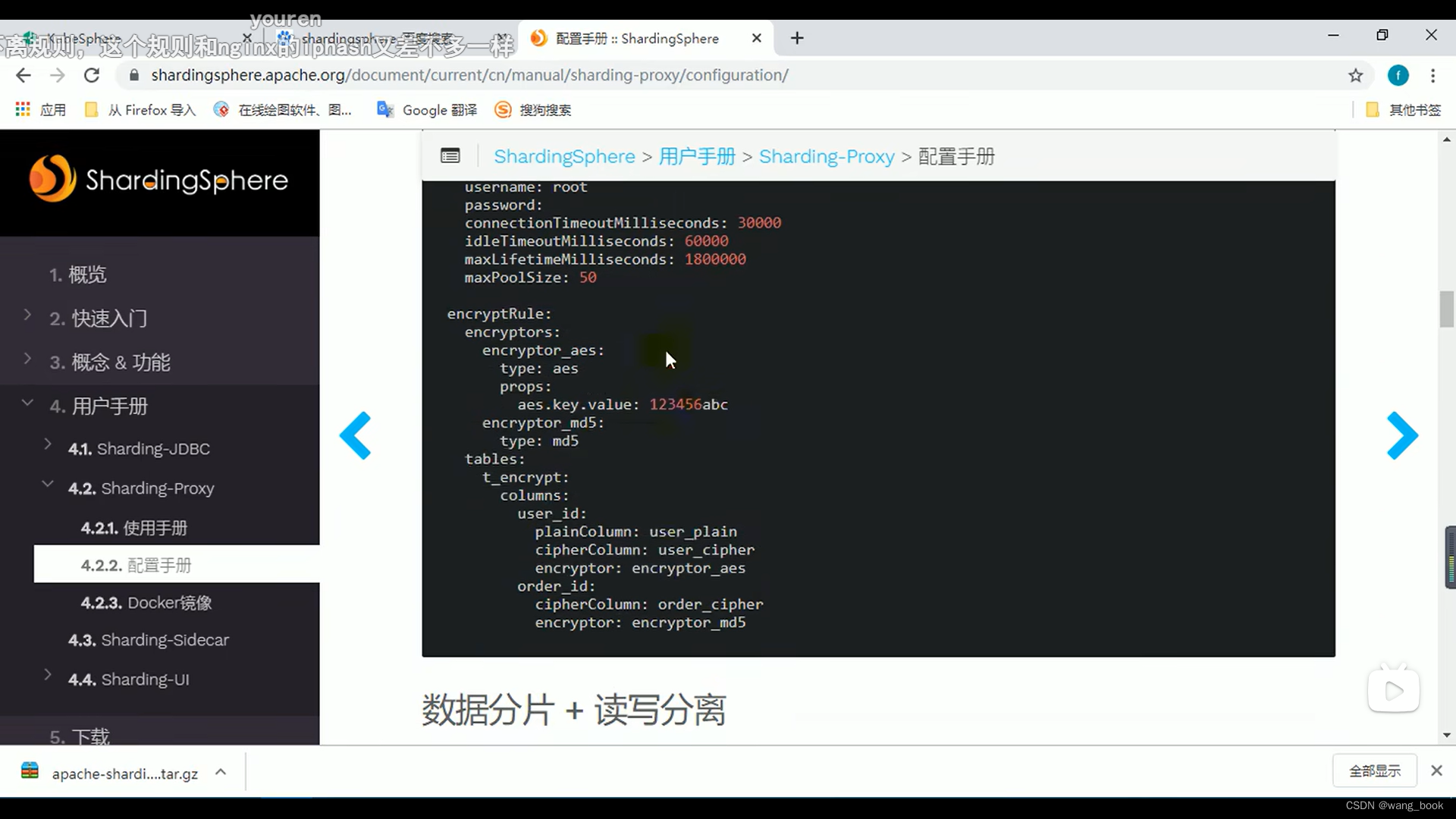
还支持数据脱敏
数据分片和读写分离
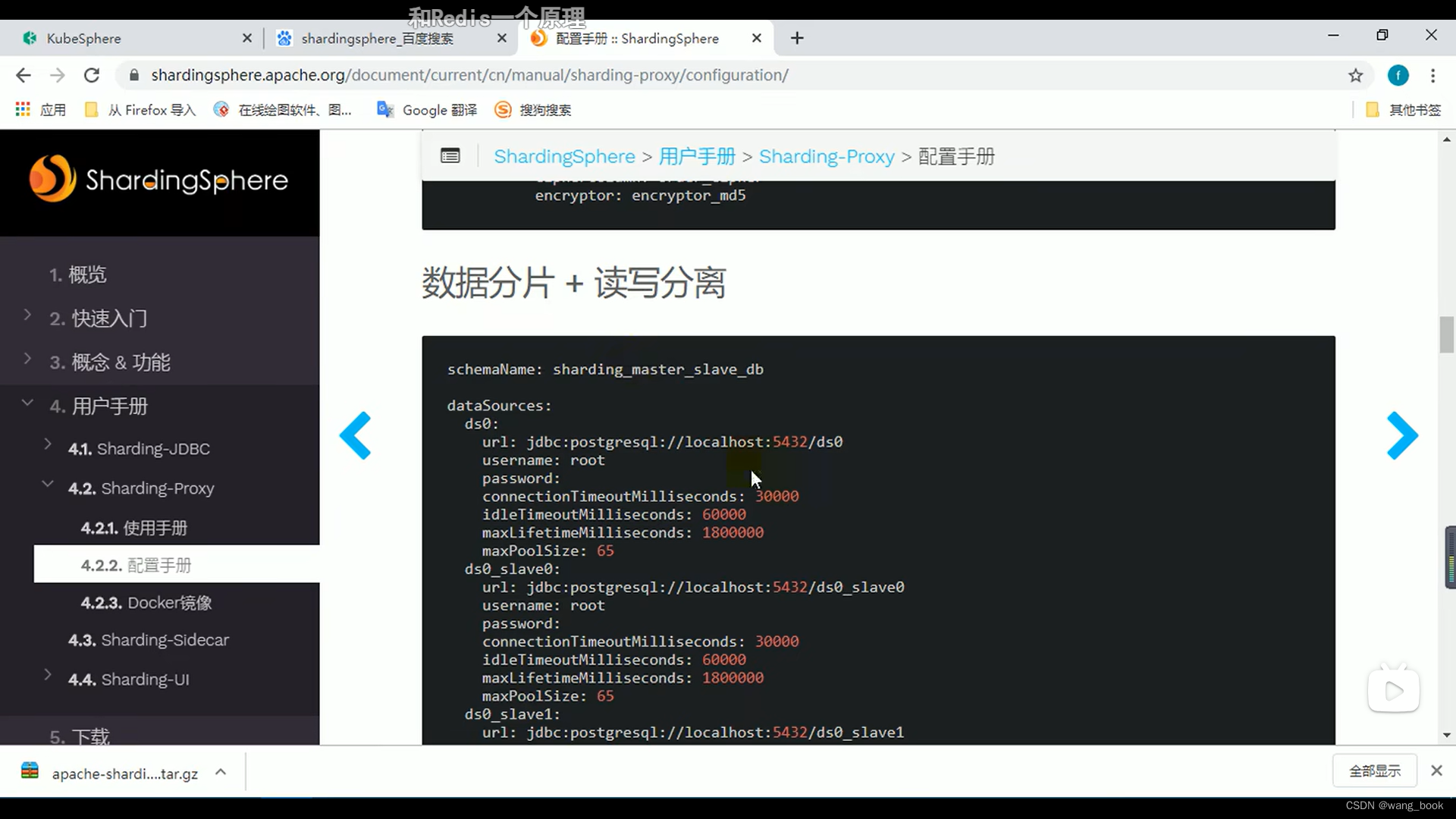
实例配置文件
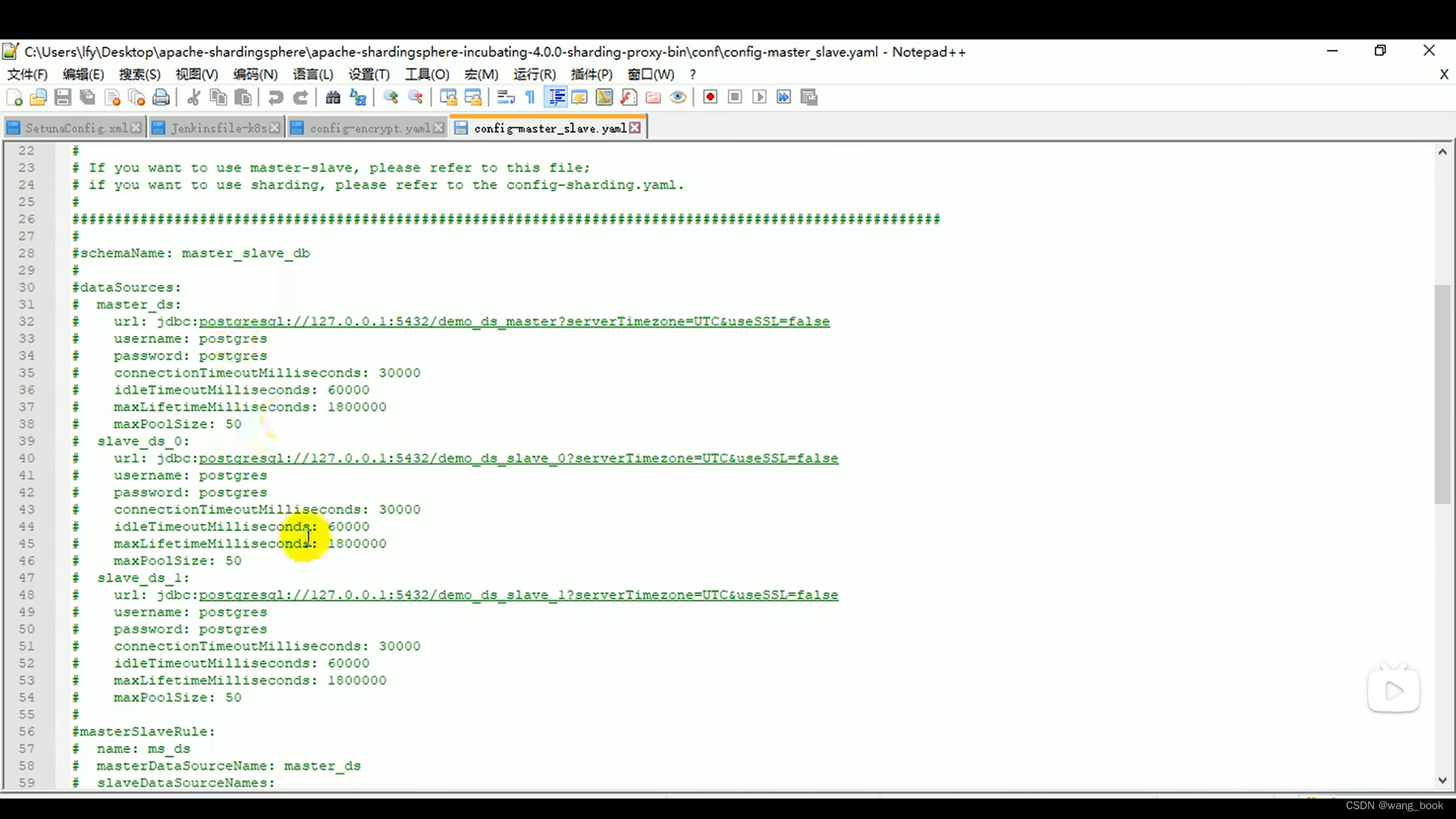
读写分离配置
*
我们使用mysql
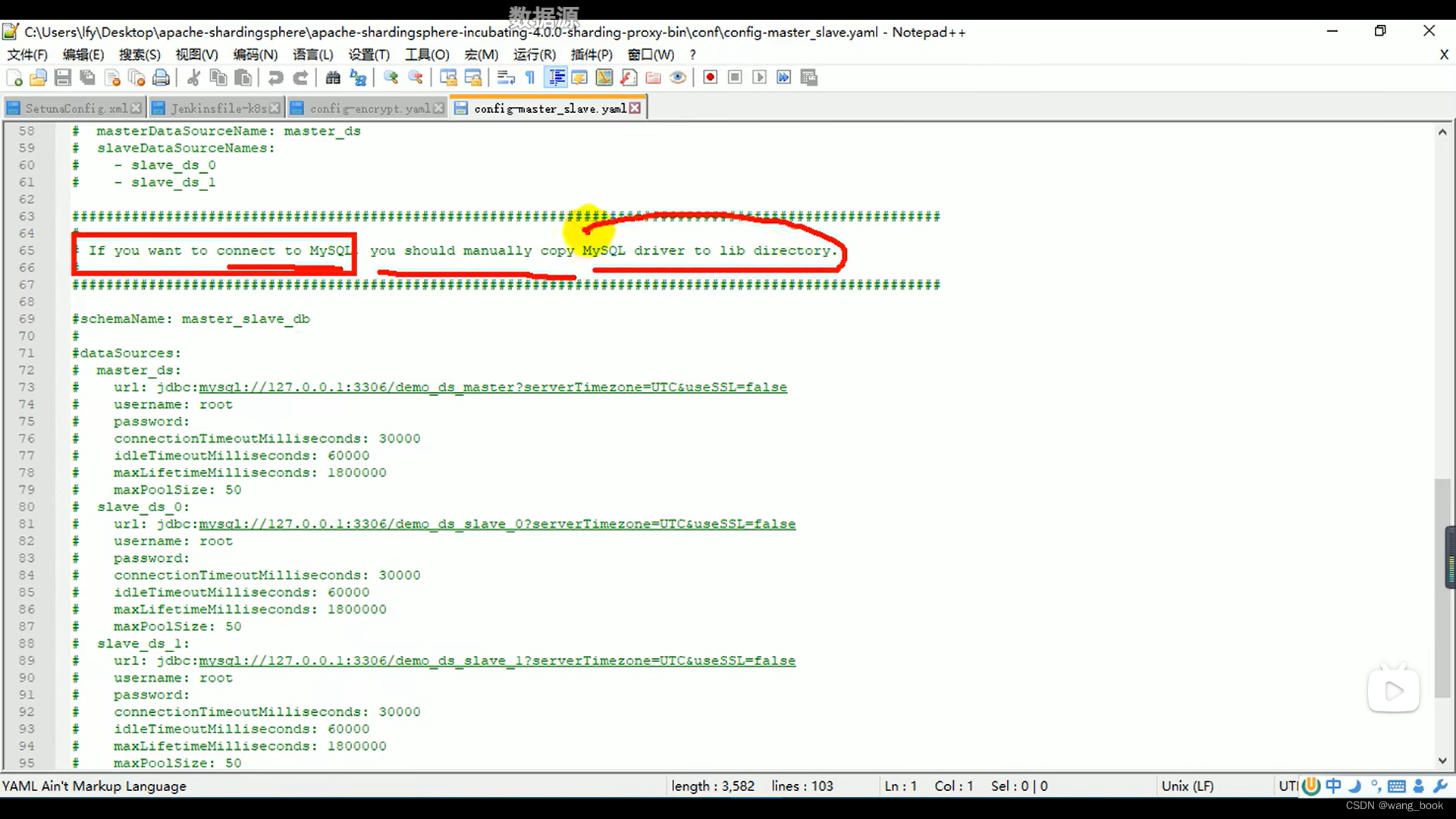
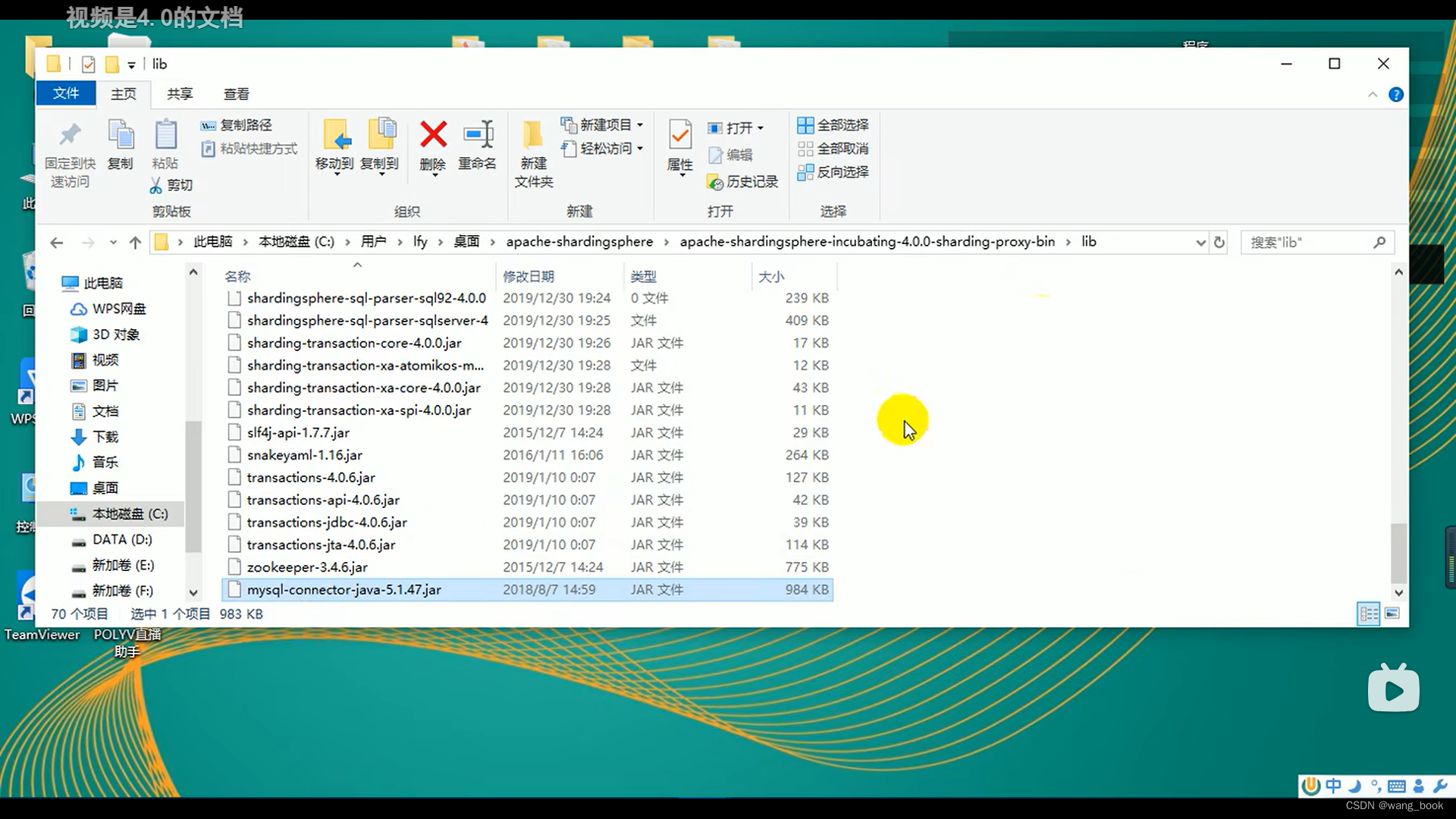
下载mysql驱动,复制到lib文件夹下
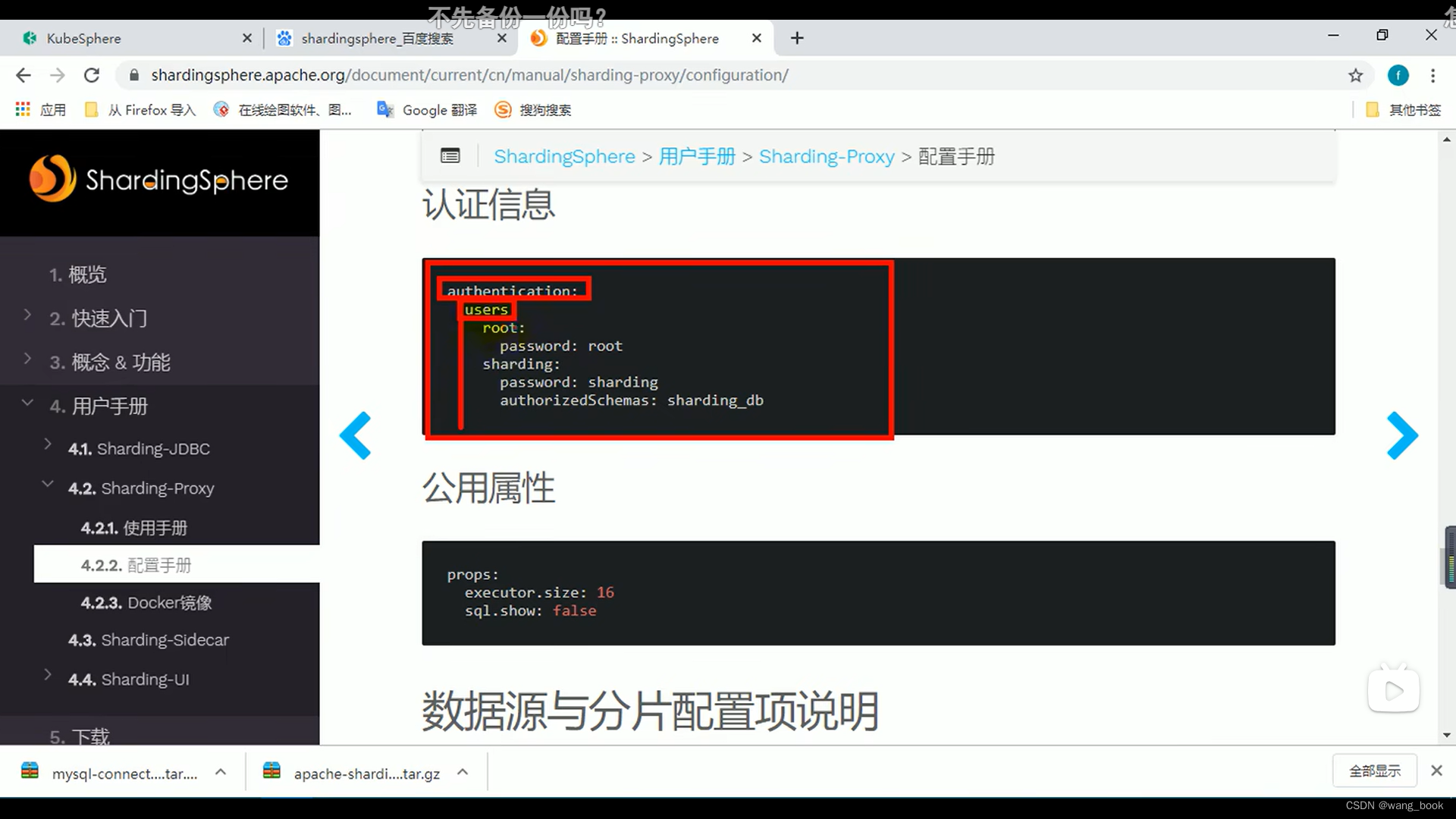
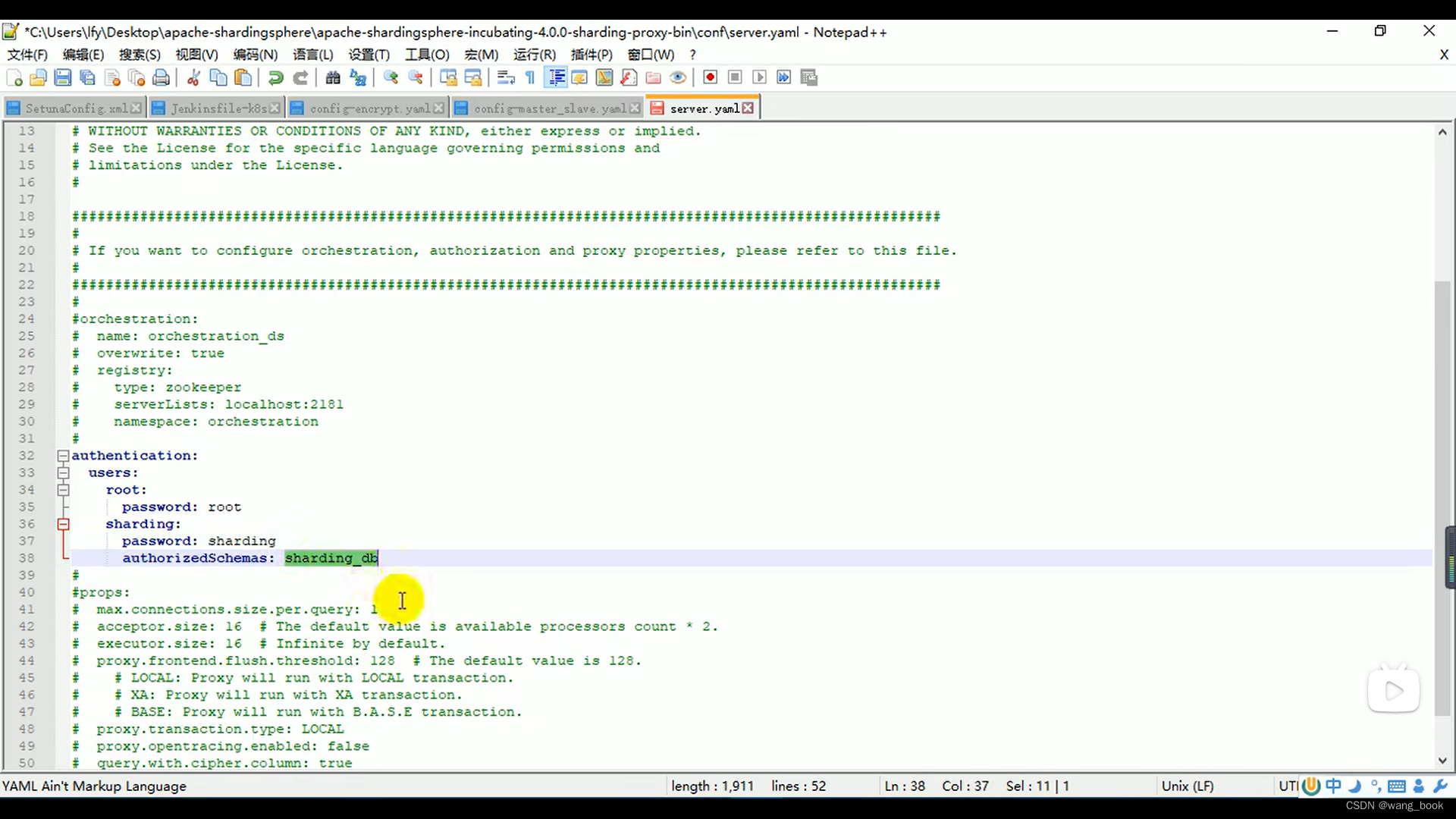
配置认证信息
还可以配置一些属性
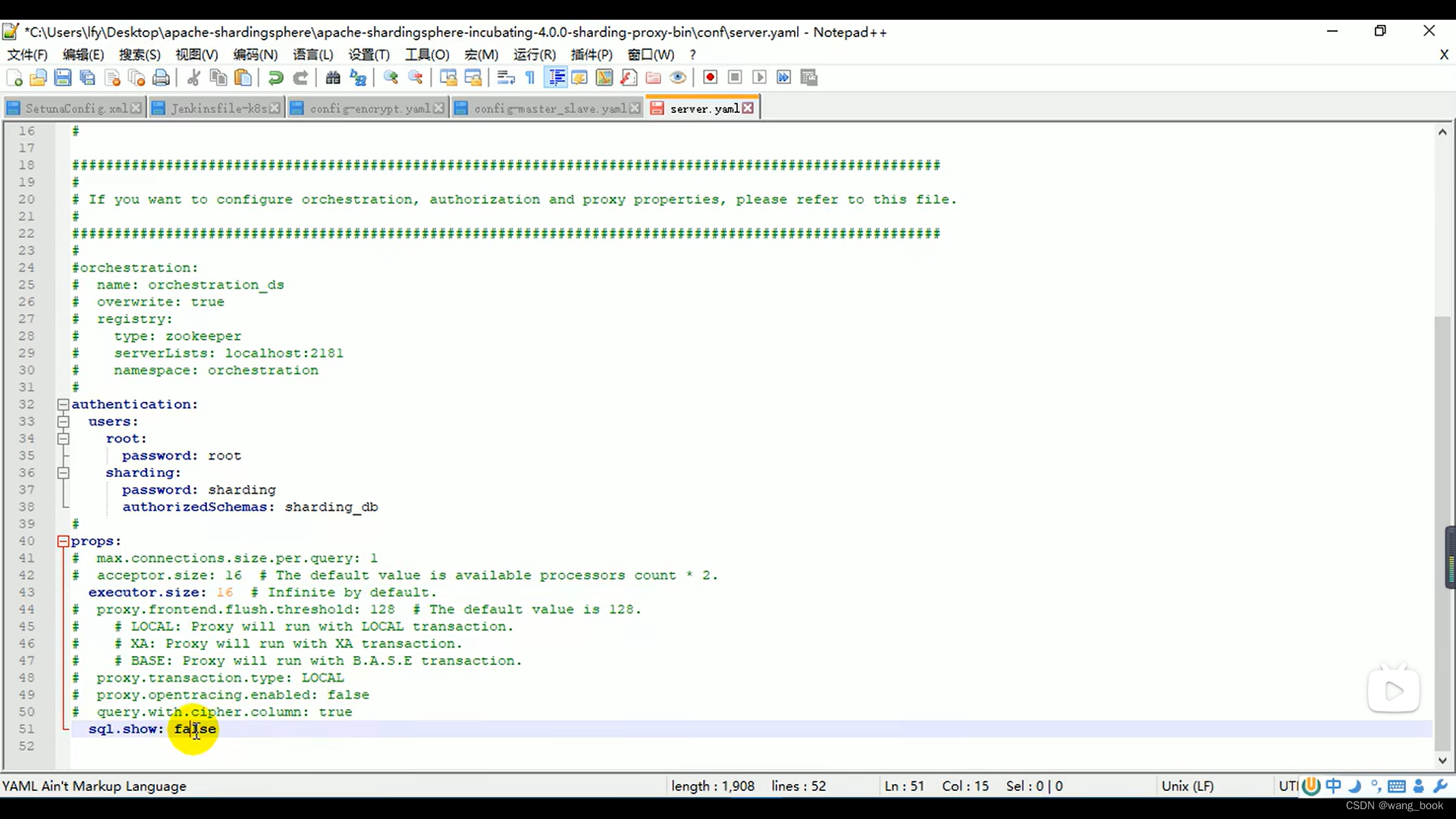
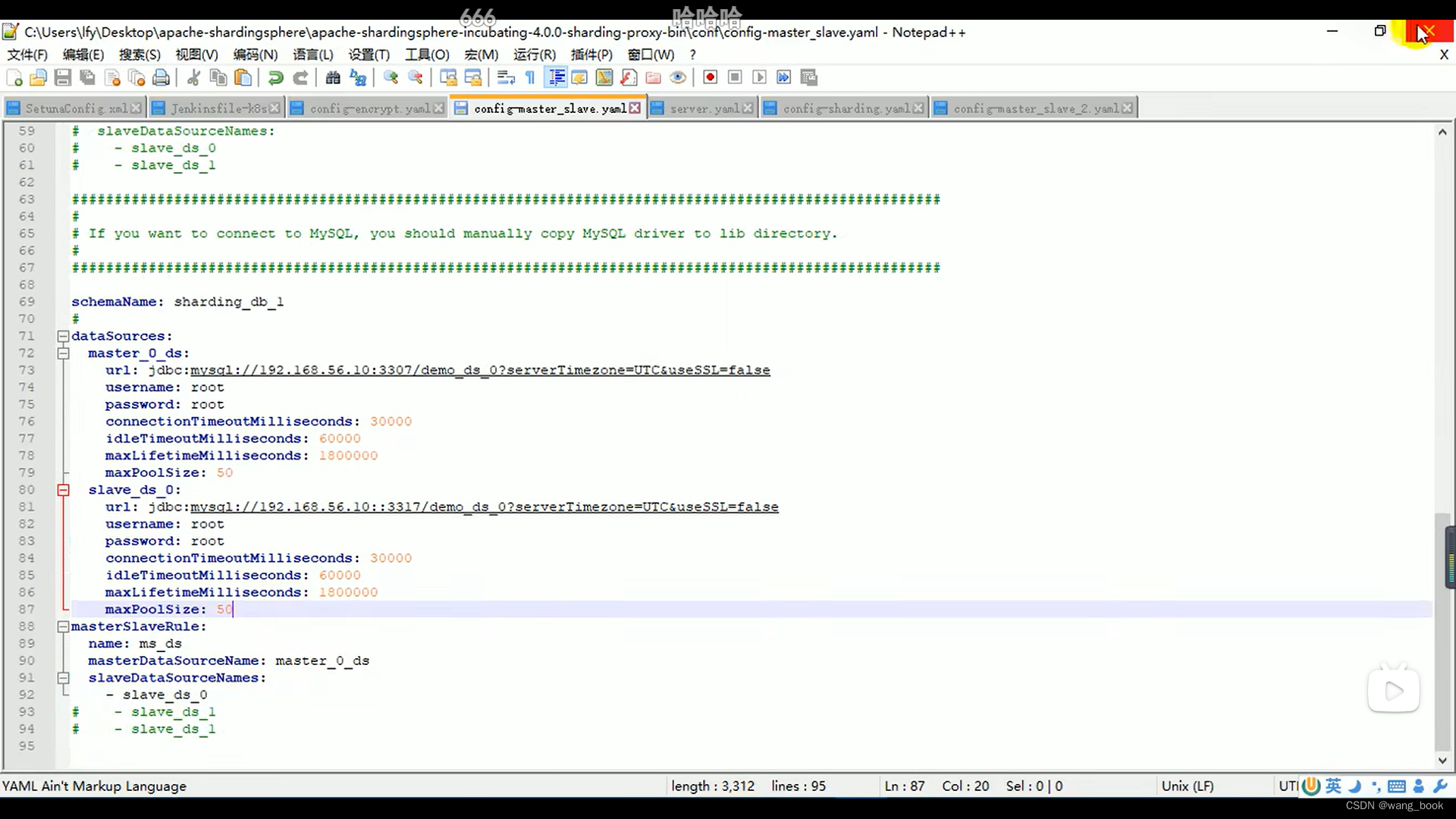
这里我们为了节省资源 分的库都在一个ip和端口上,生成环境中 最好分在两个不同的服务器上
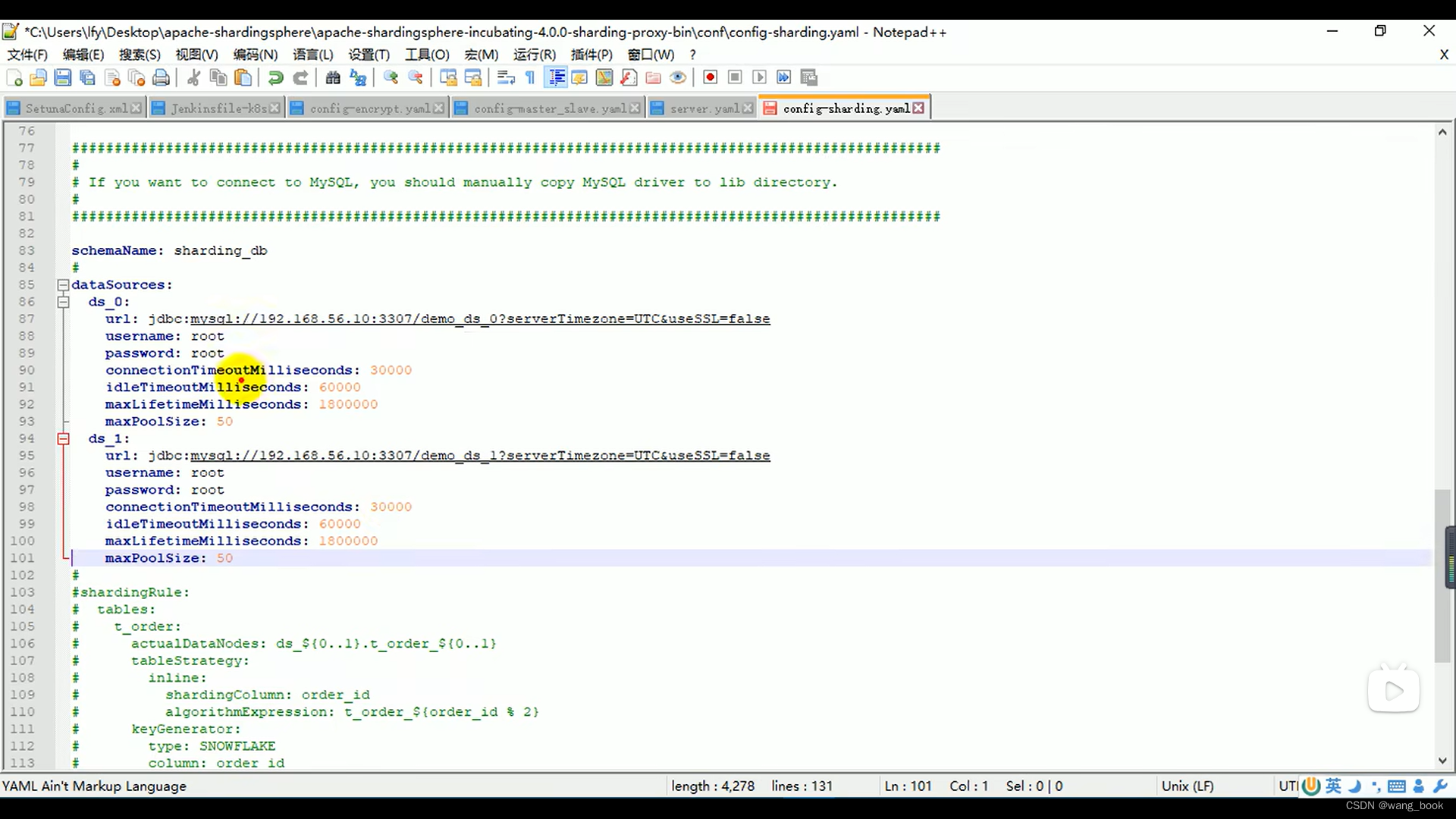
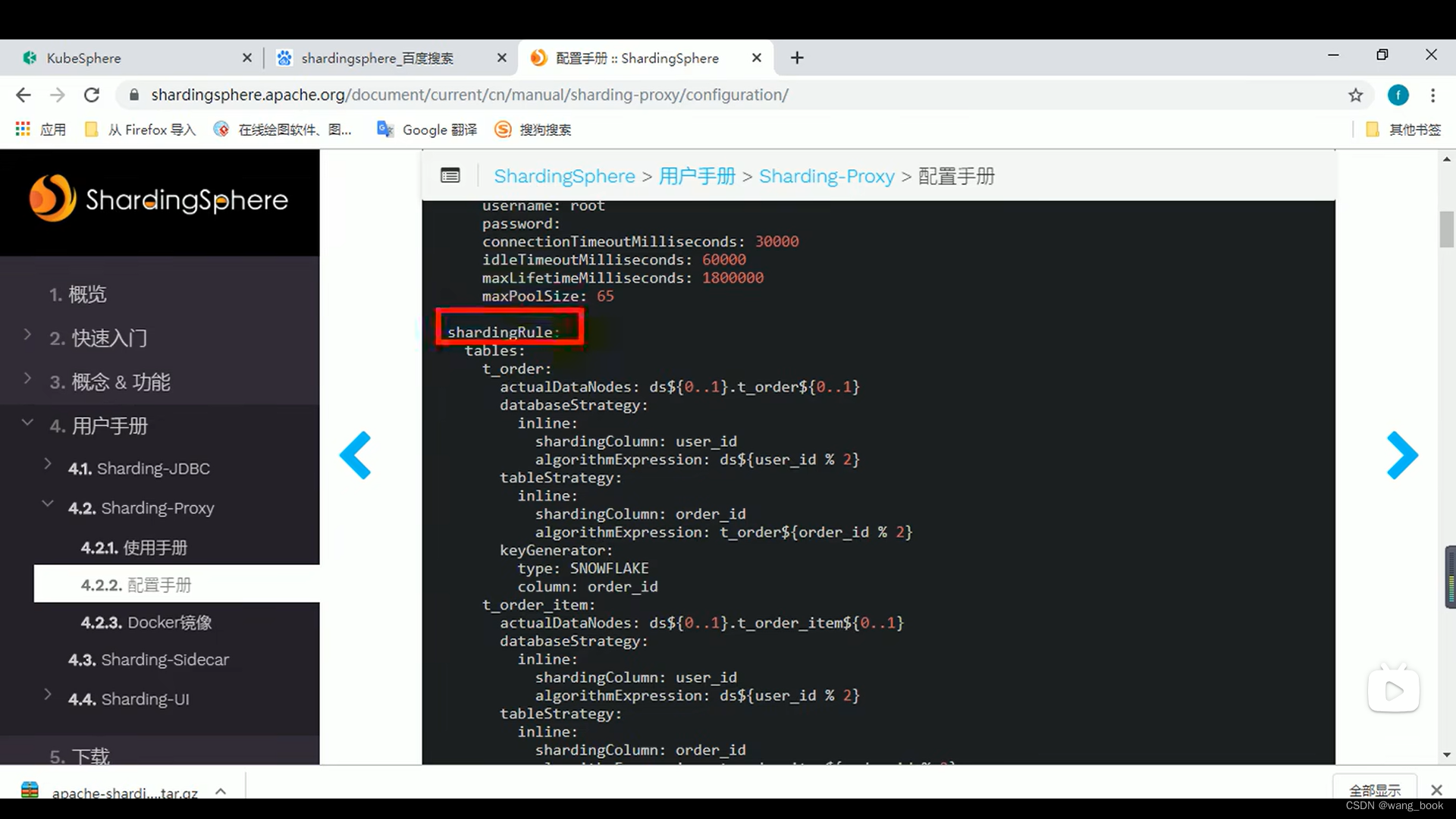
添加规则
我们使用雪花算法 这样不会产生自增的错误
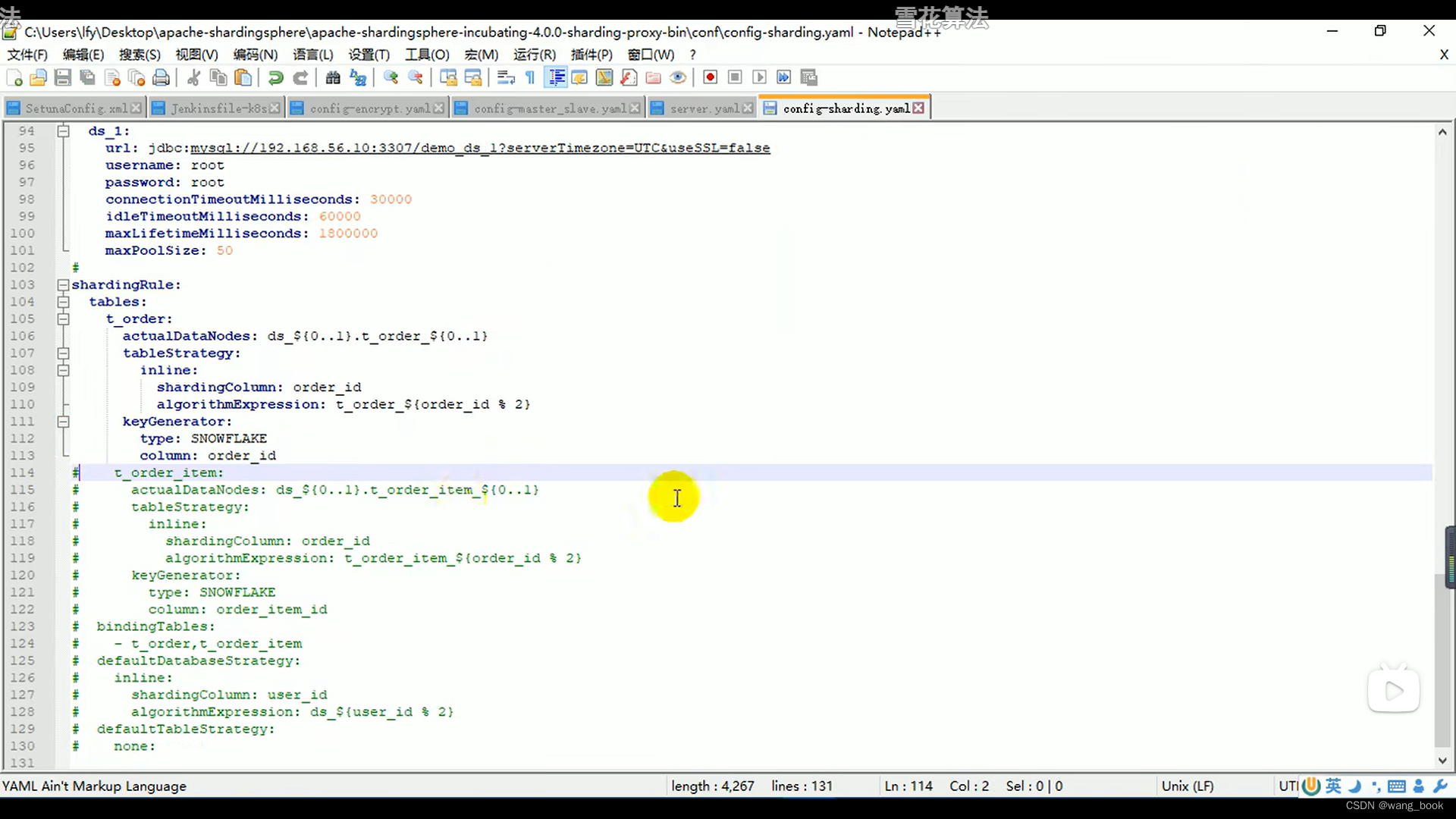
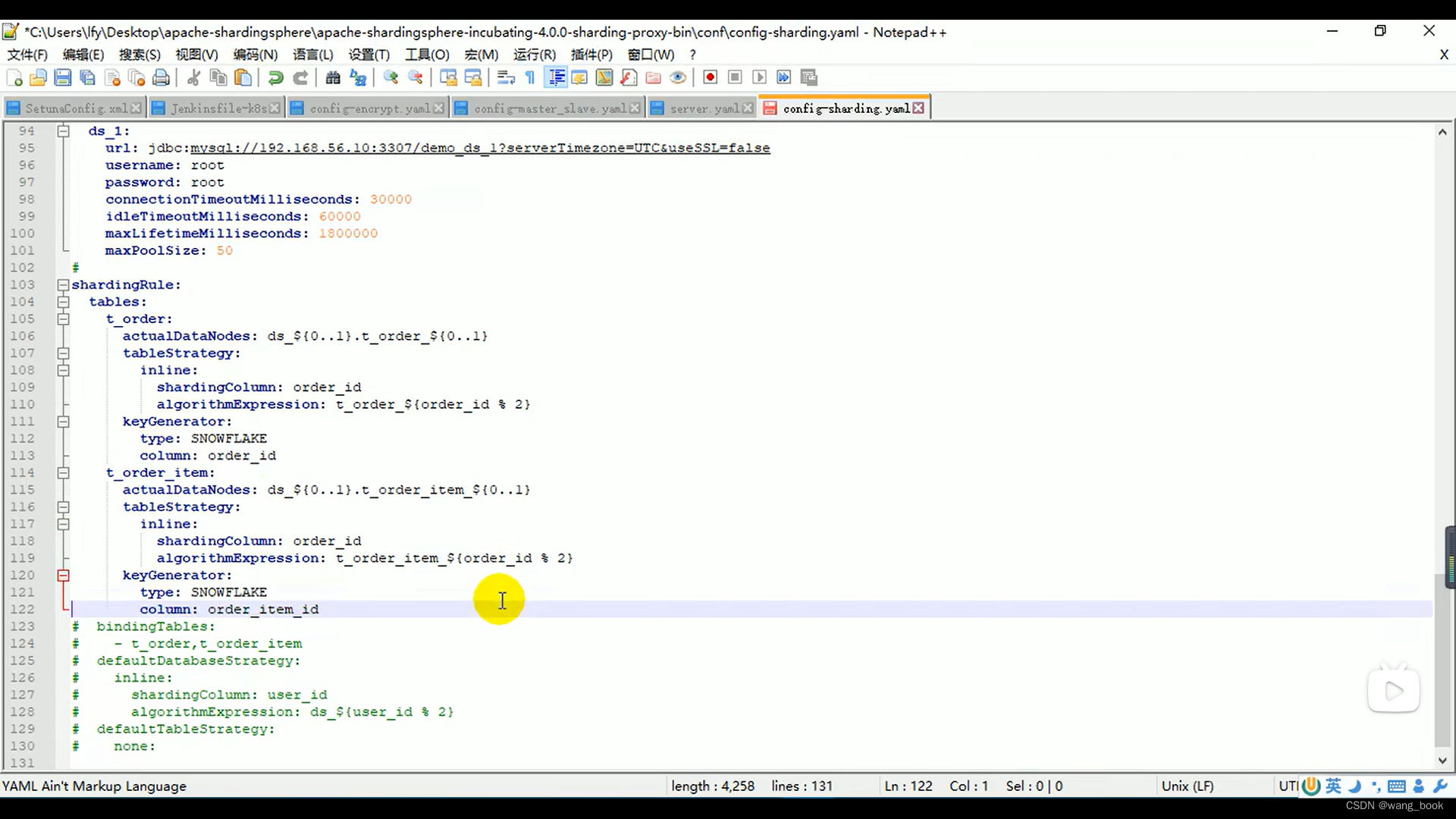
绑定表
绑定了 这俩的order_id一样的话 就都会在这里
分库策略
根据用户的id进行分库
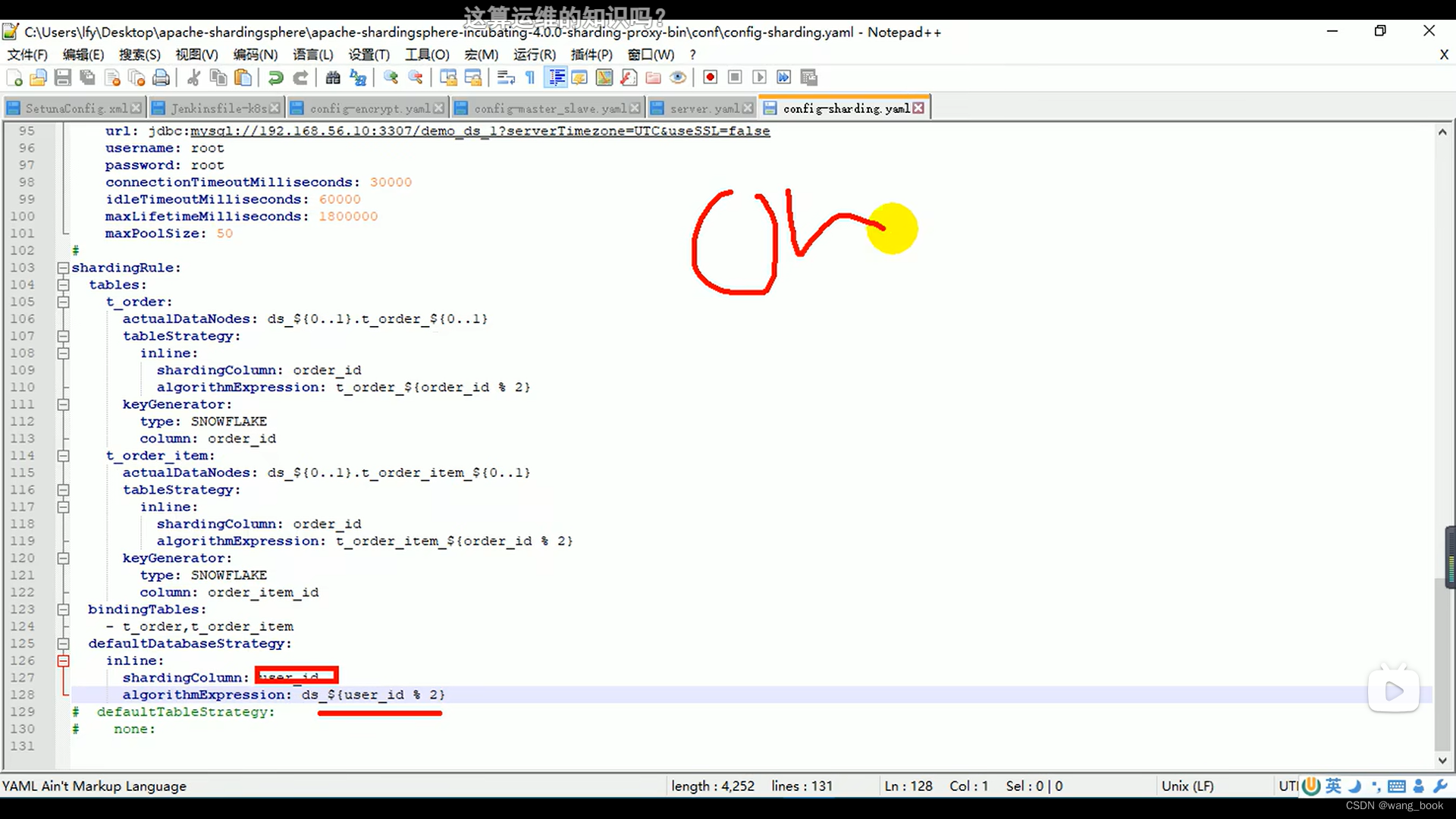
默认分表策略就可以设置为none了 因为之前已经分完了
读写分离配置
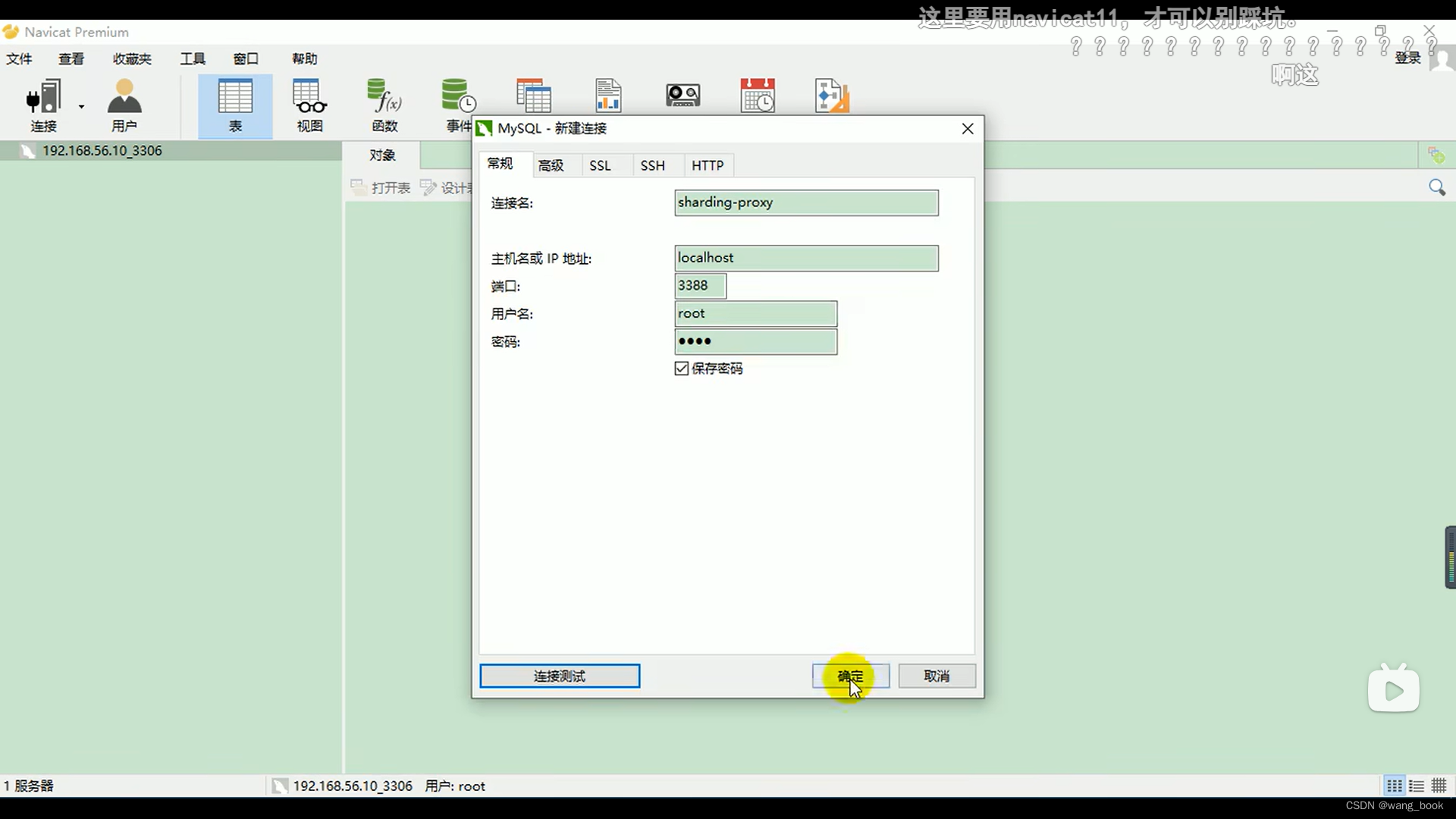
注意:Navicat11以上才能连上
主数据源
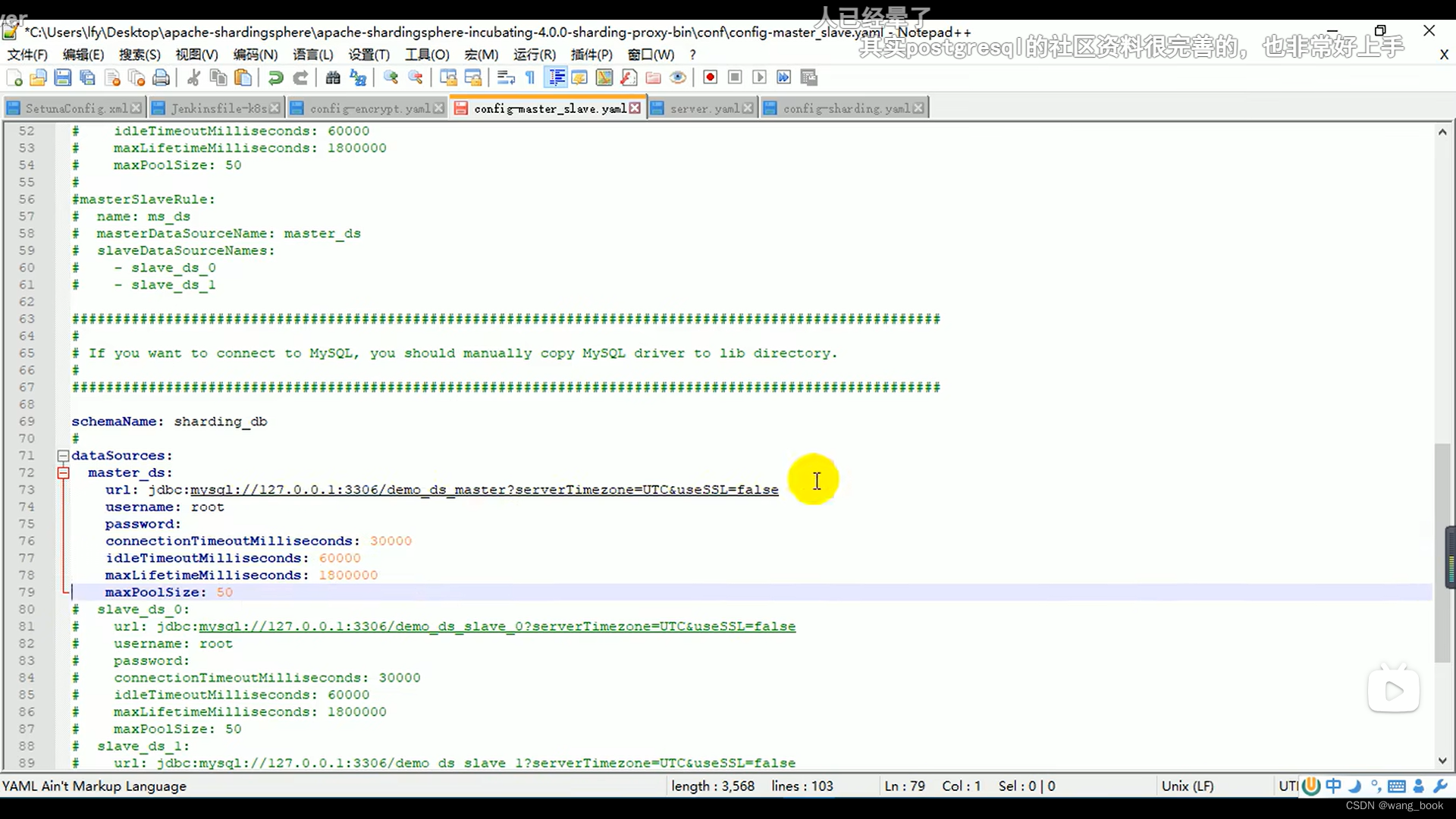
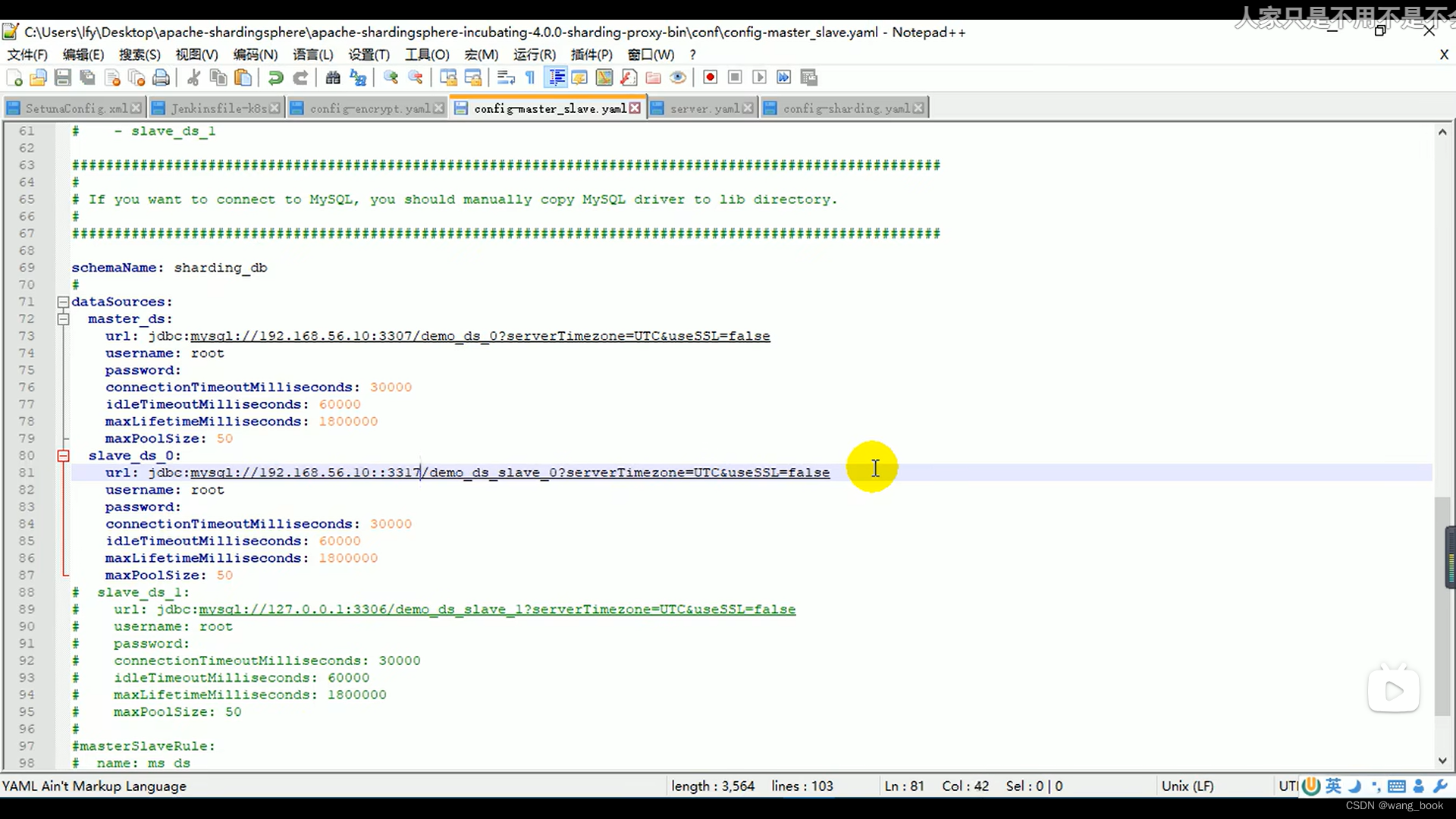
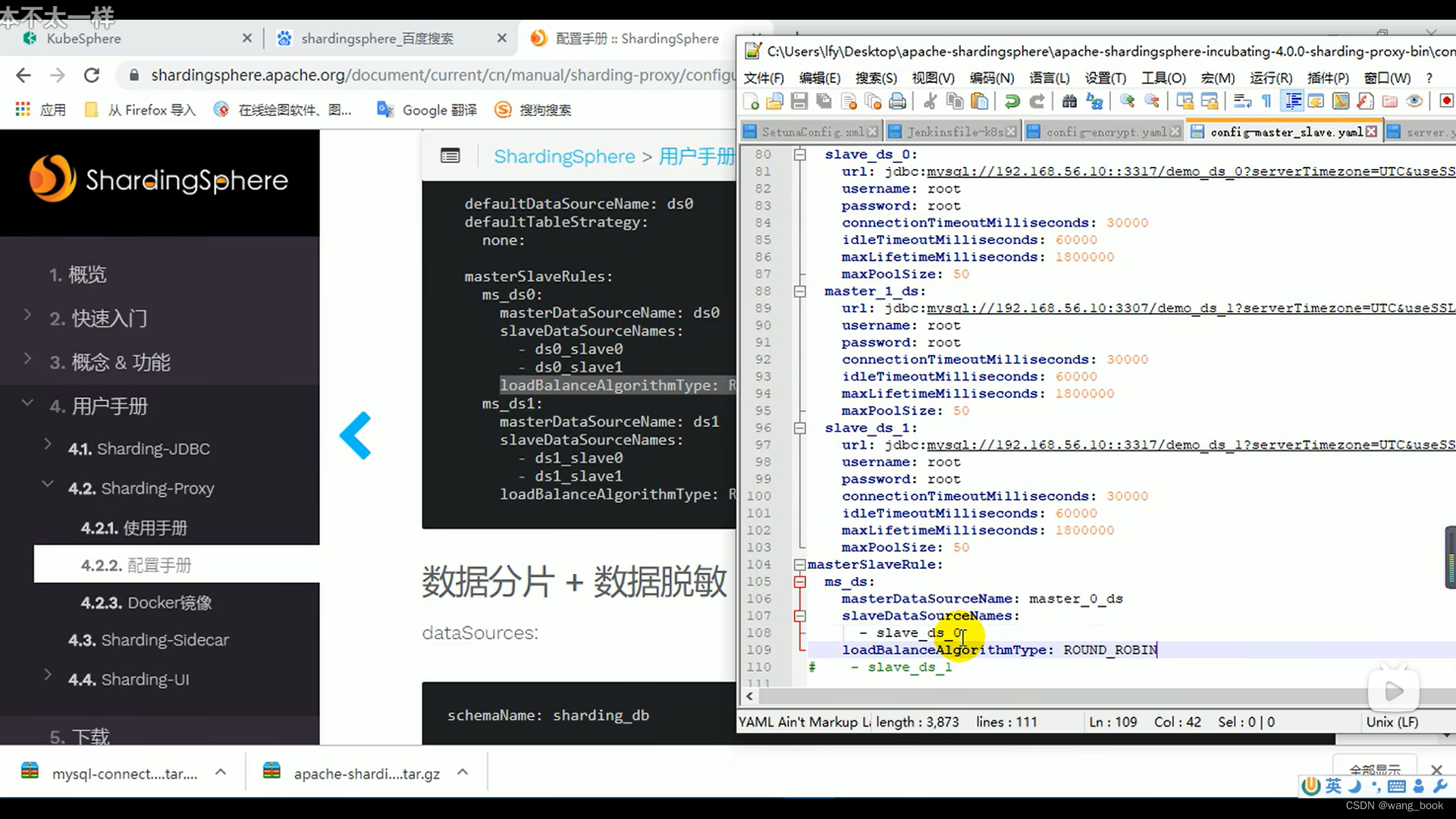
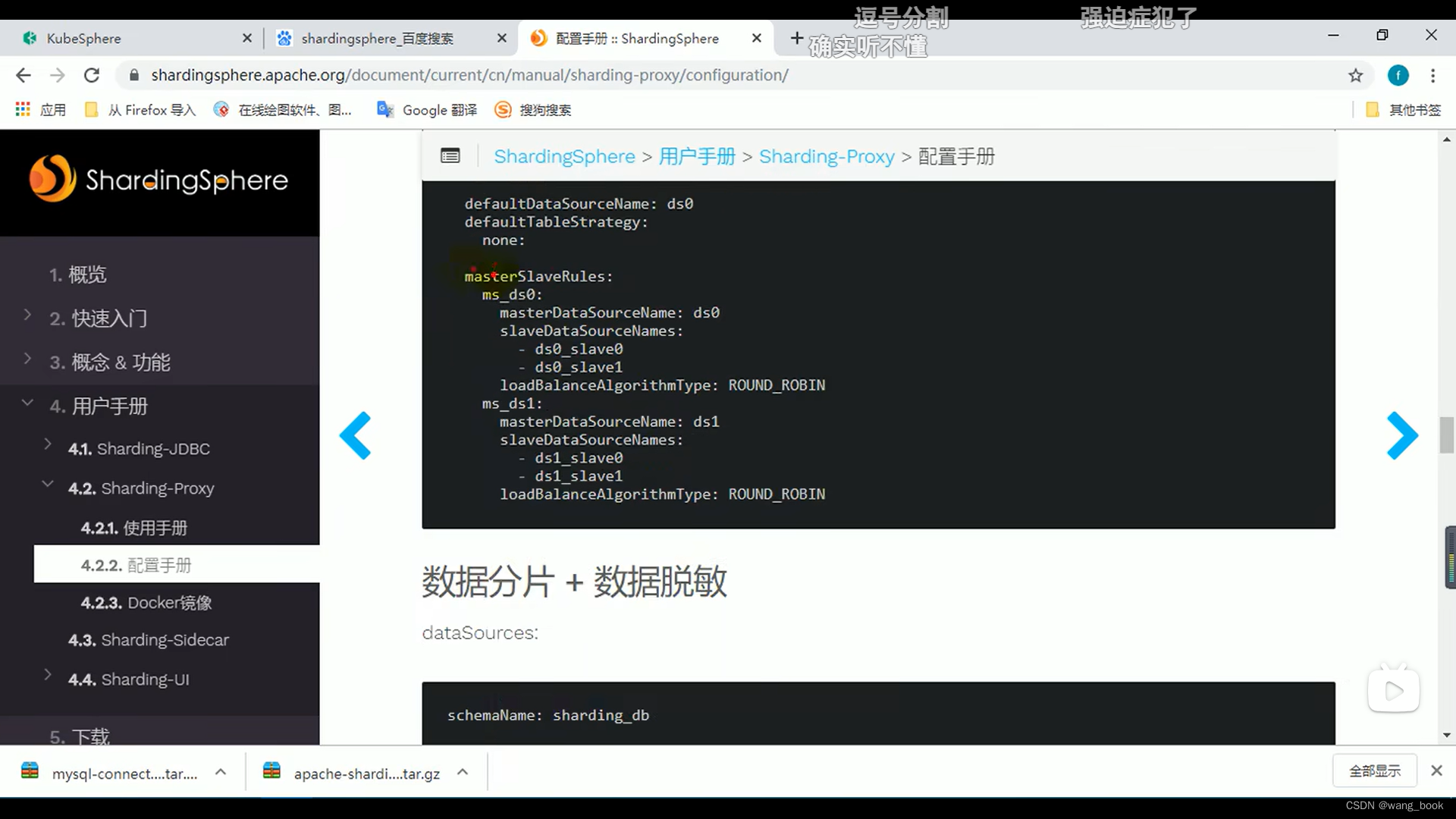
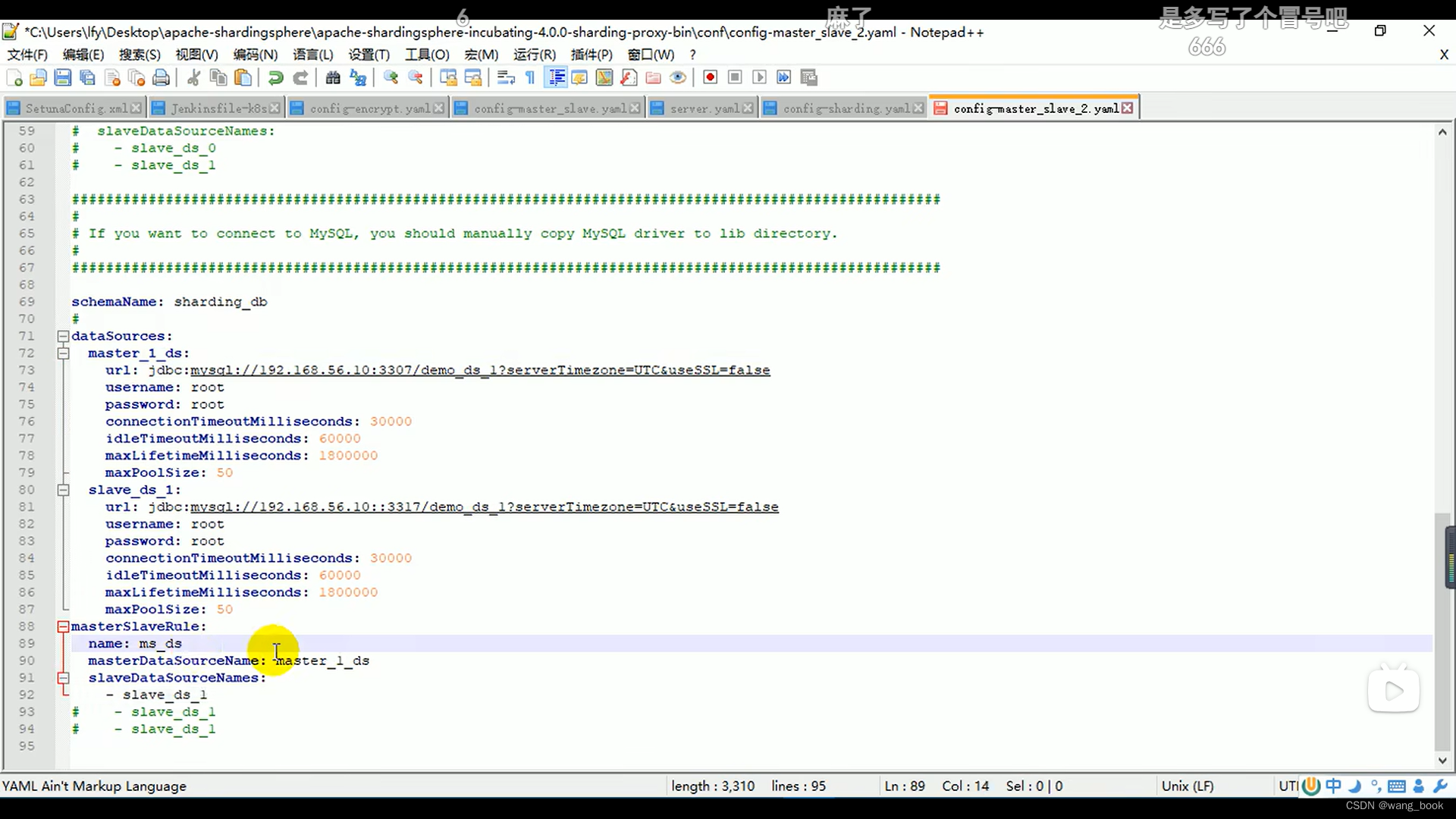
数据源主从规则
这里我们使用轮询的负载均衡策略
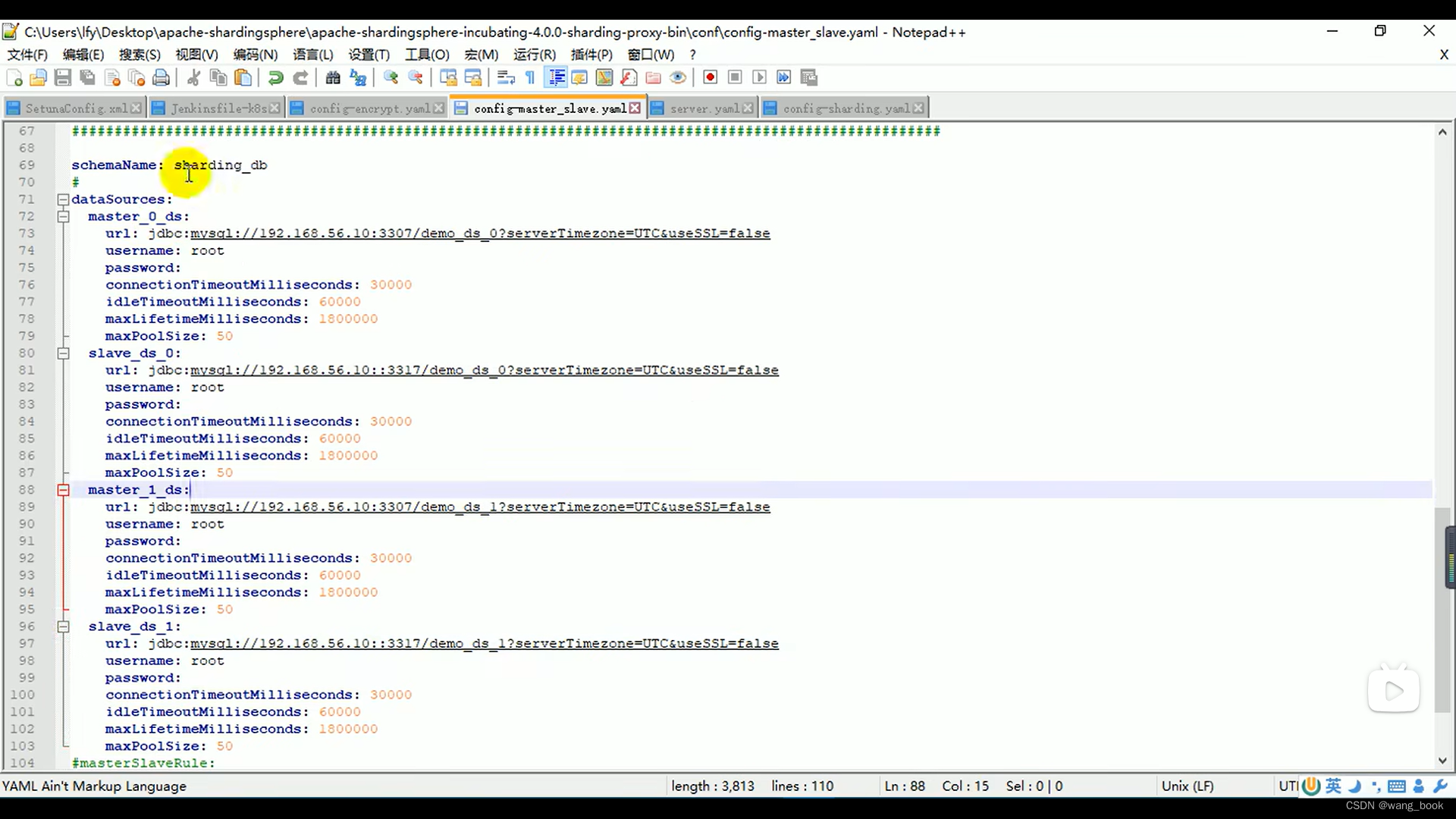
设置第二个主数据库 和从数据源
使用bat启动sharding
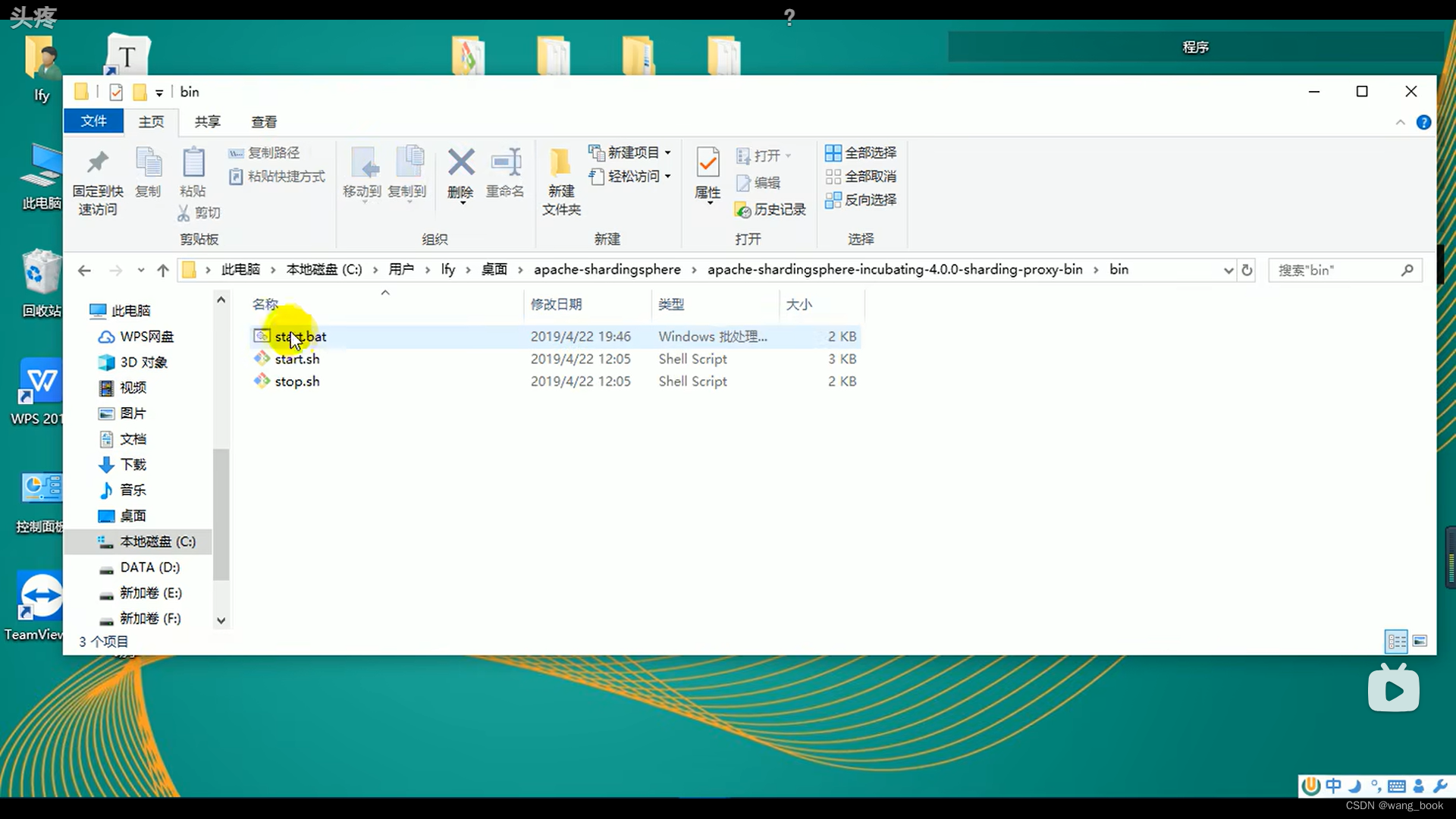
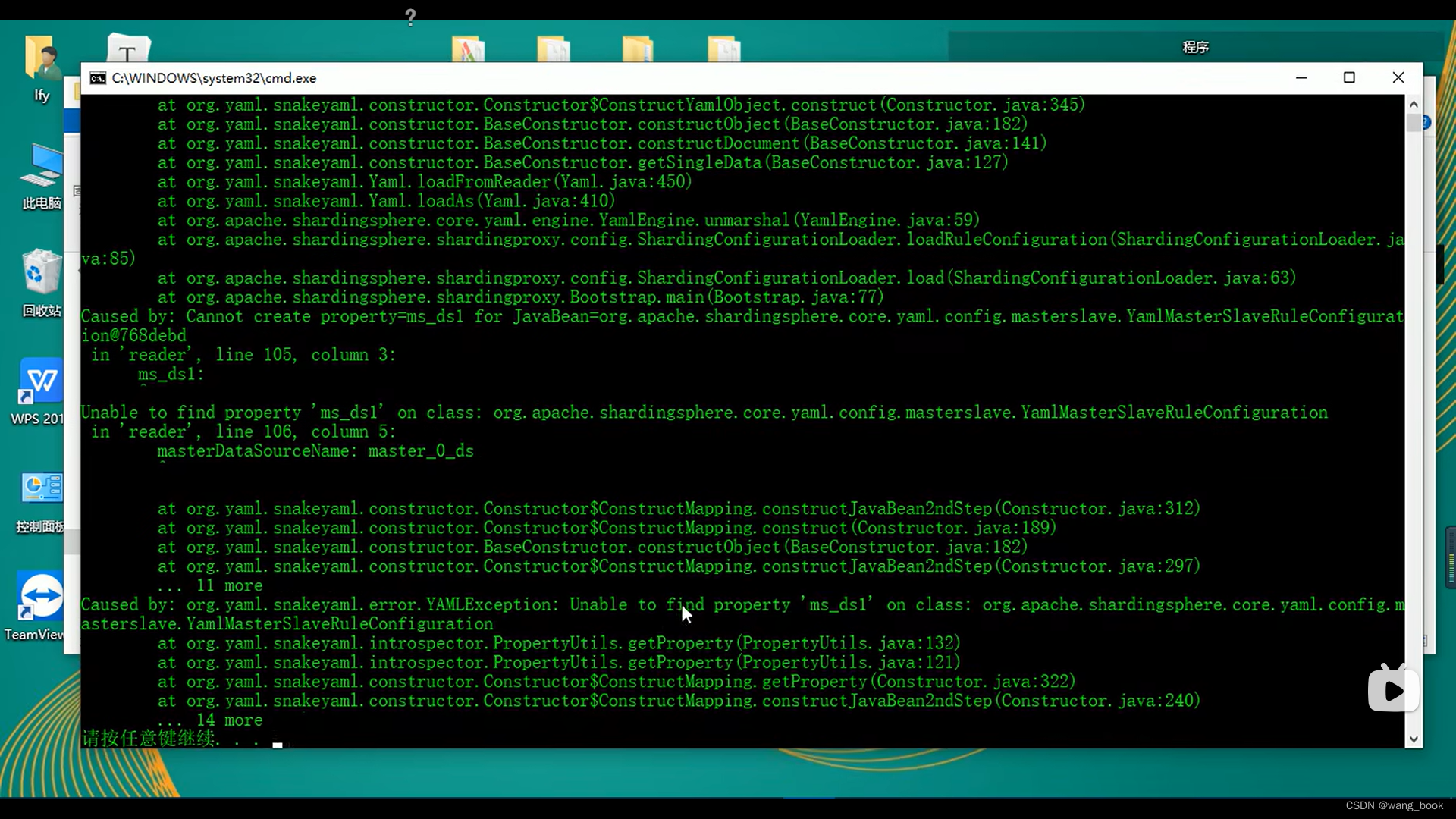
这里的报错原因 : 找不到ms_ds1
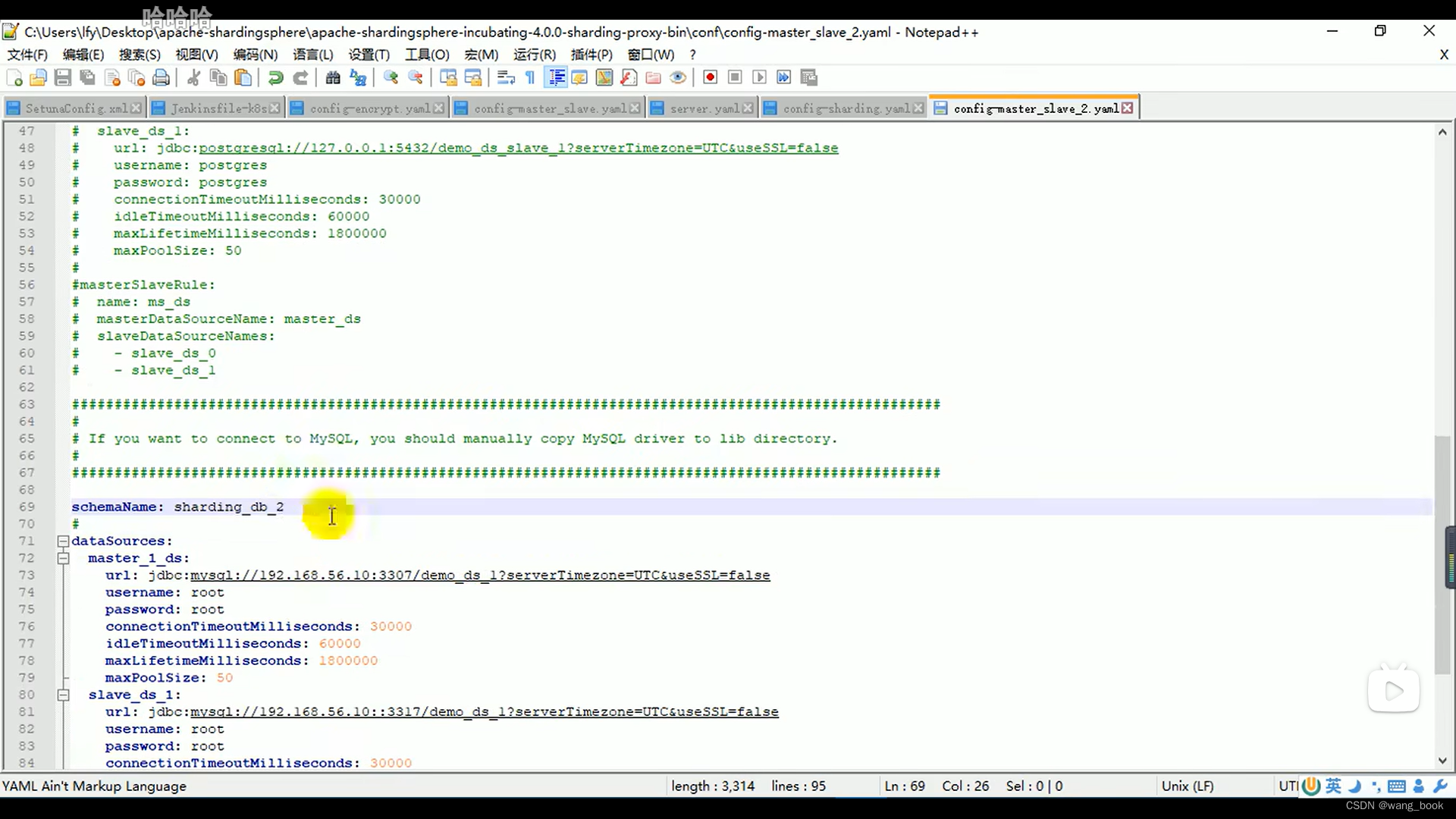
这个版本的 我们只能配置一个
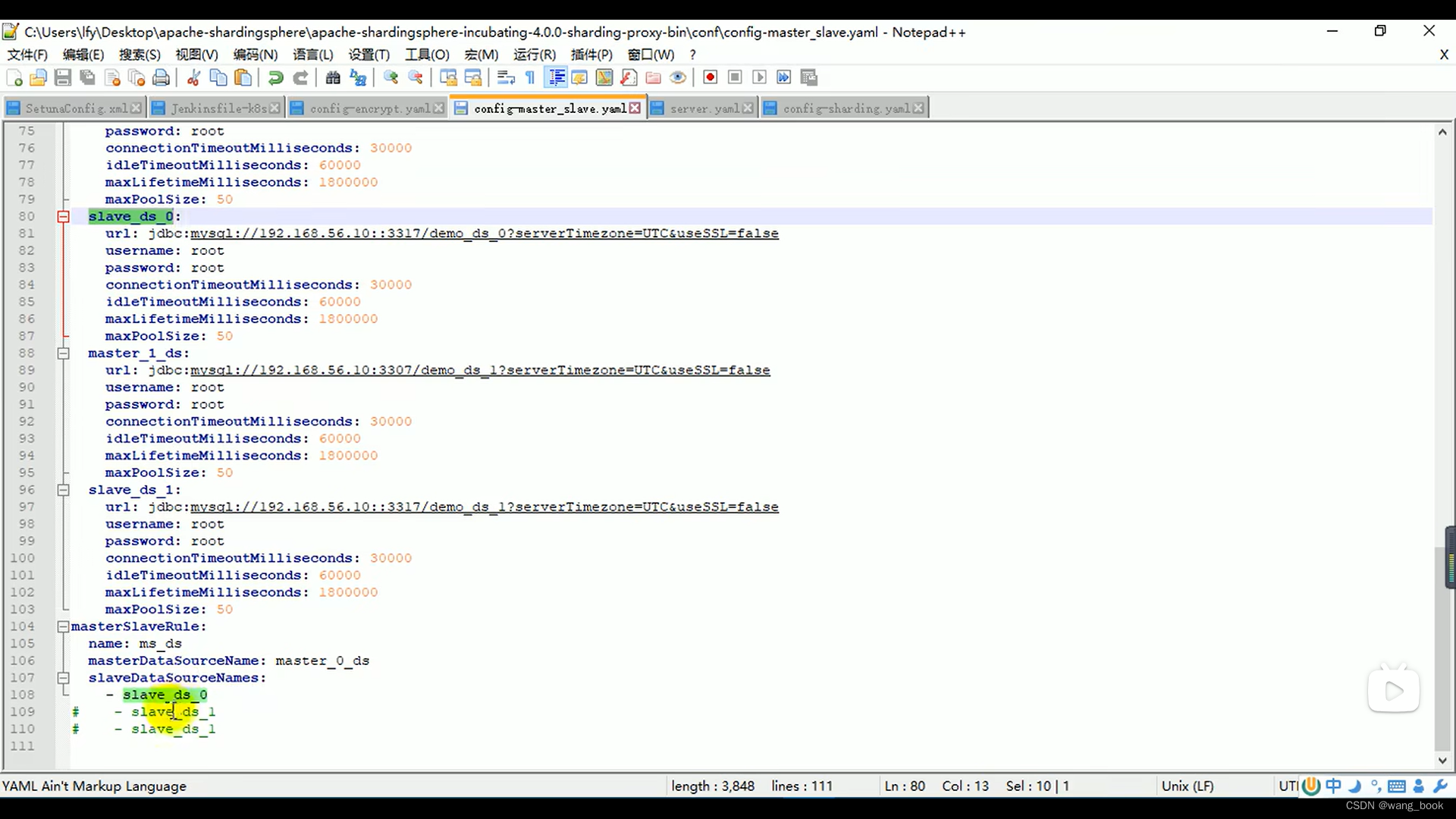
这里我们如果想配置两个 可以再添加一个配置文件
改错的时候 停掉 mysql-master 和 mysql-slaver-01
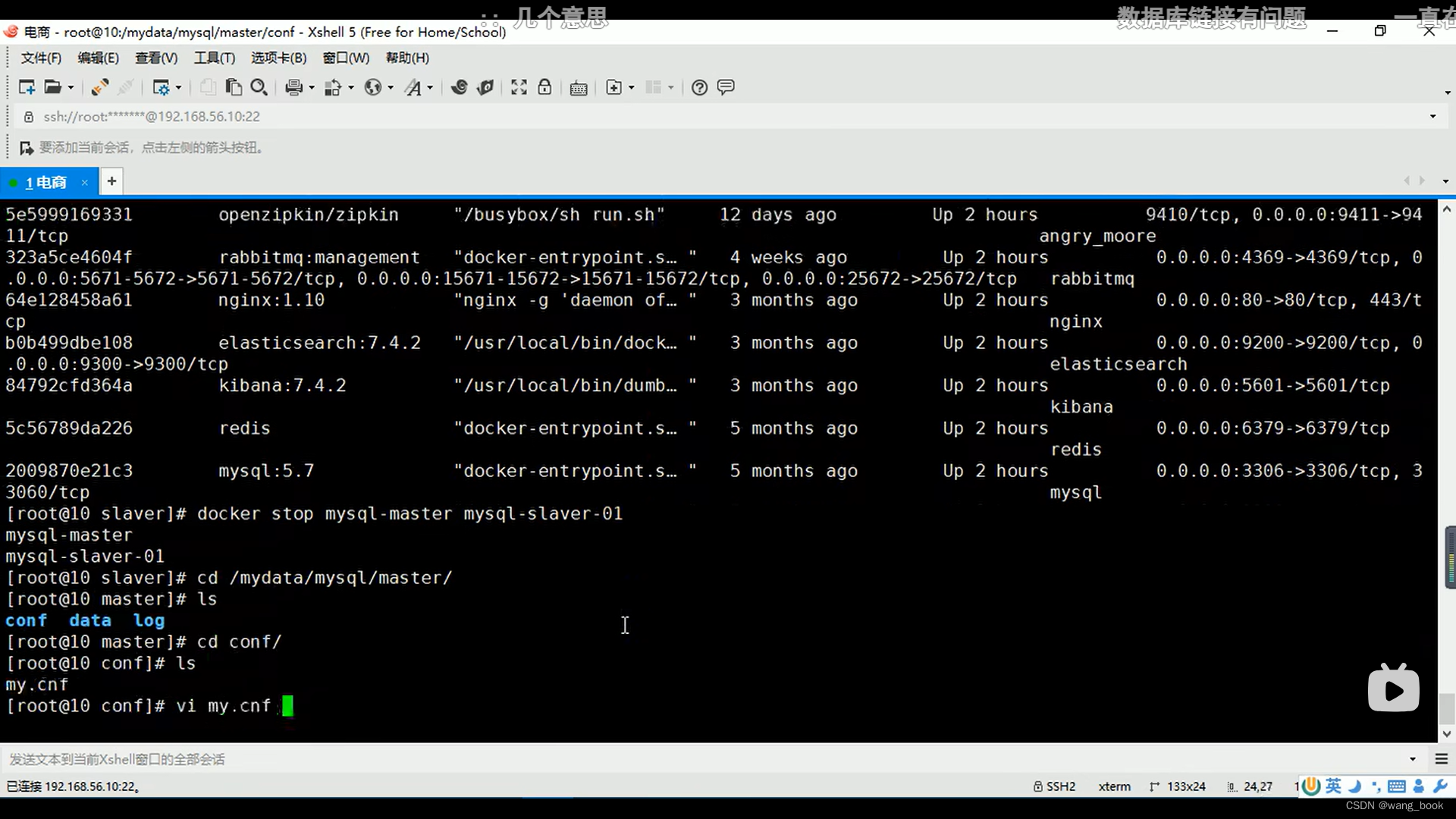
修改my.cnf文件
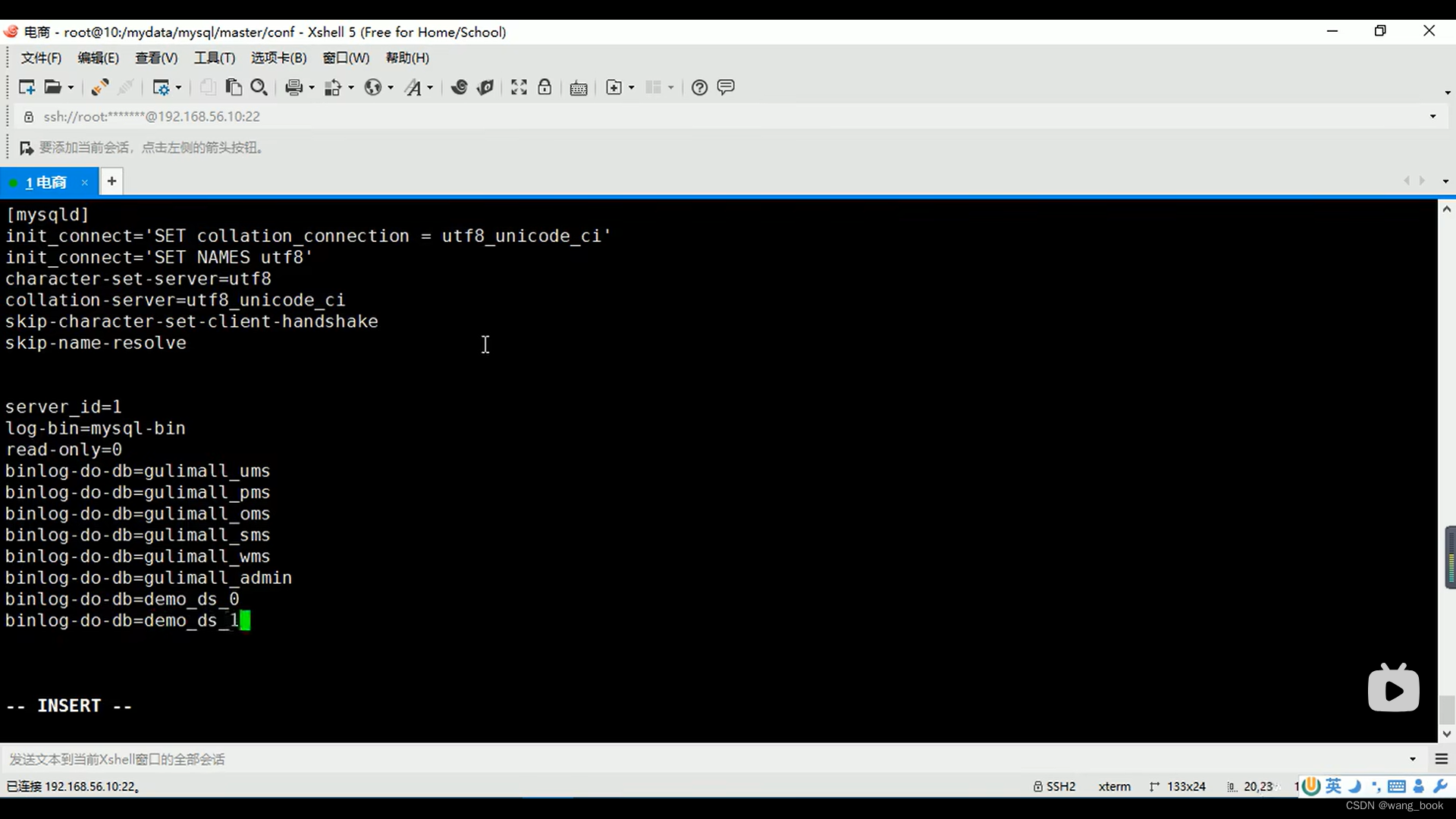
修改从库的my.cnf
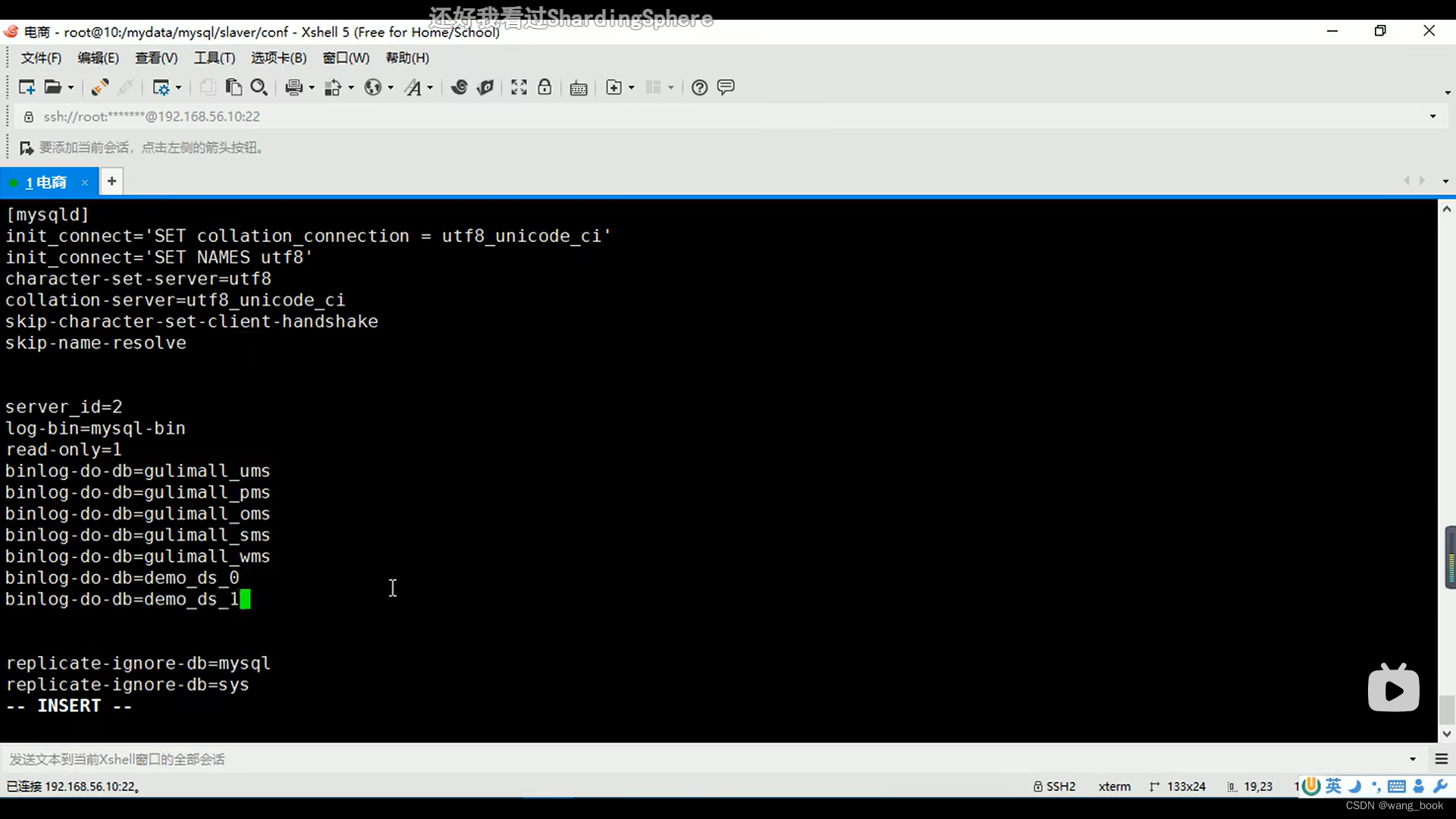
重新启动这两个库
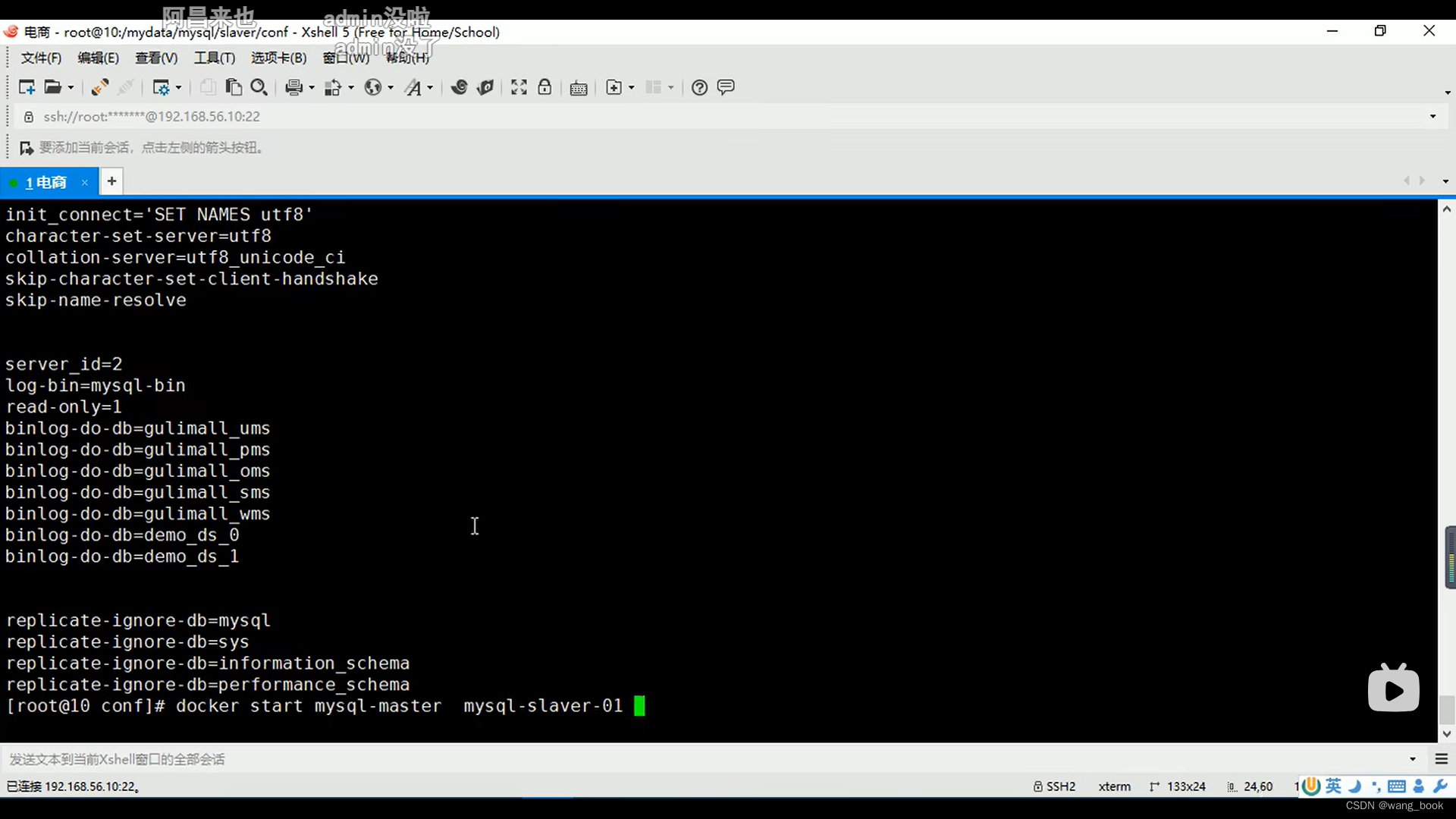
启动成功
我们自己指定端口
这个文件来看 可以传端口号
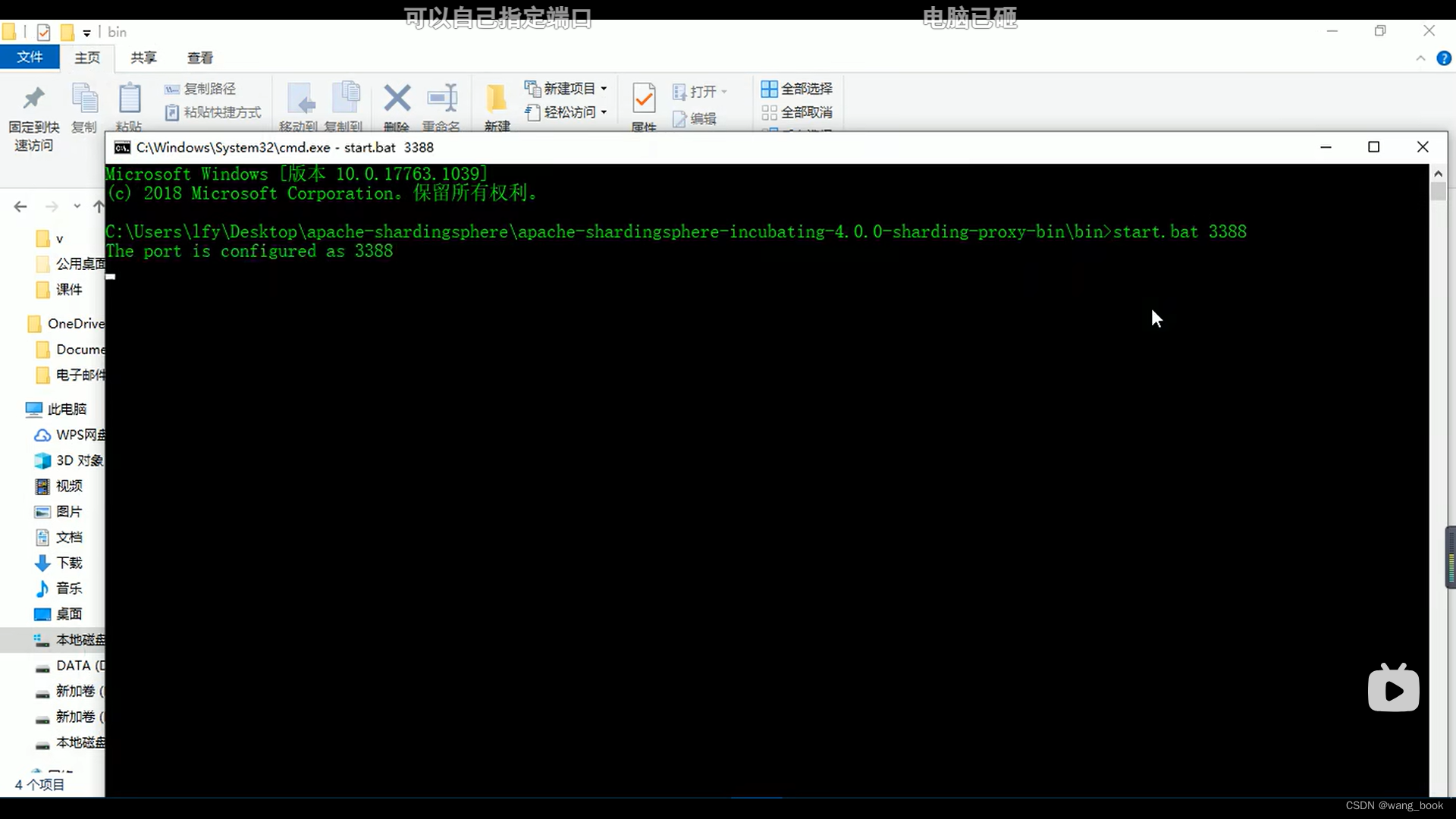
这里我们使用root用户进行登录
(shading权限太小)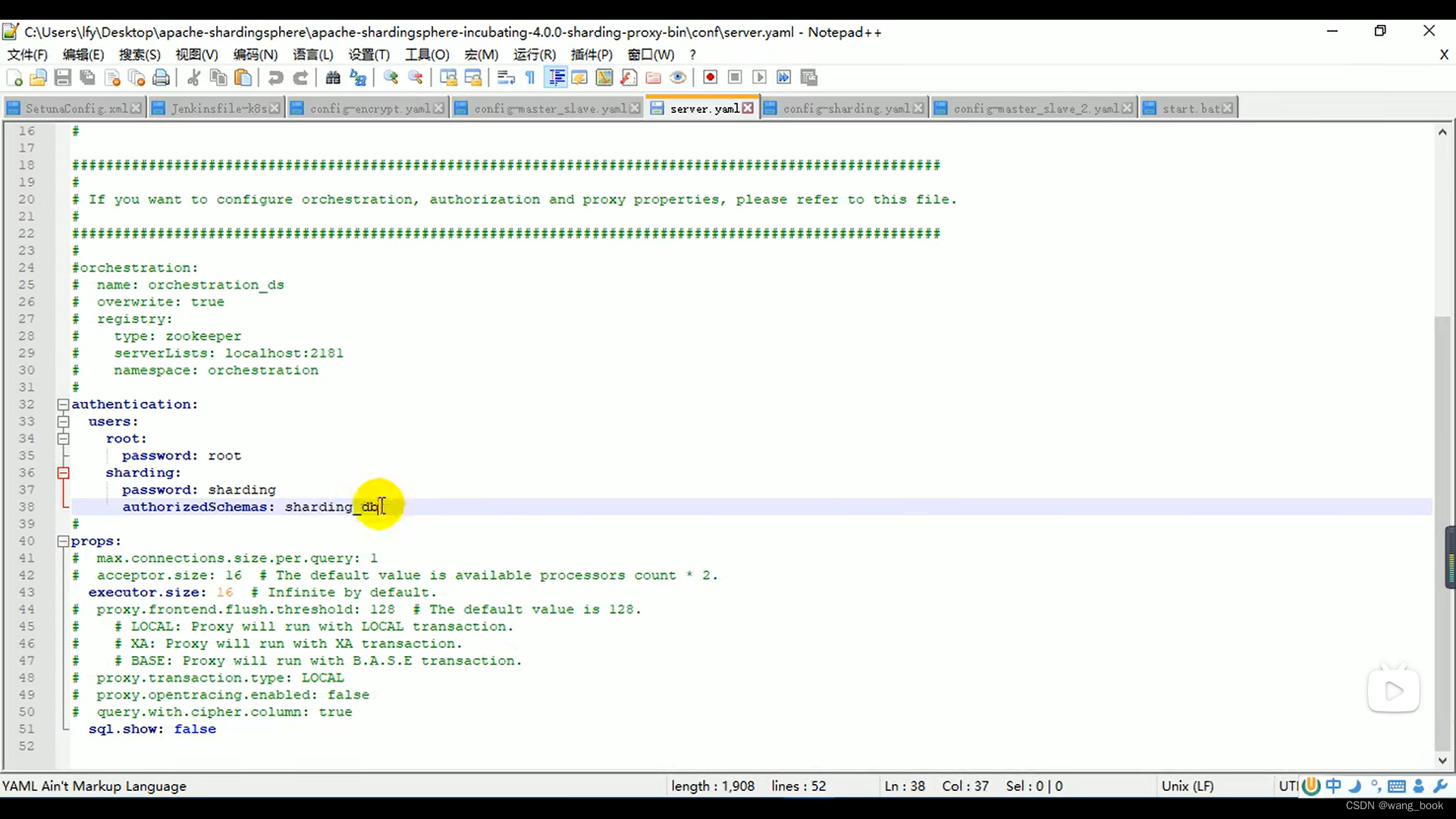
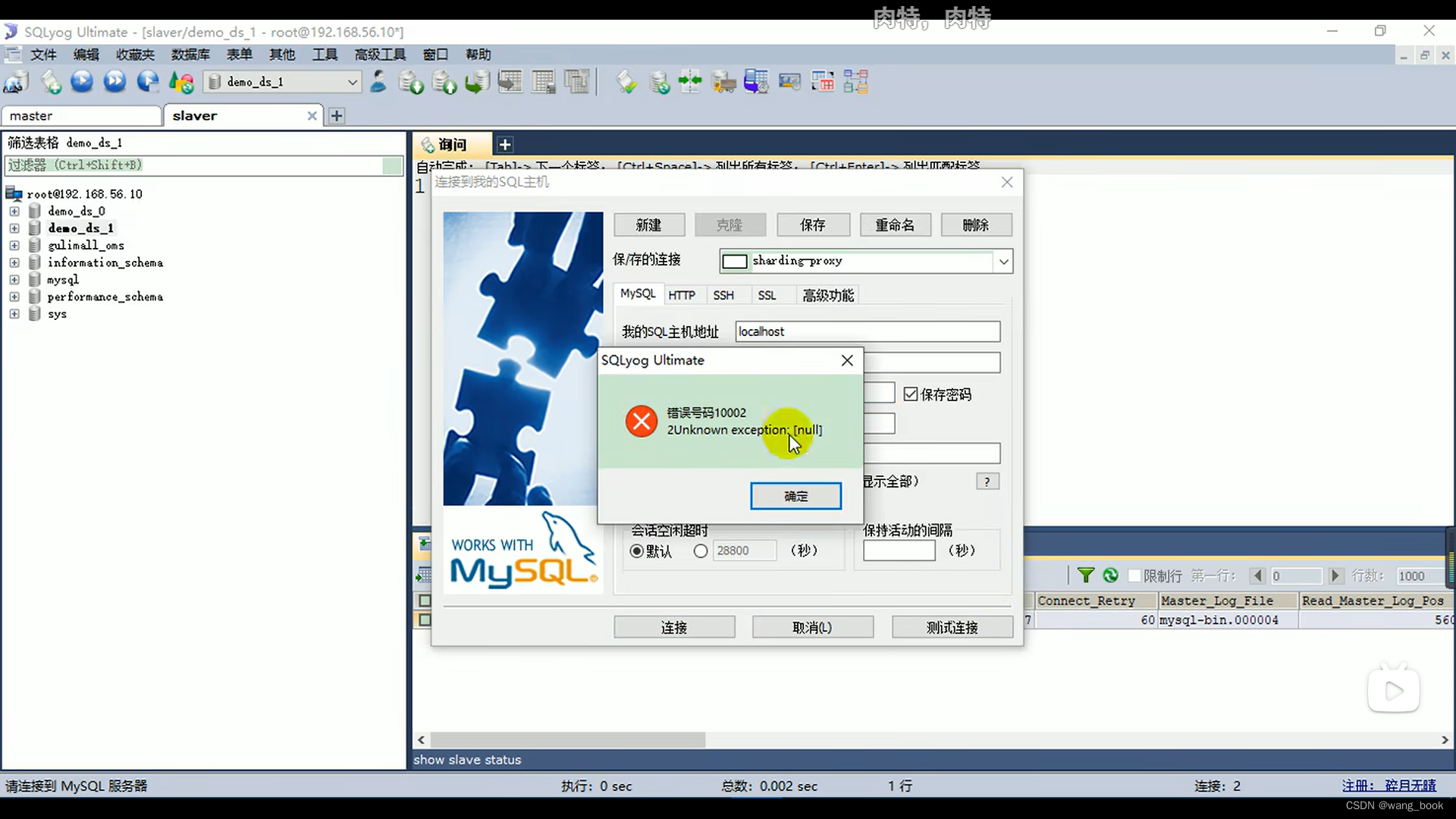
这里sqlyog产生了空指针异常 我们可以换成navcat就不报错了
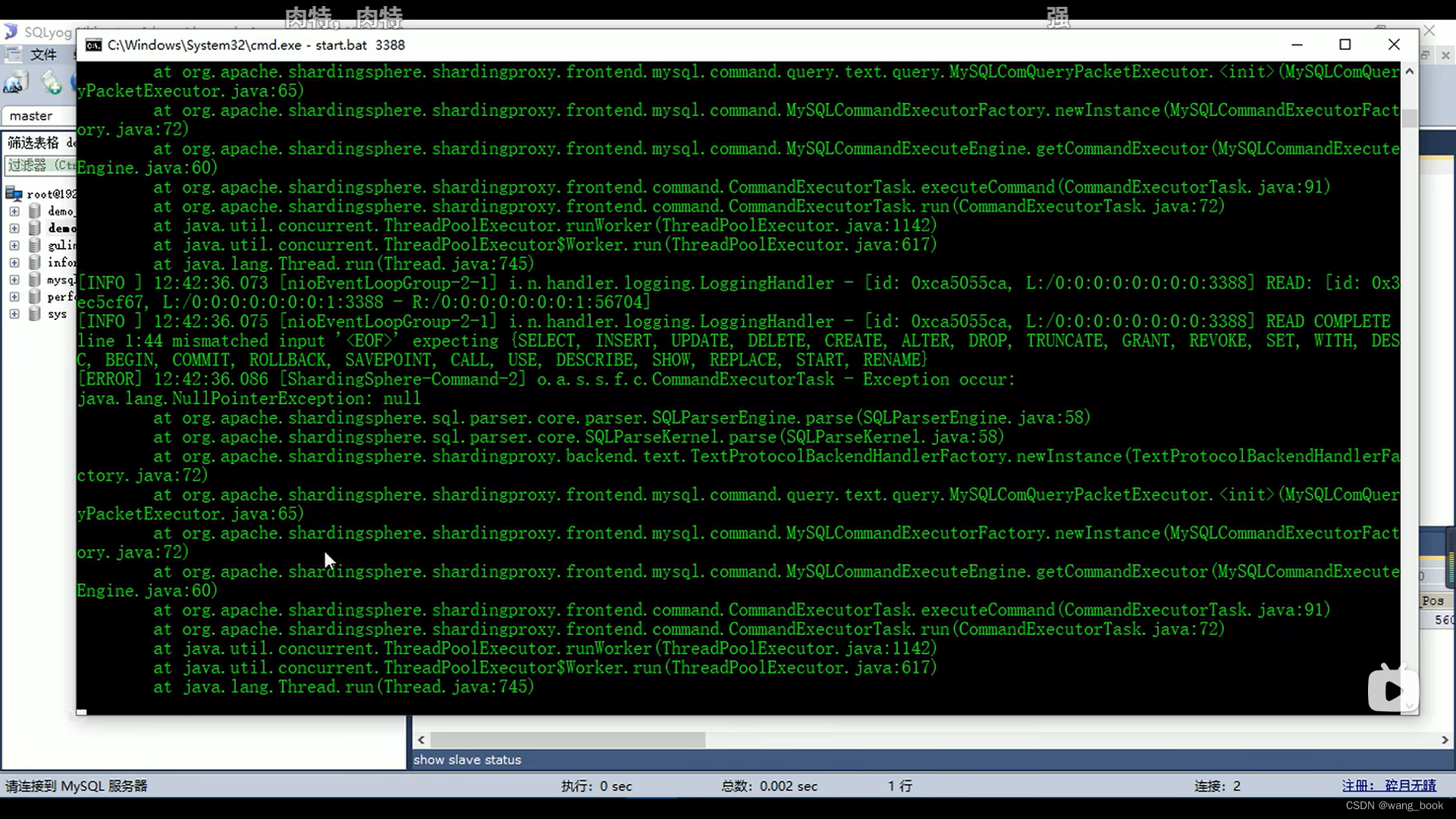
这里要用navicat11及以上
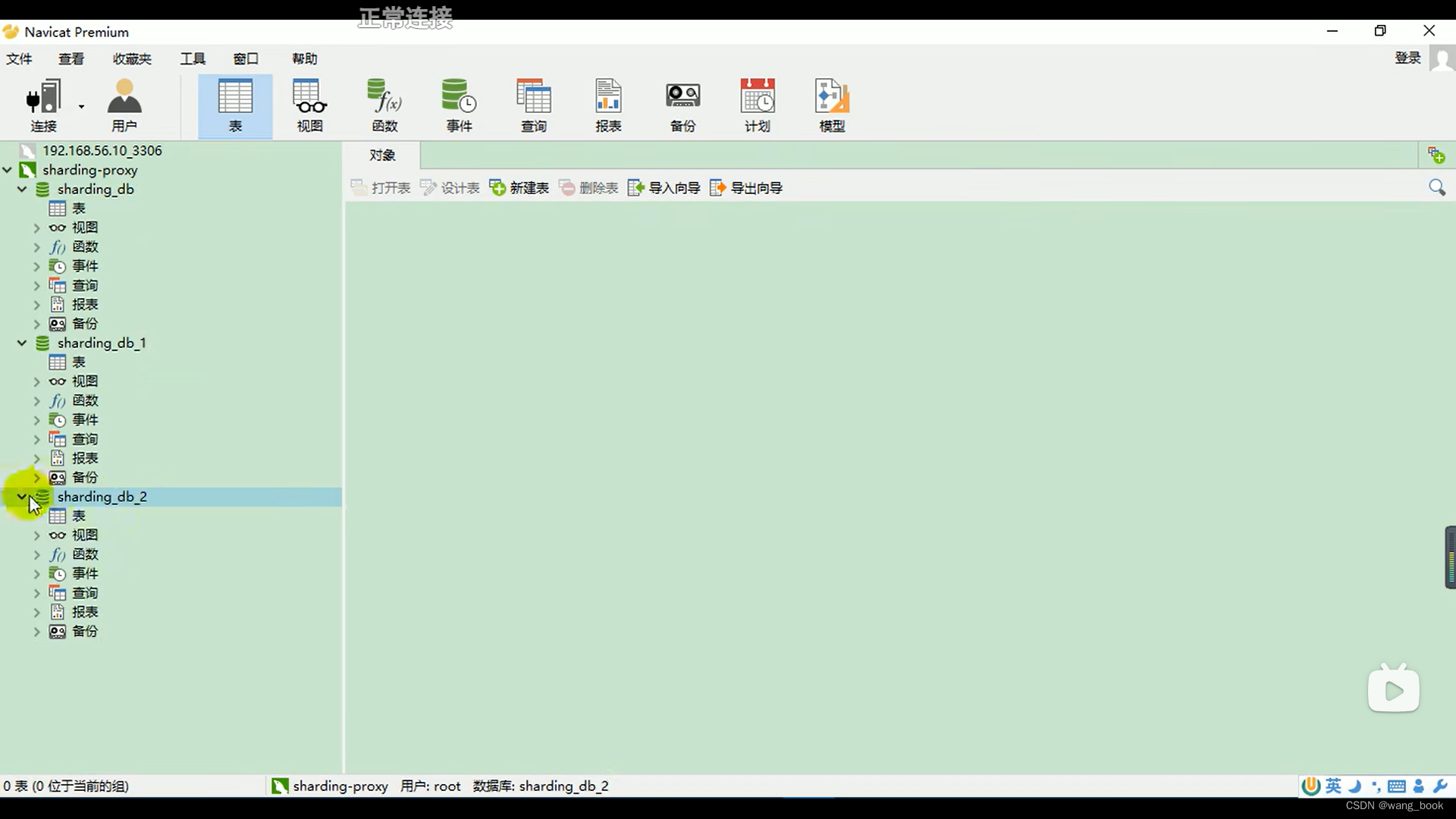
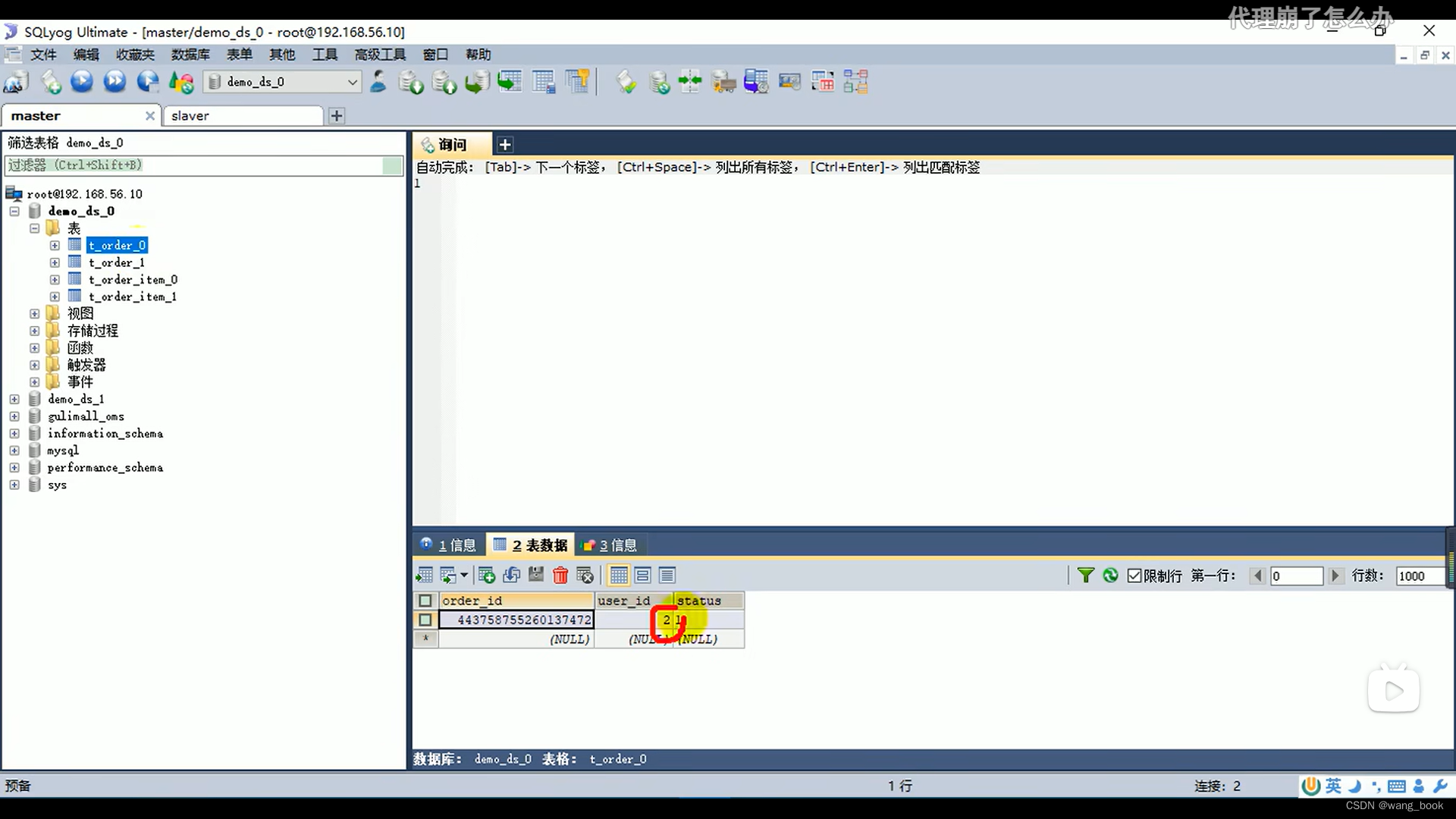
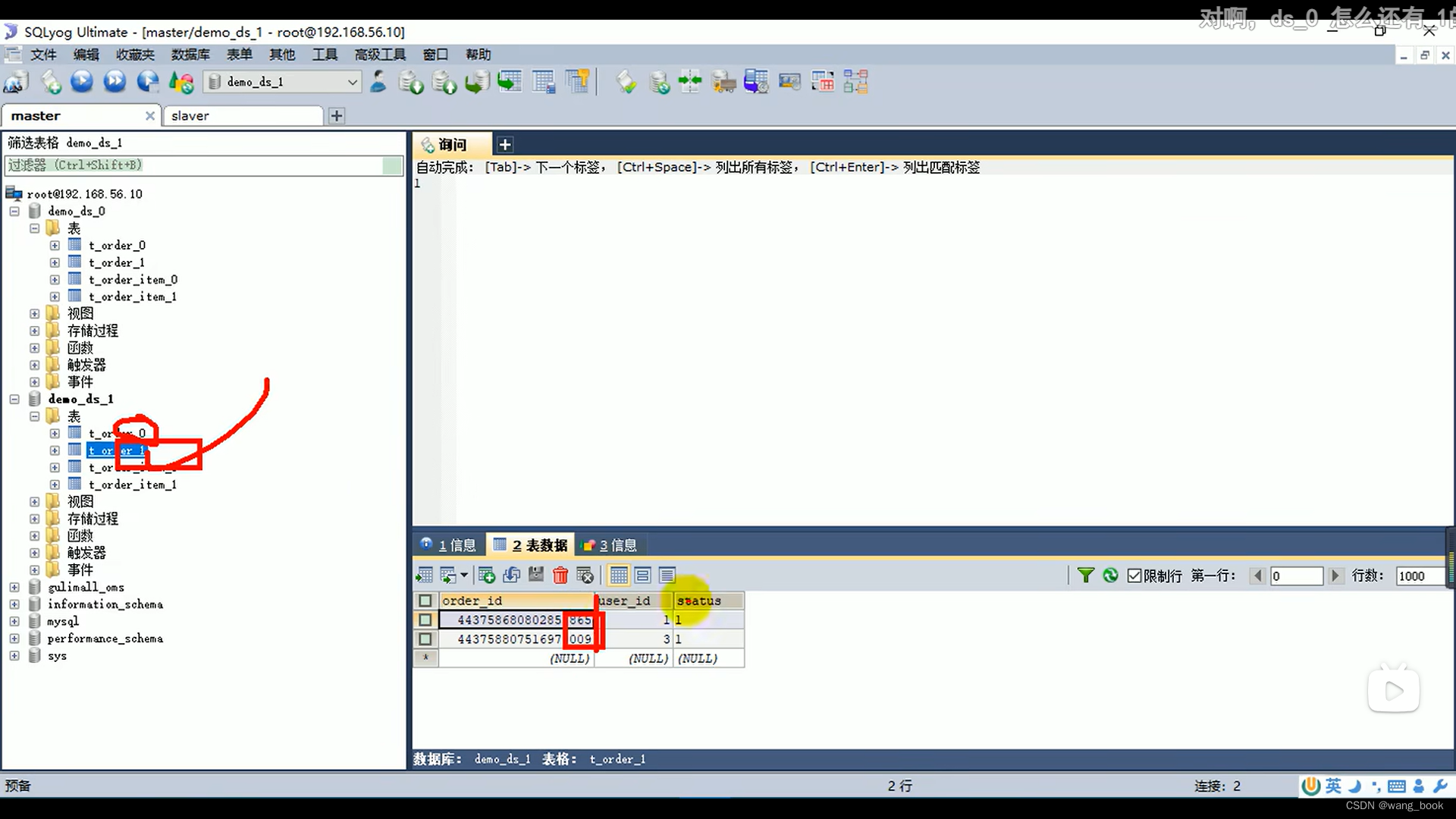
真实的数据库长这样
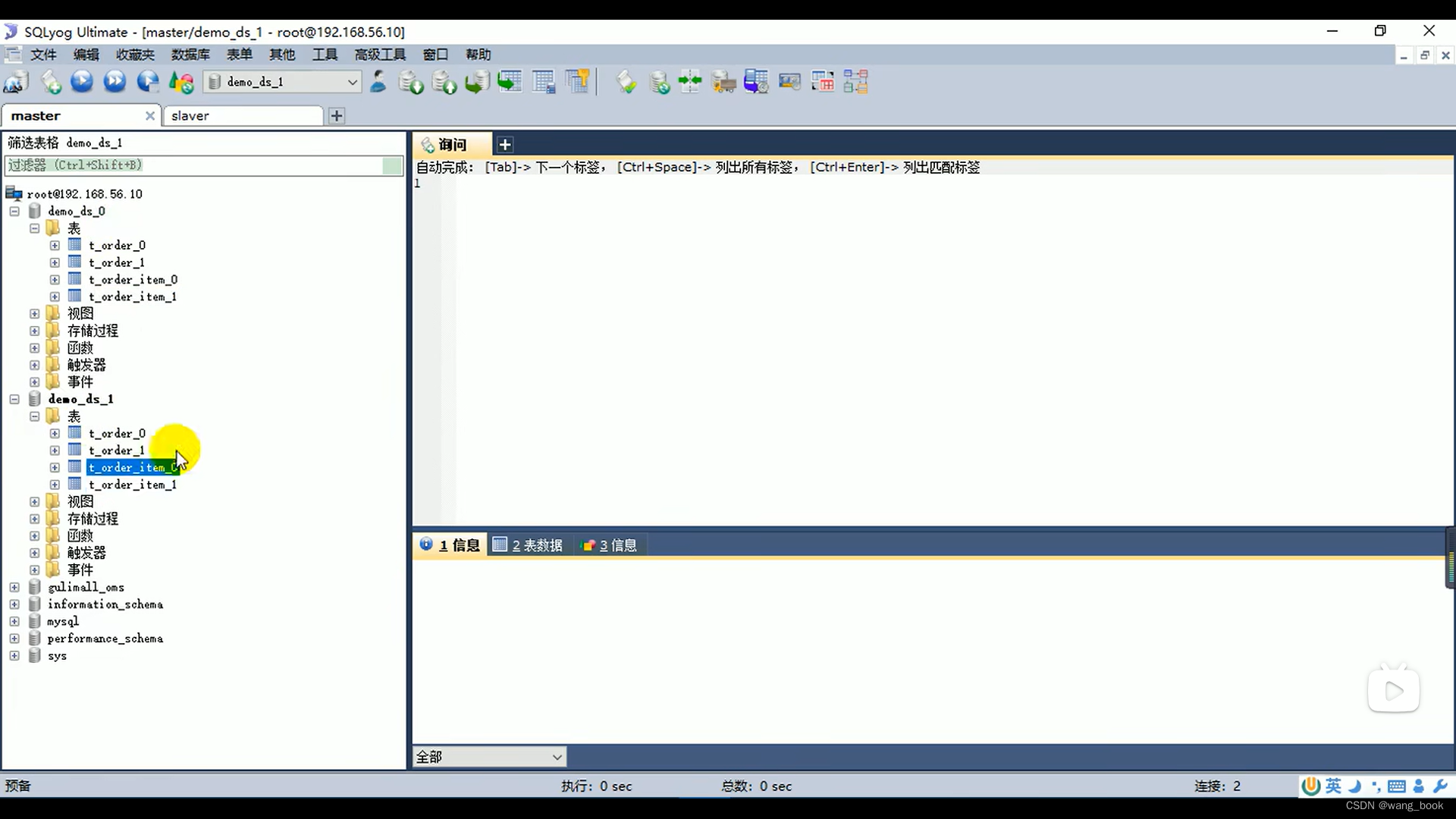
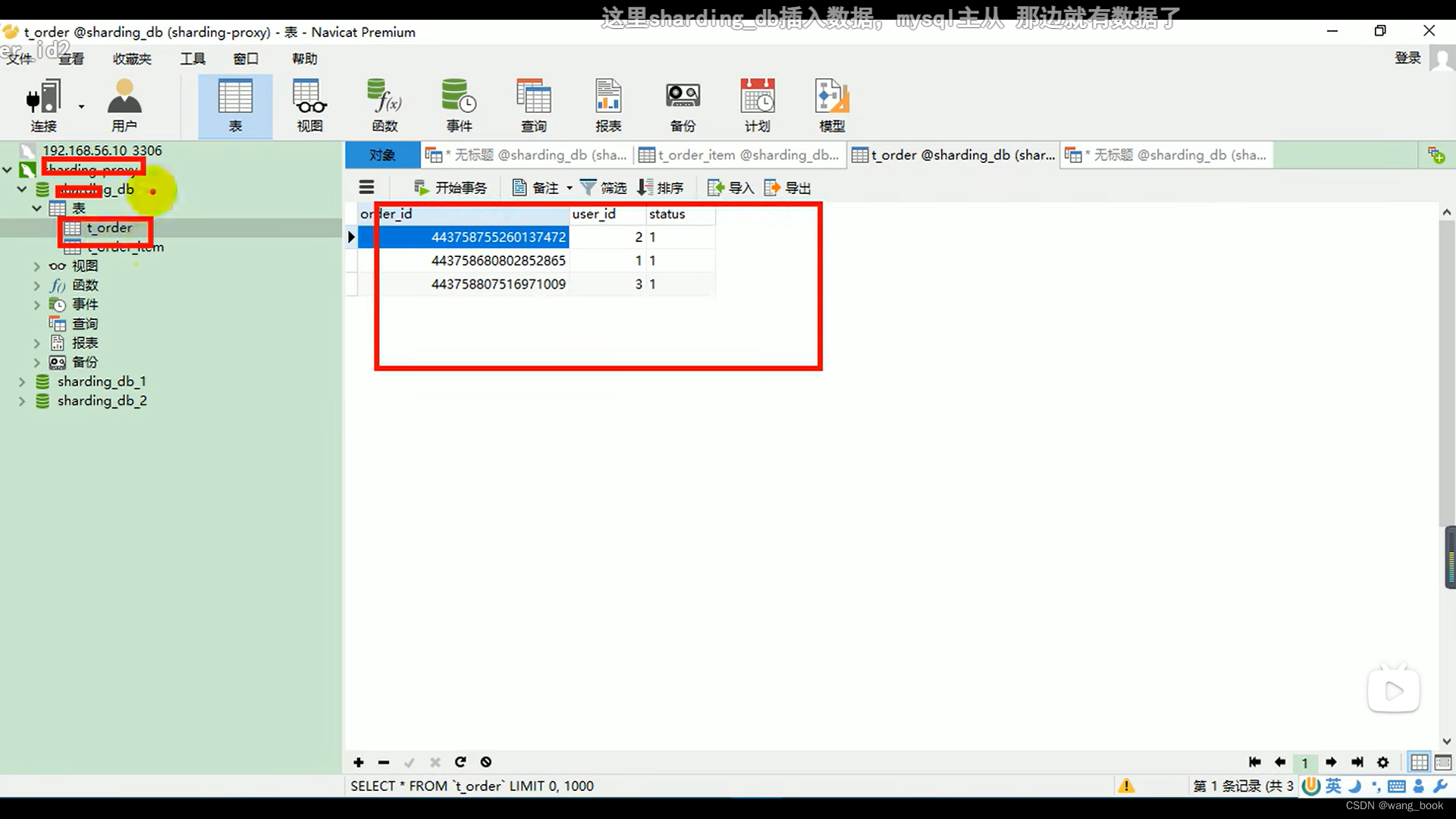
这里看真实数据库
用户id为偶数的订单都在demo_ds_0里,用户id为奇数的订单都在demo_ds_1里